-
官方文档:https://www.selenium.dev/zh-cn/documentation/
-
WebDriver 通过驱动程序向浏览器传递命令, 然后通过相同的路径接收信息。
远程通信也可以使用 Selenium Server 或 Selenium Grid 进行,这两者依次与主机系统上的驱动程序进行通信
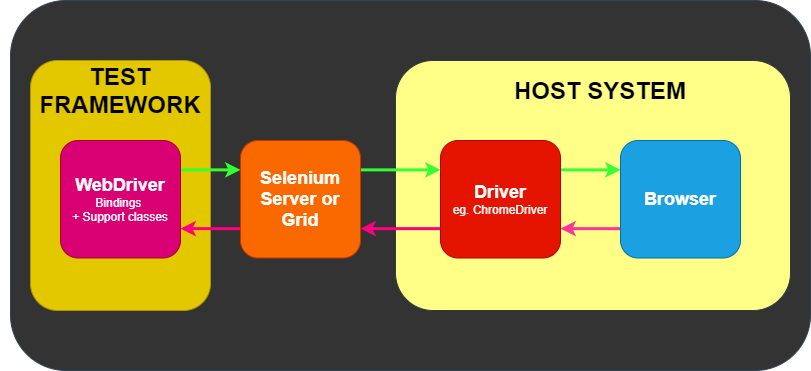
WebDriver 对测试一窍不通:它不知道如何比较事物、 断言通过或失败,当然它也不知道报告或 Given/When/Then 语法。
所以需要一个与绑定语言相匹配的测试框架,比如. NET 的 NUnit, Java 的 JUnit, Ruby 的 RSpec 等等。
测试框架负责运行和执行 WebDriver 以及测试中相关步骤。因此,您可以认为它看起来类似于下图。
-
八个基本组成部分
-
使用驱动实例开启会话
driver = webdriver.Chrome() -
导航到网页
driver.get("https://www.selenium.dev/selenium/web/web-form.html") -
请求浏览器信息
title = driver.title -
建立等待策略
driver.implicitly_wait(0.5)它的作用是让 WebDriver 在尝试查找元素时,如果没有立即找到,会在接下来的 0.5 秒内持续轮询查找,直到找到元素或者超时。
通常情况下,轮询时间的具体值是由 WebDriver 的内部实现决定的,并且对于使用者来说是不可配置的。在这个例子中,WebDriver 会在 0.5 秒的超时时间内,按照其内部设定的轮询频率不断检查元素是否出现。
-
查找元素
text_box = driver.find_element(by=By.NAME, value="my-text") submit_button = driver.find_element(by=By.CSS_SELECTOR, value="button") -
操作元素
text_box.send_keys("Selenium") submit_button.click() -
获取元素信息
text = message.text -
结束会话
driver.quit()
-
-
一个小示例
from selenium import webdriver from selenium.webdriver.common.by import By def test_eight_components(): driver = webdriver.Chrome() driver.get("https://www.selenium.dev/selenium/web/web-form.html") title = driver.title assert title == "Web form" driver.implicitly_wait(0.5) text_box = driver.find_element(by=By.NAME, value="my-text") submit_button = driver.find_element(by=By.CSS_SELECTOR, value="button") text_box.send_keys("Selenium") submit_button.click() message = driver.find_element(by=By.ID, value="message") value = message.text assert value == "Received!" driver.quit() -
驱动选项类Options-pageLoadStrategy-页面加载策略
-
normal (默认值)
WebDriver一直等到 load 事件触发并返回.
options.page_load_strategy = 'normal' driver = webdriver.Chrome(options=options)-
Window: load event
当整个页面(包括所有相关资源,如样式表、脚本、iframe 和图像,但不包括那些延迟加载的资源)加载完成时,会触发“load”事件。
-
-
eager
WebDriver一直等到 DOMContentLoaded 事件触发并返回.
options.page_load_strategy = 'eager' driver = webdriver.Chrome(options=options)-
DOMContentLoaded 事件
当 HTML 文档已被完全解析,并且所有延迟脚本已下载并执行时,会触发 DOMContentLoaded 事件。它不会等待诸如图片、子框架和异步脚本之类的其他内容完成加载。
-
-
none
WebDriver 仅等待初始页面已下载.
options.page_load_strategy = 'none' driver = webdriver.Chrome(options=options)
-
-
驱动服务类Service
-
驱动程序端口
如果希望驱动程序在特定端口上运行, 您可以在启动时指定端口号, 如下所示:
service = webdriver.ChromeService(port=1234) -
日志
日志记录功能因浏览器而异. 大多数浏览器都允许您指定日志的位置和级别.:
service = webdriver.ChromeService(service_args=['--log-level=DEBUG'], log_output=subprocess.STDOUT)service = webdriver.ChromeService(log_output=log_path) -
浏览器日志是浏览器在运行过程中记录的各种信息和事件的记录。
它可以包含多种类型的信息,例如: 1. 页面加载的相关信息:包括加载的起始时间、结束时间、是否有错误等。 2. 脚本执行的情况:如 JavaScript 脚本的执行错误、警告等。 3. 网络请求和响应:包括请求的 URL、请求方法、响应状态码、响应时间等。 4. 浏览器的配置和设置更改。 5. 插件和扩展的相关活动。 通过查看浏览器日志,开发人员可以诊断网页加载和运行中的问题,优化性能,以及了解用户与浏览器的交互情况。
不同的浏览器通常提供不同的方式来查看和获取这些日志信息。
-
-
隐式等待
Selenium 有一种内置的自动等待元素的方法,称为隐式等待。
这是一个全局设置,适用于整个会话中的每个元素定位调用。默认值是 0,这意味着如果找不到元素,它将立即返回错误。如果设置了隐式等待,在返回错误之前,驱动程序将等待所提供的值的持续时间。请注意,一旦定位到元素,驱动程序将返回元素引用,并且代码将继续执行,所以较大的隐式等待值不一定会增加会话的持续时间。
driver.implicitly_wait(2) -
显式等待
显式等待是添加到代码中的循环,它在应用程序中轮询特定条件,在该条件评估为真时才退出循环并继续执行代码中的下一个命令。如果在指定的超时值之前条件未满足,代码将给出超时错误。由于应用程序有很多方式无法处于期望的状态,所以显式等待是在每个需要的地方指定确切等待条件的绝佳选择。另一个不错的特性是,默认情况下,Selenium 的 Wait 类会自动等待指定的元素存在。
-
显式等待和隐式等待的区别
显式等待:
- 非常有针对性,可以针对特定的元素或条件进行等待。
- 可以根据不同的元素和情况设置不同的等待条件和超时时间。
- 例如,可以等待某个特定元素出现后再进行下一步操作,或者等待页面加载完成特定的部分。
隐式等待:
- 是一种通用的等待方式,适用于所有元素的查找。
- 一旦设置,在整个 WebDriver 会话期间都会生效,对所有元素的查找操作都遵循这个等待时间。
-
文件上传
因为 Selenium 无法与文件上传对话框进行交互,所以它提供了一种无需打开对话框即可上传文件的方法。如果元素是一个类型为“file”的输入元素,你可以使用
send_keys方法来发送要上传的文件的完整路径。file_input = driver.find_element(By.CSS_SELECTOR, "input[type='file']") file_input.send_keys(upload_file) driver.find_element(By.ID, "file-submit").click() -
查询器
-
Evaluating the Shadow DOM
隐藏在一个元素内部的封装 DOM 树
shadow_host = driver.find_element(By.CSS_SELECTOR, '#shadow_host') shadow_root = shadow_host.shadow_root shadow_content = shadow_root.find_element(By.CSS_SELECTOR, '#shadow_content') -
Find Elements From Element
element = driver.find_element(By.TAG_NAME, 'div') # Get all the elements available with tag name 'p' elements = element.find_elements(By.TAG_NAME, 'p') for e in elements: print(e.text) -
Get Active Element
它用于跟踪(或)找到在当前浏览上下文中具有焦点的 DOM 元素。
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get("https://www.google.com") driver.find_element(By.CSS_SELECTOR, '[name="q"]').send_keys("webElement") # Get attribute of current active element attr = driver.switch_to.active_element.get_attribute("title") print(attr)
-
-
交互
-
点击
# Navigate to url driver.get("https://www.selenium.dev/selenium/web/inputs.html") # Click on the element driver.find_element(By.NAME, "color_input").click() -
发送键位与清除
# Navigate to url driver.get("https://www.selenium.dev/selenium/web/inputs.html") # Clear field to empty it from any previous data driver.find_element(By.NAME, "email_input").clear() # Enter Text driver.find_element(By.NAME, "email_input").send_keys("[email protected]" )
-
-
定位器

-
CSS选择器
CSS 选择器(CSS Selector)是一种用于选择 HTML 或 XML 文档中特定元素的模式。它是 CSS(层叠样式表)的重要组成部分,允许开发人员指定要应用样式的元素。
一、基本类型的 CSS 选择器
- 元素选择器: - 通过元素名称来选择元素。例如,
p选择所有<p>段落元素,div选择所有<div>元素。 - 类选择器: - 以
.开头,后面跟着类名。选择具有特定类名的元素。例如,.my-class选择所有具有class="my-class"的元素。 - ID 选择器: - 以
#开头,后面跟着 ID 名称。选择具有特定 ID 的单个元素。例如,#my-id选择具有id="my-id"的元素。
二、组合和高级选择器
- 后代选择器: - 用于选择作为特定元素后代的元素。例如,
div p选择所有在<div>元素内部的<p>元素。 - 子选择器: - 选择直接子元素。以
>符号表示。例如,div > p选择所有直接在<div>元素下的<p>元素。 - 相邻兄弟选择器: - 选择紧跟在指定元素后面的兄弟元素。以
+符号表示。例如,h1 + p选择紧跟在<h1>元素后面的第一个<p>元素。 - 通用兄弟选择器: - 选择指定元素后面的所有兄弟元素。以
~符号表示。例如,h1 ~ p选择<h1>元素后面的所有<p>元素。
三、属性选择器
-
根据属性值选择元素:
[attribute=value]:选择具有特定属性和值的元素。例如,[type="text"]选择所有type="text"的元素。[attribute^=value]:选择属性值以特定值开头的元素。例如,[href^="https"]选择所有以“https”开头的href属性的元素。[attribute$=value]:选择属性值以特定值结尾的元素。例如,[href$=".pdf"]选择所有以“.pdf”结尾的href属性的元素。[attribute*=value]:选择属性值包含特定值的元素。例如,[alt*="image"]选择所有alt属性包含“image”的元素。
- 元素选择器: - 通过元素名称来选择元素。例如,
-
xpath
driver = webdriver.Chrome() driver.find_element(By.XPATH, "//input[@value='f']") -
Available relative locators
Above
If the email text field element is not easily identifiable for some reason, but the password text field element is, we can locate the text field element using the fact that it is an “input” element “above” the password element.
email_locator = locate_with(By.TAG_NAME, "input").above({By.ID: "password"})Below
password_locator = locate_with(By.TAG_NAME, "input").below({By.ID: "email"})Left of
cancel_locator = locate_with(By.TAG_NAME, "button").to_left_of({By.ID: "submit"})Right of
submit_locator = locate_with(By.TAG_NAME, "button").to_right_of({By.ID: "cancel"})Near
email_locator = locate_with(By.TAG_NAME, "input").near({By.ID: "lbl-email"})Chaining relative locators
submit_locator = locate_with(By.TAG_NAME, "button").below({By.ID: "email"}).to_right_of({By.ID: "cancel"}) -
信
是否显示
# Navigate to the url driver.get("https://www.selenium.dev/selenium/web/inputs.html") # Get boolean value for is element display is_email_visible = driver.find_element(By.NAME, "email_input").is_displayed()是否启用
# Navigate to url driver.get("https://www.selenium.dev/selenium/web/inputs.html") # Returns true if element is enabled else returns false value = driver.find_element(By.NAME, 'button_input').is_enabled()是否被选定
# Navigate to url driver.get("https://www.selenium.dev/selenium/web/inputs.html") # Returns true if element is checked else returns false value = driver.find_element(By.NAME, "checkbox_input").is_selected()获取元素标签名
# Navigate to url driver.get("https://www.selenium.dev/selenium/web/inputs.html") # Returns TagName of the element attr = driver.find_element(By.NAME, "email_input").tag_name位置和大小
# Navigate to url driver.get("https://www.selenium.dev/selenium/web/inputs.html") # Returns height, width, x and y coordinates referenced element res = driver.find_element(By.NAME, "range_input").rect获取元素CSS值
# Navigate to Url driver.get('https://www.selenium.dev/selenium/web/colorPage.html') # Retrieves the computed style property 'color' of linktext cssValue = driver.find_element(By.ID, "namedColor").value_of_css_property('background-color')文本内容
# Navigate to url driver.get("https://www.selenium.dev/selenium/web/linked_image.html") # Retrieves the text of the element text = driver.find_element(By.ID, "justanotherlink").text获取特性或属性
# Navigate to the url driver.get("https://www.selenium.dev/selenium/web/inputs.html") # Identify the email text box email_txt = driver.find_element(By.NAME, "email_input") # Fetch the value property associated with the textbox value_info = email_txt.get_attribute("value") -
浏览器导航
driver.get("https://www.selenium.dev") driver.get("https://www.selenium.dev/selenium/web/index.html") title = driver.title assert title == "Index of Available Pages" # 按下浏览器的后退按钮: driver.back() title = driver.title assert title == "Selenium" # 按下浏览器的前进键: driver.forward() title = driver.title assert title == "Index of Available Pages" # 刷新 driver.refresh() title = driver.title assert title == "Index of Available Pages" -
切换窗口或标签页
from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # 启动驱动程序 with webdriver.Firefox() as driver: # 打开网址 driver.get("https://seleniumhq.github.io") # 设置等待 wait = WebDriverWait(driver, 10) # 存储原始窗口的 ID original_window = driver.current_window_handle # 检查一下,我们还没有打开其他的窗口 assert len(driver.window_handles) == 1 # 单击在新窗口中打开的链接 driver.find_element(By.LINK_TEXT, "new window").click() # 等待新窗口或标签页 wait.until(EC.number_of_windows_to_be(2)) # 循环执行,直到找到一个新的窗口句柄 for window_handle in driver.window_handles: if window_handle != original_window: driver.switch_to.window(window_handle) break # 等待新标签页完成加载内容 wait.until(EC.title_is("SeleniumHQ Browser Automation")) -
屏幕截图
from selenium import webdriver driver = webdriver.Chrome() # Navigate to url driver.get("http://www.example.com") # Returns and base64 encoded string into image driver.save_screenshot('./image.png') driver.quit() -
元素屏幕截图
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() # Navigate to url driver.get("http://www.example.com") ele = driver.find_element(By.CSS_SELECTOR, 'h1') # Returns and base64 encoded string into image ele.screenshot('./image.png') driver.quit()