一、问题描述
在大模型训练中,后预训练技术(Post-pretraining)通常指的是在模型的初始预训练阶段和最终的微调阶段之间进行的一个额外训练步骤。这个步骤的目的是进一步调整模型,使其能够更好地适应特定领域或任务,同时保持或增强其从大规模预训练数据中学到的通用知识和特征表示。

1.1 主要特点
- 领域特定性:与初始预训练阶段使用的大规模通用数据集不同,后预训练阶段通常使用大量与特定领域或任务相关的数据。这些数据可能包含该领域的专业术语、特定语境或结构,有助于模型更深入地理解该领域。
- 监督与自监督学习结合:后预训练阶段可以采用监督学习或自监督学习的方式,具体取决于数据的可用性和任务需求。监督学习可以利用标注数据来指导模型的学习方向,而自监督学习则可以通过生成伪标签来利用未标注数据。
- 性能提升:通过后预训练,模型能够进一步细化其参数,使其更加适应特定领域或任务的要求。这有助于提高模型在该领域或任务上的表现,包括准确性、泛化能力等。
- 减少微调成本:由于后预训练阶段已经对模型进行了一定程度的调整,因此在最终的微调阶段,模型可以更快地收敛到最优解,从而减少微调所需的数据量和时间成本。
1.2 应用场景
在大规模语言模型(如BERT、GPT等)的训练过程中,后预训练技术被广泛应用于提升模型在特定任务上的表现。
例如,在自然语言处理领域,模型可能首先在大规模无标签文本数据上进行预训练,然后利用领域特定的文本数据进行后预训练,最后在特定任务的有标签数据集上进行微调。通过这种方式,模型能够更好地理解领域内的语言模式和结构,从而在相关任务上表现出更高的性能。
1.3 难点和挑战
主要源于模型的复杂性、数据的多样性以及训练过程中的优化难题,具体为:
1.3.1 数据质量与多样性
- 数据噪声:医疗、法律等专业领域的标注数据往往存在噪声,标注规范难以统一,导致模型在训练过程中可能学习到错误的信息,影响模型的准确性和泛化能力。
- 数据分布不匹配:预训练数据与后预训练数据、最终任务数据之间的分布差异可能导致模型在特定任务上表现不佳。如何确保数据分布的一致性是一个挑战。
- 数据稀缺性:对于某些领域或任务,高质量、标注好的数据可能非常稀缺,限制了后预训练过程的效果(后预训练可以无标签吧?)
1.3.2 领域适应性与通用性
- 领域特定性与通用性矛盾:后预训练过程旨在使模型适应特定领域或任务的需求,但过度的领域特定化可能导致模型在通用任务上表现下降。如何在领域适应性与通用性之间找到平衡点是一个挑战。
- 迁移学习难度:将后预训练好的模型迁移到新的任务或领域时,可能面临数据分布差异、任务复杂度变化等问题,需要设计有效的迁移学习策略来提高模型的适应能力。
- 正则化与防止过拟合:随着模型规模的增大,过拟合的风险也随之增加。如何设计有效的正则化策略(如dropout、L2正则化等)来防止过拟合是一个挑战。
什么时候我们考虑使用Post-pretrain?有以下几点:
- 有大量高质量(Billion级tokens)的行业预训练语料;
- 有少量指令集(千条数据),或有自主构建指令集的能力;
- 了解post-pretrain全流程(垂直领域Post-pretrain、通用SFT、垂直领域SFT),且接受平台计费。
希望能在大模型中注入领域知识,增强模型领域专业性,可推荐使用Post-pretrain。
若仅有少量高质量语料或费用敏感用户,建议考虑知识库管理方法,学习领域知识。
二、内在原理
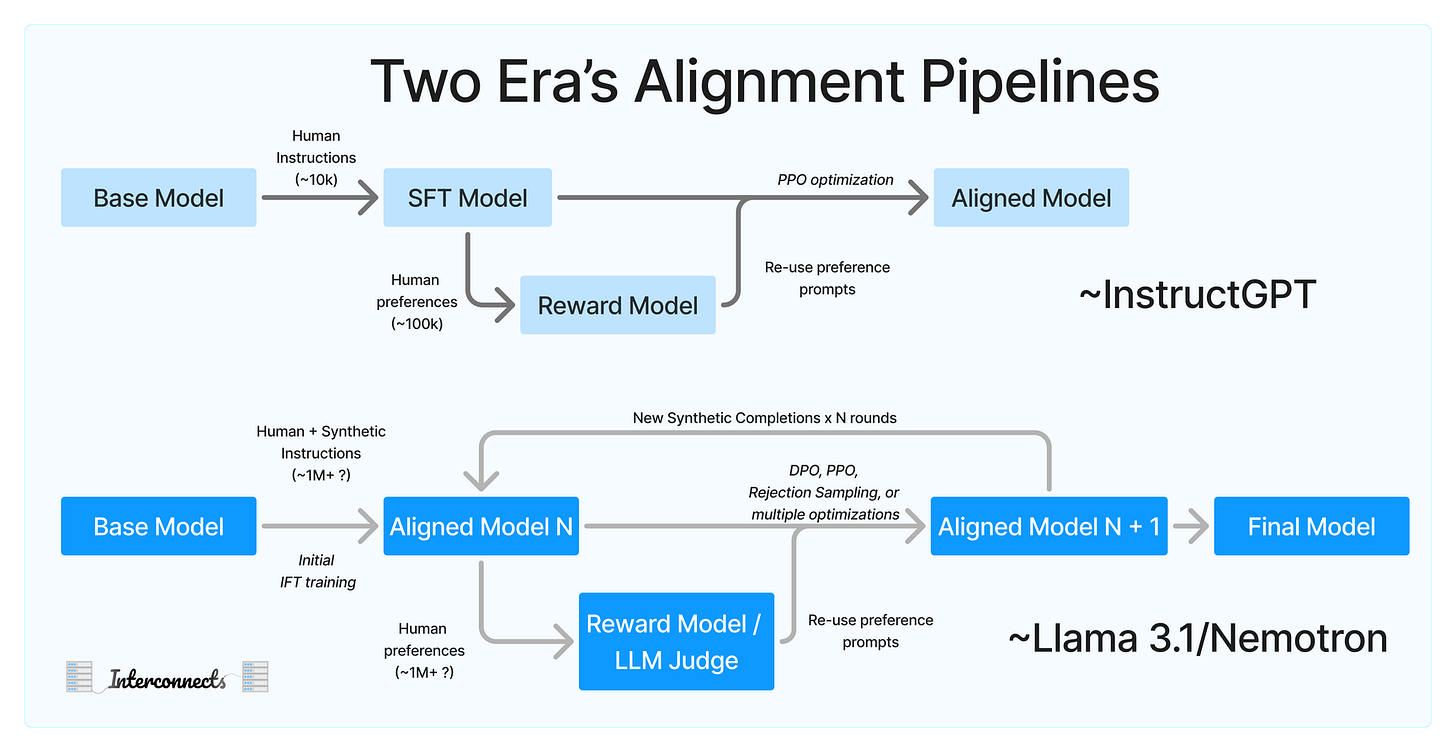
三、实践经验
3.1 数据集层面
3.1.1 数据尽量去重
重复的数据对模型训练没有额外增益,甚至是有害的,而且复制的数据会耗费额外的计算资源,导致训练速度变慢,因此在准备数据的时候需要去除重复的数据。
3.1.2 数据尽量多样化且领域专业性
- 领域专业性数据: 包含领域内常见的专业术语和词汇,以确保模型能够正确理解和使用这些术语。例如,在金融领域,包括金融教材、公司公告、研究报告等;在医疗领域,包括临床文献、病历记录、药品说明书等。
- 多样性和广泛性: 确保语料库涵盖特定领域内的各种场景、主题和任务。这有助于模型更全面地理解领域内的多样性。
3.1.3 数据规模尽量在1B以上
建议至少10亿 tokens 语料。B指Billion,1B tokens即10亿 tokens,约等于13.3亿个汉字。
3.1.4 混合训练提升通用能力
仅用单一领域数据进行模型训练,模型很容易出现灾难性遗忘现象,其他领域的能力出现下降。在领域训练过程中加入通用数据进行混合训练,在增强用户垂类场景能力的同时,保持其原本的通用能力。
- 若仅需要使用指定垂类场景下的能力,可以直接进行训练。
- 若需要模型保持通用能力的同时,提升垂类场景的能力,可以选择数据配比进行混合训练。经验上推荐配比为1:5,即1份领域数据: 5份通用语料。
3.2 训练配置层面
3.2.1 应设置为epoch=1
Epoch等价于数据重复的次数。目前的实验表明,post-pretrain阶段重复的数据对模型训练没有额外增益,甚至是有害的。
3.2.2 选择合适的学习率
学习率(LearningRate)是在梯度下降的过程中更新权重时的超参数,学习率过高会导致模型难以收敛,并且会加快遗忘,同时增加训练的不稳定性。学习率过低则会导致模型收敛速度过慢。
3.3 后续过程

领域Post-pretrain后进行通用SFT训练,提升模型对通用的指令理解和语言跟随能力。通用SFT后进行垂直领域SFT训练,提升模型在垂类领域中的指令理解和语言跟随能力。
参考资料
- 【Paper】The Llama 3 Herd of Models
- 【Blog】A recipe for frontier model post-training
- 【Blog】Post-pretrain最佳实践
- 【Paper】Multilingual BERT Post-Pretraining Alignment
- 【Paper】Exploring the Data Efficiency of Cross-Lingual Post-Training in Pretrained Language Models
- 【Blog】大语言模型 Pre-training 和 Post-training 范式的最新趋势
- 【Blog】关于post-training和一些思考