国内外语言大模型对比
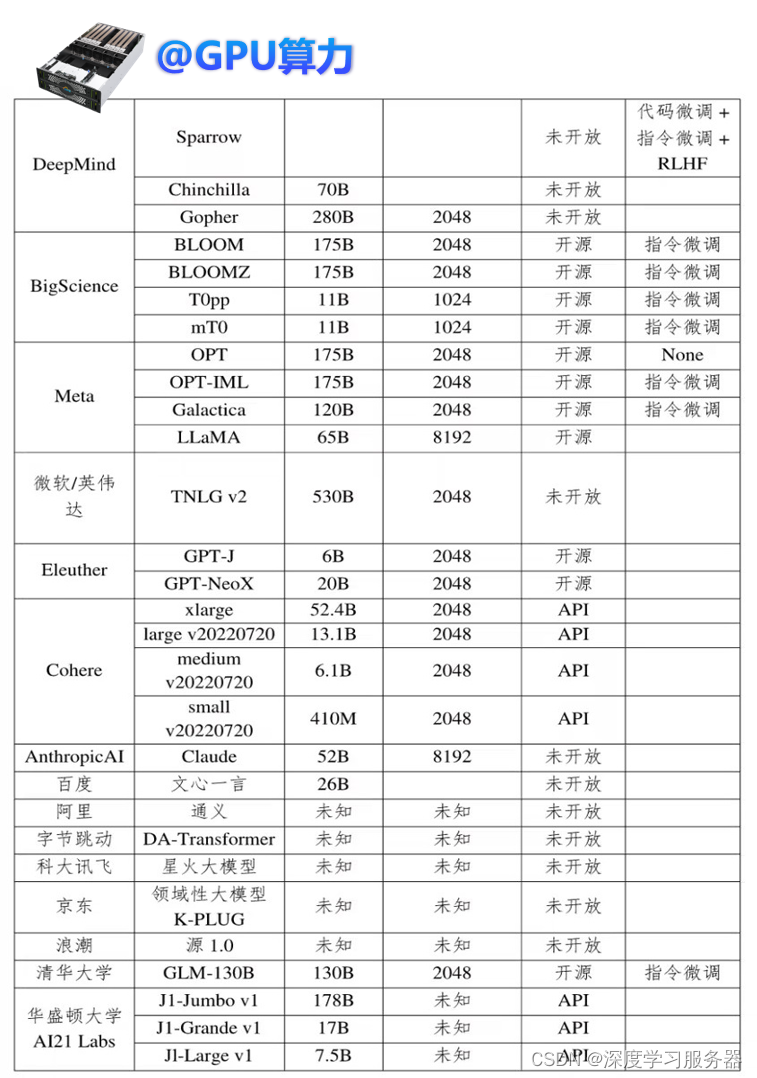
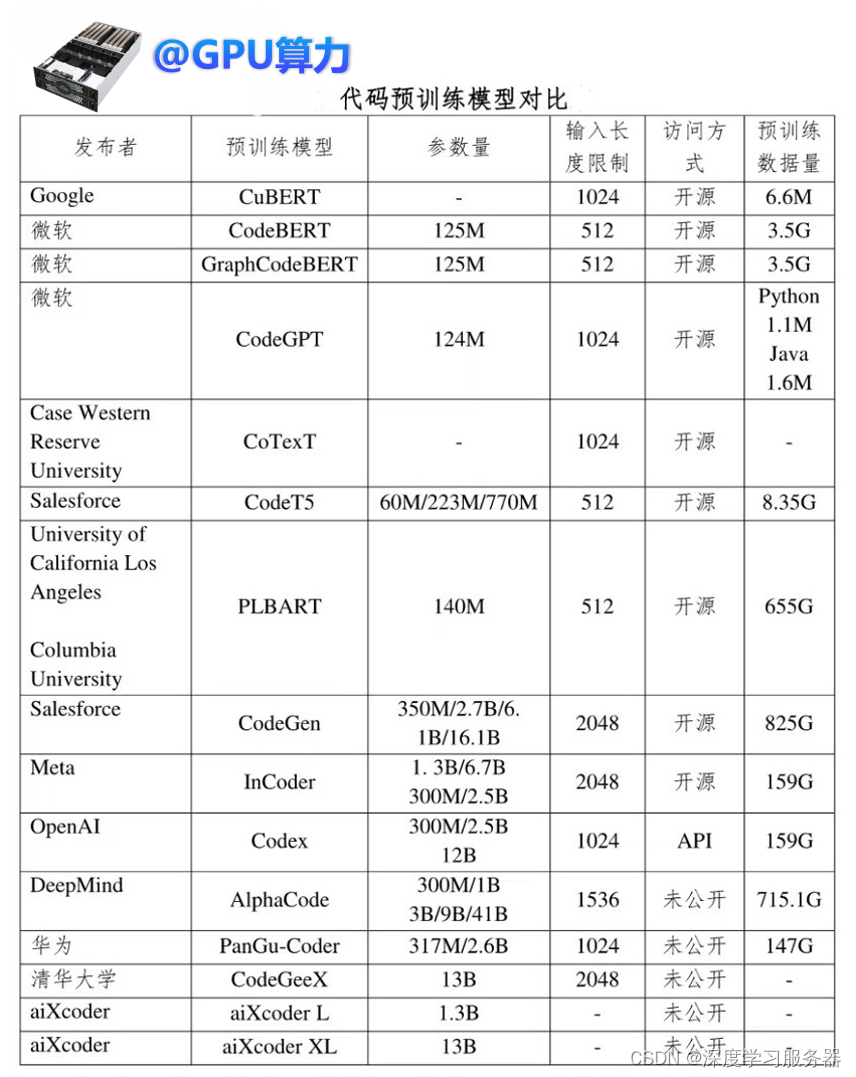
大语言模型技术的快速发展,大语言模型已成为各大互联网公司制造影响力的重要工具。在相互竞争和启发下,越来越多的大型语言模型以应用程序编程接口。图中主要是从大模型文本预训练模型和大模型代码预训练模型的对比。
(ApplicationProgrammingInterface,API)或开源形式被访问。从参数量、输入长度限制、访问方式以及模型微调方式等多个方面对比了目前较为知名的文本大规模预训练语言模型。
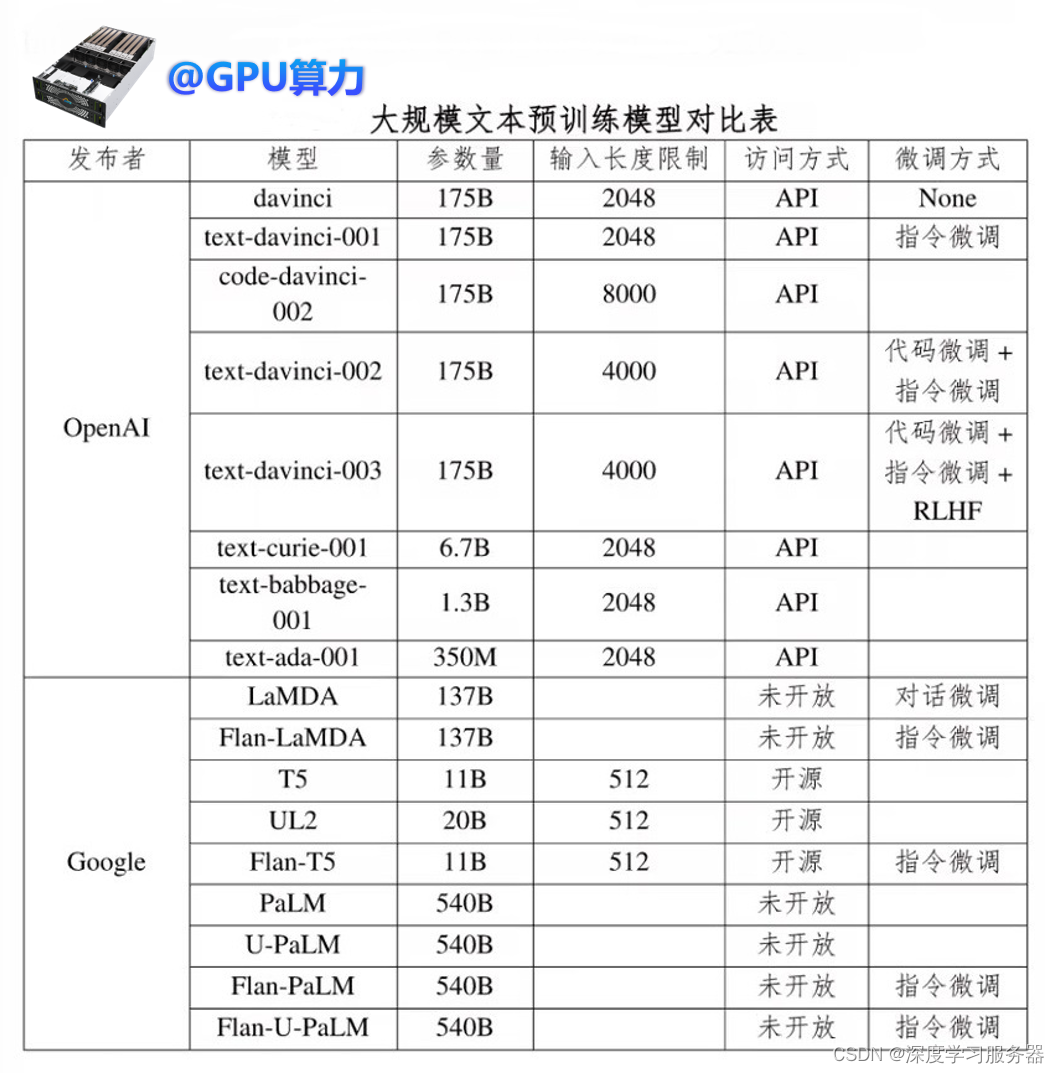
目前大多数文本大型语言模型并没有被开源,一般只能通过 API 调用来访问,有些甚至完全无法获取。其次,在这一领域,OpenAI 和Google 显然占据先发优势和市场主导地位,它们不仅推动了文本大型语言模型的发展,而且逐渐形成了家族式的大型模型集群。最后,除了文本模型之外,代码预训练模型也成为一个新的研究热点,这些模型在代码相关任务上已经展示了出色的性能。
技术能力分析:专家判断当前国内技术比 ChatGPT 主要差在大模型环节,包括清洗、标注、模型结构设计、训练推理的技术积累。
ChatGPT 背后是文本/跨模态大模型、多轮对话、强化学习等多技术的融合创新,而国内大部分科技企业、科研院所多聚焦垂直应用,缺乏多技术融合创新能力。从落地应用来看,国内头部企业均表示已开展相关技术研发或部分模型进入内测阶段,但仍未出现与ChatGPT 抗衡的大模型产品。加之大模型的训练成本较高,技术应用面临着亿元级研发投入和海量训练试错,国内企业投入严重不足研发推广和产业落地整体落后于海外。