通过探索看似不相关的大语言模型(LLM)架构之间的潜在联系,我们可能为促进不同模型间的思想交流和提高整体效率开辟新的途径。
尽管Mamba等线性循环神经网络(RNN)和状态空间模型(SSM)近来备受关注,Transformer架构仍然是LLM的主要支柱。这种格局可能即将发生变化:像Jamba、Samba和Griffin这样的混合架构展现出了巨大的潜力。这些模型在时间和内存效率方面明显优于Transformer,同时在能力上与基于注意力的LLM相比并未显著下降。
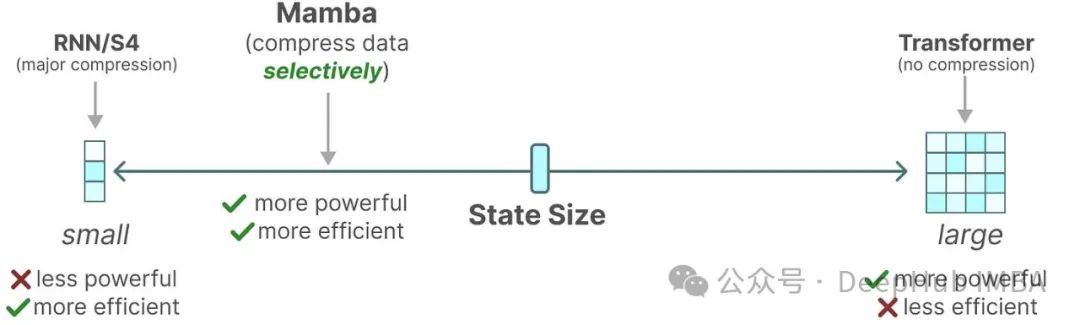
近期研究揭示了不同架构选择之间的深层联系,包括Transformer、RNN、SSM和matrix mixers,这一发现具有重要意义,因为它为不同架构间的思想迁移提供了可能。本文将深入探讨Transformer、RNN和Mamba 2,通过详细的代数分析来理解以下几点:
- Transformer在某些情况下可以视为RNN(第2节)
- 状态空间模型可能隐藏在自注意力机制的掩码中(第4节)
- Mamba在特定条件下可以重写为掩码自注意力(第5节)
这些联系不仅有趣,还可能对未来的模型设计产生深远影响。
https://avoid.overfit.cn/post/cc1b1bb7816b412790e9224484cd5b56
标签:Transformer,架构,RNN,模型,SSM,LLM From: https://www.cnblogs.com/deephub/p/18404068