正则表达式02
5.4正则表达式语法02
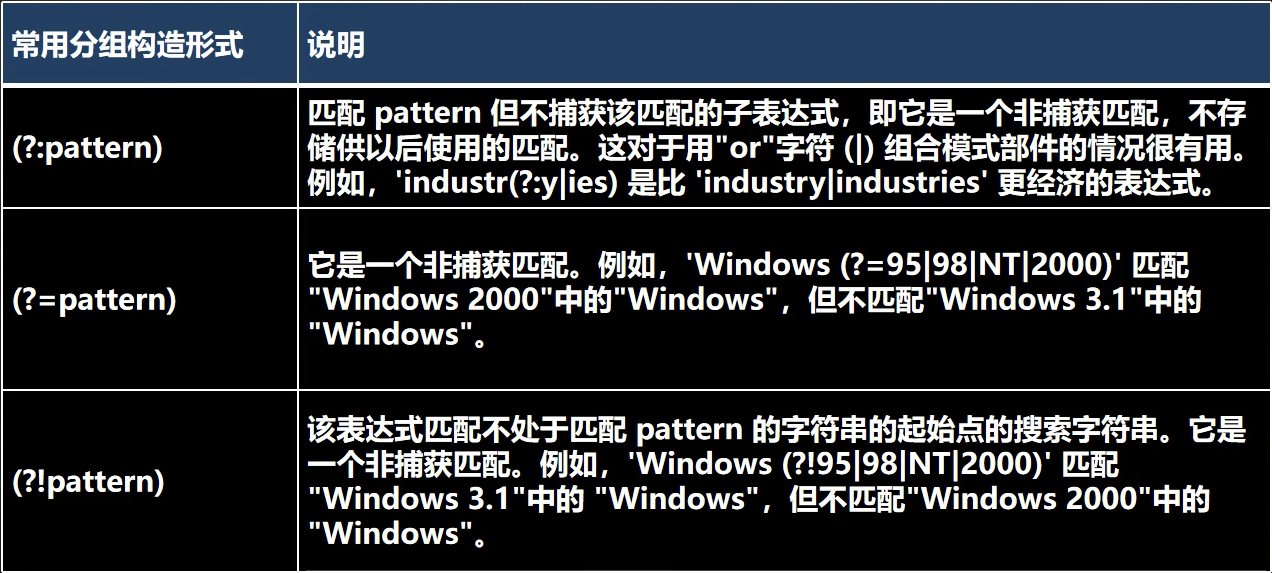
5.4.6捕获分组
详见5.3.3

例子
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//演示分组
public class RegExp07 {
public static void main(String[] args) {
String content = "hanshunping s7789 nn1189han";
//下面就是非命名分组
//说明
// matcher.group(0) 是不加括号匹配到的字符串
// matcher.group(1) 是不加括号匹配到的字符串的第一个分组的内容
// matcher.group(2) 是不加括号匹配到的字符串的第二个分组的内容
//String regStr = "(\\d\\d)(\\d\\d)";//匹配4个数字的字符串
//命名分组:即可以给分组取名(名称随意)
String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";//匹配4个数字的字符串
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
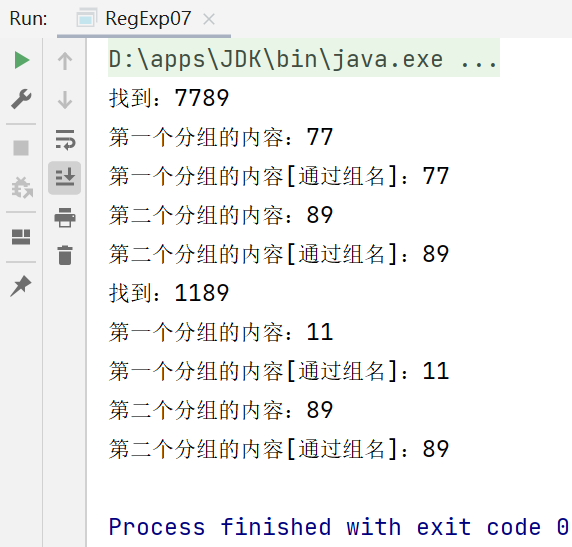
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
System.out.println("第一个分组的内容:" + matcher.group(1));
System.out.println("第一个分组的内容[通过组名]:" + matcher.group("g1"));
System.out.println("第二个分组的内容:" + matcher.group(2));
System.out.println("第二个分组的内容[通过组名]:" + matcher.group("g2"));
}
}
}
5.4.7非捕获分组
例子
给定一个字符串String content ="hello韩顺平教育 jack韩顺平老师 韩顺平同学hello";
使用非捕获分组完成,有如下要求:
- 找到韩顺平教育、韩顺平老师、韩顺平同学 子字符串
- 找到韩顺平 这个关键字,但是要求只是查找韩顺平教育和韩顺平老师中包含的韩顺平
- 找到韩顺平这个关键字,但是要求只是查找不是(韩顺平教育和韩顺平老师)中包含有的韩顺平
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp08 {
public static void main(String[] args) {
String content = "hello韩顺平教育 jack韩顺平老师 韩顺平同学hello";
// 1. 找到 韩顺平教育、韩顺平老师、韩顺平同学 子字符串
//String regStr = "韩顺平教育|韩顺平老师|韩顺平同学";
//上面的写法可以等价于非捕获分组,注意:不能matcher.group(1)
//String regStr = "韩顺平(?:教育|老师|同学)";
// 2. 找到 韩顺平 这个关键字,但是要求只是查找 韩顺平教育 和 韩顺平老师 中包含的韩顺平
//下面也是非捕获分组,也不能matcher.group(1)
//String regStr = "韩顺平(?=教育|老师)";
// 3. 找到 韩顺平 这个关键字,但是要求只是查找不是(韩顺平教育和韩顺平老师)中包含有的韩顺平
//下面也是非捕获分组,也不能matcher.group(1)
String regStr = "韩顺平(?!教育|老师)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
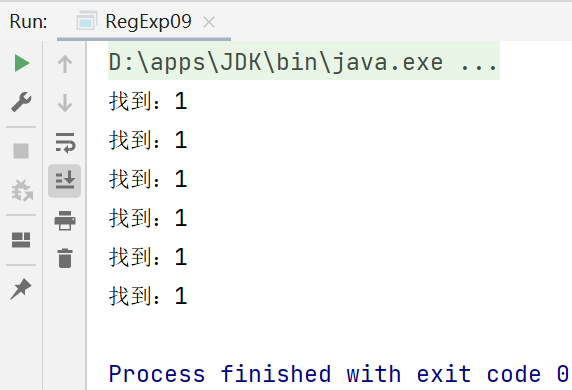
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
5.4.8非贪婪匹配
| 字符 | 说明 |
|---|---|
| ? | 当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。 |
例子
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp09 {
public static void main(String[] args) {
String content = "hello111111 ok";
//String regStr = "\\d+";//默认是贪婪匹配
String regStr = "\\d+?";//非贪婪匹配
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
5.5正则应用实例
- 对字符串进行如下验证
-
汉字
-
邮政编码
要求:是1-9开头的一个六位数,比如:123890
-
QQ号码:
要求:是一个1-9开头的一个(5位数-10位数),比如:12389,1345687,187698765
-
手机号码
要求:必须以13,14,15,18开头的11位数,比如:13588889999
例子1:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//正则表达式的应用实例
public class RegExp10 {
public static void main(String[] args) {
String content = "1358888999";
//1. 汉字
//String regStr="^[\u4e00-\u9fa5]+$";//^和 $同时出现时,表示只能匹配 ^和 $之间的内容
//2. 邮政编码
//要求:是1-9开头的一个六位数,比如:123890
//String regStr="^[1-9]\\d{5}$";
//3. QQ号码:
//要求:是一个1-9开头的一个(5位数-10位数),比如:12389,1345687,187698765
//String regStr = "^[1-9]\\d{4,9}$";
//4. 手机号码
//要求:必须以13,14,15,18开头的11位数,比如:13588889999
String regStr = "^1[3458]\\d{9}$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
System.out.println("满足格式");
} else {
System.out.println("不满足格式");
}
}
}
例子2:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp11 {
public static void main(String[] args) {
String content = "https://www.bilibili.com/video/BV1fh411y7R8?p=894&spm_id_from=pageDriver&vd_source=7e137c3a1559f85aacb1f151bb0a830d";
String content2 = "https://10fastfingers.com/typing-test/simplified-chinese";
String content3 = "https://zh.ua1lib.org/";
/**
* 思路:
* 1.先确定URL的开始部分 https:// 或 http://
* ((https|http)://)
* 2.接着是域名部分 www.bilibili.com
* www. 和 bilibili. 可以写成 ([\\w-]+\\.)+
* [\\w-]+ 则匹配 com
* 3.接着是域名后面
* 3.1首先是整体
* ()?表示()里面的出现零次或者一次
* 3.2然后是小括号里面
* \\/ 表示匹配 / 号
* [ ]* 表示匹配中括号里面的 0-n次
* 3.3中括号里面
* \w-?=&/:.# 表示匹配 `数字` 或 `大小写字母` 或 `下划线` 或 `-` 或 `?` 或 `=` 或 `&` 或 `/` 或 `:` 或 `.` 或 `#`
*/
String regStr="^((https|http)://)([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/:.#]*)?$";//注意:中括号里面的字符都是它本省的含义,不用转义
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content3);
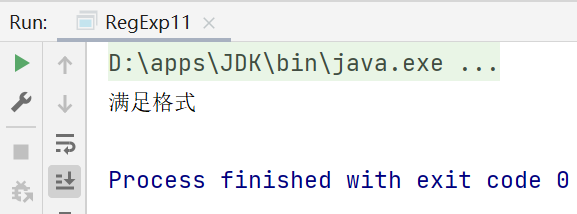
if (matcher.find()) {
System.out.println("满足格式");
} else {
System.out.println("不满足格式");
}
}
}
注意:中括号里面的字符都是它本省的含义,不用转义
标签:02,group,String,正则表达式,matcher,Pattern,regStr,day51,顺平 From: https://www.cnblogs.com/liyuelian/p/16819696.html