如果你了解过 Kafka,那么它用到的一个性能优化技术可能会引起你的注意 -- 操作系统的零拷贝(zero-copy)优化。
零拷贝操作可以避免对数据的非必要拷贝,当然,并非是说完全没有拷贝。
在 Kafka 的场景下,操作系统可以从 page cache 拷贝数据到 socket buffer,直接绕过 Kafka broker 这个 Java 程序。这可以节省一些额外的拷贝,节省一些用户态和内核态的切换。让我们看一个例子。
传统拷贝
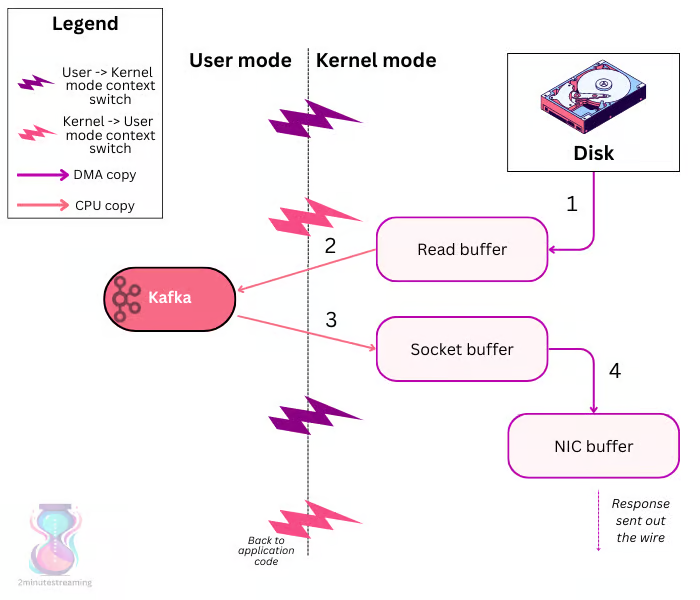
如果您的应用程序要从磁盘读取文件并通过网络发送它,则可能会进行一堆不必要的拷贝,以及用户态/内核态的切换。
一些术语:
- read buffer: 读缓冲区,操作系统的 page cache
- socket buffer: 套接字缓冲区,OS 用于管理数据包的字节缓冲区
- NIC buffer: 网卡中的字节缓冲区
- DMA copy: DMA 是 Direct Memory Access 的缩写,是内存控制器的一个功能,可以避免 CPU 的干预,允许硬件(图形卡、声卡、网卡等)直接访问内存 (RAM) 里的某些数据
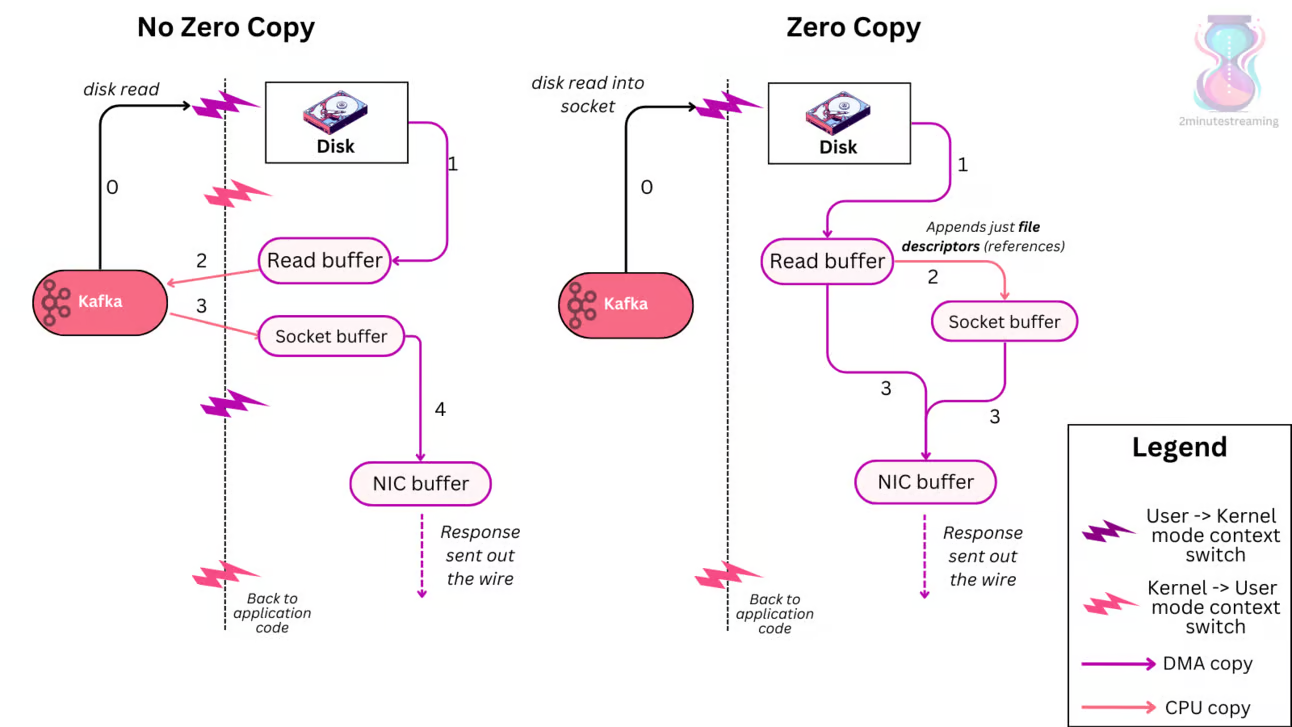
在这个例子中,我们有 4 次模式切换(用户态和内核态之间的切换)和 4 次数据拷贝。
- 应用程序(这里指 Kafka)利用 DMA copy 从磁盘 load 数据到 read buffer(
用户态->内核态) - read buffer 到应用程序的缓存区(
内核态->用户态) - 应用程序要发数据到网络上,实际是先写到 socket buffer(
用户态->内核态) - socket buffer 到 NIC buffer(响应数据写完之后,由内核态返回用户态)
零拷贝
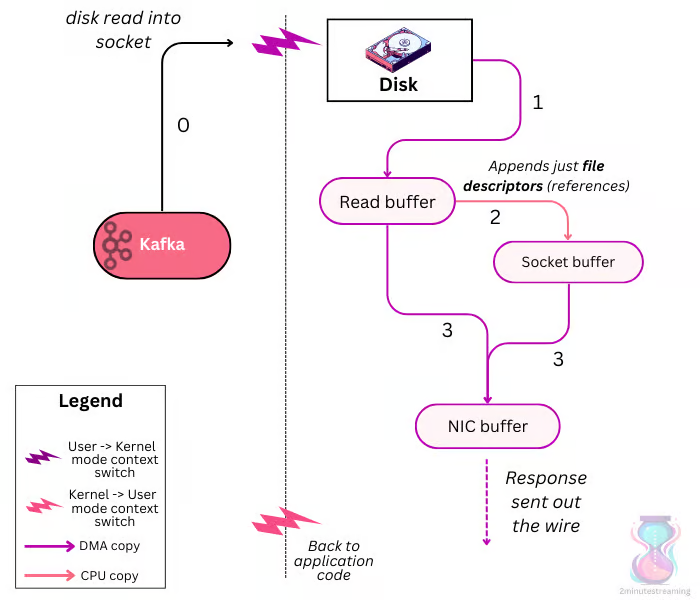
为了减少拷贝,把数据从磁盘直接发向网络,那 Kafka 在存储数据的时候,就要保证存储的数据格式和将要发出的 response 格式一致。
在传统拷贝模式下,第二步、第三步没啥意义,因为 Kafka 没有对数据做额外处理,只是简单转发。那能否从磁盘直接发向网络呢?答案是肯定的。通过零拷贝技术,磁盘上的数据还是要先进入 read buffer,然后不用再拷贝到应用程序的缓存区,而是直接拷贝到 NIC buffer,图上的步骤 2:Appends just file descriptors,只是把文件描述符交给了 Socket buffer,实际数据并没有拷贝给 Socket buffer。这就是所谓的 scatter-gather 操作(也称为 Vectorized I/O),scatter-gather 是仅将 read buffer 数据指针存储在 socket buffer 中,并让 DMA 直接从内存读取数据的行为。
最终结果如何呢?
- 4 次模式切换变成了 2 次
- 2 次 DMA 拷贝,仍然是 2 次
- 1 次微小的指针拷贝
在 Kafka 中
你可能听过 Kafka 因为零拷贝实现了高性能,但是理想很丰满现实很骨感,零拷贝技术在大部分 Kafka 集群中并没有那么大的影响力。
- CPU 很少成为瓶颈。网络饱和的速度要快得多,因此在大多数情况下,内存中副本的缺失并不会带来多大的影响。
- 启用加密和 SSL/TLS 已经禁止 Kafka 使用零拷贝
原文:https://2minutestreaming.beehiiv.com/p/apache-kafka-zero-copy-operating-system-optimization
译者:巴辉特,极客时间专栏《运维监控系统实战笔记》作者,Open-Falcon、Nightingale 开源项目发起人,目前创业中,作为 Flashcat 联合创始人,专攻监控/可观测性方向。欢迎和我一起探讨监控/可观测性相关技术和产品。