目录
-
* [stanford Alpaca](https://blog.csdn.net/qq_36287702/article/details/131138356#stanford_Alpaca_11 "stanford Alpaca") -
* [OpenBuddy-Falcon](https://blog.csdn.net/qq_36287702/article/details/131138356#OpenBuddyFalcon_53 "OpenBuddy-Falcon") -
* [LoRA](https://blog.csdn.net/qq_36287702/article/details/131138356#LoRA_92 "LoRA")
前言
自从ChatGPT出世以来,各个大厂/研究院都纷纷推出自己的大模型,大模型领域发展一日千里。随着“百模大战”热度的降低,有必要梳理一下目前主流的大模型以及其变种模型,为大家梳理一下当前开源模型的工作。
LLaMA
GitHub地址:
GitHub - facebookresearch/llama: Inference code for LLaMA
models
LLaMA是由meta2023年推出的大模型,包含了7B、13B、30B、65B,随着“被开源”成为了开源模型的主力,高校/开源社区纷纷推出基于LLaMA二次训练的模型。

stanford Alpaca
GitHub地址:
[GitHub - tatsu-lab/stanford_alpaca: Code and documentation to train
Stanford’s Alpaca models, and generate the data.](https://github.com/tatsu-
lab/stanford_alpaca “GitHub - tatsu-lab/stanford_alpaca: Code and
documentation to train Stanford’s Alpaca models, and generate the data.”)
stanford大学利用ChatGPT API花费不到500美元低成本获取指令数据集。
Guanaco
GitHub地址:
[GitHub - Guanaco-Model/Guanaco-Model.github.io](https://github.com/Guanaco-
Model/Guanaco-Model.github.io “GitHub - Guanaco-Model/Guanaco-
Model.github.io”)
Guanaco是一个基于Meta的LLaMA
7B模型构建的高级指令遵循语言模型。在 Alpaca 模型最初的 52K 数据集的基础上,又合并了 534,530
个条目,涵盖英语、简体中文、繁体中文(台湾)、繁体中文(香港)、日语、德语以及各种语言和语法任务。这些丰富的数据使Guanaco能够在多语言环境中表现出色。
Vicuna
GitHub地址:
GitHub - lm-sys/FastChat: An open platform for training, serving, and
evaluating large language models. Release repo for Vicuna and
FastChat-T5.
UC伯克利联手CMU、斯坦福、UCSD和MDZUAI推出的大模型,通过ShareGPT收集的用户共享对话在LLaMA进行微调训练而来,训练成本近300美元。
一般来说,vicuna不能直接获取,需要LLaMA原模型权重和delate权重合并获取,由于LLaMA原权重下载不是很方便,所以我上传了合并后的模型权重。
ls291/vicuna-13b-v1.1 · Hugging
Face
Chinese-LLaMA-Alpaca
GitHub地址:
GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU/GPU训练部署
(Chinese LLaMA & Alpaca LLMs)
该项目开源了中文LLaMA模型和指令精调的Alpaca大模型。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。
Chinese-Vicuna
GitHub地址:
GitHub - Facico/Chinese-Vicuna: Chinese-Vicuna: A Chinese Instruction-
following LLaMA-based Model ——
一个中文低资源的llama+lora方案,结构参考alpaca
鉴于llama,alpaca,guanaco等羊驼模型的研发成功,我们希望基于LLaMA+instruction数据构建一个中文的羊驼模型,并帮助大家能快速学会使用引入自己的数据,并训练出属于自己的小羊驼(Vicuna)
Luotuo-Chinese
GitHub地址:
GitHub - LC1332/Luotuo-Chinese-LLM: 骆驼(Luotuo): Open Sourced Chinese Language
Models. Developed by 陈启源 @ 华中师范大学 & 李鲁鲁 @ 商汤科技 & 冷子昂 @
商汤科技
项目命名为 骆驼 Luotuo (Camel) 主要是因为,Meta之前的项目LLaMA(驼马)和斯坦福之前的项目alpaca(羊驼)都属于偶蹄目-
骆驼科(Artiodactyla-Camelidae)。而且骆驼科只有三个属,再不起这名字就来不及了。
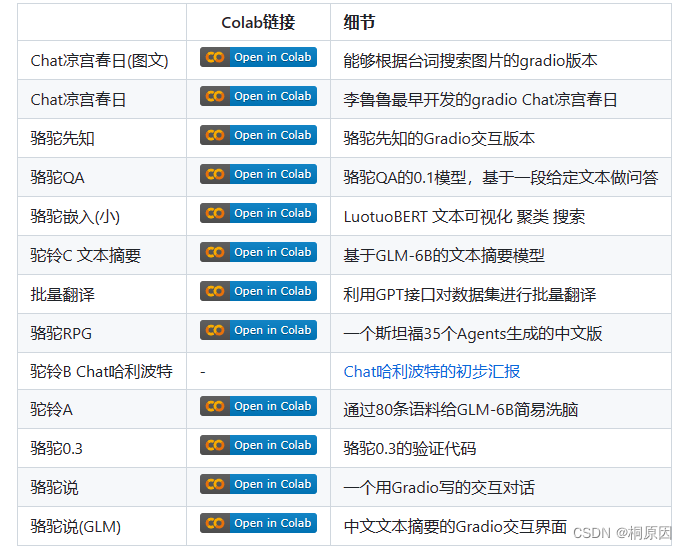
基于各个大模型做的二次衍生开发,开发项目如下:
Falcon
HF地址:
https://huggingface.co/tiiuae
是阿联酋大学推出的,最大的是40B,在AWS上384个GPU上,使用了1万亿的token训练了两个月。
由于是最近开源的模型,二次衍生的模型较少。
OpenBuddy-Falcon
HF地址:
OpenBuddy (OpenBuddy)
详细信息请见:
可商用!全球首个基于Falcon架构的中文大语言模型OpenBuddy开源了!
ChatGLM && VisualGLM
GitHub地址:
GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
是由智源和清华大学联合开发,释放出ChatGLM-6B,目前是较为主流的中文大模型。
VisualGLM是基于ChatGLM-6B+BLIP2模型联合训练得到多模态大模型。
MOSS
GitHub地址:
GitHub - OpenLMLab/MOSS: An open-source tool-augmented conversational
language model from Fudan University
由复旦大学开发,释放了MOSS-16B模型以及8-bit和4-bit量化模型,同时开源了训练数据
Aquila
GitHub地址:
FlagAI/examples/Aquila at master · FlagAI-Open/FlagAI ·
GitHub
智源新发布的大模型,模型和权重均开源,同时开源协议可商业化。
Aquila语言大模型在技术上继承了GPT-3、LLaMA等的架构设计优点,替换了一批更高效的底层算子实现、重新设计实现了中英双语的tokenizer,升级了BMTrain并行训练方法,在Aquila的训练过程中实现了比Magtron+DeepSpeed
zero-2将近8倍的训练效率。Aquila语言大模型是在中英文高质量语料基础上从0开始训练的,通过数据质量的控制、多种训练的优化方法,实现在更小的数据集、更短的训练时间,获得比其它开源模型更优的性能。
PandaGPT
GitHub地址:
GitHub - yxuansu/PandaGPT: PandaGPT: One Model To Instruction-Follow Them
All
来自University of Cambridge、 Nara Institute of Science and Technology、Tencent AI
Lab的成员开源发布了多模态大模型。该大模型能够接收文本、图像、语音模态,并可进行模态之间转换。
TigerBot
GitHub地址:
GitHub - TigerResearch/TigerBot: TigerBot: A multi-language multi-task
LLM
由虎博科技基于BLOOM模型开发的大语言模型,在BLOOM模型架构和算法上做了如下优化:
- 指令完成监督微调的创新算法以获得更好的可学习型(learnability),
- 运用 ensemble 和 probabilistic modeling 的方法实现更可控的事实性(factuality)和创造性(generativeness),
- 在并行训练上,我们突破了 deep-speed 等主流框架中若干内存和通信问题,
- 对中文语言的更不规则的分布,从 tokenizer 到训练算法上做了更适合的算法优化。
模型微调策略
LoRA
GitHub地址:
GitHub,Alpaca,LLM,训练,模型,微调,开源,LLaMA
From: https://blog.csdn.net/2401_85280106/article/details/140949218