大家好,我是程序员鱼皮,8 月 19 日下午,网易云音乐突发严重故障,并登顶微博热搜,跟黑神话悟空抢了热度。
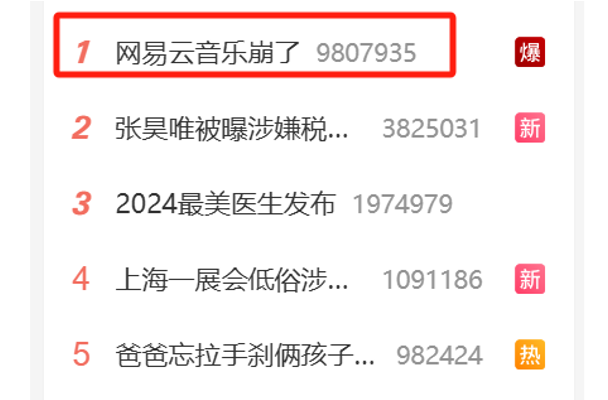
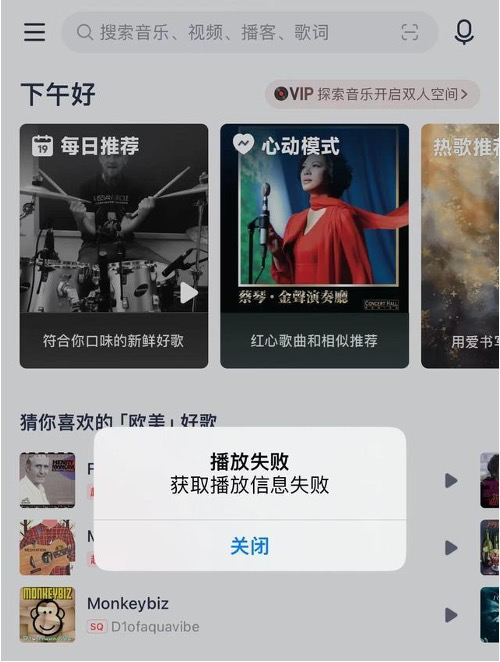
根据用户的反馈,故障的具体表现为:用户无法登录、歌单加载失败、播放信息获取失败、无法搜索歌曲等等,几乎是无法使用了,妥妥的 P0 级事故!
根据官方发布的说明,本次故障的主要原因是基础设施,导致网易云音乐各端无法正常使用:
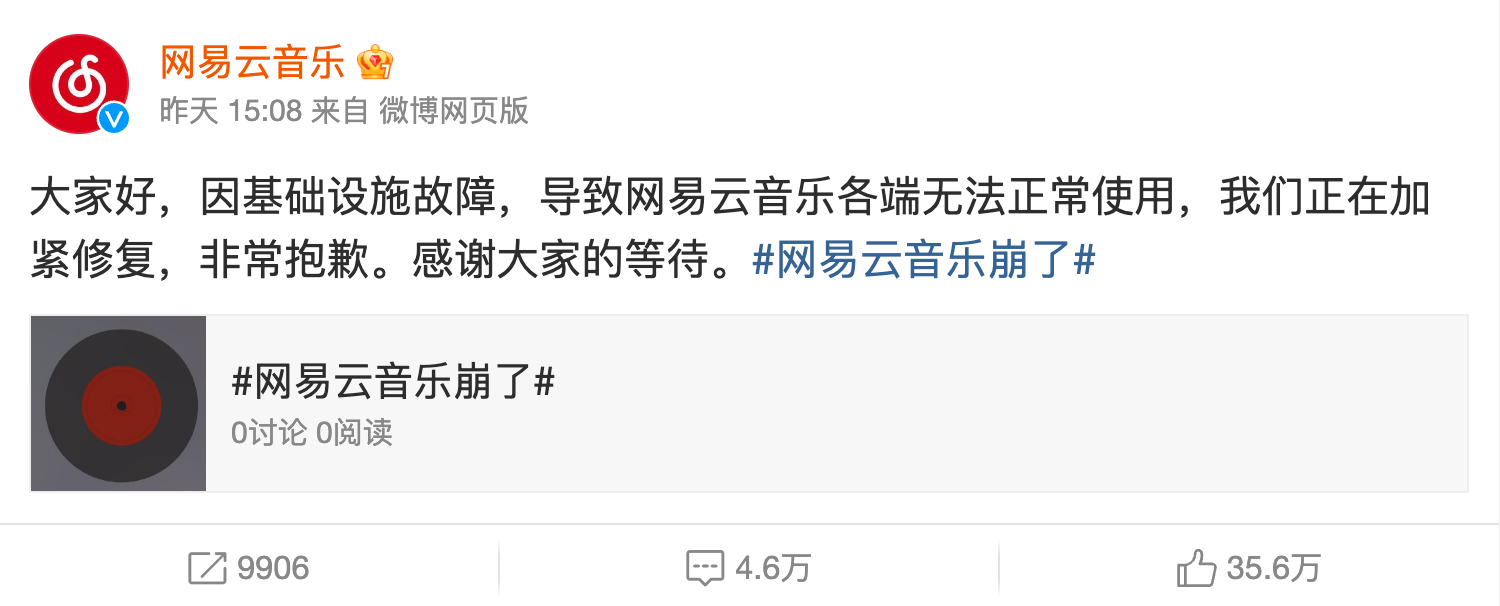
什么是基础设施?是指支持整个系统运行的基础性服务和资源,包括服务器、网络设备、数据库、存储系统、内容分发网络(CDN)、各种云服务、缓存、DNS、负载均衡等等。像之前 B 站和小红书大规模故障,就是因为某云服务商的网络出了问题,可见基础设施的重要性。
我不是内部人员,所以具体的故障原因不得而知,网上有很多猜测,什么 “开发删库跑路”、“搬迁到新机房产生了问题”、“裁员导致降本增笑” 等等,但这些说法被官方否认了。
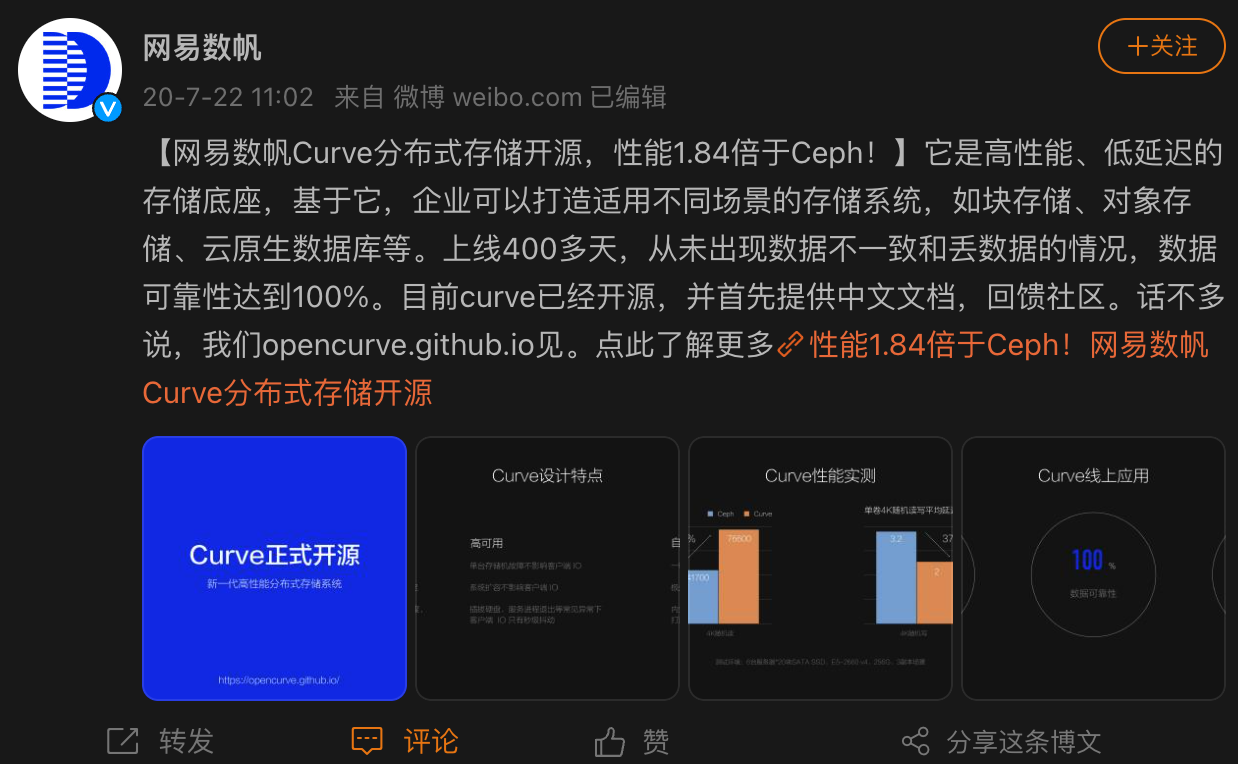
根据网上的消息,这次的故障可能与网易云自研的 Curve 存储系统有关,当时网易官方称该存储系统上线 400 多天,从未出现数据不一致和丢数据的情况,数据可靠性达到 100%,服务可用性高达 4 个 9(99.99%)。
按理说稳定运行了这么久的系统不应该自己出问题,据说是一位同学按照前人的文档执行了一个运维操作,导致了存储系统的故障。一般来说,这么重要的基础设施的变更发布需要走非常完备的流程,而且不会让不熟悉的人按照前人的文档执行,除非有一种情况,就是 “前人” 已经不在了。根据网上消息,该部门曾经历过裁员,更有小道消息说,该部门仅存的人员寥寥无几。
真相我们不得而知,不过听上去挺合理的。因为一般情况下,大厂内部是有灰度发布、容灾演练的,不会直接影响到所有用户。
-
灰度发布是指在更新 IT 基础设施时,采用逐步部署的方式,先在一部分设备上进行变更,观察其效果。如果一切正常,才逐步扩大变更范围。
-
容灾演练是指对基础设施在灾难发生时的应急响应和恢复能力进行测试和验证,确保在关键的基础设施发生故障或灾难时,系统能够迅速恢复,减少业务中断的影响。
大厂的架构师,尤其是基础设施团队的人员,一定是知道这些操作的,但为什么没有执行呢?可能是因为人手不够、也可能是因为懒、还可能是因为现在的人缺失经验、还有可能是前人留下的文档不全。总之,系统的稳定性和 “人” 有很大的关系。
让我又想到了上次微软全球蓝屏的事情,果然严重的 Bug 往往只需要一两名程序员、或者一些小的操作。
整个故障恢复历时整整 2 个小时,已经是比较慢了,采用预备方案恢复服务、或者屏蔽部分故障、或者回滚发布,应该都要不了这些时间,估计是数据出了问题吧。如果在故障中数据出现了损坏或不一致,恢复服务的难度的确会大大增加,为了确保数据完整性,可能需要进行数据恢复、重建索引、同步数据等操作,而这些都可能会延长故障恢复的时间。
目前还没有看到官方的故障报告,所以这一切只是猜测了。
故障恢复后,网易云音乐很快发布了补偿措施 —— 用户可以免费领取 7 天会员权益! 注意,只能在 8 月 20 日领取!
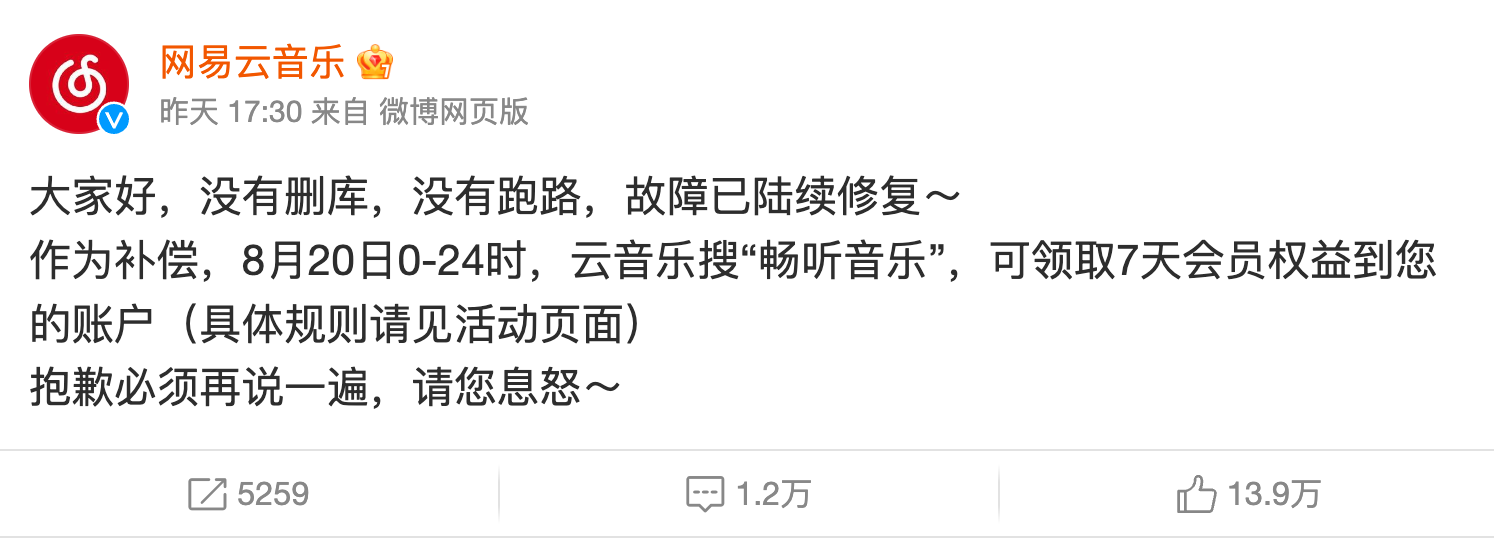
进入云音乐就能在搜索条看到领会员的入口了,虽然只有 7 天,差点儿意思,但作为一名网易云音乐 10 级会员,我必须领爆!
从这个事情也能看出来,一旦故障发生了,头大的可不只有开发和运维人员!产品同学需要快速制定补偿策略,确保用户满意;运营和客服要紧急应对用户的疑问和投诉,安抚情绪;而公关则必须迅速应对舆论压力,控制事态发展,防止负面影响扩散。同时,管理层还需统筹协调各部门,确保问题得到全面处理。
我们自己也做了很多产品,也发生过故障,我们这小规模应对起来都汗流浃背了,很难想象网易云音乐这种国民级产品背后的团队,昨天承受了多大压力。劳力越戴,责任越大呀!
朋友们,你们怎么看待这次故障,有怀疑过自己网络或设备的问题么?