天命人,请允许我先蹭个热点!

原始声音:
克隆声音:
文章写了一半,被《黑神话悟空》刷屏了。突发奇想,用里面的声音来做个素材试试看。 B站捞了一点声音素材,随便剪一剪,训练一把过,没有调优,就直接拿来用了。 情绪还差点意思,音色克隆的还不错。 下面进入正题! 声音克隆项目迎来2.0版本了! 目前,这个软件,应该是我们能接触的最强的声音克隆软件。 主要特点是高效,简单,效果也好。 快速模式,只要十秒音频,无需训练,直接克隆声音。 训练模型,也只要一分钟的左右的音频,十几分钟时间就能搞定。 本文,就不在过多介绍这个项目了,可以参考之前的两篇文章。 《声音克隆:一个牛逼的新项目,入手难度低,相似度高!》 《声音克隆: GPT-SoVITS软件更新+新教程!》 今天主要是告诉大家,软件更新了,然后软件和教程一并奉上。 软件更新 从年初发布一个版本,到现在已经过去大半年了,其中有不少更新。根据官网文档介绍。 V1版本的主要功能和V2版本的主要更新如下。 V1主要功能:- 由参考音频的情感、音色、语速控制合成音频的情感、音色、语速
- 可以少量语音微调训练,也可不训练直接推理
- 可以跨语种生成,即参考音频(训练集)和推理文本的语种为不同语种
- 低音质参考音频合成出来音质更好
- 底膜训练集增加到5k小时,zero shot性能更好音色更像,所需数据集更少
- 增加了韩语和粤语,中日英韩粤5个语种均可跨语种合成
- 更好的文本前端,V2中英文加入多音字优化。
 添加图片注释,不超过 140 字(可选)
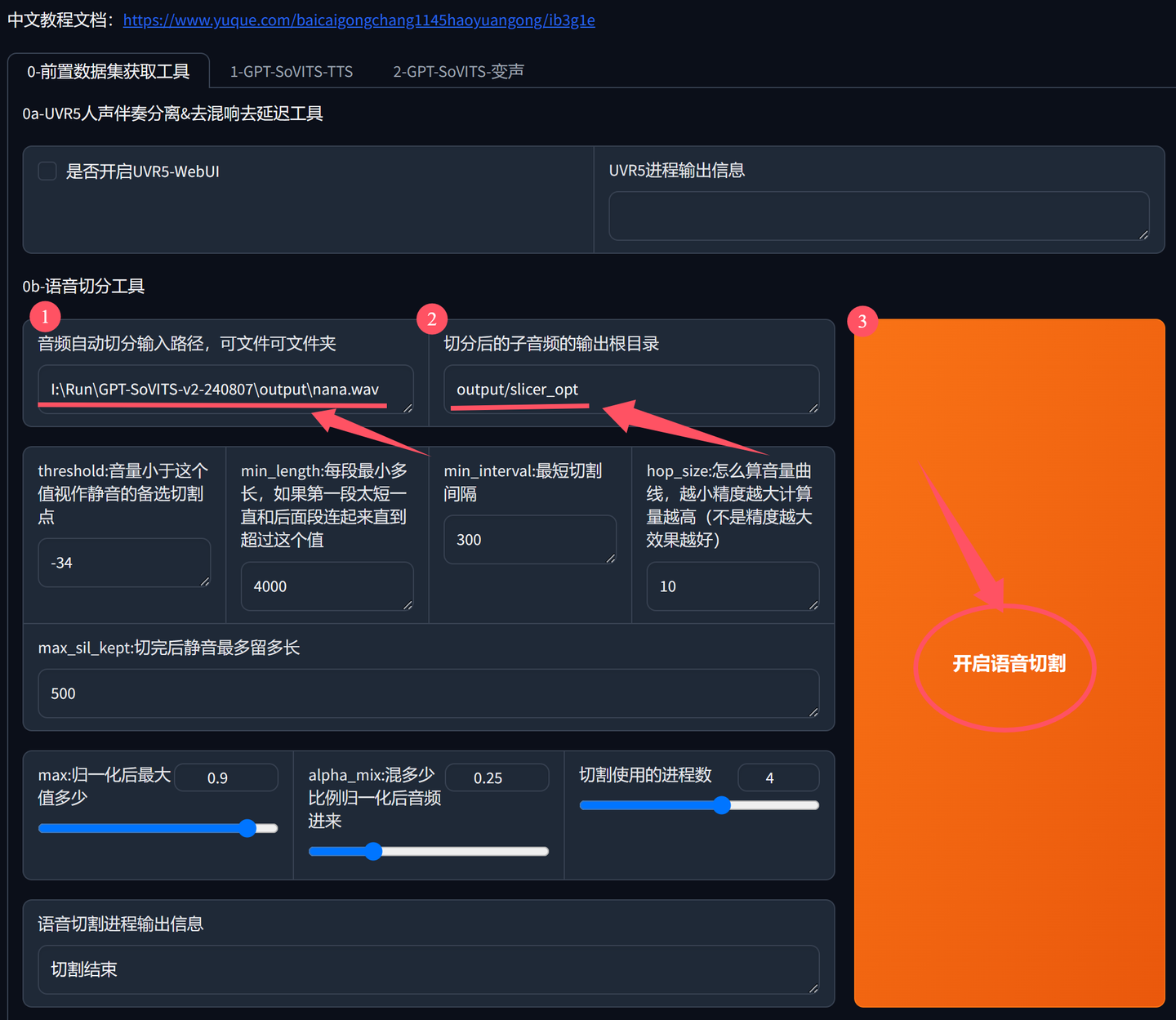
①输入音频文件地址
首先输入声音文件的地址,这个地址可以在文件管理器的地址栏复制。如果你有多个声音文件,这里可以填写文件夹的路径,如果你是单个,就写具体的单个文件的路径。
比如我这里用的是单个文件,名字叫nana.wav。所以我的路径,是以这个文件为结尾。
如果你是文件夹里放了很多声音文件,那么这里只要直接写到output这个文件夹就可以了。
当然,放音频的文件夹不一定是output,可以在任意位置,用任意名称。只要这里配置的路径正确即可。
②输入保存地址
这个地址会自动设置,最好不要改变。只要记住这个路径在output文件夹下面的slicer_opt文件里面就可以了。
③点击开启语音切割。
设置好两个地址之后,还有8参数可以调整,但是对于不懂的人来说,默认配置就是最佳配置,所以除非你知道他是干什么,否则就不要修改。
所以,只要设置好上面两个地址,然后直接点击巨大的黄色按钮就可以了。
运行结束之后,界面底部会显示“切割结束”。
为了验证操作是否真的成功,可以查看output\slicer_opt文件夹。
添加图片注释,不超过 140 字(可选)
①输入音频文件地址
首先输入声音文件的地址,这个地址可以在文件管理器的地址栏复制。如果你有多个声音文件,这里可以填写文件夹的路径,如果你是单个,就写具体的单个文件的路径。
比如我这里用的是单个文件,名字叫nana.wav。所以我的路径,是以这个文件为结尾。
如果你是文件夹里放了很多声音文件,那么这里只要直接写到output这个文件夹就可以了。
当然,放音频的文件夹不一定是output,可以在任意位置,用任意名称。只要这里配置的路径正确即可。
②输入保存地址
这个地址会自动设置,最好不要改变。只要记住这个路径在output文件夹下面的slicer_opt文件里面就可以了。
③点击开启语音切割。
设置好两个地址之后,还有8参数可以调整,但是对于不懂的人来说,默认配置就是最佳配置,所以除非你知道他是干什么,否则就不要修改。
所以,只要设置好上面两个地址,然后直接点击巨大的黄色按钮就可以了。
运行结束之后,界面底部会显示“切割结束”。
为了验证操作是否真的成功,可以查看output\slicer_opt文件夹。
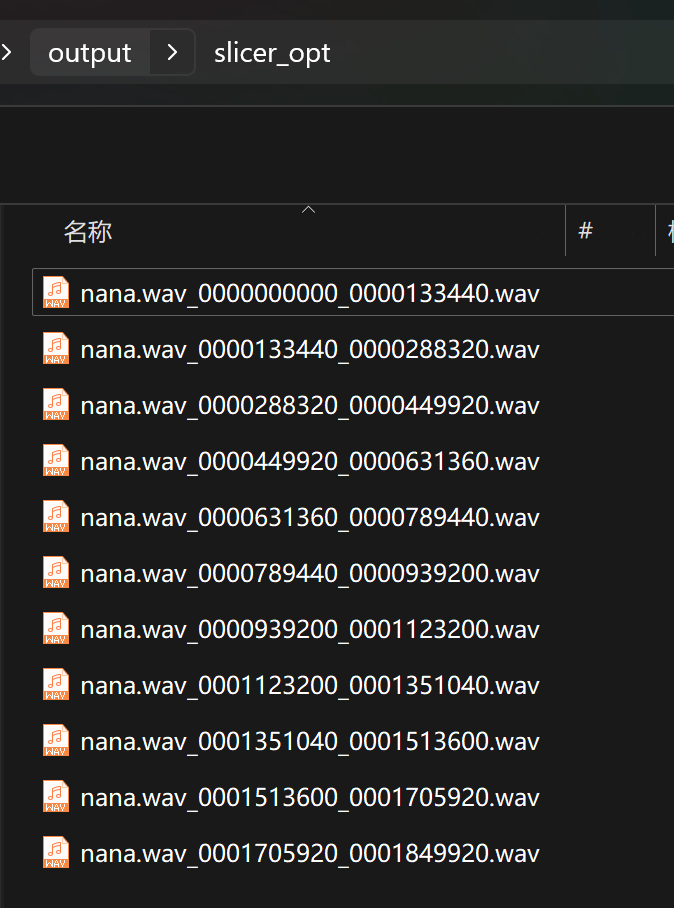 添加图片注释,不超过 140 字(可选)
里面有很多wav文件,就证明这个步骤已经彻彻底底的成功了。
转换
其实就是ASR处理,生成音频文件对应的文字。然后生成一个带有声音文件地址,对应文字内容,对应语言类型的清单。保存在一个叫slicer_pot.list的文本文件里面。
添加图片注释,不超过 140 字(可选)
里面有很多wav文件,就证明这个步骤已经彻彻底底的成功了。
转换
其实就是ASR处理,生成音频文件对应的文字。然后生成一个带有声音文件地址,对应文字内容,对应语言类型的清单。保存在一个叫slicer_pot.list的文本文件里面。
ASR(Automatic Speech Recognition,即自动语音识别)是一种将语音信号转化为文本的技术。具体操作如下图:
 添加图片注释,不超过 140 字(可选)
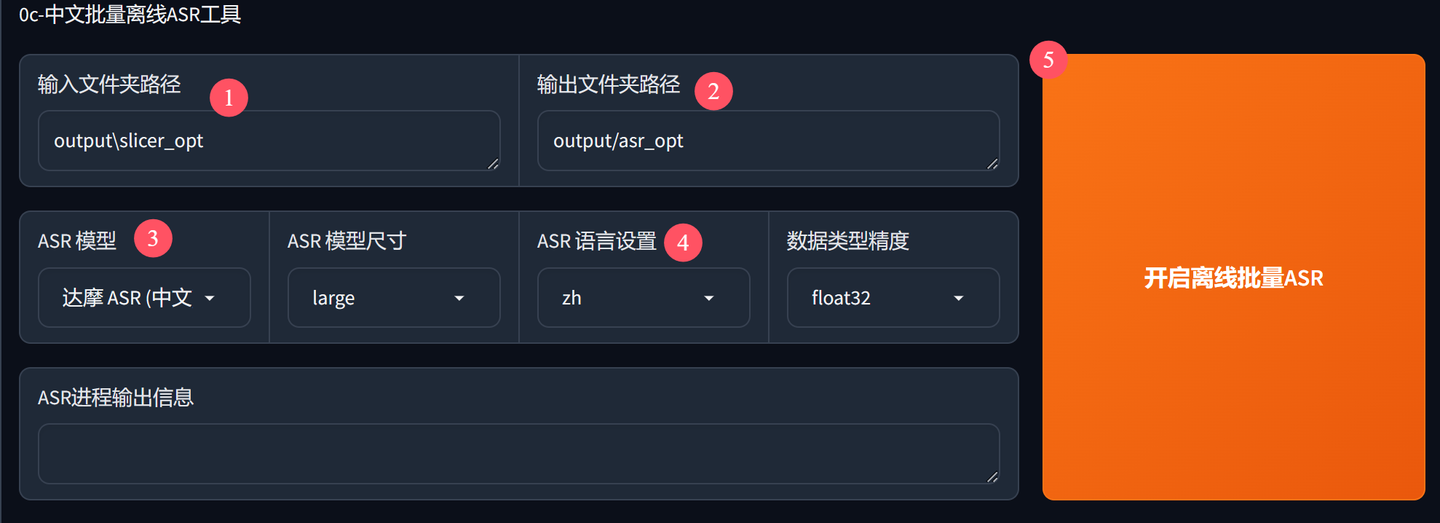
这个步骤,其实一切参数也是默认的,直接点击开启离线批量ASR按钮就可以了。
① 输入文件夹路径,就是我们上一步的输出文件夹路径,里面放的是音频片段。
②输出文件夹路径,执行完成后会在这里生成一个.list文件。
③ASR模型选择。中文默认用达摩ASR,英文用 OpenAI 的 Whisper 。
④ASR语音设置。中文汉语使用zh,粤语的话,使用yue。如果前面选的是Whisper,这里会有5种语言的候选项。
⑤开始离线批量ASR。点击按钮,就立马开始工作了。
这个过程并不会消耗太多,应该可以很快完成。
完成之后会在output\asr_opt下面生成一个叫slicer_opt.list的文本文件。
添加图片注释,不超过 140 字(可选)
这个步骤,其实一切参数也是默认的,直接点击开启离线批量ASR按钮就可以了。
① 输入文件夹路径,就是我们上一步的输出文件夹路径,里面放的是音频片段。
②输出文件夹路径,执行完成后会在这里生成一个.list文件。
③ASR模型选择。中文默认用达摩ASR,英文用 OpenAI 的 Whisper 。
④ASR语音设置。中文汉语使用zh,粤语的话,使用yue。如果前面选的是Whisper,这里会有5种语言的候选项。
⑤开始离线批量ASR。点击按钮,就立马开始工作了。
这个过程并不会消耗太多,应该可以很快完成。
完成之后会在output\asr_opt下面生成一个叫slicer_opt.list的文本文件。
 添加图片注释,不超过 140 字(可选)
可以用任何文本工具打开,里面的内容大致如下:
output\slicer_opt\nana.wav_0000000000_0000133440.wav|slicer_opt|ZH|在十二岁以前呢,我从来没有想过自己会演戏。 output\slicer_opt\nana.wav_0000133440_0000288320.wav|slicer_opt|ZH|我八岁的时候,立志成为一个像马悠悠一样的大提琴演奏家。
可以看到,每行通过“|”符号分割成了四部分。这四部分分别是路径,slicer_opt,语言类型,文字内容。
后面的步骤会用到这个文件。
语音文本校对
这个步骤,其实对上一个步骤的补充。如果你的声音质量比较好,自动识别转换的效果也会相当不错,就不需要手动修改了。
如果你对识别效果没有信心,可以勾选“是否打开打标WebUI”。
添加图片注释,不超过 140 字(可选)
可以用任何文本工具打开,里面的内容大致如下:
output\slicer_opt\nana.wav_0000000000_0000133440.wav|slicer_opt|ZH|在十二岁以前呢,我从来没有想过自己会演戏。 output\slicer_opt\nana.wav_0000133440_0000288320.wav|slicer_opt|ZH|我八岁的时候,立志成为一个像马悠悠一样的大提琴演奏家。
可以看到,每行通过“|”符号分割成了四部分。这四部分分别是路径,slicer_opt,语言类型,文字内容。
后面的步骤会用到这个文件。
语音文本校对
这个步骤,其实对上一个步骤的补充。如果你的声音质量比较好,自动识别转换的效果也会相当不错,就不需要手动修改了。
如果你对识别效果没有信心,可以勾选“是否打开打标WebUI”。
 添加图片注释,不超过 140 字(可选)
勾选之前,需要先填写.list文件的路径。这个路径一般也是自动生成。如果你有多个项目,可以手动指定路径。
勾选之后,会自动打开一个新的网页。网页显示内容如下:
添加图片注释,不超过 140 字(可选)
勾选之前,需要先填写.list文件的路径。这个路径一般也是自动生成。如果你有多个项目,可以手动指定路径。
勾选之后,会自动打开一个新的网页。网页显示内容如下:
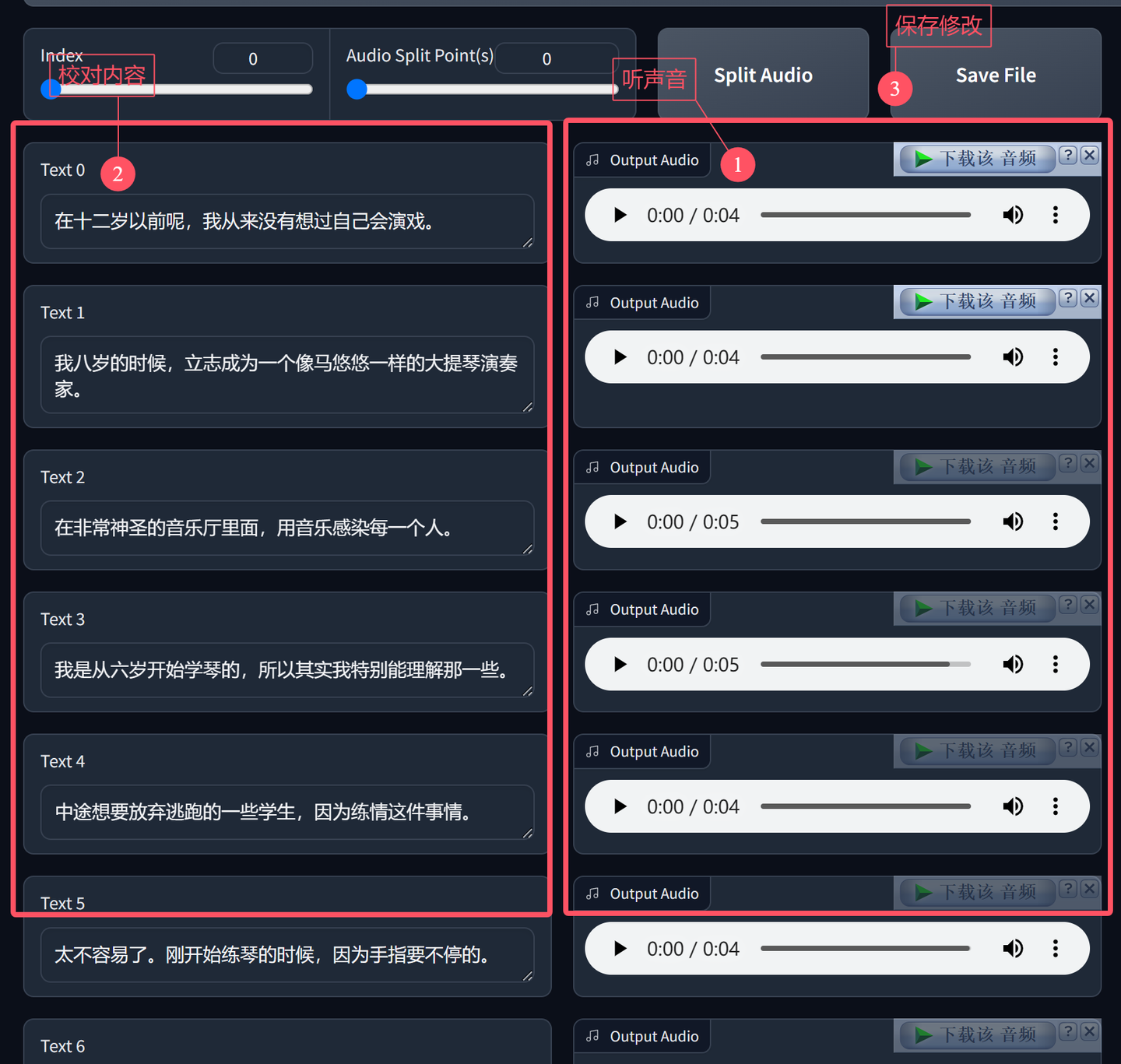 添加图片注释,不超过 140 字(可选)
只要比对左边的文字和右边声音中说话的内容是否一致,一致就不用改。如果不一致,修改左边的文字内容。
全部检查修改完成之后,保存文件就好了。
数据格式化
素材预处理完成之后,就可以对生成的数据进行格式化了。
点击“1-GPT-SoVITS-TTS”这个标签页,切换到第二个大步骤的功能页面。
切换之后,需要修改一下实验名。命名没有特别要求,好记就行。最好是英文。
添加图片注释,不超过 140 字(可选)
只要比对左边的文字和右边声音中说话的内容是否一致,一致就不用改。如果不一致,修改左边的文字内容。
全部检查修改完成之后,保存文件就好了。
数据格式化
素材预处理完成之后,就可以对生成的数据进行格式化了。
点击“1-GPT-SoVITS-TTS”这个标签页,切换到第二个大步骤的功能页面。
切换之后,需要修改一下实验名。命名没有特别要求,好记就行。最好是英文。
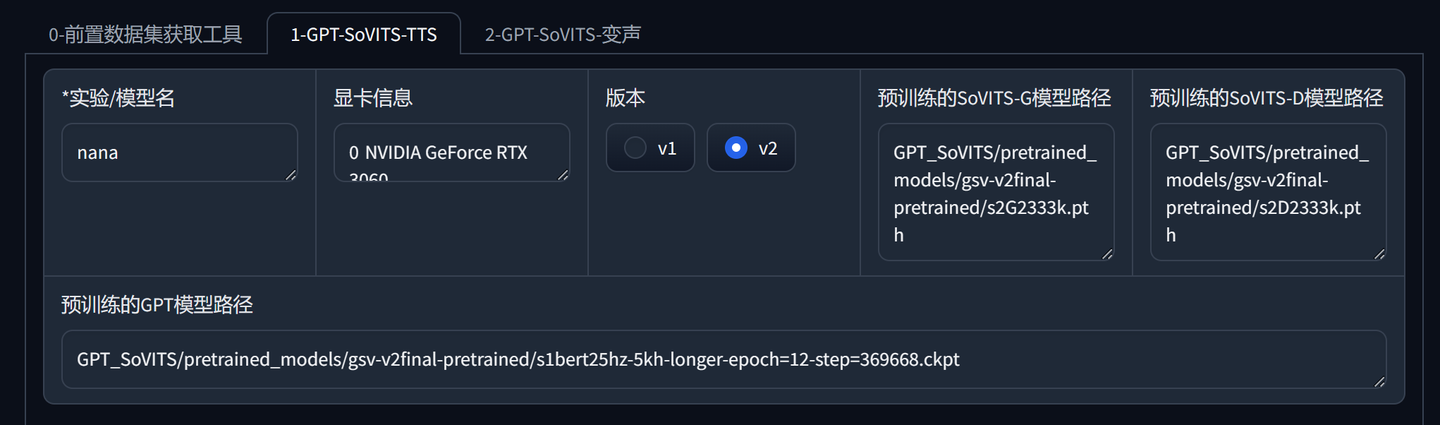 添加图片注释,不超过 140 字(可选)
另外,可以看到显卡型号,版本默认勾选V2。
另外还有G和D这两个预训练模型的路径,这里会自动设置,无需修改。
开始之前先到GPT_SoVITS\pretrained_models文件下面确认一下,已经包含如下的模型文件。
添加图片注释,不超过 140 字(可选)
另外,可以看到显卡型号,版本默认勾选V2。
另外还有G和D这两个预训练模型的路径,这里会自动设置,无需修改。
开始之前先到GPT_SoVITS\pretrained_models文件下面确认一下,已经包含如下的模型文件。
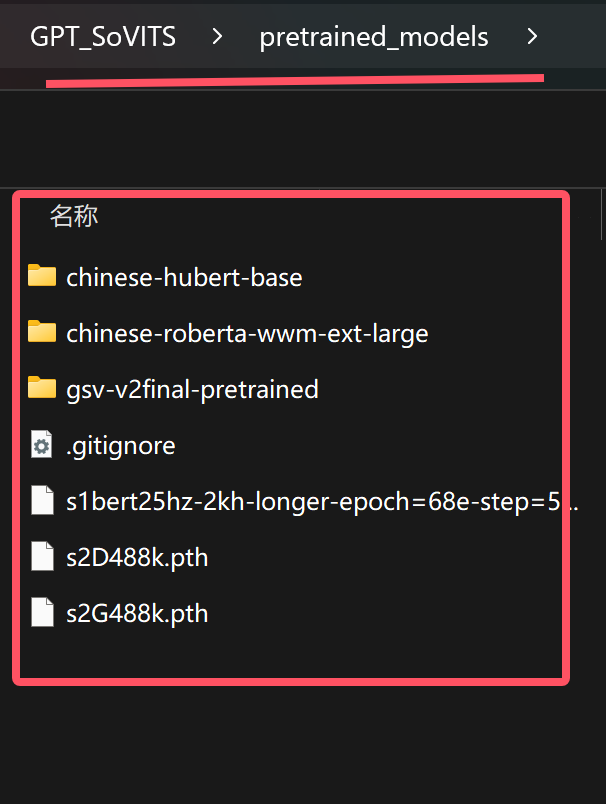 添加图片注释,不超过 140 字(可选)
正常情况下,一键运行包里面已经包含了这些模型,你只要知道,下面的步骤需要用的模型放在这里就可以了。
然后继续往下看,这里又分成了三个TAB,分别是格式化,微调训练,推理。
下面我们要做的是格式化。
格式化需要指定两个路径,一个是标注文件地址,一个切割后音频文件所在地址。
同时也分成了三个小步骤,这里实际操作比较简单。
所有参数会自动生成。只要点击左下方的“开启一键三连”按钮即可。
添加图片注释,不超过 140 字(可选)
正常情况下,一键运行包里面已经包含了这些模型,你只要知道,下面的步骤需要用的模型放在这里就可以了。
然后继续往下看,这里又分成了三个TAB,分别是格式化,微调训练,推理。
下面我们要做的是格式化。
格式化需要指定两个路径,一个是标注文件地址,一个切割后音频文件所在地址。
同时也分成了三个小步骤,这里实际操作比较简单。
所有参数会自动生成。只要点击左下方的“开启一键三连”按钮即可。
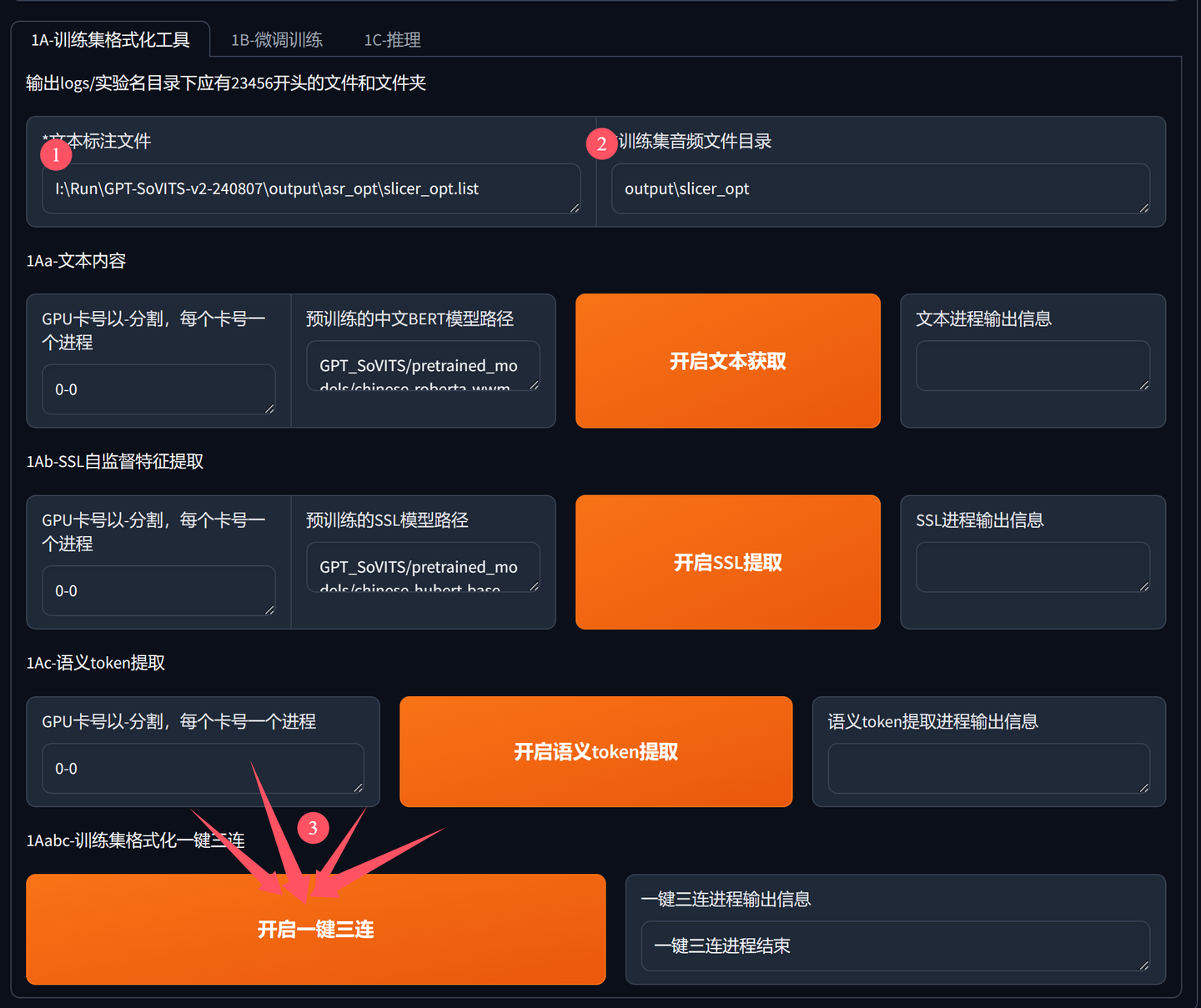 添加图片注释,不超过 140 字(可选)
执行日志如下:
添加图片注释,不超过 140 字(可选)
执行日志如下:
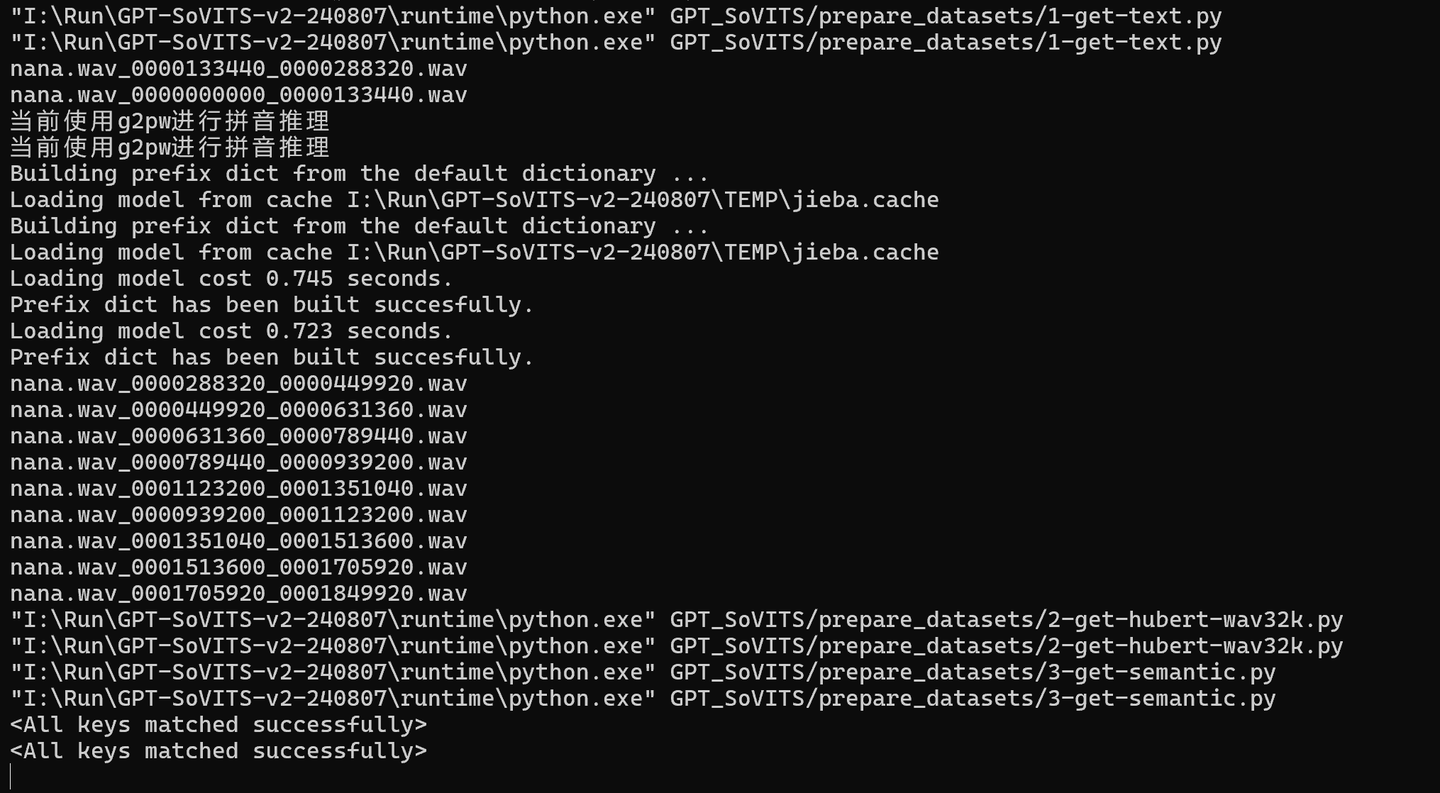 添加图片注释,不超过 140 字(可选)
执行过程如上,就证明运行正常,如果出现Error就是正面出错了。错误一般是路径问题导致!
执行成功之后,logs/nana文件下会出现1-6的文件夹和文件。
添加图片注释,不超过 140 字(可选)
执行过程如上,就证明运行正常,如果出现Error就是正面出错了。错误一般是路径问题导致!
执行成功之后,logs/nana文件下会出现1-6的文件夹和文件。
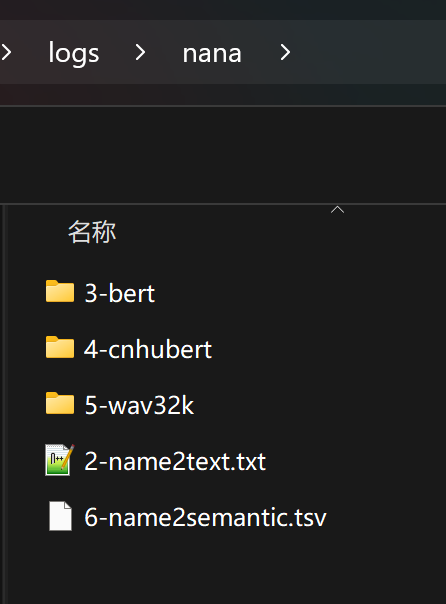 添加图片注释,不超过 140 字(可选)
文件夹nana是我们上面填写的实验名。
日志和文件生成全部正常,就可以进行下一步了。
微调训练
总的来说,前面的所有步骤,都是准备工作。准备工作做完之后,终于进入正题了。
正题就是训练,这个训练其实是基于预训练模型的微调训练。这里需要做两类训练,一个是SoVITS训练,一个是GPT训练。
点击1B-微调训练切换到微调界面,然后按下图进行操作。
SoVITS训练和 GPT训练的具体操作如下:
添加图片注释,不超过 140 字(可选)
文件夹nana是我们上面填写的实验名。
日志和文件生成全部正常,就可以进行下一步了。
微调训练
总的来说,前面的所有步骤,都是准备工作。准备工作做完之后,终于进入正题了。
正题就是训练,这个训练其实是基于预训练模型的微调训练。这里需要做两类训练,一个是SoVITS训练,一个是GPT训练。
点击1B-微调训练切换到微调界面,然后按下图进行操作。
SoVITS训练和 GPT训练的具体操作如下:
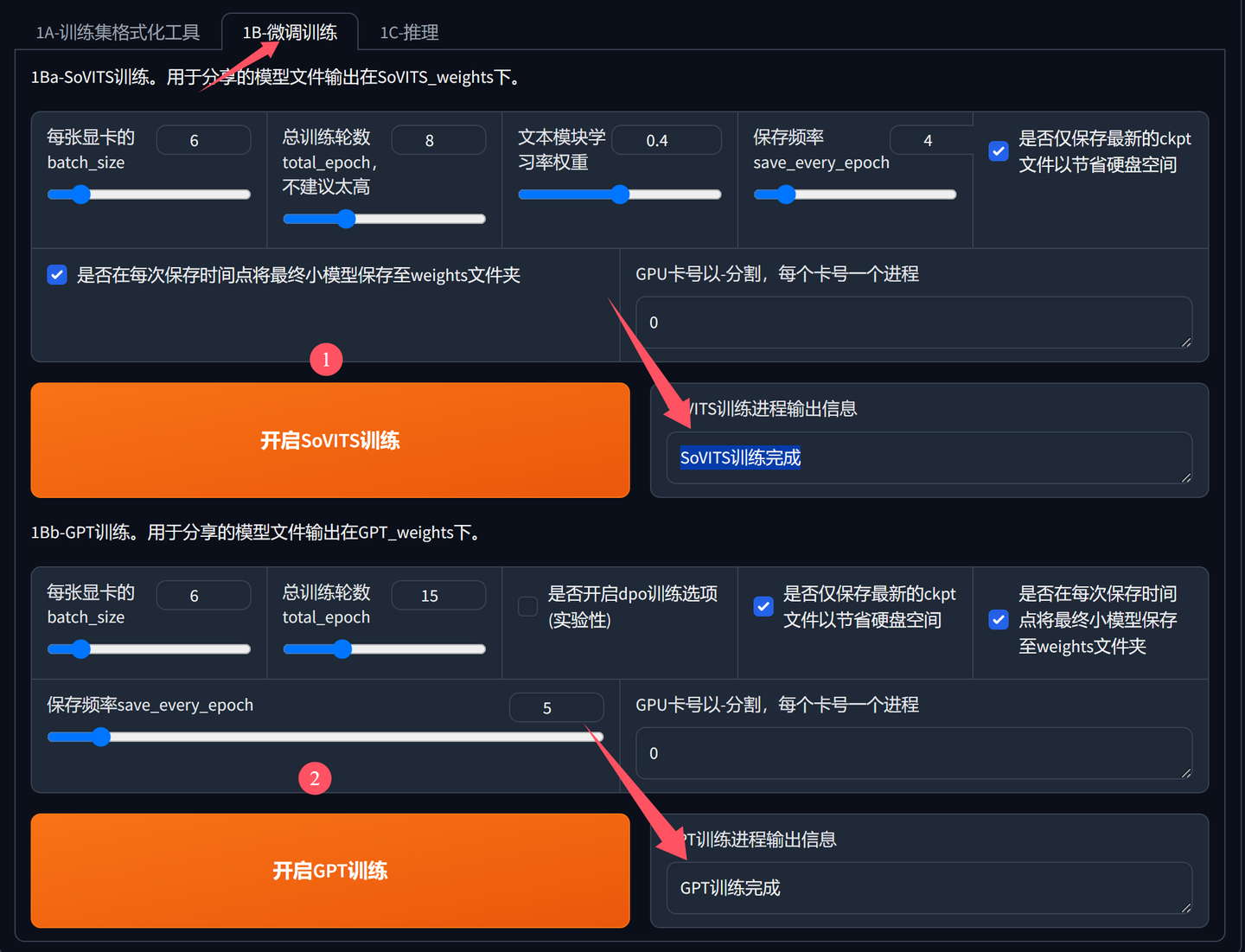 添加图片注释,不超过 140 字(可选)
这两个训练,会需要用到显卡,相对来说是整个过程中耗时比较多的部分。
有英伟达独立显卡,显卡还可以的情况下,其实也很快。比如在3060下面,只要几分钟就搞定了。
相对动不动就几个小时,几天,几个月的训练。这个微调可以说是极速微调了。
这个步骤也有一些参数,其实大部分情况下无需修改,可以适当调Batch_size 和total_epoch。数值偏离预设值很大的尝试,基本没什么必要。
这两个训练,不分前后,可以单独训练。
SoVITS训练日志如下:
添加图片注释,不超过 140 字(可选)
这两个训练,会需要用到显卡,相对来说是整个过程中耗时比较多的部分。
有英伟达独立显卡,显卡还可以的情况下,其实也很快。比如在3060下面,只要几分钟就搞定了。
相对动不动就几个小时,几天,几个月的训练。这个微调可以说是极速微调了。
这个步骤也有一些参数,其实大部分情况下无需修改,可以适当调Batch_size 和total_epoch。数值偏离预设值很大的尝试,基本没什么必要。
这两个训练,不分前后,可以单独训练。
SoVITS训练日志如下:
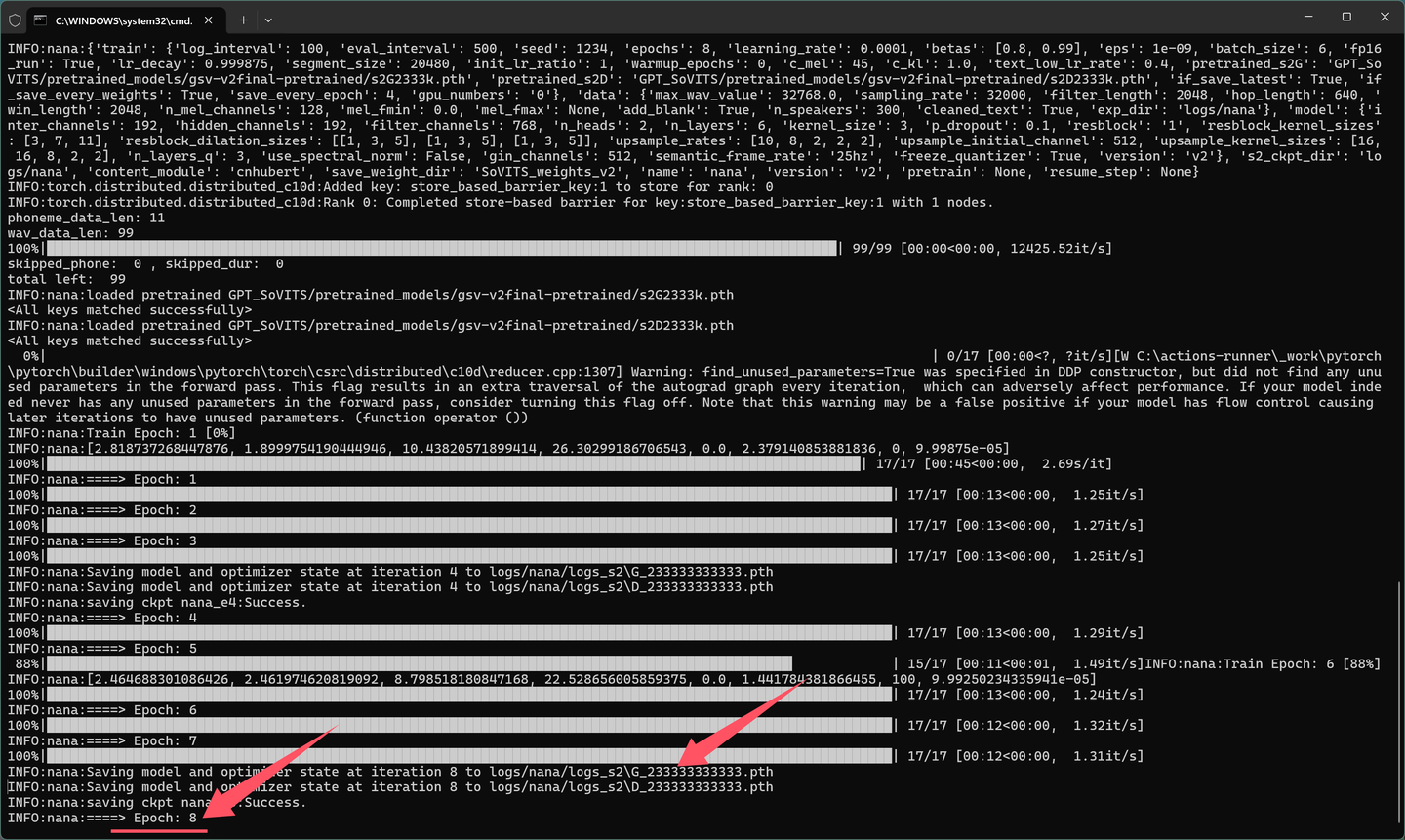 添加图片注释,不超过 140 字(可选)
训练过程成中会生成 logs_s2文件夹。
GPT训练训练日志如下:
添加图片注释,不超过 140 字(可选)
训练过程成中会生成 logs_s2文件夹。
GPT训练训练日志如下:
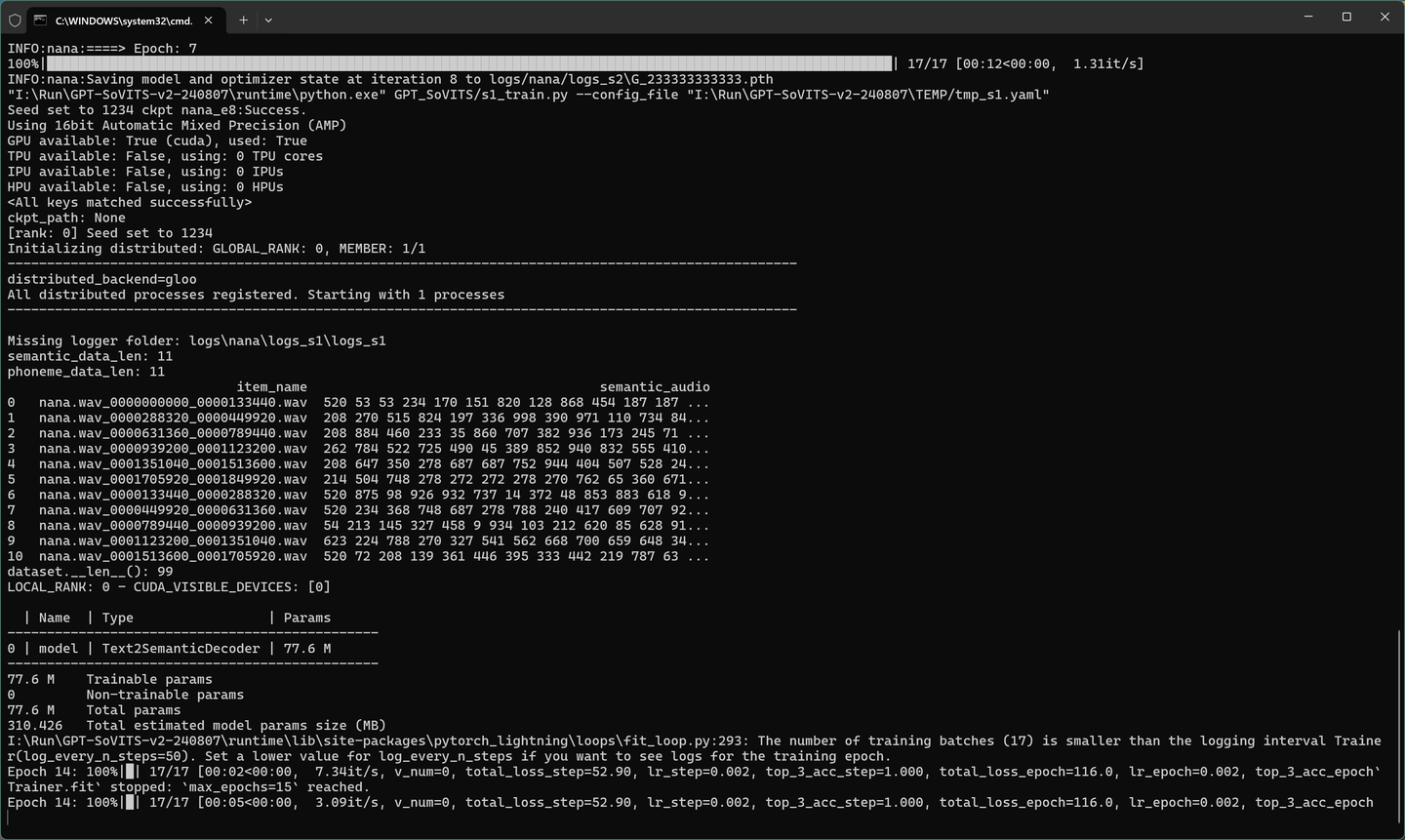 添加图片注释,不超过 140 字(可选)
训练过程成中会生成 logs_s1文件夹。
训练完成之后,页面上会有“XX训练完成”的提示。页面提示不一定准确,可以看黑色日志窗口,只要没有出现error,exception这些异常提示,输出内容简单清晰,那就是成功。
运行成功之后会生成对应的模型。
模型保存路径如下:
添加图片注释,不超过 140 字(可选)
训练过程成中会生成 logs_s1文件夹。
训练完成之后,页面上会有“XX训练完成”的提示。页面提示不一定准确,可以看黑色日志窗口,只要没有出现error,exception这些异常提示,输出内容简单清晰,那就是成功。
运行成功之后会生成对应的模型。
模型保存路径如下:
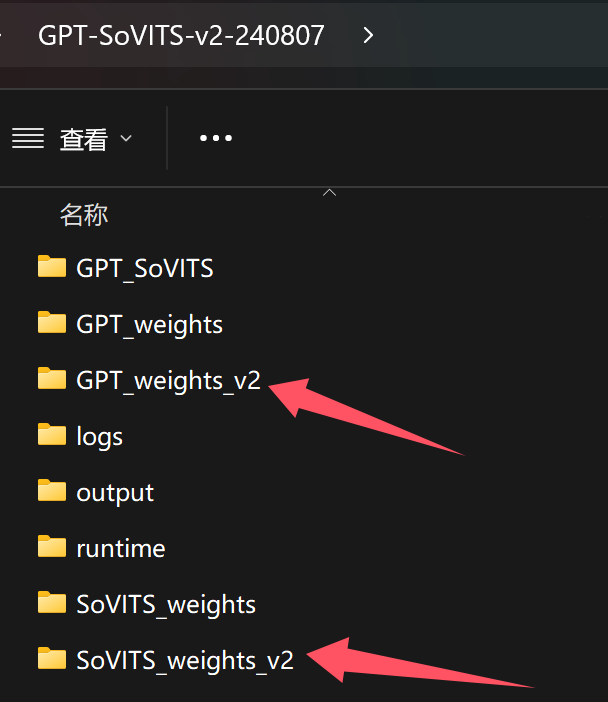 添加图片注释,不超过 140 字(可选)
我们使用的是V2训练,所以保存模型的文件夹以V2结尾。如果训练配置中,配置的为V1版本,模型就会保存在上面的文件夹中了。
这一切,都是全自动完成,无需你手动创建文件。
打开这两个文件夹,确认里面已经生成了模型文件。就基本证明微调训练成功了,接下来就是验证微调效果。
推理
所谓推理,其实就是应用训练好的模型。
点击1C-推理切换到微调界面,然后按下图进行操作:
添加图片注释,不超过 140 字(可选)
我们使用的是V2训练,所以保存模型的文件夹以V2结尾。如果训练配置中,配置的为V1版本,模型就会保存在上面的文件夹中了。
这一切,都是全自动完成,无需你手动创建文件。
打开这两个文件夹,确认里面已经生成了模型文件。就基本证明微调训练成功了,接下来就是验证微调效果。
推理
所谓推理,其实就是应用训练好的模型。
点击1C-推理切换到微调界面,然后按下图进行操作:
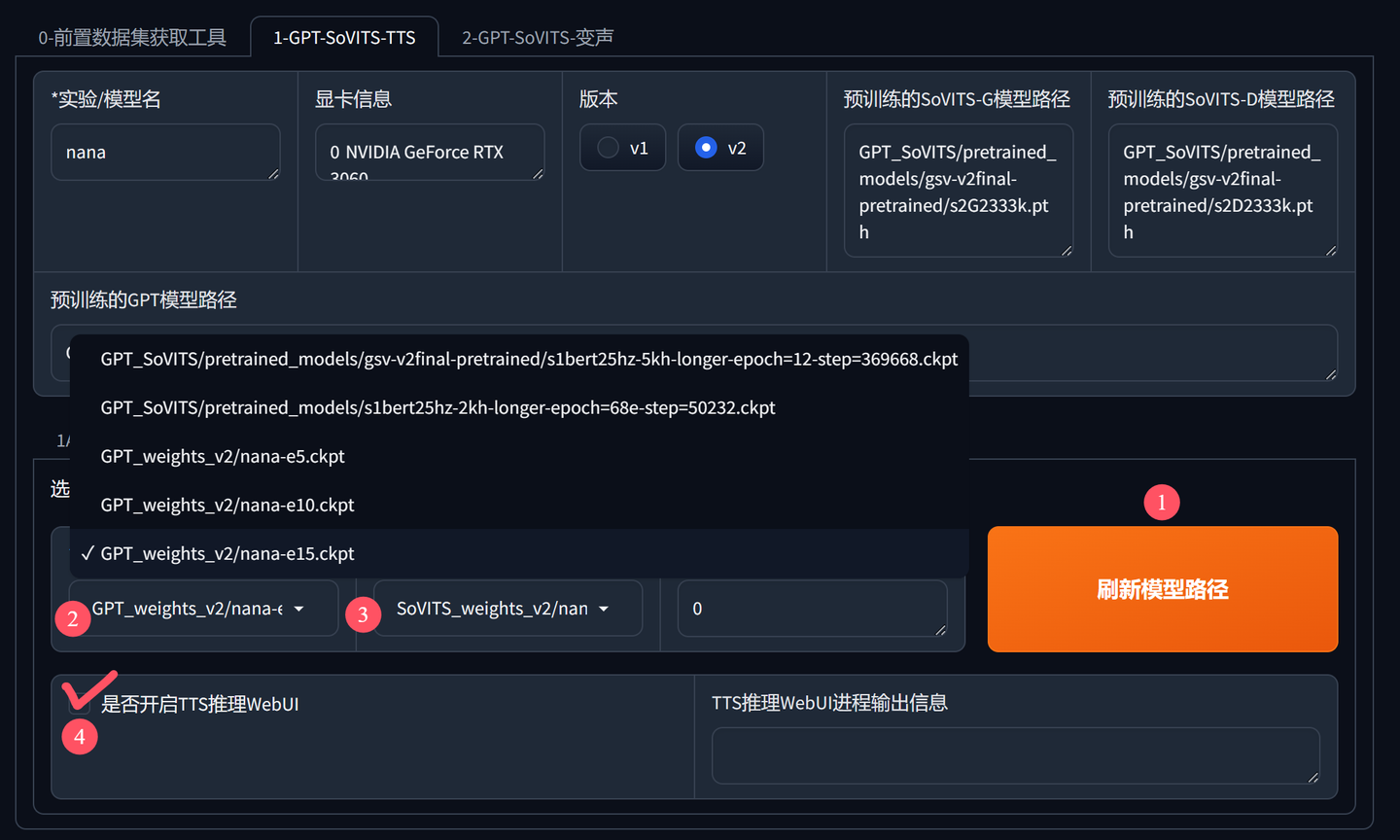 添加图片注释,不超过 140 字(可选)
①刷新模型路径,这个别忘了点。只有刷新后才能看到自己训练的模型。
②选择GPT模型,一般选数字最大的,比如这里的e15。
③选择SoVITS模型,同样道理,选尾巴上数字最大的模型。
④勾选开启TTS推理界面,勾选后会自动跳出一个新的界面。
在跳出的新界面中,依旧有刷新模型和模型列表选项。前面设置过,这里就不用设置了。如果你有很多模型的情况下,可以在这个界面单独切换模型。
在这个界面中,主要完成两个操作,一个是设置参考声,一个是填写文字合成克隆声音。
参考声音设置:
添加图片注释,不超过 140 字(可选)
①刷新模型路径,这个别忘了点。只有刷新后才能看到自己训练的模型。
②选择GPT模型,一般选数字最大的,比如这里的e15。
③选择SoVITS模型,同样道理,选尾巴上数字最大的模型。
④勾选开启TTS推理界面,勾选后会自动跳出一个新的界面。
在跳出的新界面中,依旧有刷新模型和模型列表选项。前面设置过,这里就不用设置了。如果你有很多模型的情况下,可以在这个界面单独切换模型。
在这个界面中,主要完成两个操作,一个是设置参考声,一个是填写文字合成克隆声音。
参考声音设置:
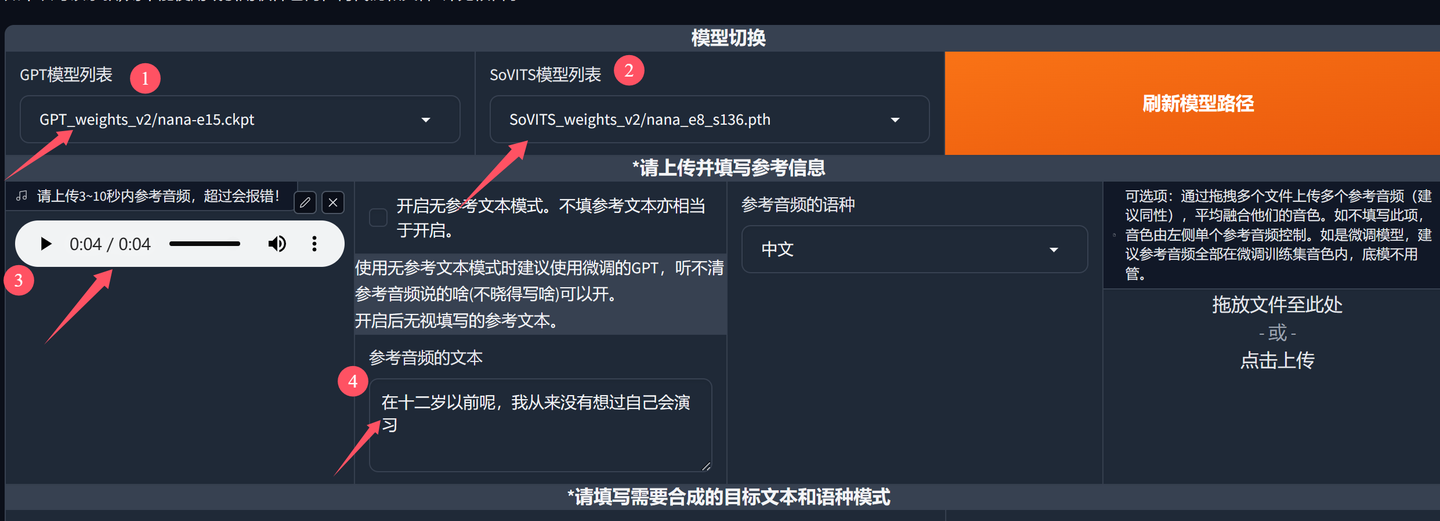 添加图片注释,不超过 140 字(可选)
在③的地方上传一个几秒钟的声音文件作为参考声音,然后在④的地方输入这个参考声音对应的文本内容。这一部分的设置就算完成了。
④这里的操作也并非必须,不填也不会爆炸。
参考声音,可以从前面切割好的音频文件中随便选一个。当然最好选清晰且有代表性的片段。所谓代表性,就是最能体现这个克隆对象音色的部分。
设置好参考对象之后,就可以生成克隆声音了。
具体设置如下:
添加图片注释,不超过 140 字(可选)
在③的地方上传一个几秒钟的声音文件作为参考声音,然后在④的地方输入这个参考声音对应的文本内容。这一部分的设置就算完成了。
④这里的操作也并非必须,不填也不会爆炸。
参考声音,可以从前面切割好的音频文件中随便选一个。当然最好选清晰且有代表性的片段。所谓代表性,就是最能体现这个克隆对象音色的部分。
设置好参考对象之后,就可以生成克隆声音了。
具体设置如下:
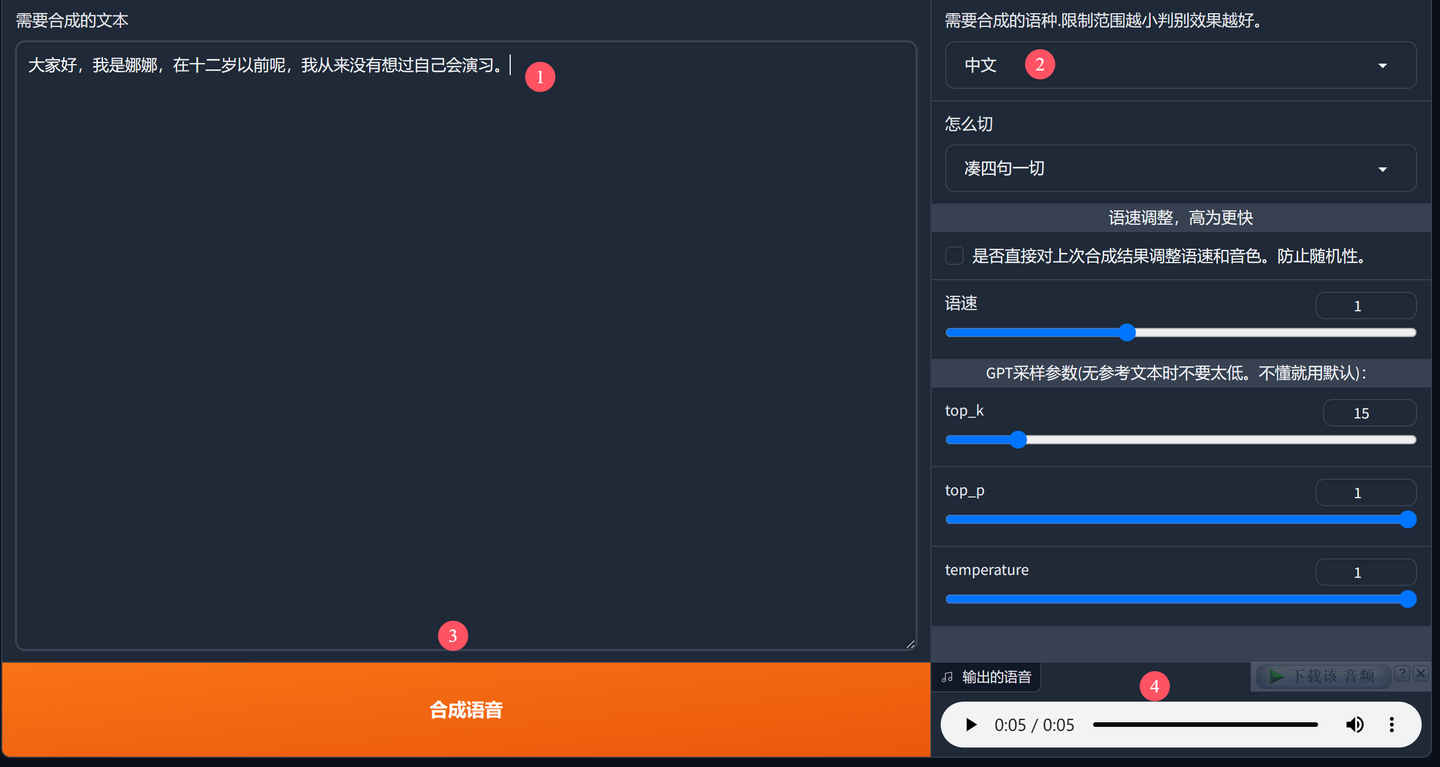 添加图片注释,不超过 140 字(可选)
①输入文本,就是输入要合成的内容。稍微长点也没关系,会自动切割处理。
②设置参数,参数一般不用改,输入的是中文,语言就选中文。怎么切,是指点文本切割的方式,语速可以根据自己的需要调整。K,P,T参数一般不用调。
③合成语音,点击按钮,一会儿就搞定了。
④播放语音,最后点击播放验证效果。
到这里,整个声音克隆的准备,微调,合成就已经完成了。GPT-SoVITS的声音克隆,是基于文本转语音的克隆方式,而不是直接改变语音的音色。直接改变音色,我们一般归类为变声,比如我们之前介绍的RVC项目,这个项目类似的功能还在“施工中”可以期待一下。
因为我常年倒腾这些项目,已经练就了一些被动避坑技能。所以在使用这个项目的过程中非常丝滑,并没有遇到任何问题。所以也没有太多异常处理建议。如果你们遇到了,可以留言,或者阅读官方手册。
从拿到软件,开始自己跑demo,记录完整的过程,写文章,修改内容,花了三天时间,打了4000多字。看到这里的可以动动手指哦。
收工收工,玩得愉快!
添加图片注释,不超过 140 字(可选)
①输入文本,就是输入要合成的内容。稍微长点也没关系,会自动切割处理。
②设置参数,参数一般不用改,输入的是中文,语言就选中文。怎么切,是指点文本切割的方式,语速可以根据自己的需要调整。K,P,T参数一般不用调。
③合成语音,点击按钮,一会儿就搞定了。
④播放语音,最后点击播放验证效果。
到这里,整个声音克隆的准备,微调,合成就已经完成了。GPT-SoVITS的声音克隆,是基于文本转语音的克隆方式,而不是直接改变语音的音色。直接改变音色,我们一般归类为变声,比如我们之前介绍的RVC项目,这个项目类似的功能还在“施工中”可以期待一下。
因为我常年倒腾这些项目,已经练就了一些被动避坑技能。所以在使用这个项目的过程中非常丝滑,并没有遇到任何问题。所以也没有太多异常处理建议。如果你们遇到了,可以留言,或者阅读官方手册。
从拿到软件,开始自己跑demo,记录完整的过程,写文章,修改内容,花了三天时间,打了4000多字。看到这里的可以动动手指哦。
收工收工,玩得愉快!
软件和官方文档
见博客文末:https://www.tonyisstark.com/2864.html
标签:训练,140,模型,注释,文件夹,SoVITS,GPT,2.0,克隆 From: https://www.cnblogs.com/wangpg/p/18374830