项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4622139?contributionType=1
fork一下,由于内容过多这里就不全部写出来了。
前言
TrustAI是集可信分析和增强于一体的可信AI工具集,助力NLP开发者提升深度学习模型效果和可信度。在后续应用中,希望将TrustAI和智能标注以及模型构螺迭代打造持续学习链路。
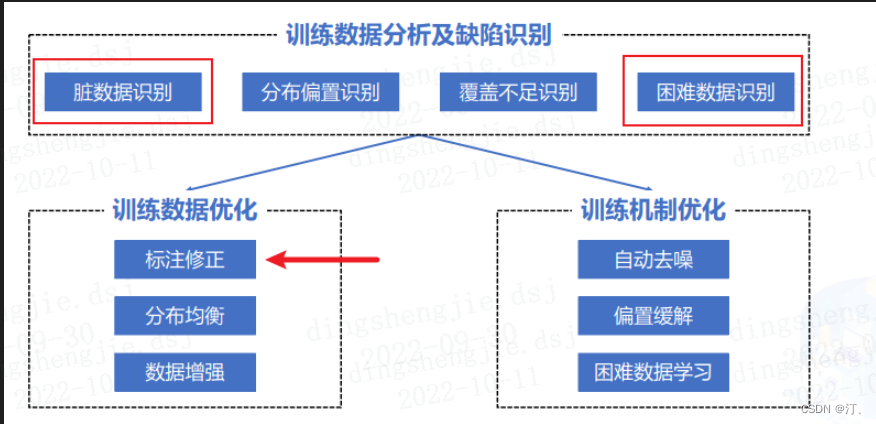
- 解决训练数据存在脏数据的问题
- 解决训练数据覆盖不足的问题(稀疏数据)
- 解决训练数据分布偏置的问题
- 解决文本冗余导致精度下降的问题
相关文章参考:
AiTrust下预训练和小样本学习在中文医疗信息处理挑战榜CBLUE表现
注意上述项目中对训练过程一些参数做了简单调整如500steps保存一次模型等,而本项目为了快速实现效果展示就以epoch为保存最优模型单位,如果为追求更好性能请参考上述项目或者自己修正。
项目参考:(更细算法原理请参考相关论文)
https://github.com/PaddlePaddle/TrustAI
https://github.com/PaddlePaddle/TrustAI/blob/main/trustai/interpretation/token_level/README.md
https://github.com/PaddlePaddle/TrustAI/blob/main/trustai/interpretation/example_level/README.md
结果部分展示:
| 模型 | DuReader-robust dev | DuReader-robust Test | 【Zero shot】 DuReader-checklist dev (Remove no answer) |
|||
|---|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | F1 | |
| bert-base[官方数据] | 71.70 | 85.47 | 30.80 | 53.14 | - | - |
| roberta-base[复现] | 73.48 | 86.98 | 45.97 | 69.43 | 28.66 | 50.47 |
| Selector-Predictor | 76.32(+2.84) | 89.03(+2.05) | 50.93(+4.96) | 72.22(+2.79) | 31.04(+2.33) | 53.29(+2.82) |

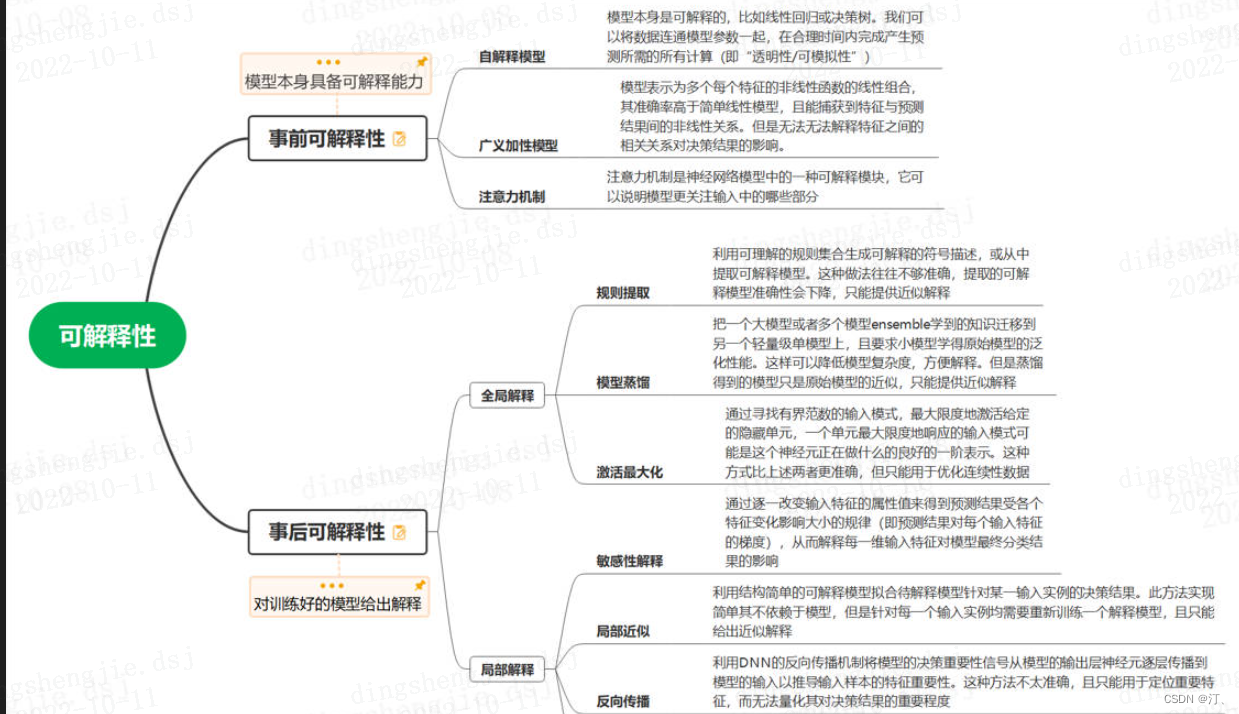
0.例证分析算法简介
随着深度学习模型的越发复杂,人们很难去理解其内部的工作原理。“黑盒”的可解释性正成为许多优秀研究者的焦点。
通过这些非常有效的可解释性方法,人们可以更好知道模型为什么好,为什么不好,进而可以针对性提高模型性能。
目前,可解释性研究领域缺乏一个用于评估解释方法的科学评估体系。
对于ante-hoc可解释性而言,其评估挑战在于如何量化模型的内在解释能力。
对于post-hoc可解释性而言,其评估挑战在于如何量化解释结果的保真度和一致性。
0.1 实例级证据分析算法简介
0.1.1 表示点方法(Representer Point)
论文:NeurIPS 2018 Representer Point Selection:https://proceedings.neurips.cc/paper/2018/file/8a7129b8f3edd95b7d969dfc2c8e9d9d-Paper.pdf
这篇论文做的跟ICML 2017 best paper influence function那篇论文一样,想分析对于一个测试点来说,哪些训练样本对这个决策影响最大,包括positive(这里叫excitatory)和negative(这里叫inhibitory)的训练样本点。方法上,这篇论文将输出层的margin(pre-activation prediction)分解成训练样本点的激活值的加权线性组合,这个权重叫做representer value,表达训练样本点对网络参数的影响。文中主要claim的比influence function有优势的是计算效率。
开源的代码里sklearn,tensorflow,pytorch都有用到,比较混乱,应用可能需要梳理这部分代码,从双方开源的代码看,该论文也借鉴了一部分influence function的代码,比如genericNeuralNet.py和genericNeuralNet.py。论文中提出的方法需要一些fine-tune,预估到最后一层的输入值等额外的步骤,也给工程框架上带来一定的困难。
相比于文中3.2估计预估误差是对比预估输出和真实输出的差异,influence function是对比去掉该训练样本前后训练得到模型的loss。输出对不同的训练样本的依赖可能有相关性,有可能当前模型比较依赖该训练样本,但不见得去掉该训练样本后,预测值有大的变化。相比之下,去掉该样本重新训练模型得到的结论会更鲁棒一些。
这篇论文提出的方法相比influence function的主要优势是计算量小,但也有一些限制(L2或者fine-tune),可以用在对计算效率要求比较高的场景。
开源代码:https://github.com/chihkuanyeh/Representer_Point_Selection
参考链接:https://zhuanlan.zhihu.com/p/114461143
0.1.2 基于梯度的相似度方法(Grad-Cosin, Grad-Dot)
论文:Input Similarity from the Neural Network Perspective https://proceedings.neurips.cc/paper/2019/hash/c61f571dbd2fb949d3fe5ae1608dd48b-Abstract.html
https://proceedings.neurips.cc/paper/2019/file/c61f571dbd2fb949d3fe5ae1608dd48b-Paper.pdf
在许多应用中,了解模型做出特定预测的原因可能与预测的准确性一样重要。然而,大型现代数据集的最高精度通常是通过甚至专家都难以解释的复杂模型来实现的,例如集成或深度学习模型,这在准确性和可解释性之间造成了矛盾。作为回应,最近提出了各种方法来帮助用户解释复杂模型的预测,但通常不清楚这些方法是如何相关的,以及何时一种方法优于另一种方法。为了解决这个问题,我们提出了一个解释预测的统一框架,SHAP(SHapley Additive exPlanations)。SHAP 为每个特征分配一个特定预测的重要性值。其新颖的组件包括:(1) 识别一类新的加性特征重要性度量,以及 (2) 理论结果表明该类中存在一个具有一组理想属性的唯一解。新类统一了六种现有方法,值得注意的是,该类中最近的几种方法缺乏建议的理想属性。基于这种统一的见解,我们提出了新的方法,这些方法显示出比以前的方法更好的计算性能和/或与人类直觉更好的一致性。
0.1.3 基于特征的相似度方法(Feature-Cosin, Feature-Dot, Feature-Euc)
论文:An Empirical Comparison of Instance Attribution Methods for NLP https://arxiv.org/abs/2104.04128
https://github.com/successar/instance_attributions_NLP
深度模型的广泛采用激发了对解释网络输出和促进模型调试的方法的迫切需求。实例归因方法构成了通过检索(可能)导致特定预测的训练实例来实现这些目标的一种方法。影响函数(IF;Koh 和 Liang 2017)通过量化扰动单个列车实例对特定测试预测的影响,提供了实现这一目标的机制。然而,即使逼近 IF 在计算上也是昂贵的,在许多情况下可能会令人望而却步。更简单的方法(例如,检索与给定测试点最相似的训练示例)可能具有可比性吗?在这项工作中,我们评估不同潜在实例归因在训练样本重要性方面的一致性程度。我们发现,简单的检索方法产生的训练实例与通过基于梯度的方法(例如 IF)识别的训练实例不同,但仍然表现出与更复杂的归因方法相似的理想特征
0.2 特征级证据分析算法简介
参考链接 https://blog.csdn.net/wxc971231/article/details/121184091
0.2.1 可解释性之积分梯度算法(Integrated Gradients)
论文:IntegratedGraients: Axiomatic Attribution for Deep Networks, Mukund Sundararajan et al. 2017 https://arxiv.org/abs/1703.01365
我们研究将深度网络的预测归因于其输入特征的问题,这是之前由其他几项工作研究过的问题。我们确定了归因方法应该满足的两个基本公理——敏感性和实现不变性。我们表明,大多数已知的归因方法都不满足它们,我们认为这是这些方法的根本弱点。我们使用这些公理来指导一种称为集成梯度的新归因方法的设计。我们的方法不需要对原始网络进行修改,实现起来非常简单;它只需要对标准梯度运算符进行几次调用。我们将这种方法应用于几个图像模型、几个文本模型和一个化学模型,展示了它调试网络、从网络中提取规则的能力
一种神经网络的可视化方法:积分梯度(Integrated Gradients),它首先在论文《Gradients of Counterfactuals》中提出,后来《Axiomatic Attribution for Deep Networks》再次介绍了它,两篇论文作者都是一样的,内容也大体上相同,后一篇相对来说更易懂一些,如果要读原论文的话,建议大家优先读后一篇。当然,它已经是2016~2017年间的工作了,“新颖”说的是它思路上的创新有趣,而不是指最近发表。所谓可视化,简单来说就是对于给定的输入x以及模型F(x),我们想办法指出x的哪些分量对模型的决策有重要影响,或者说对x各个分量的重要性做个排序,用专业的话术来说那就是“归因”。一个朴素的思路是直接使用梯度∇xF(x)来作为x各个分量的重要性指标,而积分梯度是对它的改进
参考链接:https://www.spaces.ac.cn/archives/7533
https://zhuanlan.zhihu.com/p/428131762
https://zhuanlan.zhihu.com/p/365815861
https://blog.csdn.net/wxc971231/article/details/121184091
0.2.2 LIME算法
论文: Lime: "Why Should I Trust You?": Explaining the Predictions of Any Classifier, Marco Tulio Ribeiro et al. 2016 https://arxiv.org/abs/1602.04938
尽管被广泛采用,机器学习模型仍然主要是黑匣子。然而,了解预测背后的原因对于评估信任非常重要,如果一个人计划根据预测采取行动,或者在选择是否部署新模型时,这是至关重要的。这种理解还提供了对模型的洞察力,可用于将不可信的模型或预测转换为可信的模型。在这项工作中,我们提出了 LIME,这是一种新颖的解释技术,通过在预测周围学习可解释的模型,以可解释和忠实的方式解释任何分类器的预测。我们还提出了一种通过以非冗余方式呈现具有代表性的个体预测及其解释来解释模型的方法,将任务定义为子模块优化问题。我们通过解释文本(例如随机森林)和图像分类(例如神经网络)的不同模型来展示这些方法的灵活性。我们通过模拟和人类受试者的新实验展示了解释的效用,在各种需要信任的场景中:决定是否应该信任预测、在模型之间进行选择、改进不可信的分类器以及确定为什么不应该信任分类器.
Local: 基于想要解释的预测值及其附近的样本,构建局部的线性模型或其他代理模型;
Interpretable: LIME做出的解释易被人类理解。利用局部可解释的模型对黑盒模型的预测结果进行解释,构造局部样本特征和预测结果之间的关系;
Model-Agnostic: LIME解释的算法与模型无关,无论是用Random Forest、SVM还是XGBoost等各种复杂的模型,得到的预测结果都能使用LIME方法来解释;
Explanations: LIME是一种事后解释方法。
参考链接:https://cloud.tencent.com/developer/news/617057
https://blog.csdn.net/weixin_42347070/article/details/106455763
https://blog.csdn.net/weixin_42347070/article/details/106076360
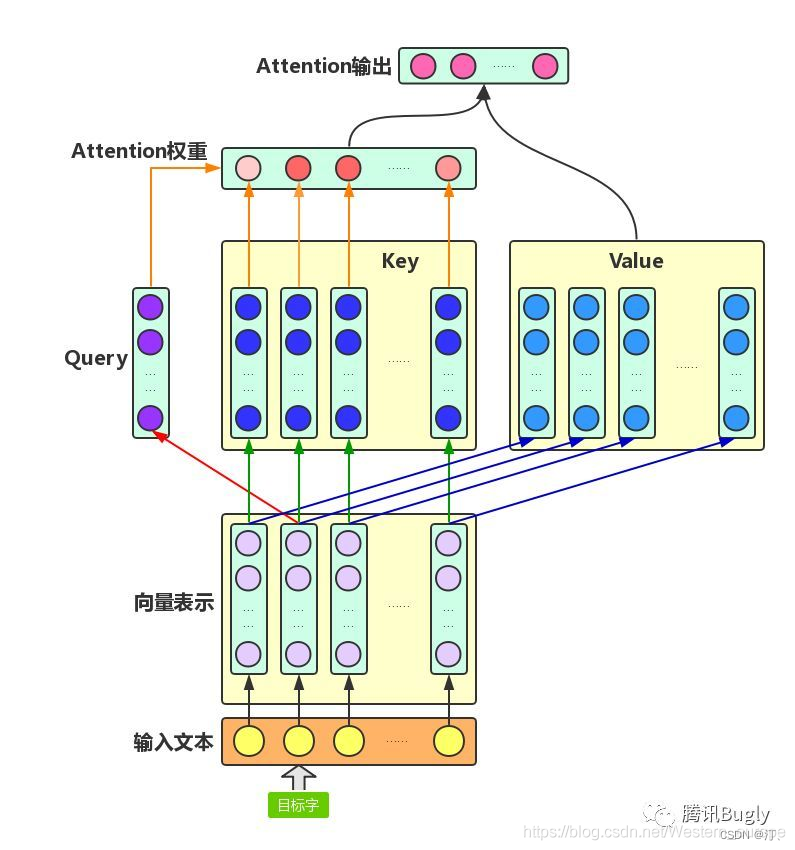
0.2.3 Quantifying Attention Flow in Transformers
Rollout: Quantifying Attention Flow in Transformers, Abnar et al. 2020 https://arxiv.org/abs/2005.00928
在 Transformer 模型中,“self-attention”将来自参与嵌入的信息组合到下一层焦点嵌入的表示中。因此,在 Transformer 的各个层中,来自不同令牌的信息变得越来越混合。这使得注意力权重在解释探测时变得不可靠。在本文中,我们考虑通过自我注意来量化这种信息流的问题。我们提出了两种在给定注意力权重、注意力推出和注意力流的情况下将注意力近似于输入令牌的方法,作为使用注意力权重作为输入令牌的相对相关性时的事后方法。我们表明,这些方法对信息流给出了互补的观点,并且与原始注意力相比,
参考链接
https://blog.csdn.net/Western_europe/article/details/109611695
1.项目主要内容:


7.总结
各个方法对比可以看每个章节的小结
总结下来:实例级证据分析方法RepresenterPointModel和FeatureSimilarityModel整体取得效果更佳,主要原因在于可以判别出需要标注的数据,这样在部分样本下就能取得更好的效果。
github提了一个issue关于PaddleNLP在持续学习这块的迭代期待:
https://github.com/PaddlePaddle/PaddleNLP/issues/3395
问题背景:
2021-11-29 :百度ERNIE-Health登顶中文医疗信息处理CBLUE榜单冠军:https://baijiahao.baidu.com/s?id=1717731573139745403&wfr=spider&for=pc
2022-04-13 :云知声登顶中文医疗信息处理挑战榜CBLUE 2.0:https://baijiahao.baidu.com/s?id=1729960390071520105&wfr=spider&for=pc
2022-05月份: 艾登&清华团队在中文医疗信息处理挑战榜喜创佳绩:https://www.cn-healthcare.com/articlewm/20220606/content-1372998.html
1.可以看到在CBLUE榜单上,ERNIE最先刷榜登顶,后续有一些别的团队再更新刷榜。通过模型对比,我相信ERNIE一定是NLP领域前沿模型,效果性能都很优越。而后续新榜单模型,在算法模型的优化侧重点可能没那么大,感觉更多的会对数据集的处理上下了很大功夫。模型差不多情况下,不同数据增强等技术影响还是比较大的,然后不断迭代。
2.看到paddlenlp已经推出了:pipelines面向 NLP 全场景为用户提供低门槛构建强大产品级系统的能力,通过一种简单高效的方式搭建一套语义检索系统,使用自然语言文本通过语义进行智能文档查询。
因此引出了一个问题:关于持续学习
目前看到在paddlenlp 提供了一些数据优化的方法:如:AITrust等可信分析,以及BML平台上看到的智能标注(或者个人依赖ERNIE生成的教师模型),来提供相对较高质量的标注数据。
但感觉在模型迭代过程中更多的是点状,是靠人工进行一个个串行起来。 希望可以出现一个持续学习模型的流程(自动化)和这些技术结合起来,还是有很大意义的。
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4622139?contributionType=1
fork一下自己跑下项目即可,由于内容过多这里就不全部写出来了。