通过对多样化基准的严格评估,论文展示了现有特定方法在实现跨领域推理以及其偏向于数据偏差拟合方面的缺陷。从两阶段的视角重新审视视觉推理:(
1)符号化和(2)基于符号或其表示的逻辑推理,发现推理阶段比符号化更擅长泛化。因此,更高效的做法是通过为不同数据领域使用分离的编码器来实现符号化,同时使用共享的推理器。来源:晓飞的算法工程笔记 公众号
论文: Take A Step Back: Rethinking the Two Stages in Visual Reasoning

Introduction
推理能力是人类智能的集中体现,它是概念形成、对世界的认知理解以及与环境交互的基础。具体而言,视觉推理作为人类获取信息和理解的主要方式之一,已经成为广泛研究的焦点。近年来,随着深度学习的进步,涌现出了许多关于视觉推理的研究工作。此外,也出现了各种数据集来评估推理模型。
然而,现有视觉推理工作的显著局限性在于它们直接依赖于通过端到端深度学习模型同时进行识别和推理阶段,例如,在回答逻辑问题时识别图像中的概念。然而,这种范式存在显而易见的局限性:1)推理注释(规则、关系)比符号注释(三角形、立方体、苹果)要昂贵且困难得多,当前严格的视觉推理数据集通常很小。因此,当前方法往往是在小数据集上的特定任务,阻碍了它们的泛化潜力。2)同时追求符号识别和逻辑推理的通用模型可能效率低下且具有挑战性,即使是最近的大型语言模型(LLM)也难以处理多样化的视觉推理任务。
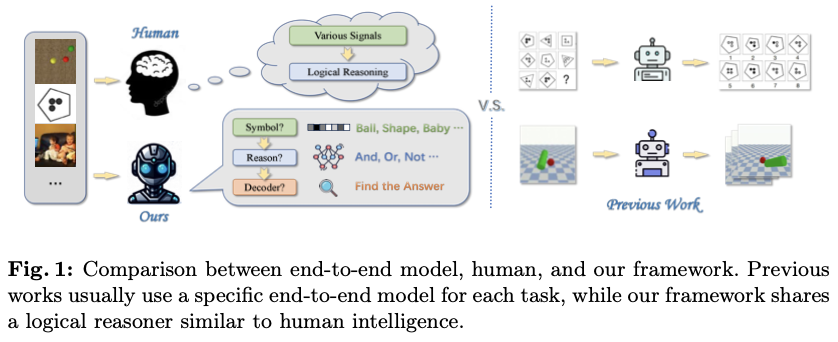
论文认为视觉推理的重点在于先从视觉信号中获取符号化表示,随后是逻辑推理,如图1所示。因此,一个问题浮现出来:这两个阶段应该纠缠在一起还是解开?推理自然比符号化具有更好的泛化性。例如,可以使用类似的逻辑分析不同任务的规则(如下围棋、做数学题和发现异常),但对于识别字母和物体则需要完全不同的知识。因此,论文认为解开符号化和推理将是一个更明智的选择。最近大型语言模型(LLM)在基于文本的推理任务上的成功也验证了这一点,因为LLM直接利用从人类观察中得出的抽象符号(语言),并专注于高级语言任务。相对而言,多模态大型语言模型(MLLM)即使参数更多,仍在视觉推理中遇到困难。最近,另一个相关的研究趋势是神经符号方法,将原始输入转换为明确的符号,以便进行后续推理和分析。然而,神经符号方法通常局限于单一数据集,这使得在不同任务之间实现泛化变得具有挑战性。
论文在多个具有显著领域差距的基准任务上进行了全面的实验,以验证假设。将符号化阶段定义为利用深度神经网络(DNN)进行表示提取,采用多种架构(如MLP、CNN、GNN、Transformer、神经符号模型、LLM等)实现逻辑推理器。论文主要探讨两个关键问题:(1) 在训练过的DNN模型中,符号化阶段的结束在哪里?即确定适合推理的合适符号(表示),如模型的深度、特征特性等。(2) 针对抽象的符号,哪种类型的模型和训练策略最适合进行推理,并赋予泛化能力?
对于第一个问题,论文发现不同的任务和领域需要非常不同规模的参数或模型深度才能实现良好的符号化。因此,针对特定领域,一个小型的独立领域内编码器就足以从数据中提取符号,以供后续推理阶段使用。虽然像CLIP这样的通用大型基础模型在某些任务上表现不错,但在与其训练数据存在巨大领域差距的任务上仍然面临挑战。对于第二个问题,实验结果显示,现有方法在执行跨领域推理时往往困难重重,而更倾向于适应与训练数据一致的偏见。因此,也许只能通过训练它执行各种推理任务(如解谜、物理预测、视觉问答)和数据领域(2D、3D、文本)来实现可泛化的共享推理器,即“近似原则”。
基于实验的发现,论文构建了一个简洁的框架,采用分离的编码器来实现不同数据领域的最佳符号化,并遵循“近似原则”建立了一个共享的推理器。该方法在跨领域基准测试中表现出色,使用更少的参数即可达到优异的性能。
总体而言,论文的贡献如下:
- 总结了一种高效的视觉推理的两阶段方法,借鉴了先前的视觉推理网络的思路。
- 探讨了视觉推理中符号化和逻辑推理的最优设计原则。
- 引入了一个简洁的框架,在多个具有领域差距的数据集上表现良好。
Preliminary
Two Stages
如上所述,视觉推理可以分为两个阶段:符号化阶段提取基础数据的符号表示,推理阶段进行逻辑推理。
对于人类来说,从感觉器官收集到的视觉和听觉信息的不同模态,通过不同的通路转换成电信号,然后发送到小脑皮层进行逻辑推理。类比地,为了通用的视觉推理机器,分离的任务特定符号化器和共享的领域无关推理器是一个合理的选择。此外,推理器应能够对来自各种模态的输入信息进行统一推理。换句话说,推理的本质在于其泛化能力。
-
Symbolization Stage
在符号化阶段,实现了各种面向任务的特征提取网络。这些网络使用针对每个任务定制的符号编码器,将多模态输入(文本、图像、视频)转换为符号表示。具体而言,假设有 \(n\) 个任务。对于第 \(i\) 个任务,有输入数据 \(\mathbf{x}^{i}\) 和任务 \(t^{i}\) ,以及任务定向编码器 \(E^{i}\) ,通过以下方式得到符号表示集合 \(\mathbf{f}^{i}\) :
\[\begin{equation} \mathbf{f}^{i} = E_i(\mathbf{x}^{i} \mid t^{i}). \end{equation} \]-
Reasoning Stage
推理器接收每个特定任务的符号表示,旨在捕捉数据中嵌入的更深入和更全面的模式和关系理解。对于所有任务的符号表示集合 \(\{\mathbf{f}^{(i)}\}_{i=1}^n\) ,将它们送入推理器 \(R\) ,在逻辑处理后得到其推理结果集合 \(\{\mathbf{c}^{i}\}_{i=1}^n\) ,以促进跨多模态问题解决:
\[\begin{equation} \{\mathbf{c}^{i}\}^n_{i=1} = R(\{\mathbf{f}^{i}\}^n_{i=1}). \label{eq:reasoning} \end{equation} \]-
Task-specific Heads
框架的最后部分是任务特定头部,将推理器的推理结果作为输入,并生成任务特定的答案。针对不同的任务,我们需要构建任务特定的分类或回归头部 \(H_i\) ,以获得最终输出 \(s^i\) 。
\[\begin{equation} s^i = H_i(\mathbf{c}^{i} \mid t^{i}). \end{equation} \]Symbolization-Reasoning Framework
Entanglement v.s. Disentanglement
考虑到这两个阶段,一个自然的问题出现了:对于任务,符号编码器(符号化)和推理器(推理)应该共享还是分开?
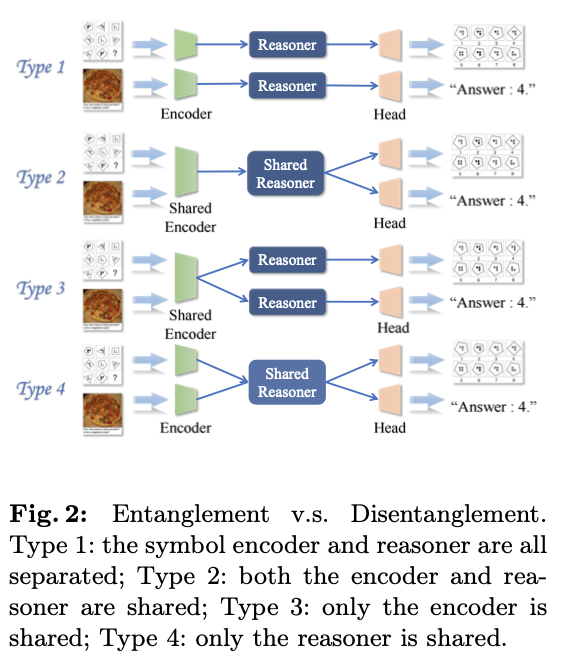
为了验证共享推理器假设,进行了不同设计的比较(图2):
Both-Separated:符号编码器和逻辑推理器均分离(每个任务的特定模型)。Both-Shared:符号编码器和推理器都是共享的。Shared-Encoder-Only:仅符号编码器是共享的。Shared-Reasoner-Only:仅推理器是共享的。
我们在几个多模态视觉推理基准上比较上述四种设计。对于共享的编码器/推理器,采用更多的参数来平衡它们与分离的编码器/推理器参数总和。在所有基准测试中,仅共享推理器(类型4)的表现远远优于仅共享编码器(类型3)和完全共享(类型1和2)。此外,仅共享推理器甚至在某些基准测试中超过了临时的完全分离模型,验证了其优越性和泛化能力。
Symbolization Depth
接下来,探讨符号编码器在不同任务中的合适深度。符号化阶段涉及处理来自不同领域的输入,并将它们映射到概念层次,即符号。尽管可以使用二进制或类似索引的表示(one-hot)来表示符号,但在深度学习的背景下,论文选择更具代表性的方式,即从深度神经网络中提取的高维特征。直观上,不同的任务可能需要不同程度的符号化。接下来的问题是如何确定每个任务的抽象层次。
为了回答这个问题,论文设计了实验来定量探究符号化过程中的程度。为了控制变量,在跨领域任务中采用相同的特征提取网络(ResNet),同时不断调整网络的深度。在不同深度下,将符号化网络的输出连接到相同的推理器,并以准确率作为符号化完成的指标进行测量。
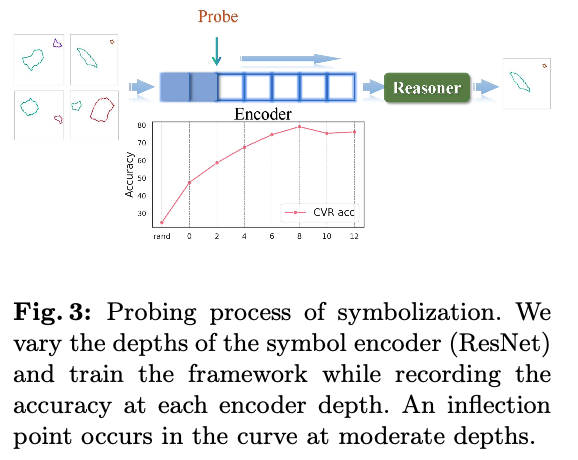
假设当符号化完成时,网络深度-准确率曲线将显示出明显的拐点。通过监测这一拐点的出现,可以为不同任务选择合适的推理器深度,如图3所示。在实验中,结果与常识一致:过浅和过深的网络对推理任务都是有害的。一方面,如果编码器过浅,符号化可能无法在输入推理器之前完全完成,而推理器则需要完成部分符号化工作,从而影响推理性能。另一方面,过深的网络往往会过拟合于单一任务,从而削弱旨在泛化的共享推理器的性能。不同领域的任务也需要不同的符号化深度。设置深度不当会导致共享参数冲突,进而导致更深层次的性能不佳。
Reasoner Architecture
接下来,论文希望弄清楚哪种架构更适合于推理器,这是一个长期存在的问题。许多研究已经提出并在各种视觉推理基准上取得了改进。在这里,每个任务由其各自的编码器和任务头处理,这些设计旨在适应其数据的固有特性。论文为所有任务使用一个共享的推理器,并根据公式2中的符号表示进行处理。
论文选择了一系列在许多任务中取得了巨大成功的架构作为推理器的候选项:多层感知器(MLP)、卷积神经网络(CNN)和Transformer,还探索了将神经网络的表示能力与符号系统的可解释性结合的混合神经符号模型。此外,论文采用了流行的图形和自回归模型:图卷积网络(GCN)和MiniGPT-4。上述模型为论文提供了广泛且多样化的方法论。如果在各种领域多样化的数据集上观察到强大而一致的性能,这将导致假设存在某种类型的架构,特别擅长逻辑推理。
Generalization of Reasoner
最后但并非最不重要的是,论文的目标是验证其“近似原理”,即通过来自不同领域的多样化任务和数据的训练,得到一个接近能够提供通用逻辑推理能力的良好推理器。论文认为推理涵盖普适性和泛化能力,因此,首先在一个任务上训练完整的两阶段模型,然后直接将其推理器与另一个任务的另一个符号编码器配对。如果推理器具有泛化能力,则其应该能够很好地适应其他任务的编码器。然而,在论文的测试中,仅使用一个任务/领域训练的推理器通常泛化能力不佳。因此,接下来验证推理器在训练更多任务/领域后是否具有更好的泛化能力。
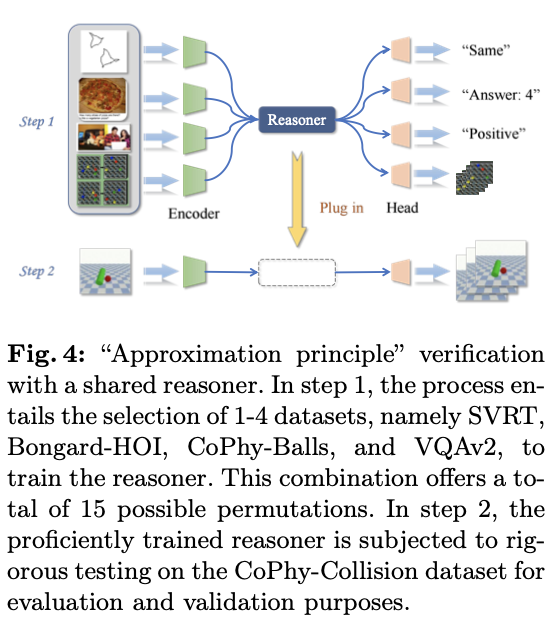
如图4所示,论文发现随着涉及不同任务和领域的数据越来越多,整体任务变得越来越具有挑战性。然而,推理器将会专注于“纯粹”的推理,而不是特定于任务/领域的解决方法,从而赋予更好的泛化能力。换句话说,论文的“近似原理”是合理的。因此,可以预测,随着训练数据和任务的增加,推理器在跨领域任务上的表现应该会更好。此外,一个共享并跨任务训练的推理器使整个视觉推理框架更轻便和更高效。
Experiments
Entanglement v.s. Disentanglement Analysis
为了比较图2中的三种类型,使用五个数据集对模型进行训练:RAVEN、CVR、SVRT、Bongard-HOI和Bongard-LOGO。为了控制变量并便于模型共享,对于上述所有类型,我们采用ResNet-18作为编码器,使用MLP作为推理器。
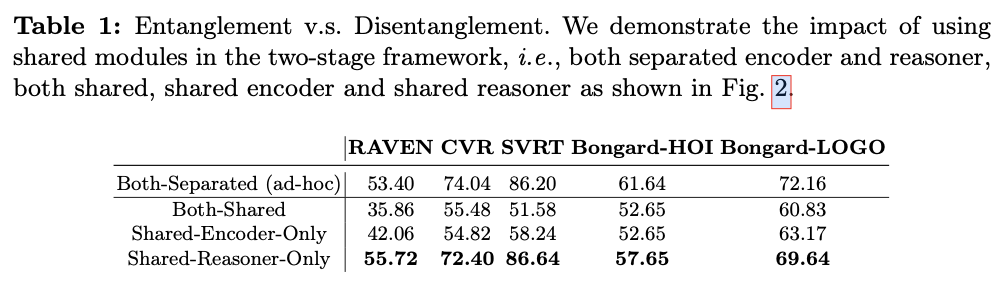
结果如表1所示,仅共享推理器的性能在所有五个数据集上与ad-hoc方案相当,在RAVEN和SVRT上甚至更高。此外,仅共享编码器和共享双方案在所有数据集上表现明显不及。这反映了在跨多个任务使用任务特定符号化器和共享推理器设计的有效性。
Optimal Symbolization Depth
接下来,通过探测符号编码器的深度来确定两个阶段之间的边界,如图3所示,使用的共享推理器是一个MLP。通过观察准确率的变化,希望找到明显的拐点和符号化基础阶段的终止点。为了确保公平性,在以下二维数据集(RAVEN、CVR、SVRT、Bongard-LOGO、Bongard-HOI)上采用ResNet18编码器。对于每个基准,训练各自的模型以达到最佳性能,然后在不同深度中断训练的网络,以探测符号化终止点。将分离的符号编码器的输出连接到一个共享推理器,并记录不同中断点处的准确率,这被视为符号化终止的证据。
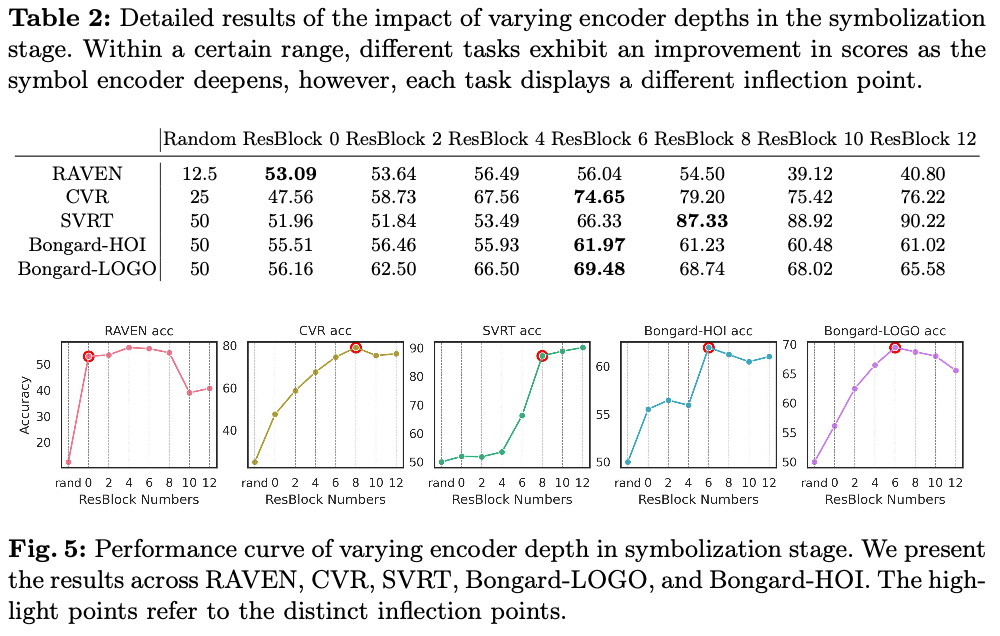
如图5和表2所示,对于每个基准,网络深度表现出初期的增长,然后进入一个平稳期。不同任务的拐点位置因其难度水平和所需的符号抽象程度不同而异。例如,Bongard-HOI的拐点比RAVEN深得多,表明前者更难符号化,需要一个更深的符号化网络来获取复杂的高维特征。这些结果验证了在不同复杂度的数据集上使用深度不同的符号化网络的必要性,并说明了两个阶段之间的合理边界。
One-for-All Reasoner Architecture
接下来,找出适合的推理器架构,并测试其在仅共享推理器设计中的效果。选择了9个跨领域数据集(RAVEN、CVR、SVRT、Bongard-HOI、Bongard-LOGO、Filtered-CoPhy、VQAv2)来进行实验,因为用不同领域的数据解决各种推理问题可以更好地展示模型的推理能力。
根据不同任务的要求设计了任务特定的编码器和头部。至于推理器,测试了CNN、MLP、Transformer、GCN、混合神经符号模型和MiniGPT-4。首先单独训练每个数据集,以获得使用分离编码器和分离头部时的最佳结果,然后使用一个共享推理器对多个数据集进行联合训练。
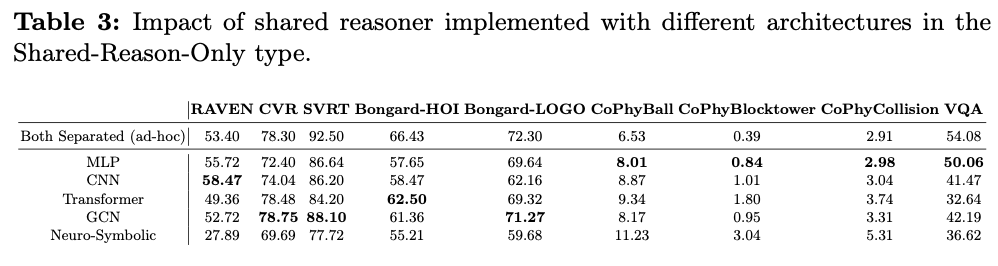
如表3所示,在所有架构中,MLP在四个数据集上表现出乎意料的最佳性能,并且在其他五个数据集上表现相当。此外,GCN在三个数据集上表现良好,符合之前在推理工作中的经验。然而,通常被认为更先进的Transformer等其他架构并未显示明显优势。因此,选择MLP作为One-for-All中的轻量推理器。

One-for-All在大多数任务上表现出色,甚至与最先进技术(SOTA)ad-hoc相比也不遑多让。论文根据复杂性将SOTA分为轻量和重型,如表4所示,One-for-All与轻量ad-hoc SOTA表现可比,并且在一些数据集(如RAVEN)上甚至超越了轻量ad-hoc SOTA。这个实验表明,推理阶段与识别任务有着不同的性能参数关系。如果在多领域任务上进行训练,一个轻量级的推理器也可以在推理任务上表现出色。
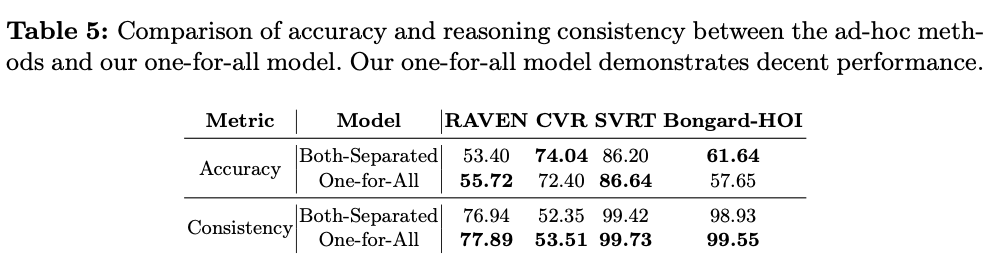
由于推理能力不能仅通过准确性来衡量,论文还使用推理一致性评估推理能力。对于每个任务,使用相同的编码器和推理器参数,采用两种问答方法:“这个问题的答案是什么?”和“某个选项是否正确?”。一个具有良好推理能力的模型应该在这两种方法上产生一致的结果,而不像随机模型可能存在不一致性。论文使用F1分数来衡量这些方法之间的一致性,如表5所示。One-for-All在多个数据集上联合训练后,显示出比单独训练的模型更高的一致性,表明其在真正推理中的潜力。
为了进一步评估LLM的性能,采用MiniGPT-4作为共享推理器。One-for-All在相似的模型规模下也表现出优势。令人惊讶的是,轻量化的One-for-All在特定任务上超过了MiniGPT-4,例如RAVEN和Bongard-HOI,这提供了强有力的证据表明,模型参数数量与模型推理能力之间没有绝对的正相关关系。

为了分析基于LLM的模型性能,根据论文的两阶段框架设计探索任务,并分别进行检查:(1)符号化:LLM-based模型能否识别问题的要素。(2) 概念化:LLM-based模型能否学习任务背后的具体概念并进行推理。(3) 答案生成:LLM-based模型能否利用其学习到的概念来解决问题。以MiniGPT-4为代表,总结了LLM-based模型对RAVEN和Bongard中三级问题的典型响应,如图6所示。
论文发现LLM在解决视觉推理任务时可能会遇到某些幻觉情况。如图6所示,对于RAVEN问题,MiniGPT-4在第一阶段成功识别物体,但在第二阶段根据排列规则进行推理时失败。对于Bongard问题,MiniGPT-4在第一阶段成功识别人类活动,并在第二阶段逻辑推理中掌握了推理,但在答案生成阶段失败,并且在利用规则回答问题时迷失方向。基于以上案例,能够了解LLM-based模型在推理任务中的缺点,即其良好的概念理解能力,但在逻辑推理和答案生成方面表现不足。
Approximation Principle Verification
接下来,验证使用来自多个领域数据训练推理器可以确保推理器具有更好的泛化能力,在SVRT、Bongard-HOI、Filtered-CoPhy的Balls任务、Filtered-CoPhy的Collision任务以及VQAv2上进行了相关实验。这些数据集涵盖了2D谜题、3D视频和VQA任务,提供了多样化和多模态的数据,利用Filtered-CoPhy的Collision任务作为测试的基准。
论文引入越来越多跨领域数据集来训练推理器,并将其与目标测试数据集的分离编码器配对。鉴于各个数据集之间的固有差异,在推理器之前引入了基于MLP的高度轻量级适配器。为了均衡每个数据集对推理引擎的贡献,调整了用于跨数据集训练的样本大小。具体而言,使用了1,000和3,000的样本大小。

如表6所示,随着训练数据集数量的增加,推理器逐步改善。尽管处理来自多样化领域的更多数据集显著增加了复杂性,但经过训练的推理器在跨领域的Filtered-CoPhy上表现良好。这表明随着训练数据集领域的增加,推理器将专注于任务无关的纯推理,这验证了我们的“逼近原理”。
Additional Ablation Study
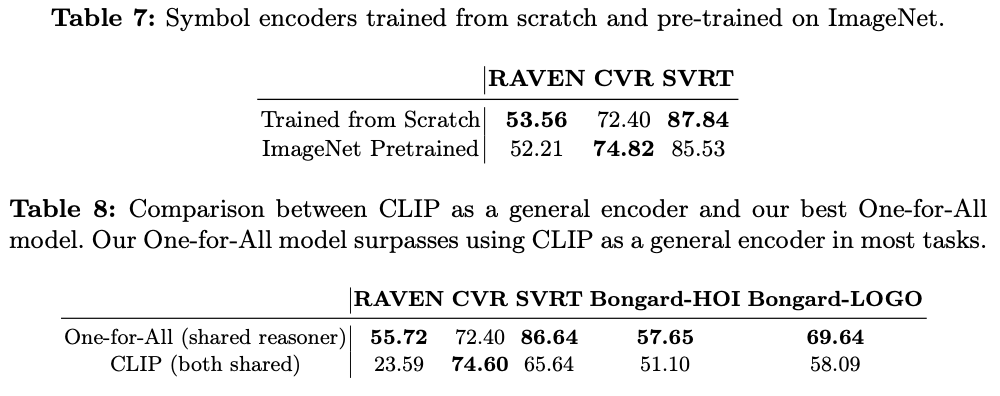
在表7中展示了在符号编码器是否使用预训练模型的消融实验,选择了RAVEN、CVR和SVRT数据集,并采用ImageNet作为预训练数据集。结果非常接近,可能的原因是ImageNet与这三个推理数据集之间存在明显的领域差异。
论文测试了CLIP作为通用和大型基础模型在充当通用符号编码器时的表现,将CLIP作为多模态数据集的视觉编码器,接着使用MLP作为推理器,并采用任务特定的头部网络。如表8所示,即使在微调后,使用CLIP得到的结果仍不及最佳的One-for-All方法。这验证了即使像CLIP这样的大型模型也无法完成不同数据集的符号化任务,从而确认了采用分离编码器和共享推理器框架设计的理论依据。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
