1 Guava Cache 介绍
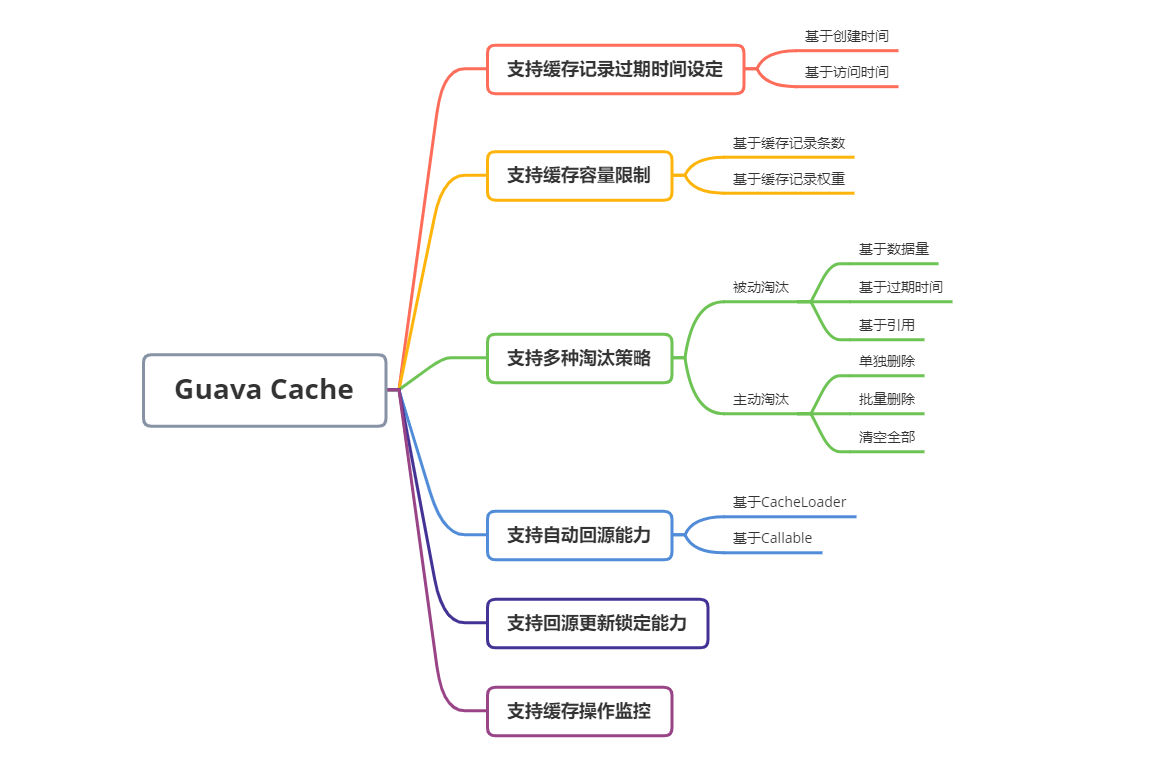
Guava 是 Google 提供的一套 JAVA 的工具包,而 Guava Cache 则是该工具包中提供的一套完善的 JVM 级别的高并发缓存框架。其实现机制类似 ConcurrentHashMap,但是进行了众多的封装与能力扩展。作为 JVM 级别的本地缓存框架,Guava Cache 具备缓存框架该有的众多基础特性。当然,Guava Cache 能从众多本地缓存类产品中脱颖而出,除了具备上述基础缓存特性外,还有众多贴心的能力增强。
1.1 支持缓存记录的过期设定
作为一个合格的缓存容器,支持缓存记录过期是一个基础能力。Guava Cache不但支持设定过期时间,还支持选择是根据插入时间进行过期处理(创建过期)、或者是根据最后访问时间进行过期处理(访问过期)。
| 过期策略 | 具体说明 |
|---|---|
| 创建过期 | 基于缓存记录的插入时间判断。比如设定10分钟过期,则记录加入缓存之后,不管有没有访问,10分钟时间到则过期。 |
| 访问过期 | 基于最后一次的访问时间来判断是否过期。比如设定10分钟过期,如果缓存记录被访问到,则以最后一次访问时间重新计时;只有连续10分钟没有被访问的时候才会过期,否则将一直存在缓存中不会被过期。 |
实际使用时,在创建缓存容器的时候指定过期策略即可:
① 基于创建时间过期
public Cache<String, User> createUserCache() {
return CacheBuilder.newBuilder()
.expireAfterWrite(30L, TimeUnit.MINUTES)
.build();
}
② 基于访问时间过期
public Cache<String, User> createUserCache() {
return CacheBuilder.newBuilder()
.expireAfterAccess(30L, TimeUnit.MINUTES)
.build();
}
1.2 支持缓存容量限制
作为内存型缓存,必须要防止出现内存溢出的风险。Guava Cache支持设定缓存容器的最大存储上限,并支持根据缓存记录条数或者基于每条缓存记录的权重进行判断是否达到容量阈值。
当容量触达阈值后,支持根据FIFO + LRU策略实施具体淘汰处理以腾出位置给新的记录使用。
| 淘汰策略 | 具体说明 |
|---|---|
| FIFO | 根据缓存记录写入的顺序,先写入的先淘汰 |
| LRU | 根据访问顺序,淘汰最久没有访问的记录 |
实际使用的时候,同样是在创建缓存容器的时候指定容量上限与淘汰策略。
① 限制缓存记录条数
public Cache<String, User> createUserCache() {
return CacheBuilder.newBuilder()
.maximumSize(10000L)
.build();
}
② 限制缓存记录权重
public Cache<String, User> createUserCache() {
return CacheBuilder.newBuilder()
.maximumWeight(10000L)
.weigher((key, value) -> (int) Math.ceil(instrumentation.getObjectSize(value) / 1024L))
.build();
}
这里需要注意:按照权重进行限制缓存容量的时候必须要指定 weighter 属性才可以生效。上面代码中我们通过计算value对象的字节数 (byte) 来计算其权重信息,每 1kb 的字节数作为 1 个权重,整个缓存容器的总权重限制为 1w,这样就能实现将缓存内存占用控制在10000*1k≈10M左右 (若存储的都是 1kb 的记录,则最多缓存 1w 条记录;若存储的都是 100kb 的记录,则最多缓存 100 条记录)。
为什么要有 “限制缓存记录权重” 这种方式?
一般而言,限制容器的容量的初衷,是为了防止内存占用过大导致
内存溢出,所以本质上是限制内存的占用量。从实现层面,往往会根据总内存占用量与预估每条记录字节数进行估算,将其转换为对缓存记录条数的限制。这种做法相对简单易懂,但是对于单条缓存记录占用字节数差异较大的情况下,会导致基于条数控制的结果不够精准。为了解决这个问题,Guava Cache 中提供了一种相对精准的控制策略,即基于权重的总量控制,根据一定的规则,计算出每条 value 记录所占的权重值,然后以权重值进行总量的计算。基于
weight权重的控制方式,比较适用于这种对容器体量控制精度有严格诉求的场景,可以在创建容器的时候指定每条记录的权重计算策略 (如基于字符串长度或者基于 bytes 数组长度进行计算权重)。
1.3 支持多种淘汰策略
为了简单描述,我们将数据从缓存容器中移除的操作统称数据淘汰。按照触发形态不同,可将数据的清理与淘汰策略分为被动淘汰与主动淘汰两种。
- 被动淘汰
- 基于过期时间:在创建容器的时候指定其
expireAfterWrite或expireAfterAccess - 基于数据量:在创建容器的时候指定其
maximumSize或maximumWeight - 基于引用:基于引用回收的策略,核心是利用
JVM虚拟机的 GC 机制来达到数据清理的目的。按照 JVM 的 GC 原理,当一个对象不再被引用之后,便会执行一系列的标记清除逻辑,并最终将其回收释放。在构建 Cache 实例过程中,通过设置使用弱引用的键、或弱引用的值、或软引用的值,从而使 JVM在GC时顺带实现缓存的清除,不过一般不轻易使用这个特性。- CacheBuilder.weakKeys():使用弱引用存储键。当键没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式,使用弱引用键的缓存用 == 而不是 equals 比较键。
- CacheBuilder.weakValues():使用弱引用存储值。当值没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式,使用弱引用值的缓存用 == 而不是 equals 比较值。
- CacheBuilder.softValues():使用软引用存储值。软引用只有在响应内存需要时,才按照全局最近最少使用的顺序回收。考虑到使用软引用的性能影响,我们通常建议使用更有性能预测性的缓存大小限定(基于数据量)。使用软引用值的缓存同样用 == 而不是 equals 比较值。
- 基于过期时间:在创建容器的时候指定其
- 调用 cache 相关 api 主动淘汰
- invalidate(key):删除指定的记录
- invalidateAll(keys):批量删除给定的记录
- invalidateAll():清空整个缓存容器
1.4 支持自动回源
在前面文章中,我们有介绍过缓存的三种模型,分别是旁路型、穿透型、异步型。Guava Cache 作为一个封装好的缓存框架,是一个典型的穿透型缓存。正常业务使用缓存时通常会使用旁路型缓存,即先去缓存中尝试查询获取数据,如果获取不到则会从数据库中进行查询并加入到缓存中;而为了简化业务端使用复杂度,Guava Cache支持集成数据源,业务层面调用接口查询缓存数据的时候,如果缓存数据不存在,则会自动去数据源中进行数据获取并加入缓存中。
1.4.1 实现方式
Callable 方式
通过在 cache 的 get 方法中传入 Callable 实现来指定回源获取数据:
public class CacheService {
UserDao userDao = new UserDao();
public User findUser(Cache<String, User> cache, String userId) {
try {
return cache.get(userId, () -> {
System.out.println(userId + "用户缓存不存在,尝试回源查找并回填...");
return userDao.getUser(userId);
});
} catch (ExecutionException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
Cache<String, User> cache = CacheBuilder.newBuilder().build();
CacheService cacheService = new CacheService();
System.out.println(cacheService.findUser(cache, "123"));
System.out.println(cacheService.findUser(cache, "124"));
System.out.println(cacheService.findUser(cache, "123"));
}
}
实际使用时若查询的用户不存在,则会自动去回源查找并写入缓存里,再次获取时便能从缓存直接获取。执行结果:
123用户缓存不存在,尝试回源查找并回填...
User(userId=123, userName=铁柱, department=研发部)
124用户缓存不存在,尝试回源查找并回填...
User(userId=124, userName=翠花, department=测试部)
User(userId=123, userName=铁柱, department=研发部)
CacheLoader 方式
需要在创建缓存容器的时候声明容器为 LoadingCache 类型,并且指定CacheLoader处理逻辑:
public class CacheService {
public LoadingCache<String, User> createUserCache() {
return CacheBuilder.newBuilder().build(new CacheLoader<String, User>() {
@Override
public User load(String key) throws Exception {
System.out.println(key + "用户缓存不存在,尝试CacheLoader回源查找并回填...");
return userDao.getUser(key);
}
});
}
public static void main(String[] args) {
CacheService cacheService = new CacheService();
LoadingCache<String, User> cache = cacheService.createUserCache();
try {
System.out.println(cache.get("123"));
System.out.println(cache.get("124"));
System.out.println(cache.get("123"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
这样,获取不到数据时,也会自动回源查询并填充。执行结果:
123用户缓存不存在,尝试回源查找并回填...
User(userId=123, userName=铁柱, department=研发部)
124用户缓存不存在,尝试回源查找并回填...
User(userId=124, userName=翠花, department=测试部)
User(userId=123, userName=铁柱, department=研发部)
二者结合
Callable 和 CacheLoader 这两种方式都能实现回源获取数据,二者也可结合使用,这种情况下优先会执行 Callable 提供的逻辑,Callable 缺失的场景会使用 CacheLoader 提供的逻辑。
public static void main(String[] args) {
CacheService cacheService = new CacheService();
LoadingCache<String, User> cache = cacheService.createUserCache();
try {
System.out.println(cache.get("123", () -> new User("xxx")));
System.out.println(cache.get("124"));
System.out.println(cache.get("123"));
} catch (Exception e) {
e.printStackTrace();
}
}
执行后,可以看出 Callable 逻辑被优先执行,而 CacheLoader 作为兜底策略存在:
User(userId=xxx, userName=null, department=null)
124用户缓存不存在,尝试CacheLoader回源查找并回填...
User(userId=124, userName=翠花, department=测试部)
User(userId=xxx, userName=null, department=null)
1.4.2 支持更新锁定能力
这是与上面数据源集成一起的辅助增强能力。在高并发场景下,如果某个 key 值没有命中缓存,大量的请求同步打到下游模块处理的时候,很容易造成缓存击穿问题。
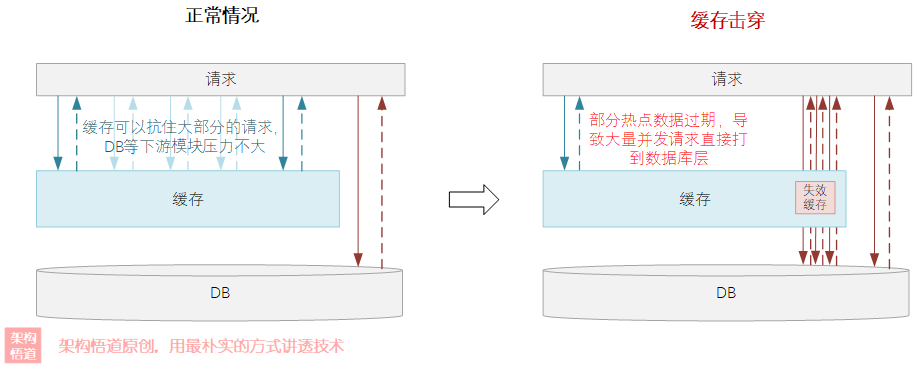
为了防止缓存击穿问题,可以通过加锁的方式来规避。当缓存不可用时,仅持锁的线程负责从数据库中查询数据并写入缓存中,其余请求重试时先尝试从缓存中获取数据,避免所有的并发请求全部同时打到数据库上。
作为穿透型缓存的保护策略之一,Guava Cache 自带了并发锁定机制,同一时刻仅允许一个请求去回源获取数据并回填到缓存中,而其余请求则阻塞等待,不会造成数据源的压力过大。
1.5 数据清理与刷新机制
1.5.1 数据过期
对于数据有过期失效诉求的场景,Guava cache 可通过 expireAfterWrite或expireAfterAccess设定缓存的过期时间。但数据过期后,会立即被删除吗?
缓存数据删除有几种机制:
| 删除机制 | 具体说明 |
|---|---|
| 主动删除 | 搞个定时线程不停的去扫描并清理所有已经过期的数据。 |
| 惰性删除 | 在数据访问的时候进行判断,如果过期则删除此数据。 |
| 两者结合 | 采用惰性删除为主,低频定时主动删除为兜底,兼顾处理性能与内存占用。 |
在Guava Cache 中,为了最大限度的保证并发性,采用的是惰性删除的策略,而没有设计独立清理线程。所以这里我们就可以回答前面的问题,也即过期的数据,并非是立即被删除的,而是在get等操作访问缓存记录时触发过期数据的删除操作。
// LocalCache 源码
class LocalCache<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V> {
@Nullable
public V get(@Nullable Object key) {
if (key == null) {
return null;
} else {
int hash = this.hash(key);
return this.segmentFor(hash).get(key, hash); // 最终只会触发这一个分片内的数据清理操作
}
}
static class Segment<K, V> extends ReentrantLock {
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
Preconditions.checkNotNull(key);
Preconditions.checkNotNull(loader);
try {
if (this.count != 0) {
ReferenceEntry<K, V> e = this.getEntry(key, hash);
if (e != null) {
long now = this.map.ticker.read();
V value = this.getLiveValue(e, now);
if (value != null) {
this.recordRead(e, now);
this.statsCounter.recordHits(1);
Object var18 = this.scheduleRefresh(e, key, hash, value, now, loader);
return var18;
}
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
Object var9 = this.waitForLoadingValue(e, key, valueReference);
return var9;
}
}
}
Object var16 = this.lockedGetOrLoad(key, hash, loader);
return var16;
} catch (ExecutionException var13) {
ExecutionException ee = var13;
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error)cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
} else {
throw ee;
}
} finally {
this.postReadCleanup(); // 触发可能的清理操作
}
}
void postReadCleanup() {
if ((this.readCount.incrementAndGet() & 63) == 0) { // 并非每次请求都会触发 cleanUp, 会尝试积攒一定次数后再清理
this.cleanUp();
}
}
}
}
在 get 执行逻辑中进行数据过期清理以及重新回源加载的执行判断流程,可以简化为下图中的关键环节:
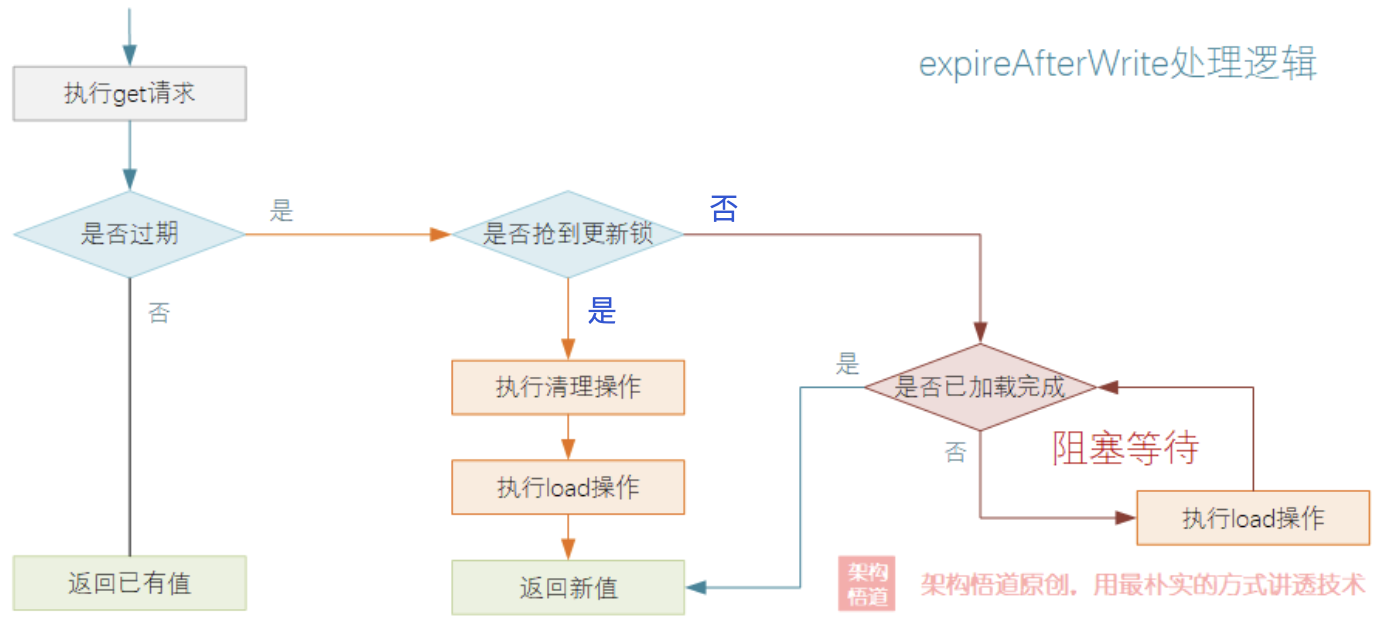
在执行 get 请求的时候,会先判断下当前查询的数据是否过期,如果已经过期,则会触发对当前操作的Segment的过期数据清理操作。
为了实现高效的多线程并发控制,Guava Cache 采用了类似 ConcurrentHashMap 一样的
分段锁机制,数据被分为了不同分片,每个分片同一时间只允许有一个线程执行写操作,这样降低并发锁争夺的竞争压力。而上面代码中也可以看出,执行清理的时候,仅针对当前查询的记录所在的Segment分片执行清理操作,而其余的分片的过期数据并不会触发清理逻辑。在创建缓存容器的时候将
concurrencyLevel设置为允许并发数为1,就强制所有的数据都存放在同一个分片中。(concurrencyLevel 值与分段 Segment 的数量关系见 1.6)
1.5.2 数据刷新
除了上述的 2 个过期时间设定方法,Guava Cache 还提供了 refreshAfterWrite 方法,用于设定定时自动 refresh 操作。这能在设定过期时间的基础上,再设定一个每隔1分钟重新 refresh 的逻辑。这样既可以保证数据在缓存中的留存时长,又可以尽可能的缩短缓存变更生效的时间。
若要使用 refreshAfterWrite 方法,创建缓存容器时必须指定 CacheLoader 实例,并覆写 reload 方法,提供一个异步数据加载能力,避免数据刷新操作对业务请求造成阻塞。
// CacheLoader 源码
public abstract class CacheLoader<K, V> {
@GwtIncompatible
public ListenableFuture<V> reload(K key, V oldValue) throws Exception {
Preconditions.checkNotNull(key);
Preconditions.checkNotNull(oldValue);
return Futures.immediateFuture(this.load(key));
}
}
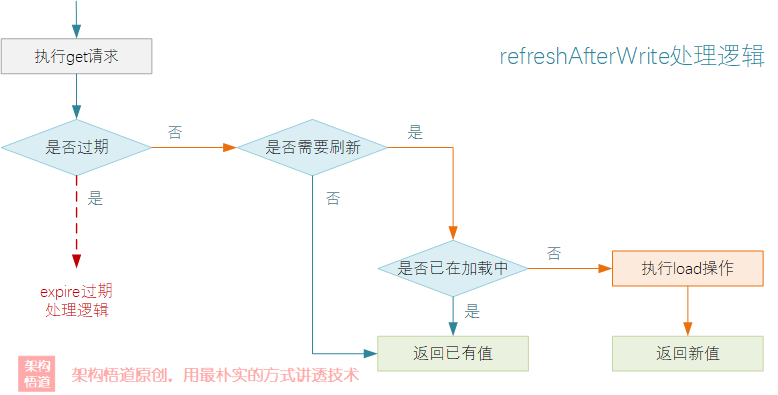
与 expire 清理逻辑相同,refresh 操作依旧是采用一种被动触发的方式来实现。当 get 操作执行的时候会判断下如果创建时间已经超过了设定的刷新间隔,则会重新去执行一次数据的加载逻辑 (前提是数据并没有过期)。
鉴于缓存读多写少的特点,Guava Cache 在数据 refresh 操作执行时,采用了一种非阻塞式的加载逻辑,尽可能的保证并发场景下对读取线程的性能影响。
public class CacheService {
private static class MyCacheLoader extends CacheLoader<String, User> {
@Override
public User load(String s) throws Exception {
System.out.println(Thread.currentThread().getId() + "线程执行CacheLoader.load()...");
Thread.sleep(500L);
System.out.println(Thread.currentThread().getId() + "线程执行CacheLoader.load()结束...");
return new User(s, RandomUtil.randomString(5));
}
@Override
public ListenableFuture<User> reload(String key, User oldValue) throws Exception {
System.out.println(Thread.currentThread().getId() + "线程执行CacheLoader.reload(),oldValue=" + oldValue);
return super.reload(key, oldValue);
}
}
public static void main(String[] args) {
try {
LoadingCache<String, User> cache = CacheBuilder.newBuilder().refreshAfterWrite(1L, TimeUnit.SECONDS).build(new MyCacheLoader());
cache.put("123", new User("123", "ertyu"));
Thread.sleep(1100L);
Runnable task = () -> {
try {
System.out.println(Thread.currentThread().getId() + "线程开始执行查询操作");
User user = cache.get("123");
System.out.println(Thread.currentThread().getId() + "线程查询结果:" + user);
} catch (Exception e) {
e.printStackTrace();
}
};
CompletableFuture.allOf(CompletableFuture.runAsync(task), CompletableFuture.runAsync(task)
).thenRunAsync(task).join();
} catch (Exception e) {
e.printStackTrace();
}
}
}
执行后,结果如下:
14线程开始执行查询操作
13线程开始执行查询操作
13线程查询结果:User(userName=ertyu, userId=123)
14线程执行CacheLoader.reload(),oldValue=User(userName=ertyu, userId=123)
14线程执行CacheLoader.load()...
14线程执行CacheLoader.load()结束...
14线程查询结果:User(userName=97qx6, userId=123)
15线程开始执行查询操作
15线程查询结果:User(userName=97qx6, userId=123)
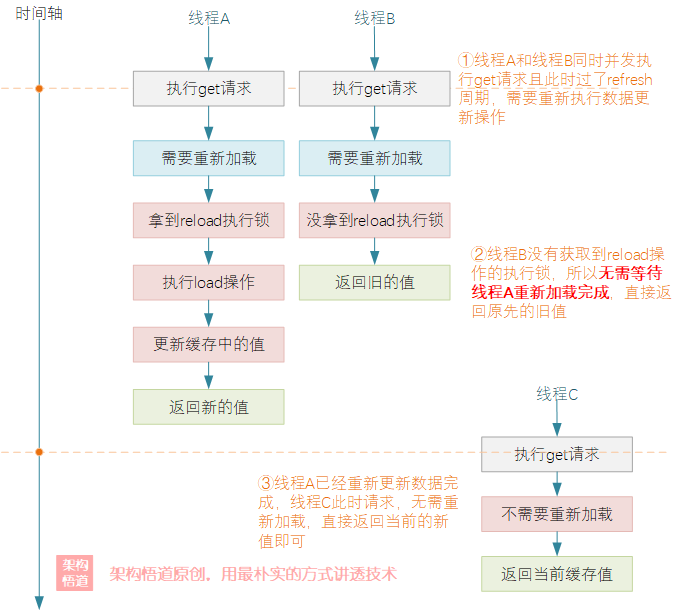
从执行结果可以看出,两个并发同时请求的线程只有1个执行了load数据操作,且两个线程所获取到的结果是不一样的。具体而言,可以概括为如下几点:
- 同一时刻仅允许一个线程执行数据重新加载操作,并阻塞等待重新加载完成之后该线程的查询请求才会返回对应的新值作为结果。
- 当一个线程正在阻塞执行
refresh数据刷新操作的时候,其它线程此时来执行 get 请求的时候,会判断下数据需要 refresh 操作,但是因为没有获取到 refresh 执行锁,这些其它线程的请求不会被阻塞等待 refresh 完成,而是立刻返回当前 refresh 前的旧值。 - 当执行 refresh 的线程操作完成后,此时另一个线程再去执行 get 请求的时候,会判断无需 refresh,直接返回当前内存中的当前值即可。