RAG 幻觉检测方法
未经检查的幻觉在今天的检索增强生成应用中仍然是一个大问题。本研究评估了 4 个公共 RAG 数据集中流行的幻觉检测器。使用 AUROC 和精度/召回率,我们报告了 G-eval、Ragas 和可信语言模型等方法如何能够自动标记不正确的 LLM
响应。
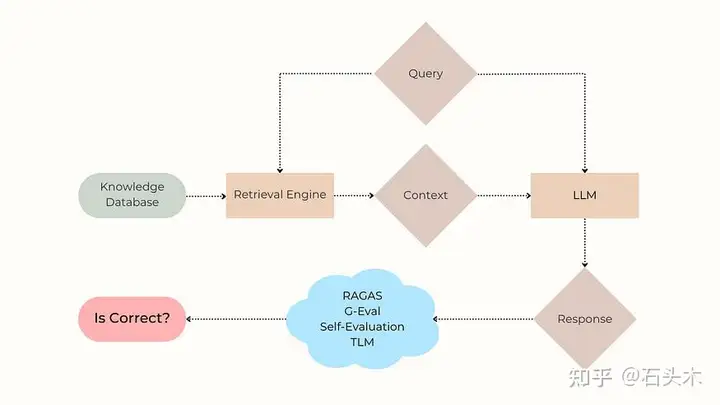
利用各种幻觉检测方法识别 RAG 系统中的 LLM 错误。
问题:RAG 系统中的幻觉和错误
众所周知,大型语言模型(LLM)在被问到训练数据中没有得到很好支持的问题时,会产生不正确的答案。检索增强生成(RAG)系统通过增强 LLM 从特定知识数据库检索上下文和信息的能力来缓解这一问题。虽然组织正在迅速采用 RAG 将LLM的力量与他们自己的专有数据相结合,但幻觉和逻辑错误仍然是一个大问题。在一个广为流传的案例中,一家大型航空公司(加拿大航空公司)输掉了一场官司,因为他们的 RAG 聊天机器人对他们的退款政策的重要细节产生了幻觉。
为了理解这个问题,让我们首先回顾一下 RAG 系统是如何工作的。当用户提出问题(“这是可以退款吗?”)时,检索组件会在知识库中搜索准确响应所需的相关信息。最相关的搜索结果被格式化成一个上下文,该上下文与用户的问题一起馈送到一个 LLM 中,该 LLM 生成呈现给用户的响应。由于企业 RAG 系统通常是复杂的,最终的响应可能是不正确的,原因包括:
- LLM很脆弱,容易产生幻觉。即使检索到的上下文中包含正确的答案,
LLM 也可能无法生成准确的响应,特别是当综合响应需要在上下文中对不同事实进行推理时。 - 由于次优搜索、糟糕的文档分块/格式或知识数据库中缺乏此信息,检索的上下文可能不包含准确响应所需的信息。在这种情况下,LLM 可能仍然会尝试回答问题并产生不正确的回答。
虽然有些人使用“幻觉”一词仅指特定类型的 LLM 错误,但在这里,我们使用这个术语作为错误回答的同义词。对于 RAG 系统的用户来说,重要的是它的答案的准确性和能够信任它们。与评估许多系统属性的 RAG 基准测试不同,我们专门研究:当答案不正确时,不同的检测器如何有效地提醒RAG用户。
由于检索或生成过程中的问题,RAG 答案可能不正确。我们的研究重点是后一个问题,这源于LLM的根本不可靠性。
解决方案:幻觉检测方法
假设现有检索系统已经获取了与用户问题最相关的上下文,我们考虑算法来检测何时不应该信任基于该上下文生成的 LLM 响应。这种幻觉检测算法在跨越医学、法律或金融的高风险应用中至关重要。除了标记不可信的响应以进行更仔细的人工审查外,此类方法还可用于确定何时值得执行更昂贵的检索步骤(例如搜索额外的数据源,重写查询等)。
以下是我们研究中考虑的幻觉检测方法,所有这些方法都基于使用LLM来评估产生的反应:
自我评价(“Self-eval”)是一种简单的技术,要求 LLM 评估生成的答案,并以1-5(李克特量表)的等级对其置信度进行评分。我们利用思维链(CoT)提示来改进这项技术,要求 LLM 在输出最终分数之前解释其置信度。以下是所使用的具体提示模板:
提问:{Question}
回答:{response}
评估你是否有信心给出的答案是对问题的一个好的、准确的回答。
请使用以下 5 分制评分:
1:您对答案解决问题没有信心,答案可能完全偏离主题或与问题无
关 2:您对答案解决问题
的信心较低,对答案的准确性存在疑问和不确定性 3:您对答案解决问题有中等信心,答案似乎相当准确且与主题相关,但有改进的空间。
4:你对答案解决了问题有很高的信心,答案提供了准确的信息,解
决了大部分问题
5:你对答案解决了问题有极大的信心,答案高度准确、相关,并有
效地解决了问题的整体。
输出应严格使用以下模板:Explanation:[提供一个你用来推导评分分数的简短推理],然后在最后一行写上“Score: <rating>”。
G-Eval(来自 DeepEval 包)是一种使用 CoT 自动开发用于评估给定响应质量的多步骤标准的方法。在 G-Eval 论文(Liu et al.)中,该技术在几个基准数据集上与 Human Judgement 相关。质量可以通过各种方式进行测量,如 LLM 提示,在这里我们指定它应该基于响应的事实正确性进行评估。以下是用于 G-Eval 评估的标准:
确定给定上下文的输出是否事实正确。
幻觉度量(来自 DeepEval 软件包)估计幻觉的可能性,即LLM的反应与另一位LLM评估的背景相矛盾/不一致的程度。
ef="https://docs.ragas.io/en/stable/">RAGAS 是一个 RAGAS 特定的,llm 驱动的评估套件,提供各种分数,可用于检测幻觉。我们考虑以下每个 RAGAS 分数,这些分数是通过使用 llm 来估计所需数量而产生的: - 忠实度-答案中被所提供的上下文支持的主张的比例。
- 答案相关度是向量表示与原始问题的平均余弦相似度,以及从答案中生成的三个 llm 问题的向量表示。这里的向量表示是来自 BAAI/ big -base-en 编码器
的嵌入。
- 上下文利用率衡量的是 LLM 响应对上下文的依赖程度。
可信语言模型(trusted Language Model, TLM)是一种评估语言响应可信度
的模型不确定性估计技术。它结合使用自我反思、跨多个采样响应的一致性和概率度量来识别错误、矛盾和幻觉。下面是用于提示 TLM 的提示模板:
仅使用上下文中的信息回答 QUESTION
:{CONTEXT}
QUESTION:{QUESTION}
评价方法
我们将在跨越不同 RAG 应用程序的 4 个公共上下文问答数据集上比较上述幻觉检测方法。
对于我们基准测试中的每个用户问题,现有的检索系统会返回一些相关的上下文。然后将用户查询和上下文输入到生成器 LLM 中(通常伴随着特定于应用程序的系统提示),以便为用户生成响应。每种检测方法都接受{用户查询、检索上下文、 LLM 响应},并返回 0-1 之间的分数,表示出现幻觉的可能性。
为了评估这些幻觉检测器,我们考虑当 LLM 响应不正确与正确时,这些分数取较低值的可靠性。在我们的每个基准测试中,都存在关于每个 LLM 响应正确性的真值注释,我们仅为评估目的保留这些注释。我们基于 AUROC 来评估幻觉检测器,定义为从 LLM 反应不正确的子集中抽取的样本的得分低于从 LLM 反应
正确的子集中抽取的样本的得分的概率。具有较大 AUROC 值的检测器可用于以更高的精度/召回率捕获生产系统中的 RAG 错误。
所有考虑的幻觉检测方法本身都是由 LLM 提供动力的。为了公平比较,我们在所有方法中将这个 LLM 模型修正为 gpt- 40 -mini。
基准测试结果
我们在下面描述了每个基准数据集和相应的结果。这些数据集源于流行的 HaluBench 基准测试套件(我们不包括该套件中的其他两个数据集,因为我们在它们的基础真值注释中发现了重大错误)。
PubMedQA
PubMedQA 是一个基于 PubMed 摘要的生物医学问答数据集。数据集中的每个实例都包含一篇来自 PubMed(医学出版物)摘要的文章,从文章中衍生出一个问题,例如:结核性小肠结肠炎 9 个月的治疗是否足够?,以及生成的答案。
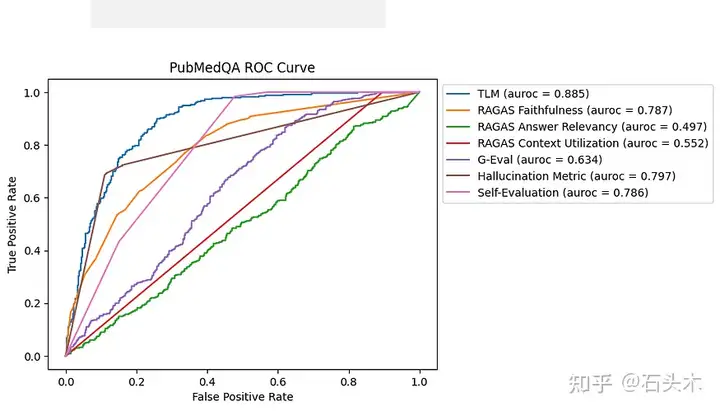
PubMedQA 数据集的 ROC 曲线
在这个基准中,TLM 是辨别幻觉最有效的方法,其次是幻觉度量、自我评估和 RAGAS 忠实度。在后三种方法中,RAGAS 忠实度和幻觉度量更有效地捕获了高
精度的错误答案(RAGAS 忠实度的平均精度为 0.762,幻觉度量的平均精度为 0.761,自我评估的平均精度为 0.702)。
DROP
DROP,即“段落离散推理”,是一个基于维基百科文章的高级问答数据集。 DROP 之所以困难,是因为这些问题需要对文章中的上下文进行推理,而不是简单地提取事实。例如,给定维基百科中描述海鹰队与 49 人队橄榄球比赛中触地得分的文章,一个示例问题是:总码数在 5 码或 5 码以下的触地得分有多少次?要求 LLM 阅
读每一次触地得分,然后将其长度与 5 码的要求进行比较。
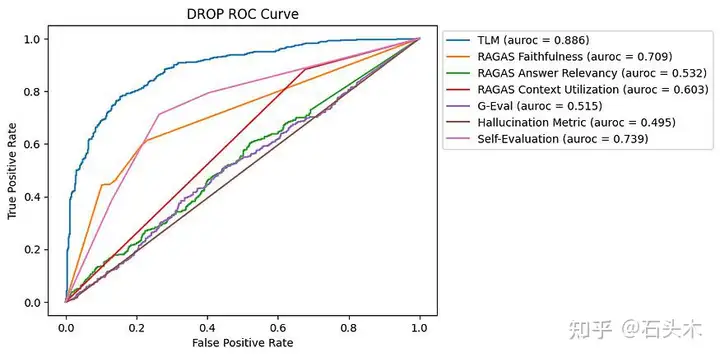
DROP 数据集的 ROC 曲线
由于所需推理的复杂性,大多数方法在检测 DROP 数据集中的幻觉时都面临挑战。
TLM 是该基准最有效的方法,其次是自我评估和 RAGAS 忠实度。
COVID-QA
COVID-QA 是基于与 COVID-19 相关的科学文章的问答数据集。数据集中的每个实例都包括与 COVID-19 相关的科学段落和由此衍生的问题,例如:SARS-COV-2 基
因组序列与 SARS-COV 有多大的相似性?
与 DROP 相比,这是一个更简单的数据集,因为它只需要对文章中的信息进行基本的综合,就可以回答更直接的问题。
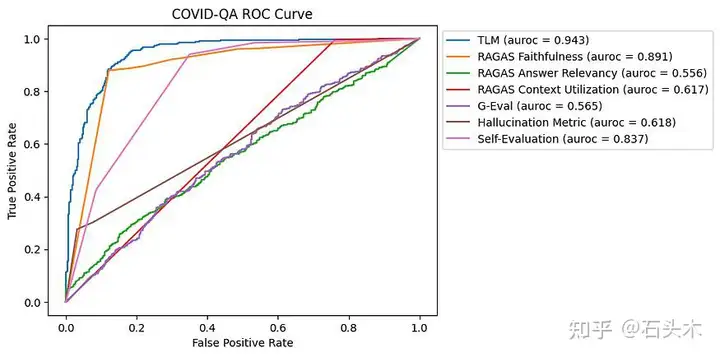
COVID-QA 数据集的 ROC 曲线
在 COVID-QA 数据集中,TLM 和 RAGAS 忠实度在检测幻觉方面都表现出很强的性能。自我评估也表现良好,然而其他方法,包括 RAGAS 答案相关性,G-Eval
和幻觉度量,结果好坏参半。
FinanceBench
FinanceBench 是一个包含有关公开财务报表和上市公司信息的数据集。数据集
中的每个实例都包含一个检索到的大型明文财务信息上下文,以及一个关于该信息的问题,例如:卡夫亨氏(Kraft Heinz) 2015 财年的净营运资金是多少?,以及一个数字答案,如:$2850.00。
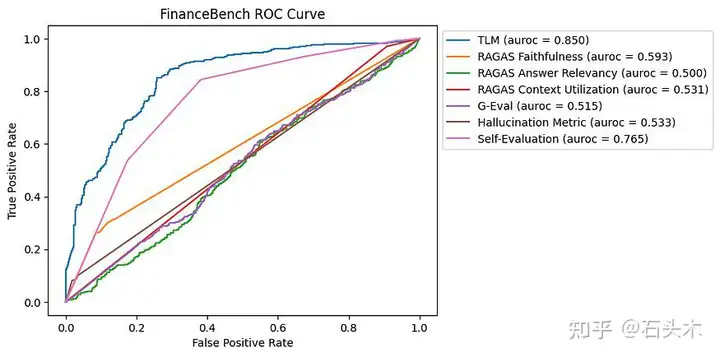
FinanceBench 数据集的 ROC 曲线
对于这个基准,TLM 在识别幻觉方面是最有效的,其次是自我评估。大多数其他方法都在努力提供比随机猜测更显著的改进,突出了这个包含大量上下文和数字数据的数据集中的挑战。
讨论
我们对各种 RAG 基准的幻觉检测方法的评估揭示了以下关键见解:
- 值得信赖的语言模型(trusted Language Model,TLM)一直表现良好,通过自我反思、一致性和概率度量的结合,在识别幻觉方面表现出强大的能力。
- 自我评估在检测幻觉方面表现出一致的有效性,在 LLM 的自我评估可以准确衡量的更简单的环境中尤其有效。虽然它可能并不总是与 TLM 的性能相匹配,但它仍然是评估响应质量的一种直接而有用的技术。
- RAGAS 在响应的准确性与检索上下文密切相关的数据集中表现出稳健
的性能,例如在 PubMedQA 和 COVID-QA 中。它在识别答案中的主张何时不受所提供上下文的支持方面特别有效。然而,根据问题的复杂性,其有效
性是可变的。默认情况下,RAGAS 使用 gpt-3.5-turbo-16k 生成,使用 gpt-4
生成关键的 LLM,这比我们在这里报告的使用 gpt- 40-mini 的 RAGAS 产生的结果更差。在我们的基准测试中,由于其句子解析逻辑,RAGAS 无法在某些示例上运行,我们通过在没有以标点符号结束的答案末尾添加句点(.)来修复这个问题。
4.其他方法,如 G-Eval 和 Hallucination Metric,结果好坏参半,在不同的基准测试中表现出不同的性能。它们的表现不太一致,表明可能需要进一步的改进和适应。
总的来说,TLM、RAGAS 忠实度和自我评估是检测 RAG 应用中幻觉的更可靠的方法。对于高风险的应用,结合这些方法可以提供最好的结果。未来的工作可以探索混合方法和有针对性的改进,以更好地针对特定用例进行幻觉检测。通过整合这些方法,RAG 系统可以实现更高的可靠性,并确保更准确和可信的响应。
标签:RAG,RAGAS,LLM,检测,答案,幻觉,上下文 From: https://www.cnblogs.com/little-horse/p/18412922