zabbix-agent自定义配置监控项
1. 环境准备
本例中安装zabbix开源软件和zabbix运行所需的中间件和数据库apache、php和postgres,软件版本信息如下:
| 软件 | 版本 |
|---|---|
| zabbix | Zabbix6.4.0 |
| apache | httpd-2.4.57 |
| apr | apr-1.7.4 |
| apr-util | 1.6.3 |
| php | 8.2.6 |
| sqlite-autoconf | 3420000 |
| gcc | 11 |
| postgres | 14.7 |
| zabbix-agent | 6.4.17 |
主机信息如下:
Red Hat Enterprise Linux Server 7.9 (Maipo)
| 主机名 | 主机地址 | 用途 |
|---|---|---|
| zib_server | 192.168.101.238 | zabbix的服务器地址 |
| pgsql_master | 192.168.101.232 | pgsql的主服务器 |
| pgsql_backup | 192.168.101.239 | pgsql的备服务器 |
2. agent的zabbix-agent.cong文件配置
要启用自定义配置,需要修改配置文件。
vi /usr/local/etc/zabbix_agentd.conf
# 修改
UnsafeUserParameters=1
如果提到了 “UnsafeUserParameters”,通常指的是允许用户定义的自定义参数或命令,这些参数可以在 Zabbix Agent 配置中通过 UserParameter 指令定义。这些自定义参数允许用户根据需要执行各种操作或收集特定的监控数据,但同时也增加了安全风险,因为不当配置可能导致安全漏洞或不可预料的系统行为。
为了避免潜在的安全问题,Zabbix Agent 在默认情况下禁用了对于 UserParameter 的使用,即使在配置文件中出现了相关的设置,也不会生效,除非明确地在配置中将其设置为允许 (UnsafeUserParameters=1)。在启用这些不安全的用户参数时,开发人员和系统管理员必须格外小心,确保仅允许受信任和经过验证的命令和参数,以减少潜在的安全风险。
3. psql环境准备
根据解决zabbix用户无法使用psql命令的问题.md文档来进行操作。
4. 创建文件夹
创建shell脚本目录,创建zabbix-agent自定义配置项目录。(如果有了不需要创建)
su - root
mkdir -p /usr/local/zabbix/etc/shell_dict
mkdir -p /usr/local/zabbix/etc/zabbix_agent.d
chown zabbix:zabbix /usr/local/zabbix/etc/shell_dict
chown zabbix:zabbix /usr/local/zabbix/etc/shell_dict
5. 创建soltStatus.conf文件
su zabbix
cd /usr/local/zabbix/etc/zabbix_agent.d
vi soltStatus.conf
cat soltStatus.conf
UserParameter=soltStatus[*],"$1"/soltStatus.sh "$2"
6. 创建soltStatus.sh文件
su zabbix
cd /usr/local/zabbix/etc/shell_dict
vi soltStatus.sh
# 创建完成之后重启zabbix_agentd服务
ps aux | grep zabbix_agentd
kill 进程pid
/etc/init.d/zabbix_agentd
shell脚本内容如下:
#!/bin/bash
PGSHELL_CONFDIR="$1"
source $PGSHELL_CONFDIR/zabbix_shell.conf
query="SELECT active FROM pg_replication_slots where slot_name='pgbackup';"
# 执行查询,并获取结果
result=$($PSQL -t -c "${query}" | tr -d '[:space:]')
# 检查结果并输出状态
if [ "$result" == "t" ]; then
# echo "Replication slot '$SLOT_NAME' is active."
echo "T"
elif [ "$result" == "f" ]; then
# echo "Replication slot '$SLOT_NAME' is inactive."
echo "F"
else
# echo "Unexpected result: $result"
echo "F"
fi
7. 在server的web端创建宏
在server的web端中,点击监听的主机,再点击宏,添加宏。如下图所示
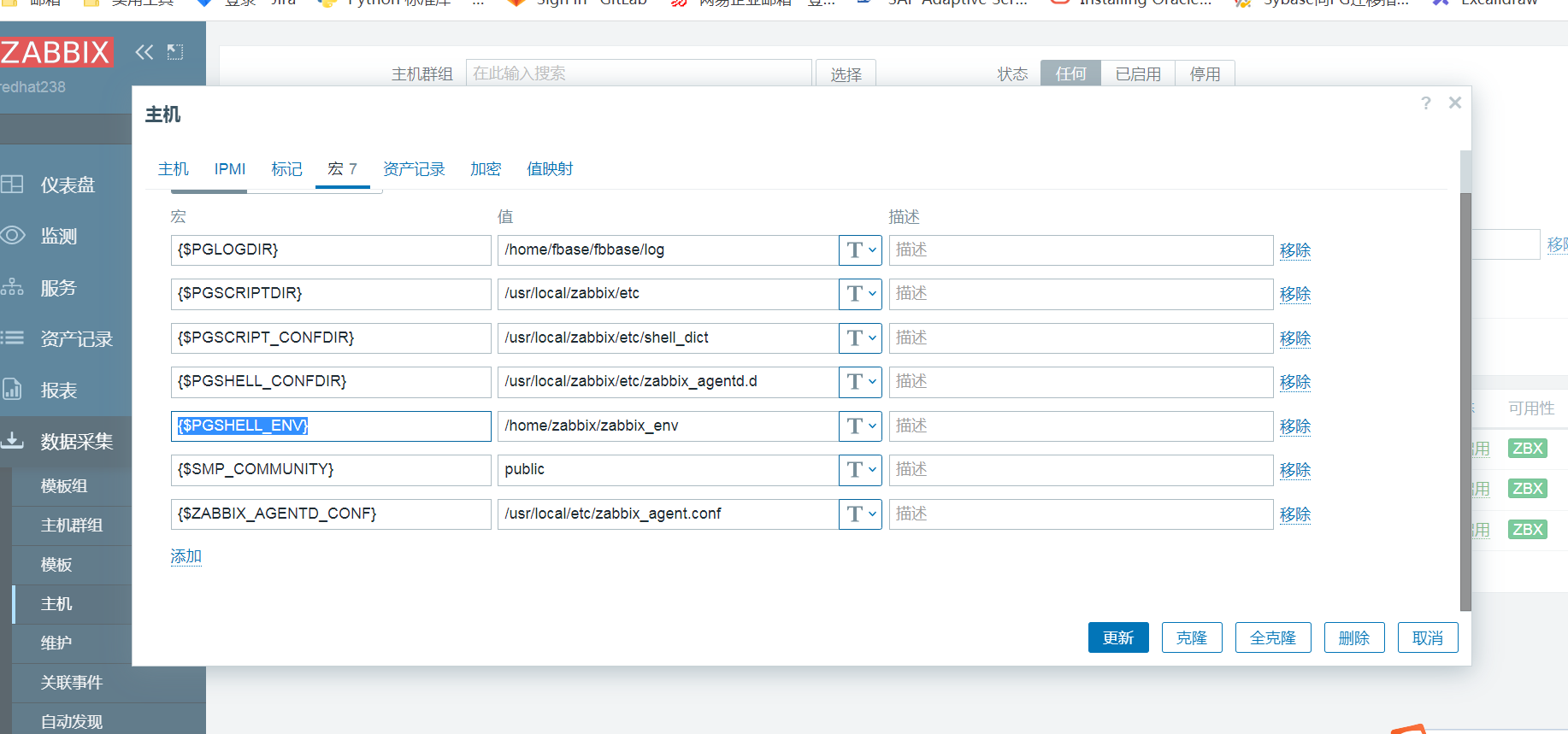
8. 创建监控项
点击主机,然后点击监控项进行监控项页面,再点击右上角的创建监控项进入创建监控项页面。如下图所示。
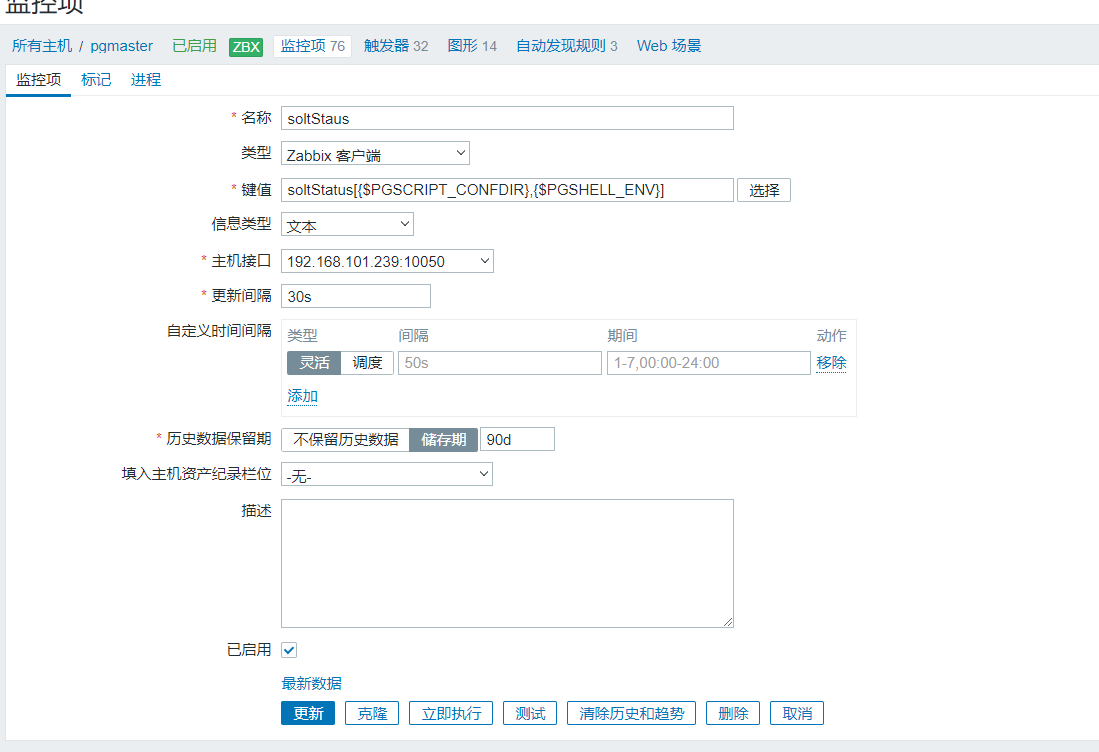
创建完成之后进行测试。如下图所示。
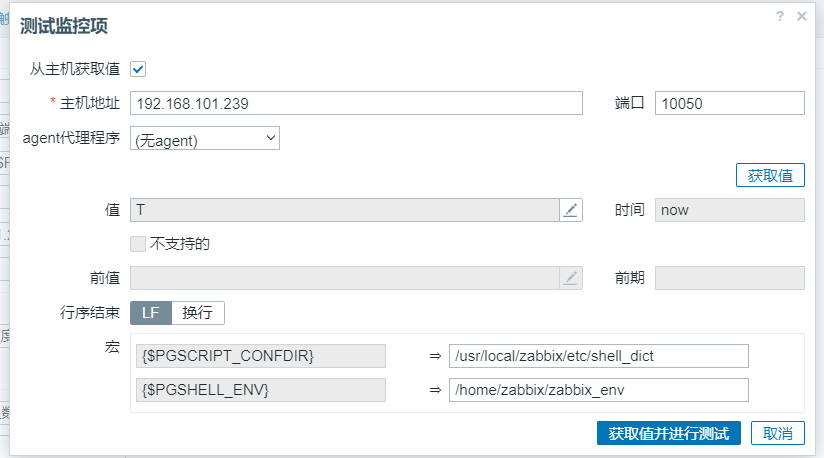
在zabbix-service端使用agent_get命令来进行测试。
[zabbix@zib-server root]$ zabbix_get -s 192.168.101.239 -k 'soltStatus['/usr/local/zabbix/etc/shell_dict','/home/zabbix/zabbix_env']'
T
附录1 pg_replication_slots
pg_replication_slots视图提供了当前存在于数据库集簇上的所有复制槽的列表,其中也包括复制槽的当前状态。
| 字段 | 类型 | 描述 |
|---|---|---|
| slot_name | name | 一个唯一的、集簇范围内的复制槽标识符。 |
| plugin | name | 包含这个逻辑槽正在使用的输出插件的共享对象基础名称,对于物理槽为空值。逻辑解码器输出插件。 |
| slot_type | text | 槽类型 - physical或者logical。replication类型。 |
| datoid | oid | 与这个槽相关的数据库的OID,或者为空值。只有逻辑槽具有相关的数据库。slot所关联数据库的OID。 |
| database | name | 与这个槽相关的数据库的名称,或者为空值。只有逻辑槽具有相关的数据库。 |
| temporary | bool | 如果这是一个临时复制槽则为真。临时槽不会被保存在磁盘上并且会在出错或会话结束时自动被删除掉。 |
| active | bool | 如果这个槽当前正在被使用则为真。 |
| active_pid | int4 | 如果槽当前正在被使用,则记录使用这个槽的会话的进程 ID。如果不活动则为NULL。对应流复制进程ID。 |
| xmin | xid | 这个槽要需要数据库保留的最旧事务。VACUUM不能移除被其后续事务删除的元组。 |
| catalog_xmin | xid | 这个槽要需要数据库保留的影响系统目录的最旧事务。VACUUM不能移除被其后续事务删除的目录元组。 |
| restart_lsn | pg_lsn | 可能仍被这个槽的消费者要求的最旧WAL地址(LSN),并且因此不会在检查点期间自动被移除。 如果这个槽的LSN从未被保留过,则为NULL。对应数据库能访问到的最老的数据点。 |
| confirmed_flush_lsn | pg_lsn | 代表逻辑槽的消费者已经确认接收数据到什么位置的地址(LSN)。 比这个地址更旧的数据已经不再可用。对于物理槽这里是NULL。此流复制能访问到的最老的数据位置。 |
| wal_status | text | 此插槽声称的 WAL 文件的可用性。可能的值为:reserved 意味着声称的文件包含 max_wal_size。 extended意味着max_wal_size已超出,但文件仍保留,通过复制插槽或wal_keep_size。 unreserved意味着该插槽不再保留所需的 WAL 文件,并且将在下一个检查点删除其中一些文件。 此状态可以返回到reserved或extended。 lost意味着某些需要的 WAL 文件已被删除,并且此插槽不再可用。最后两种状态仅在 max_slot_wal_keep_size为非负值时才看到。 如果restart_lsn为 NULL,则此字段为空。 |
| safe_wal_size | int8 | 可写入 WAL 的字节数,以便此插槽不会处于"丢失"状态的危险中。 对丢失插槽它是NULL,以及如果max_slot_wal_keep_size是-1。 |
| two_phase | bool | 如果该插槽为解码准备事务所启用则为真。物理插槽总是为假。 |
附录2 pg_stat_replication
| 字段名 | 类型 | 描述 |
|---|---|---|
| pid | integer | WAL 发送进程的进程 ID。 |
| usesysid | oid | 登录到此 WAL 发送进程的用户 OID。 |
| usename | name | 登录到此 WAL 发送进程的用户名。 |
| application_name | text | 连接到此 WAL 发送进程的应用程序的名称。 |
| client_addr | inet | 连接到此 WAL 发送方的客户端的 IP 地址。如果此字段为空,则表示客户端通过服务器计算机上的 Unix 套接字进行连接。 |
| client_hostname | text | client_addr 的反向 DNS 查找报告的已连接客户端的主机名。此字段仅对 IP 连接为非 null,并且仅在启用 log_hostname 时为非 null。 |
| client_port | integer | 客户端用于与此 WAL 发送方通信的 TCP 端口号,或如果使用 Unix 套接字,则为 -1。 |
| backend_start | timestamp with time zone | 此进程启动的时间,即客户端连接到此 WAL 发送方的时间。 |
| backend_xmin | xid | 此备用服务器的 xmin 水平,由 hot_standby_feedback 报告。 |
| state | text | 当前 WAL 发送方状态。可能的值为:startup:此 WAL 发送方正在启动。catchup:此 WAL 发送方的连接备用服务器正在赶上主服务器。 streaming:此 WAL 发送方在连接备用服务器赶上主服务器后正在流式传输更改。 backup:此 WAL 发送方正在发送备份。 stopping:此 WAL 发送方正在停止。 |
| sent_lsn | pg_lsn | 在此连接上发送的最后一个预写日志位置。 |
| write_lsn | pg_lsn | 此备用服务器写入磁盘的最后一个预写日志位置。 |
| flush_lsn | pg_lsn | 此备用服务器刷新到磁盘的最后一个预写日志位置。 |
| replay_lsn | pg_lsn | 此备用服务器上重放到数据库中的最后一个预写日志位置。 |
| write_lag | interval | 在本地刷新最近的 WAL 和收到此备用服务器已写入(但尚未刷新或应用)它的通知之间经过的时间。如果此服务器配置为同步备用服务器,则可用于衡量在提交时 synchronous_commit 级别 remote_write 产生的延迟。 |
| flush_lag | interval | 在本地刷新最近的 WAL 与收到通知表明此备用服务器已写入并刷新它(但尚未应用它)之间经过的时间。如果此服务器配置为同步备用,则可用于衡量在提交期间 synchronous_commit 级别 on 产生的延迟。 |
| replay_lag | interval | 在本地刷新最近的 WAL 与收到通知表明此备用服务器已写入、刷新并应用它之间经过的时间。如果此服务器配置为同步备用,则可用于衡量在提交期间 synchronous_commit 级别 remote_apply 产生的延迟。 |
| sync_priority | integer | 在基于优先级的同步复制中,此备用服务器作为同步备用被选中的优先级。在基于法定人数的同步复制中,此项无效。 |
| sync_state | text | 此备用服务器的同步状态。可能的值为:async:此备用服务器是异步的。 potential:此备用服务器现在是异步的,但如果当前同步服务器之一发生故障,则有可能变为同步的。sync:此备用服务器是同步的。quorum:此备用服务器被视为法定人数备用的候选者。 |
| reply_time | timestamp with time zone | 从备用服务器收到的上次回复消息的发送时间。 |
附录3 复制槽
复制槽提供了一种自动方式,以确保主服务器在所有备用服务器收到 WAL 段之前不会删除这些段,并且主服务器不会删除可能导致恢复冲突的行,即使备用服务器已断开连接。
除了使用复制槽之外,还可以使用wal_keep_size防止删除旧的 WAL 段,或者使用archive_command或archive_library将这些段存储在存档中。但是,这些方法通常会导致保留比所需更多的 WAL 段,而复制槽仅保留已知需要的段数。另一方面,复制槽可以保留如此多的 WAL 段,以至于它们填满了为pg_wal分配的空间;max_slot_wal_keep_size限制了复制槽保留的 WAL 文件的大小。
同样,hot_standby_feedback本身在不使用复制槽的情况下,可以防止真空删除相关行,但在备用服务器未连接的任何时间段内不提供保护。复制槽克服了这些缺点。
查询和操作复制槽
每个复制槽都有一个名称,其中可以包含小写字母、数字和下划线字符。
可以在pg_replication_slots视图中查看现有的复制槽及其状态。
可以通过流复制协议或通过 SQL 函数创建和删除槽。
SELECT * FROM pg_replication_slots;
postgres=# SELECT * FROM pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_
flush_lsn | wal_status | safe_wal_size | two_phase | conflicting
-----------+--------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+-----------
----------+------------+---------------+-----------+-------------
(0 rows)
SELECT slot_name, active, xmin, catalog_xmin, restart_lsn, confirmed_flush_lsn FROM pg_replication_slots;
postgres=# SELECT slot_name, active, xmin, catalog_xmin, restart_lsn, confirmed_flush_lsn
postgres-# FROM pg_replication_slots;
slot_name | active | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn
-----------+--------+------+--------------+-------------+---------------------
(0 rows)
查询结果会包括以下字段:
- slot_name: 复制槽的名称。
- active: 指示复制槽是否处于活动状态。如果复制槽当前被使用,则为
true,否则为false。 - xmin: 复制槽记录的最小事务 ID。
- catalog_xmin: 复制槽记录的系统目录事务 ID。
- restart_lsn: 对于物理复制槽,表示从何处重新启动复制。
- confirmed_flush_lsn: 对于逻辑复制槽,表示确认的刷新位置。
创建复制槽
-
创建物理复制槽:
在主服务器上执行sql:
SELECT pg_create_physical_replication_slot('pgbackup'); postgres=# SELECT pg_create_physical_replication_slot('pgbackup'); pg_create_physical_replication_slot ------------------------------------- (pgbackup,) (1 row) SELECT * FROM pg_replication_slots; postgres=# SELECT * FROM pg_replication_slots; slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_ flush_lsn | wal_status | safe_wal_size | two_phase | conflicting -----------+--------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+----------- ----------+------------+---------------+-----------+------------- pgbackup | | physical | | | f | f | | | | | | | | f | (1 row)在备份服务器上配置:
若要配置备用服务器以使用此槽,则应在备用服务器上配置
primary_slot_name。这是一个简单的示例primary_conninfo = 'host=192.168.101.239 port=8432 user=repuser password=123456' primary_slot_name = 'pgbackup' -
创建逻辑复制槽
-
创建发布: 逻辑复制需要首先创建一个发布(publication),这决定了要复制哪些表或数据。例如,要创建名为
my_publication的发布:CREATE PUBLICATION my_publication FOR TABLE my_table;这将创建一个名为
my_publication的发布,并指定要复制的表。 -
执行创建复制槽的命令: 使用
pg_create_logical_replication_slot函数创建逻辑复制槽。例如,要创建名为my_logical_slot的复制槽:这里,'test_decoding'是逻辑复制槽使用的解码插件。您可以根据需要选择不同的插件,如pgoutput。
SELECT pg_create_logical_replication_slot('my_logical_slot', 'test_decoding');-
确认复制槽的创建: 使用
pg_replication_slots视图查看新创建的复制槽:SELECT * FROM pg_replication_slots;
重要提示
- 物理复制槽: 物理复制槽通常用于主备复制,必须在 PostgreSQL 主服务器和备用服务器之间配置好流复制。
- 逻辑复制槽: 逻辑复制槽用于更灵活的数据复制和集成场景,需配置发布和订阅。
确保在创建复制槽之前,您的 PostgreSQL 配置文件(通常是
postgresql.conf)中已经正确配置了复制相关的设置,如wal_level、max_replication_slots和max_wal_senders。这两个操作都需要具有足够权限的用户进行操作,通常是数据库管理员。
-
删除复制槽
-
删除物理复制槽
在删除之前,您可以检查物理复制槽的状态,以确保它确实存在。
SELECT * FROM pg_replication_slots WHERE slot_type = 'physical';使用
pg_drop_replication_slot函数删除物理复制槽。例如,要删除名为my_physical_slot的物理复制槽:如果物理复制槽正在被从库使用,您可能需要先停止从库上的复制进程,然后再删除复制槽。在从库上,确保关闭或移除相关的复制配置。SELECT pg_drop_replication_slot('pgbackup');删除物理复制槽后,您可以再次检查复制槽的状态以确认其已被删除:
SELECT * FROM pg_replication_slots; -
删除逻辑复制槽
在删除之前,您可以检查逻辑复制槽的状态,以确保它确实存在。
SELECT * FROM pg_replication_slots WHERE slot_type = 'logical';使用
pg_drop_replication_slot函数删除逻辑复制槽。例如,要删除名为my_logical_slot的逻辑复制槽。SELECT pg_drop_replication_slot('pgbackup');请注意,如果逻辑复制槽正在被某个订阅(subscription)使用,您可能需要先删除相关的订阅。可以使用以下命令查看订阅。
\ds+ -- 在 psql 中列出所有订阅删除逻辑复制槽后,您可以再次检查复制槽的状态以确认其已被删除:
SELECT * FROM pg_replication_slots WHERE slot_type = 'logical';
特别注意:
对于创建复制槽,从库的postgresql.conf文件中的primary_conninfo配置中,关于user的配置很重要,对于复制槽的创建要使用这个用户来进行创建。负责配置的复制留的active依旧不会转变为t。
操作流程为:
1.查看当前的用户是谁。是管理员用户的话可以先查询一遍权限再切换为repuser用户。
# 查看当前用户
SELECT CURRENT_USER;
# 在主库上执行,查看repuser的用户是否有REPLICATION的权限
SELECT rolname, rolsuper, rolreplication FROM pg_roles WHERE rolname = 'repuser';
# 在主库上执行,授予权限
GRANT CREATE_REPLICATION_SLOT ON DATABASE your_database TO repuser;
# 在主库上执行,切换用户
SET ROLE repuser;
2.创建复制槽
SELECT pg_create_physical_replication_slot('pgbackup');
3.修改从库配文件
primary_conninfo = 'host=192.168.101.239 port=8432 user=repuser password=123456'
primary_slot_name = 'pgbackup'
4.验证复制槽状态
SELECT slot_name, active, xmin, catalog_xmin, restart_lsn, confirmed_flush_lsn FROM pg_replication_slots;
postgres=# SELECT slot_name, active, xmin, catalog_xmin, restart_lsn, confirmed_flush_lsn FROM pg_replication_slots;
slot_name | active | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn
-----------+--------+------+--------------+-------------+---------------------
pgbackup | t | 747 | | 0/41B0CF0 |
(1 row)