一、传统监控系统的盲区,如何打造业务状态监控。
在系统架构设计中非常重要的一环是要做数据监控和数据最终一致性,关于一致性的补偿,已经由算法部的大佬总结过就不在赘述。这里主要讲如何去补偿?补偿的方案哪些?这就引出来数据监控系统了。有小伙伴会问了,为什么业务状态监控系统可以做补偿?别急,往下看。
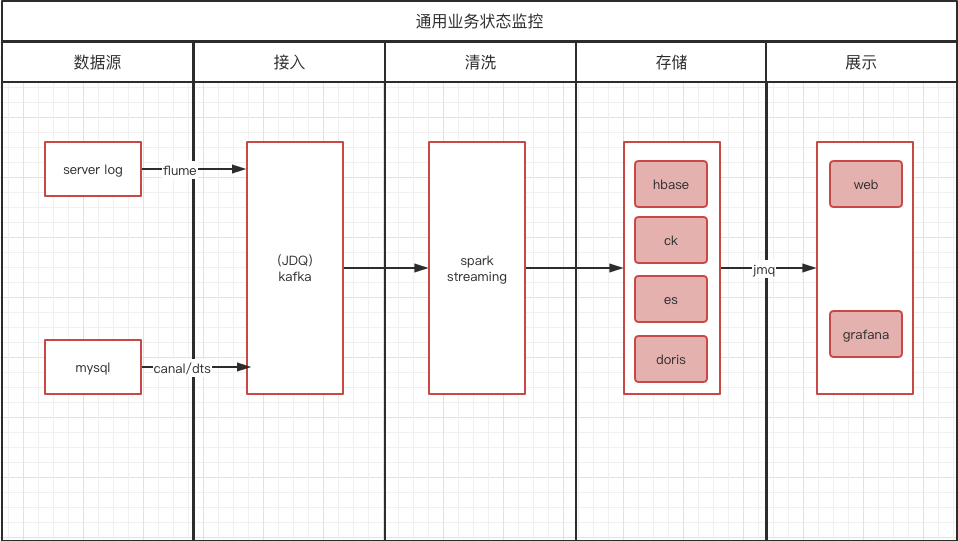
传统监控系统分为两种,系统监控和业务监控。系统监控有并发量监控、异常监控、调用链监控、端口监控、zabbix 监控、http监控等。业务监控是指用以监控业务数据是否正常,用户需要进行业务埋点进行数据采集。业务监控底层常规依赖日志上报系统,接入业务监控之前先申请接入日志上报系统。如图1
(图1)
从业务监控时序图中看到一般分为五步:
1.数据埋点,业务端埋点后上报的日志,也可以是mysql。日志文件最后通过flume或者bin log上报。 2.数据收集,通常都通过kafka做数据采集。 3.数据清洗,一般都是在ods层用spark-streaming进行分流,清洗。 4.数据存储,数据分流后会存储到dw层,最后落到各种库里面。 5.数据展示,开源的很多,用的多还是grafana,还有数据大屏等。看到这里大家有没有感觉到一丝困惑?有没有感觉跟链路追踪傻傻分不清楚?业务监控和链路追踪的区别就成了侵入式埋点上报和无侵入式agent抓取上报。这仿佛没了灵魂,于是我去问了下AI,AI给出的答案是“业务监控则是一种用于监测业务指标和关键业务流程的技术,目的在于实现对业务运营状况的实时了解和快速响应”。
二、新型业务监控,hunter-monitor的诞生。
站在巨人的肩膀上开始俯视全局,发现真实的需求:
1.报警能力,围绕业务,运营场景。设置各种预警的阈值。达到阈值后要及时发出响应。 2.数据计算和数据统计能力,根据埋点计算整条链路上,每个节点的异常数据。帮做统计和输出。 3.触达能力,内部聊天工具,邮件,必要时电话,短信,微信都要跟上。 4.数据归档能力,数据归档是为了兜底,做最终一致性。是为了异常时做数据比对。 5.数据自理能力,在AI时代,必须要有自动消化处理的能力。 6.报警规则能力,“树”的应用,要把整个系统链路串联起来的能力。
我们是京东保险平台研发部,承接商城的端延保订单的流量。流量全是交易数据。交易数据是不允许丢失。因此我们孕育出自己的业务监控系统“监控猎手 (hunter-monitor)” 简称hm。hm已经实现了以上6种能力。在出现问题时,会第一时间通知业务和产品。还提供了异常数据统计、节点数据计算、回溯、补偿等能力。业务或产研发需要时,可以在平台上做数据对比。还具备了延展能力,如可以对接jsf接口。来实现自动补偿能力。
hm业务状态监控的核心能力是:数据串联和数据计算。是可以把业务整条链路在系统中的埋点,已线性串联起来。并展示出每个节点的异常状态数据。最终消化掉异常数据。
三、三连问:谁适合接入?如何使用?有接入的实例么?
1、谁适合接入
接入保险SaaS工作台的系统都可以接入业务状态监控。没介入的呢?只需要在保险SaaS工作台中,创建租户便可以使用hm业务状态监控。
2、如何使用
2.1 监控接入
接入hm只要简单的三步即可,创建规则,创建报警规则,业务接入埋点。创建方式和常规的业务监控系统一样。
2.2 数据处理
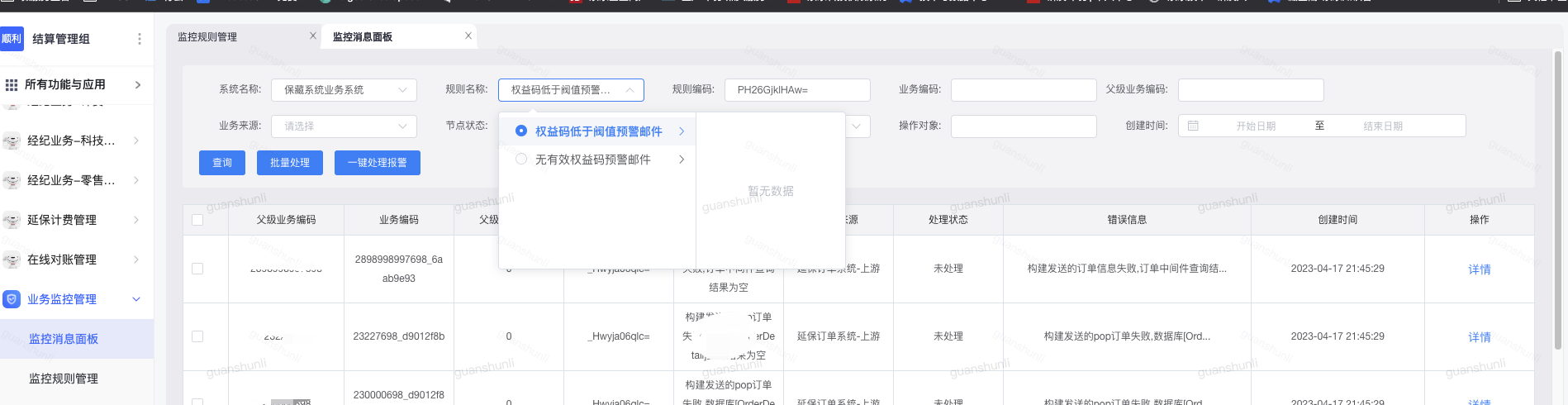
异常数据最终需要处理掉。在监控列表中可以一键处理异常数据
2.3 定制化
我们支持触达内容定制化,异常数据处理方式定制化,异常数据统计定制化。可以调用业务系统jsf接口完成自动处理,也可以根据需求出异常数据报告,更可以深度帮助业务方定制系统链路中的异常处理。hm已应用到延保交易全链路系统,履约平台,业财一体平台和保险abTest等系统。我们来看几个延保业务的接入的场景。
3、实战!延保业务接入场景
3.1 大屏展示:
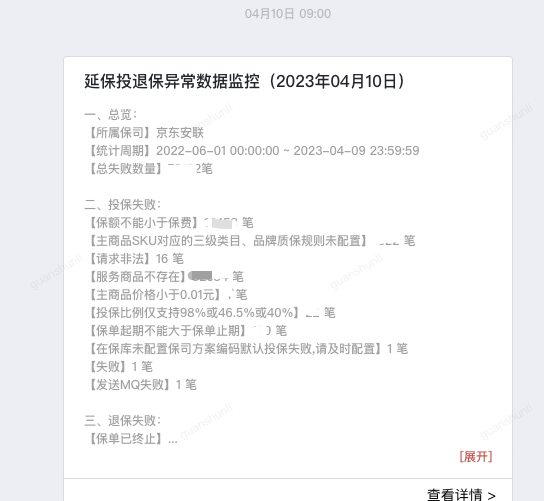
每周都会公示出上一周延保业务出现的问题,并通过内部通讯工具和邮件发送给业务方负责人,支持异常投保单的下载。业务收到邮件后会按照邮件中的攻略去操作,完成正确的投保。截止目前帮助业务侧完成40万+的异常投保单的重新投保。帮助业务降低了客诉率,也帮助保司拿到保费。(图2)
(图2)
3.2 自动补单:
延保的业务上游大多来自商城,业务会在系统里处理订单分发到下游,由于量大,操作门槛高,总会出现异常的情况,比如漏配某个参数,导致交易失败或者用户不能正常履约。以前都是到客户履约的时候或者下游交易发起结算失败时,才能发现的问题。在hm中配置了监控后,发现异常情况会调用补单的jsf接口,触发自动补单。以前出现问题最长要已天为单位才能解决,现在分钟级解决问题。起到了降本增效的效果。
3.3 数据归档:
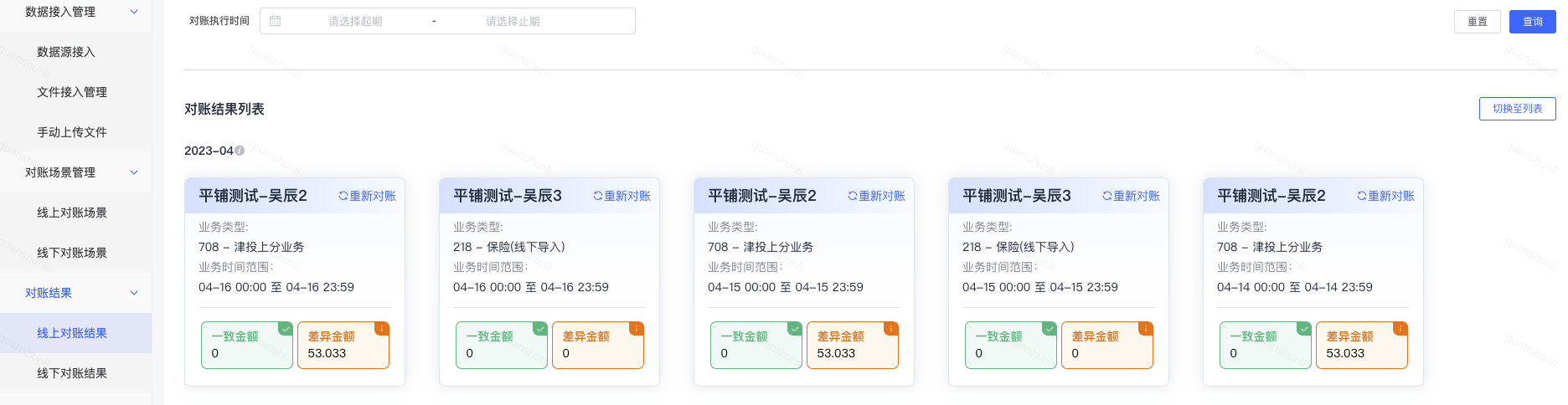
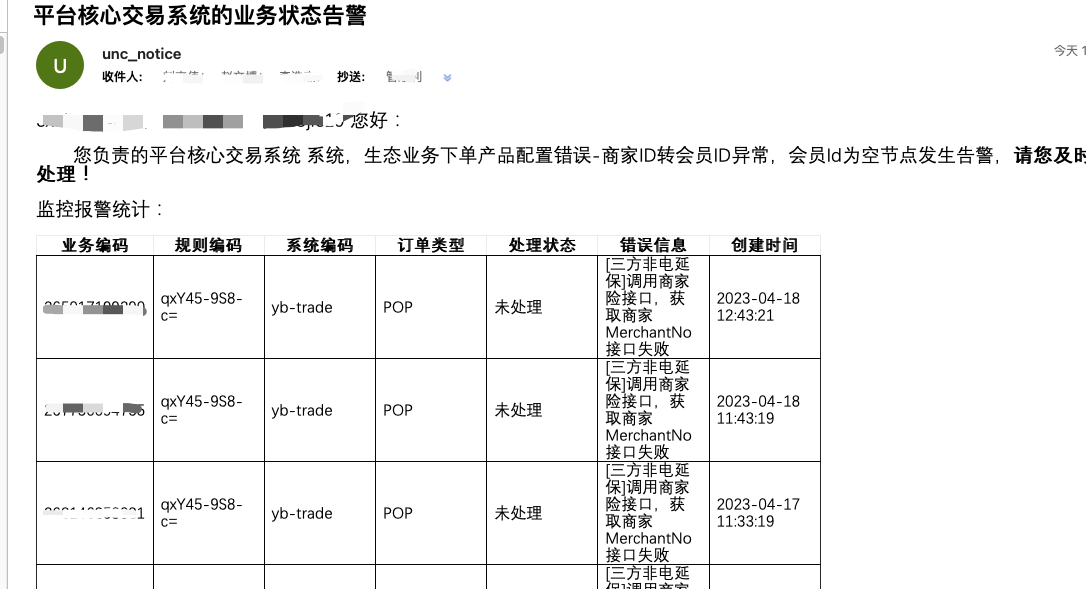
hm给延保上游和下游交易提供数据了永久归档能力,如发现各种异常类的情况,可以从hm系统里面导出数据来作数据比对。如果是金额类的还可以自动接入到对账系统。在线上查看对账结果,导出对账差异数据(图3)。同时会发送异常数据邮件,通知对应的产品和业务(图4)。
(图3)
(图4)
四、HM的内核,技术架构和实现方案
如果实在是没办法接入,只能自研怎么办?没关系,我把技术方法列出来。给大家提供解决方案的思路。
1.技术架构
hm架构上化繁为简,单刀直入。从最核心的业务数据下手,在业务应用中埋点,通过树型节点nodeId串起整条链路。埋点数据统一进数仓清洗后。由调度中心定时触发去做数据计算和数据统计,展示到前端。我们先来看一张架构图。图5
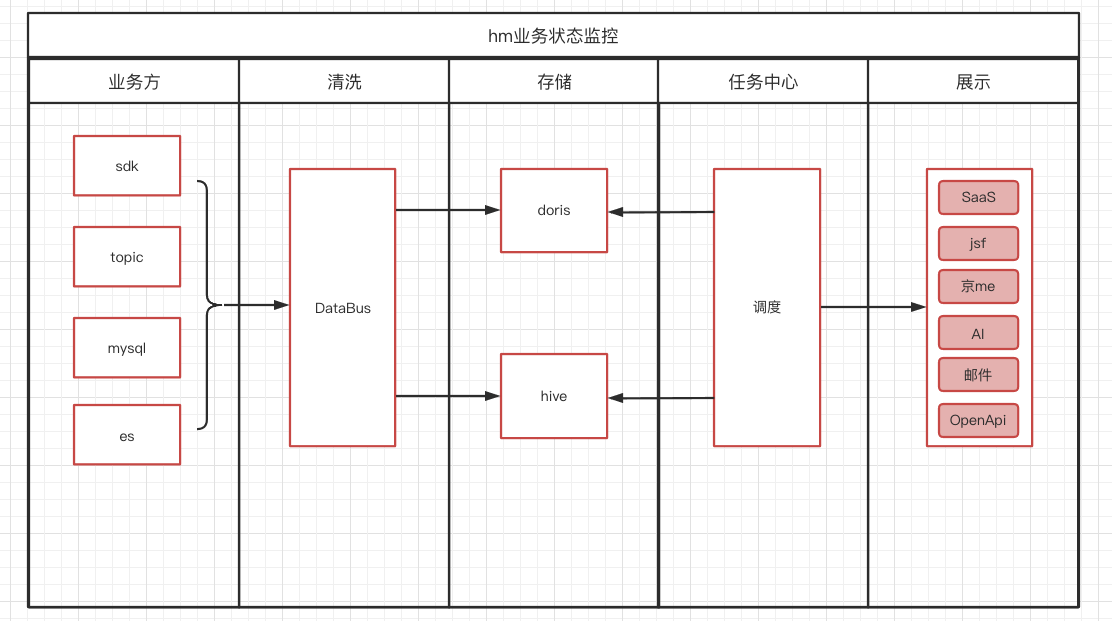
(图5)
2.核心技术
2.1 规则引擎
规则引擎是指埋点的规则。规则引擎参考了Jaeger源码,用来生成我们的规则编码nodeId。(图6)构建成hm的规则树。最终缓存到工作业务台展示(图7)。
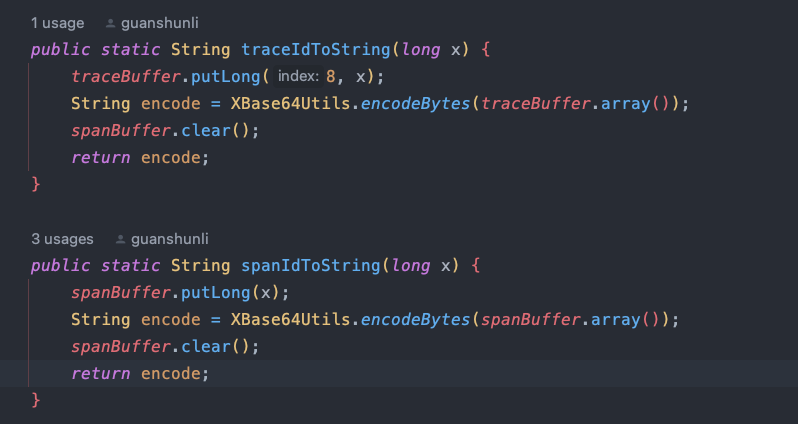
(图6)
(图7)
2.2 报警引擎
报警引擎是指配置报警的一系列的规则,数据计算的规则,触达的方式。创建好规则后,要对每一个规则进行详细的报警配置,包括触发报警的类型,报警规则,操作阈值,处理方式等。(图8)报警类型指触达方式,继承了保险SaaS-msg的能力,支持邮件、内部聊天工具、微信、电话等触达方式。任务系统使用Easy-Job来动态管理任务。处理方式可以对接业务方Jsf 来完成闭环,也可以设置成归档,以便后续的有导出或对数的需求。
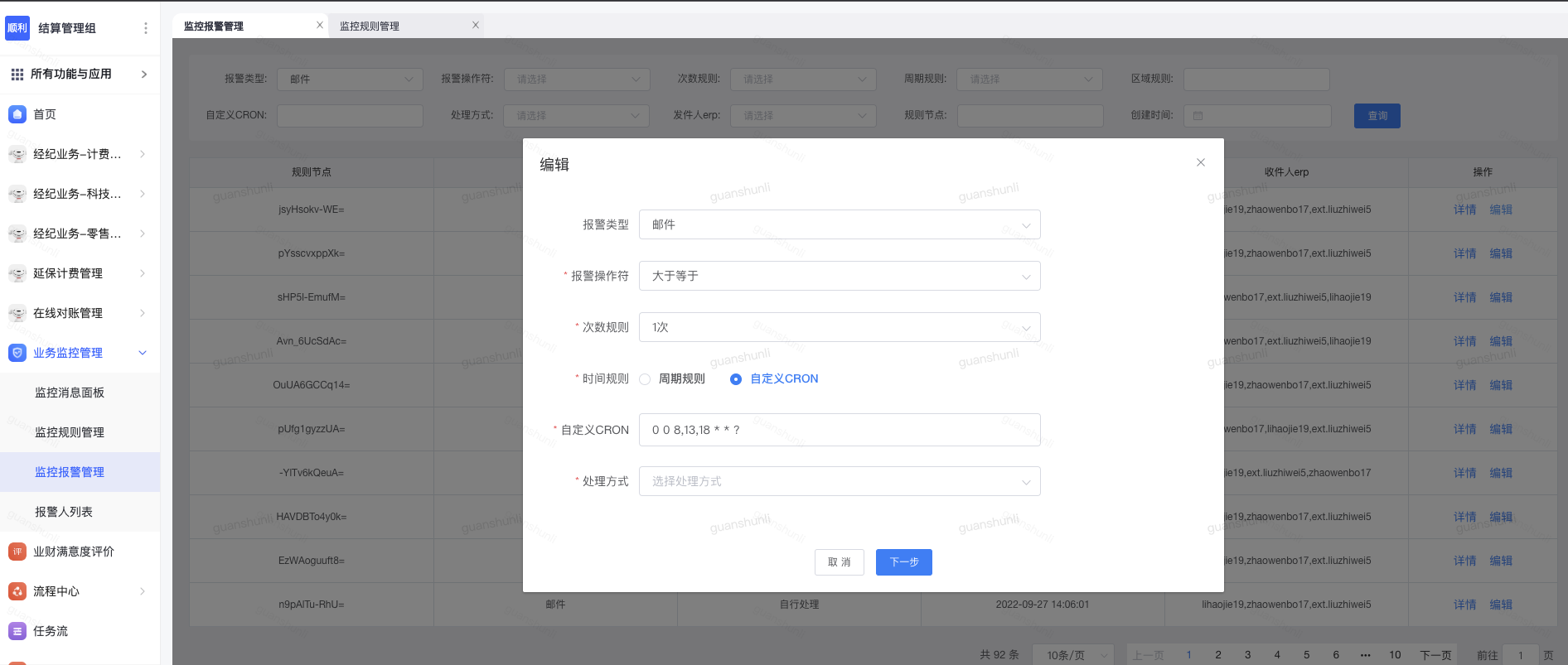
(图8)
2.3 数据埋点
在保险工作台配置好埋点规则和报警规则后,就可以在业务方去埋点,区别于链路追踪或传统的基于Agent系统,它们都是无侵入埋点系统。hm则属于强侵入式埋点系统,在这里我们定制了一套埋点规范,“必须启用异步线程,进行发送MQ或者调用API接口”。埋点支持两种方式,一种是send msg to topic,mq支持jmq2/jmq4。另一种就是通过调用API去初始化hunter-expoxt的实体类。由hm来发送消息。
2.4 数据清洗
hm的主要职责在业务数据的归纳、分拣。除了埋点接入外还支持,mq、数据库等数据源的接入。所有的数据统一有集团的DP(DataPilot )平台的DataBus系统的DTS完成,统一进数仓的FDM/BDM层。再由集团的调度中心Buffalo(EMR),配置的spark任务执行数据分拣。最终数据进入doris/hive/es中存储。
2.5 数据计算
hm只记录异常数据,发力在异常数据的统计和计算上。在配置好规则节点和系统埋点后,hm会去计算每个节点的异常数据。根据报警规则来进行处理,或通知业务和产研,或调用业务系统的jsf接口去做异常数据的自动处理,又或者根据规则自行处理数据。
2.6 数据统计
hm每周会出数据统计报表发送给业务和产研。报表中会体现他负责的业务线下所有系统的异常数据,包括处理过的异常数据和未处理的异常数据,A业务线和B业务线异常对比数据,业务系统与业务系统的异常对比数据等。可以根据业务需求定制报表。帮助业务和产研更好掌握系统的最新状况。
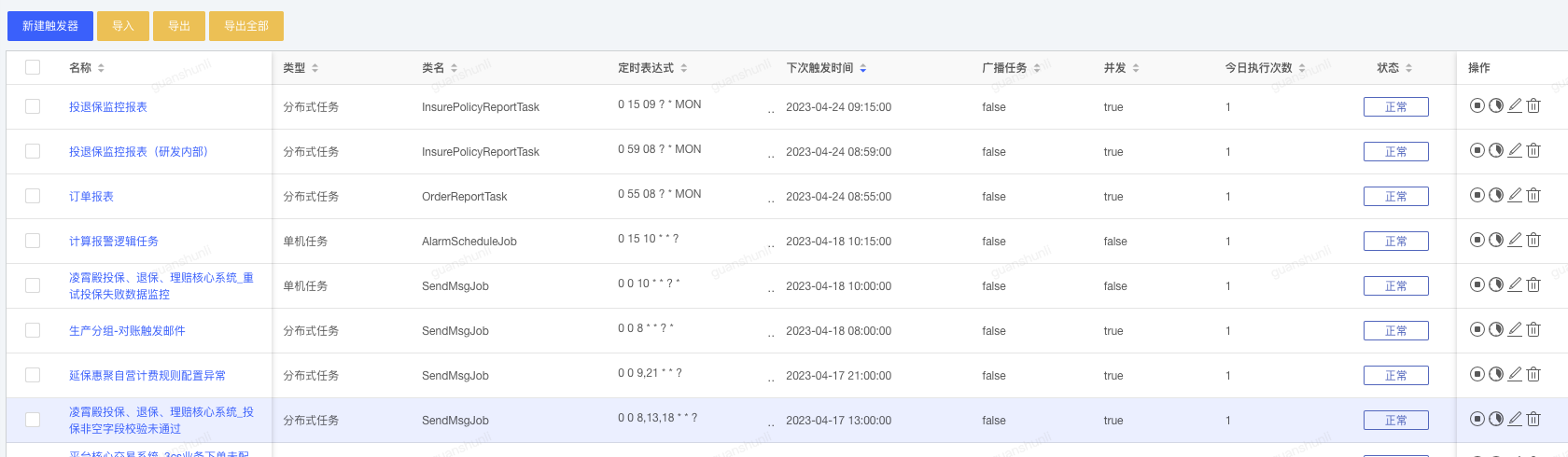
2.7 任务中心
任务中心是指xxljob任务指调度中心,它和报警规则强绑定的。调度任务分为两类,一类是业务类任务,是动态去创建的任务,按照设置的corn执行。另一类是平台任务。用于维护业务类任务的,比如定期去删除没有异常的任务等。(图9)
(图9)
2.8 触达展示
触达方式支持了保险工作台、内部聊天工具、邮件、企业微信、电话语音等。根据业务方需求来选择。
2.9 处理方式
如果触达3次还没有做异常的处理数据,会进行自动升级,在下次触达时会抄给本部门的上一级。异常数据需要在hm列表页里做数据状态变更。
2.10 开源能力:jaeger
hm底层参考了jaeger-core,重写了jaegerSpan和jaegerTracer类。并把jaeger-core和opentracing-api重新打包-形成自己的jar(hunter-api)
标签:异常,新思路,业务,hm,监控,HM,埋点,数据 From: https://www.cnblogs.com/Jcloud/p/18386711