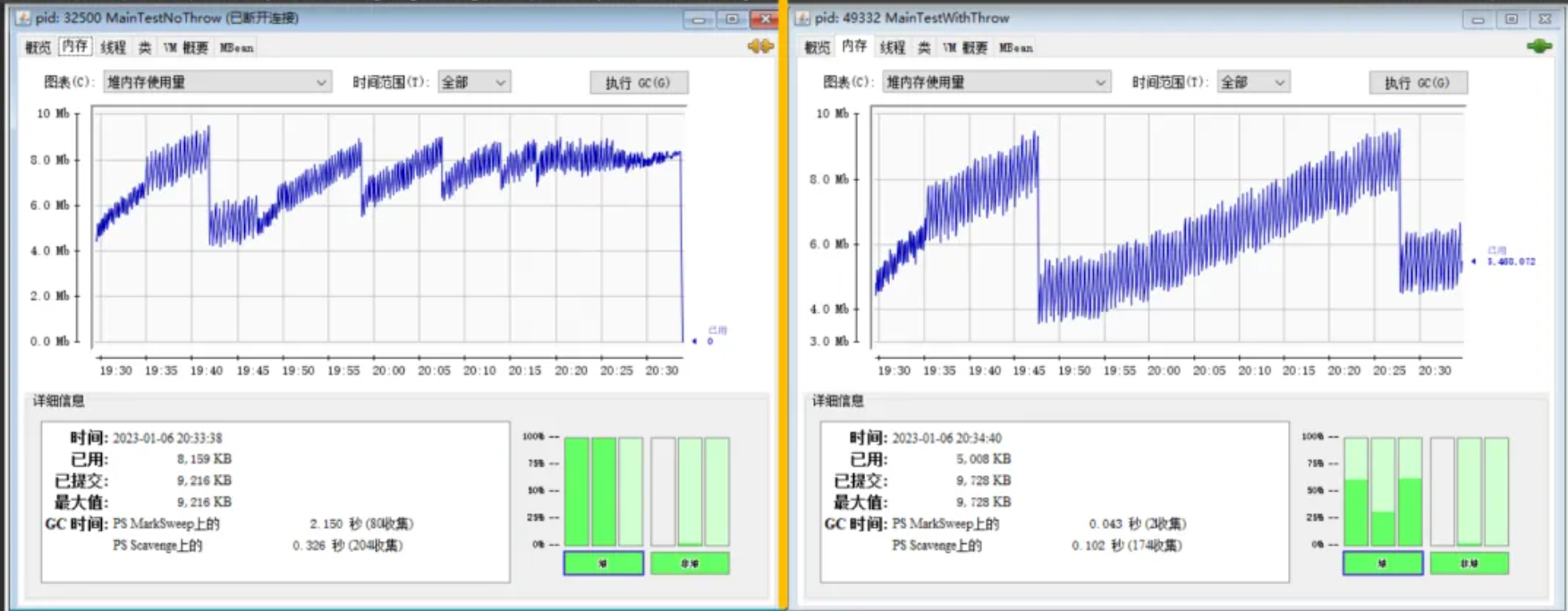
你好呀,我是歪歪。 最近遇到一个生产问题,我负责的一个服务触发了内存使用率预警,收到预警的时候我去看了内存使用率已经到了 80%,看了一眼 GC 又发现还没有触发 FullGC,一次都没有。 基于这个现象,当时推测有两种可能,一种是内存溢出,一种是内存泄漏。 好,假设现在是面试,面试官目前就给了这点信息,他问你到底是溢出还是泄漏,你怎么回答? 在回答之前,我们得现明确啥是溢出,啥情况又是泄漏。 虽然都与内存相关,但它们发生的时机和影响有所不同。内存溢出通常发生在程序运行时,当数据结构的大小超过预设限制时,常见的情况是你要分配一个大对象,比如一次从数据中查到了过多的数据。 而内存泄漏和“过多”关系不大,是一个细水长流的过程,一次内存泄漏的影响可能微乎其微,但随着时间推移,多次内存泄漏累积起来,最终可能导致内存溢出。 概念就是这个概念,这两个玩意经常被大家搞混,所以多嘴提一下。 概念明确了,回到最开始这个问题,你怎么回答? 你回答不了。 因为这些信息太不完整了,所以你回答不了。 面试的时候面试官就喜欢出这种全是错误选项的题目来迷惑你,摸摸你的底子到底怎么样。 首先,为什么不能判断,是因为前面说了:一次 FullGC 都没有。 虽然现在内存使用率已经到 80% 了,万一一次 FullGC 之后,内存使用率又下去了呢,说明程序没有任何问题。 如果没有下去,说明大概率是内存溢出了,需要去代码里面找哪里分配了大对象了。 那如果下去了,能说明一定没有内存泄漏吗? 也不能,因为前面又说了:内存泄漏是一个细水长流的过程。 关于内存溢出,如果监控手段齐全到位的话,你就记住左边这个走势图: 一个缓慢的持续上升的内存趋势图, 最后疯狂触发 GC,但是并没有内存被回收,最后程序直接崩掉。 内存泄漏,一眼定真假。 这个图来自我去年写的这篇文章:《虽然是我遇到的一个棘手的生产问题,但是我写出来之后,就是你的了。》 里面就是描述了一个内存泄漏的问题,通过分析 Dump 文件的方式,最终成功定位到泄漏点,修复代码。 一个不论多么复杂的内存泄漏问题,处理起来都是有方法论的。 不过就是 Dump 文件分析、工具的使用以及足够的耐心和些许的运气罢了。 所以我不打算赘述这些东西了,我想要分享的是我这次是怎么对应文章开始说的内存预警的。 我的处理方式就是:重启服务。 是的,常规来说都是会保留现场,然后重启服务。但是我的处理方式是:直接执行重启服务的预案。没有后续动作了。 我当时脑子里面的考虑大概是这样的。 首先,这个服务是一个边缘服务,它所承载的数据量不多,其业务已经超过一年多没有新增,存量数据正在慢慢的消亡。代码近一两年没啥改动,只有一些升级 jar 包,日志埋点这类的横向改造。 其次,我看了一下这个服务已经有超过四个月没有重启过了,这期间没有任何突发流量,每天处理的数据呈递减趋势,内存走势确实是一个缓慢上升的过程,我初步怀疑是有内存泄漏。 然后,这个服务是我从别的团队那边接手的一个服务,基于前一点,业务正在消亡这个因素,我也只是知道大概的功能,并不知道内部的细节,所以由于对系统的熟悉度不够,如果要定位问题,会较为困难。 最后,基于公司制度,虽然我知道应该怎么去排查问题,命令和工具我都会使用,但是我作为开发人员是没有权限使用运维人员的各类排查工具和排查命令的,所以如果要定位问题,我必须请求协调一个运维同事帮忙。 于是,在心里默默的盘算了一下投入产出比,我决定直接重启服务,不去定位问题。 按照目前的频率,程序正常运行四五个月后可能会触发内存预警,那么大不了就每隔三个月重启一次服务嘛,重启一次只需要 30s。一年按照重启 4 次算,也就是才 2 分钟。 这个业务我们就算它要五年后才彻底消亡,那么也就才 10 分钟而已。 如果我要去定位到底是不是内存泄露,到底在哪儿泄露的,结合我对于系统的熟悉程度和公司必须有的流程,这一波时间消耗,少说点,加起来得三五个工作日吧。 10 分钟和三五个工作日,这投入产出比,该选哪个,一目了然了吧? 我分享这个事情的目的,其实就是想说明我在这个事情上领悟到的一个点:在工作中,你遇到的问题,不是每一个都必须被解决的,也可以选择绕过问题,只要最终结果是好的就行。 如果我们抛开其他因素,只是从程序员的本职工作来看,那么遇到诸如内存泄漏的问题的时候,就是应该去定位问题、解决问题。 但是在职场中,其实还需要结合实际情况,进行分析。 什么是实际情况呢? 我前面列出来的那个“首先,其次,然后,最后”,就是我这个问题在技术之外的实际情况。 这些实际情况,让我决定不用去定位这个问题。 这也不是逃避问题,这是权衡利弊之后的最佳选择。 同样是一天的时间,我可以去定位这个“重启就能解决”的问题,也可以去做其他的更有价值事情,敲一些业务价值更大的代码。 这个是需要去权衡的,一个重要的衡量标准就是前面说的:投入产出比。 关于“不是所有的问题都必须被解决的,也可以选择绕过问题”这个事情,我再给你举一个我遇到的真实的例子。 几年前,我们团队遇到一个问题,我们使用的 RPC 框架是 Dubbo,有几个核心服务在投产期间滚动发布的时候,流量老是弄不干净,导致服务已经下线了,上游系统还在调用。 当时安排我去调研一下解决方案。 其实这就是一个优雅下线的问题,但是当时资历尚浅,我认真研究了一段时间,确实没研究出问题的根本解决方案。 后来我们给出的解决方案就是做一个容错机制,如果投产期间有因为流量不干净的问题导致请求处理失败的,我们把这些数据记录下来,然后等到投产完成后再进行重发。 没有解决根本问题,选择绕过了问题,但是从最终结果上看,问题是被解决了。 再后来,我们搭建了双中心。投产之前,A,B 中心都有流量,每次投产的时候,先把所有流量从 A 中心切到 B 中心去,在 A 中心没有任何流量的情况下,进行服务投产。B 中心反之。 这样,从投产流程上就规避了“流量老是弄不干净”的问题,因为投产的时候对应的服务已经没有在途流量了,不需要考虑优雅的问题了,从而规避了优雅下线的问题。 问题还是没有被解决,但是问题被彻底绕过。 最后,再举一个我在知乎上看到的一个回答,和我想要表达的观点,有异曲同工之妙: https://www.zhihu.com/question/634940930/answer/3336285780 这个回答下面的评论也很有意思,有兴趣的可以去翻一下,我截取两个我觉得有意思的: 在职场上,甚至在生活中,一个虽然没有解决方案但是可以被绕过的问题,我认为不是问题。 但是这个也得分情况,不是所有问题都能绕开的,假如是一个关键服务,那肯定不能置之不理,硬着头皮也得上。 关键是,我在职场上和生活中遇到过好多人,遇到问题的时候,似乎只会硬着头皮往上冲。 只会硬着头皮往上冲和知道什么时候应该硬着头皮往上冲,是两种截然不同的职场阶段。 所以有时候,遇到问题的时候,不要硬上,也让头皮休息一下,看看能不能绕过去。