本文,我们将发布 Docmatix - 一个超大的文档视觉问答 (DocVQA) 数据集,比之前的数据集大 100 倍。当使用 Docmatix 微调 Florence-2 时,消融实验显示 DocVQA 任务的性能提高了 20%。

Docmatix 数据集样本示例
缘起于 丹鼎 (The Cauldron) 的开发,丹鼎包含了 50 个数据集,旨在用于视觉语言模型 (VLM) 的微调,我们的 Idefics2 就是由此训得。在丹鼎的开发过程中,我们发现缺乏大规模文档视觉问答 (DocVQA) 数据集。Idefics2 依赖的视觉问答数据集主要是 DocVQA,其中仅包含 1 万张图像以及 3 万 9 千对问答 (Q/A)。基于其以及其他数据集微调出的开源模型在性能上与闭源模型差距很大。
为了解决这一问题,我们很高兴推出 Docmatix,这是一个 DocVQA 数据集,包含 240 万张图像以及源自 130 万个 PDF 文档的 950 万对问答。与之前的数据集相比,规模扩大了 240 倍。
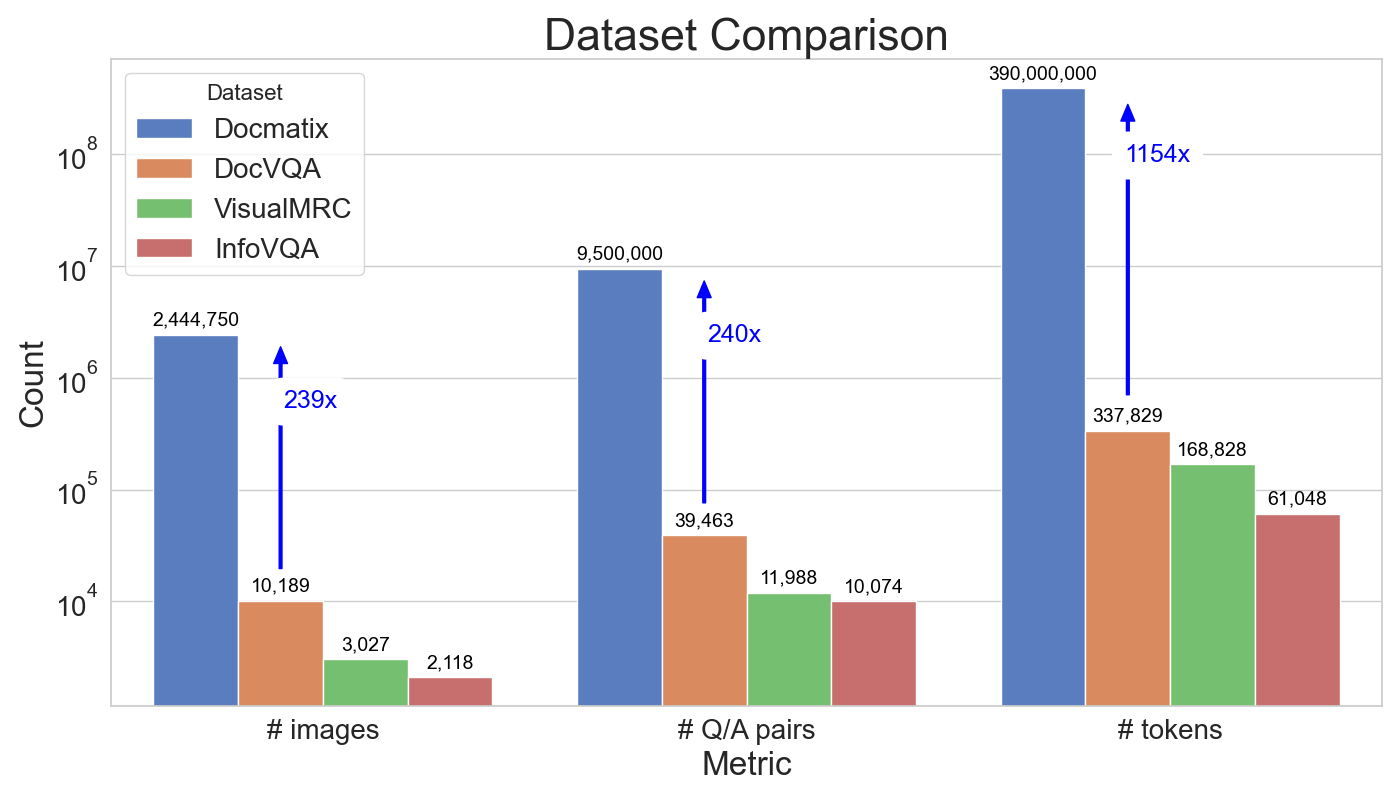
Docmatix 和其它 DocVQA 数据集的对比
你可以通过下面的页面自由探索数据集并查阅 Docmatix 中包含的文档类型以及问答对。
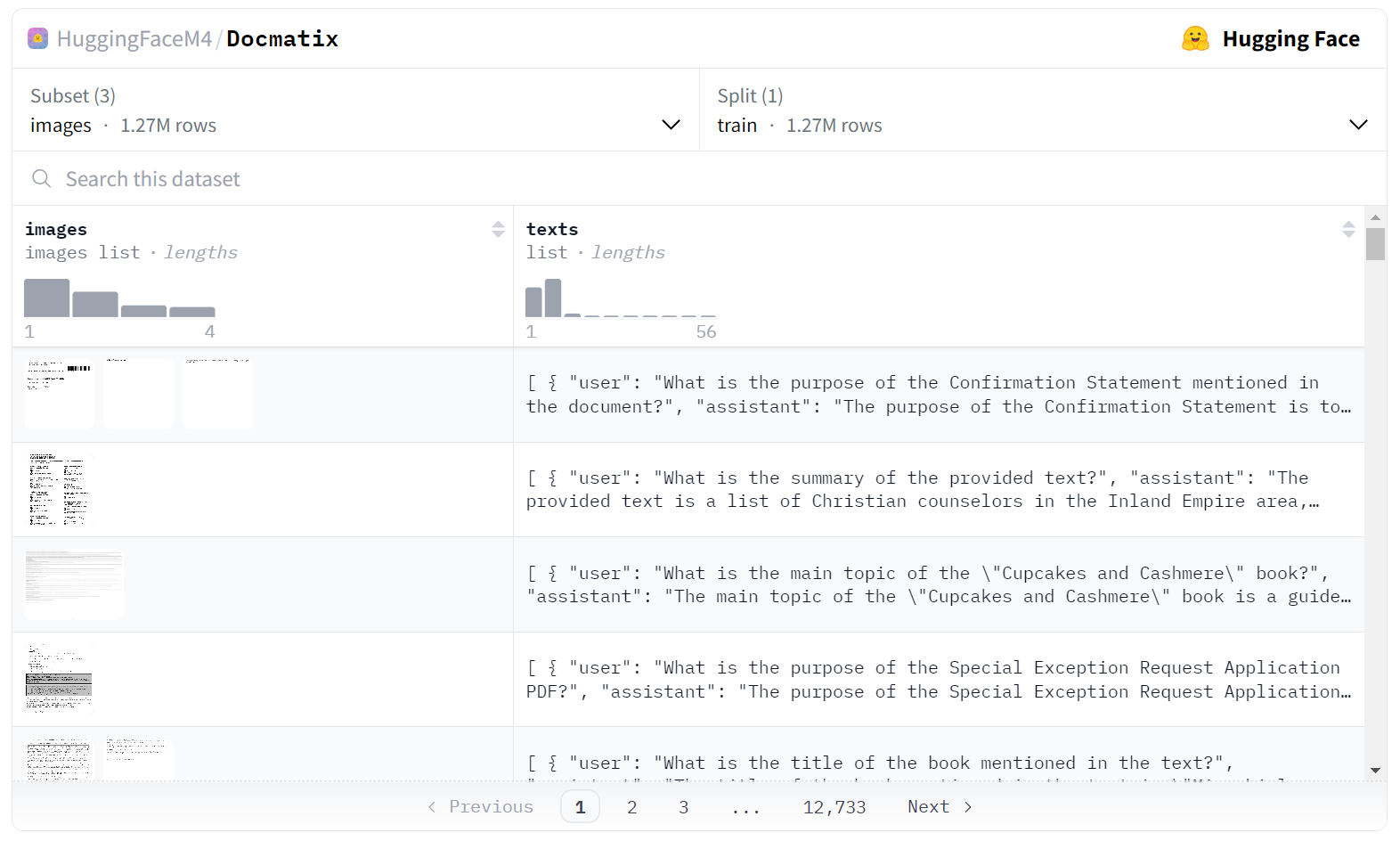
Docmatix 是基于 PDFA - 一个包含 210 万个 PDF 的 OCR 数据集 生成的。我们从 PDFA 中转录出文本,然后用 Phi-3-small 模型生成 Q/A 对。为了确保数据集的质量,我们对模型生成的回答进行了过滤,丢弃了 15% 被识别为幻觉的 Q/A 对。另外,我们还使用正则表达式来检测代码并删除了包含关键字 “unanswerable” 的答案。Docmatix 数据集中的每一行对应于一个 PDF 文件,我们将 PDF 转换为分辨率为 150 dpi 的图像,并将处理后的图像上传至 Hugging Face Hub 以便于访问。所有样本的原始 PDF 都可以溯源至 PDFA 数据集,以最大程度提供透明度和可靠性。但考虑到将这么多 PDF 转换为图像会消耗不少资源,为方便数据集的用户起见,数据集中的样本用的是处理后的图像。
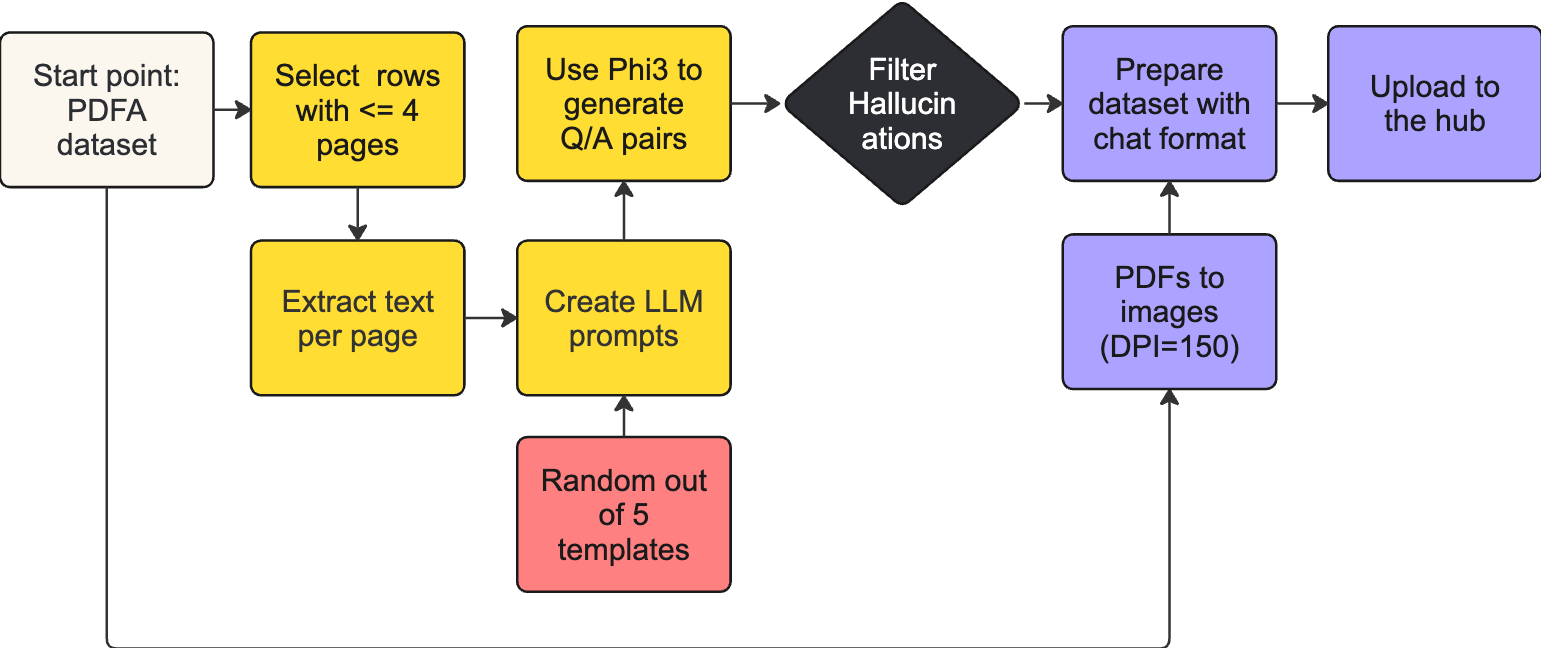
生成 Docmatix 的数据处理流水线
我们先处理了一小批数据集,并对其进行多次消融研究以对提示进行优化。我们的目标是每页生成大约 4 对问答。太多的话,它们之间会有很大的重叠,太少的话,则说明当前页的内容中细节较少。此外,我们的目标是让生成的答案与人类回答相似,避免过短或过长的答案。我们还比较重视问题的多样性,以确保尽量减少重复问题。有趣的是,当我们引导 Phi-3 模型 根据文档中的具体信息提出问题时 (例如,“某甲的头衔是什么?”),问题几乎没有重复。下图展示了我们得到的一些关键统计分析数据:

从提示的维度分析 Docmatix
为了评估 Docmatix 的质量,我们使用 Florence-2 模型进行了消融实验。我们训练了两个版本的模型以进行比较。第一个版本在 DocVQA 数据集上训练数个 epoch。第二个版本先在 Docmatix 上训练 1 个 epoch (仅使用 20% 的图像、4% 的 Q/A 对),然后再在 DocVQA 上训练 1 个 epoch,以确保模型的输出格式符合 DocVQA 评估的要求。结果很明显: 先对 Docmatix 进行微调可带来近 20% 的相对指标提升。此外,所得的 0.7B Florence-2 模型的性能仅比基于混合训练集训练的 8B Idefics2 模型差 5%,要知道从模型尺寸上来看 8B 可以比 0.7B 大得远不止 5%。
| 数据集 | DocVQA 上的 ANSL 值 | 模型尺寸 |
|---|---|---|
| 在 DocVQA 上微调的 Florence 2 | 60.1 | 700M |
| 在 Docmatix 上微调的 Florence 2 | 71.4 | 700M |
| Idefics2 | 74.0 | 8B |
总结
本文介绍了 Docmatix,一个用于 DocVQA 的超大数据集。我们的结果表明,使用 Docmatix 在微调 Florence-2 时,我们可以将 DocVQA 性能提高 20%。该数据集有助用户弥合开源 VLM 相对于闭源 VLM 的性能差距。我们鼓励开源社区利用 Docmatix 去训练新的的 DocVQA 模型,创造新的 SOTA!我们迫不及待地想在
标签:Docmatix,DocVQA,超大,文档,问答,Florence,数据,模型 From: https://www.cnblogs.com/huggingface/p/18388820