首先应该明确的是JVM调优不是常规手段,JVM的存在本身就是为了减轻开发对于内存管理的负担,当出现性能问题的时候第一时间考虑的是代码逻辑与设计方案,以及是否达到依赖中间件的瓶颈,最后才是针对JVM进行优化。
1.JVM内存模型
针对JAVA8的模型进行讨论,JVM的内存模型主要分为几个关键区域:堆、方法区、程序计数器、虚拟机栈和本地方法栈。堆内存进一步细分为年轻代、老年代,年轻代按其特性又分为E区,S1和S2区。关于内存模型的一些细节就不在这里讨论了,如下是从网上找的内存模型图:
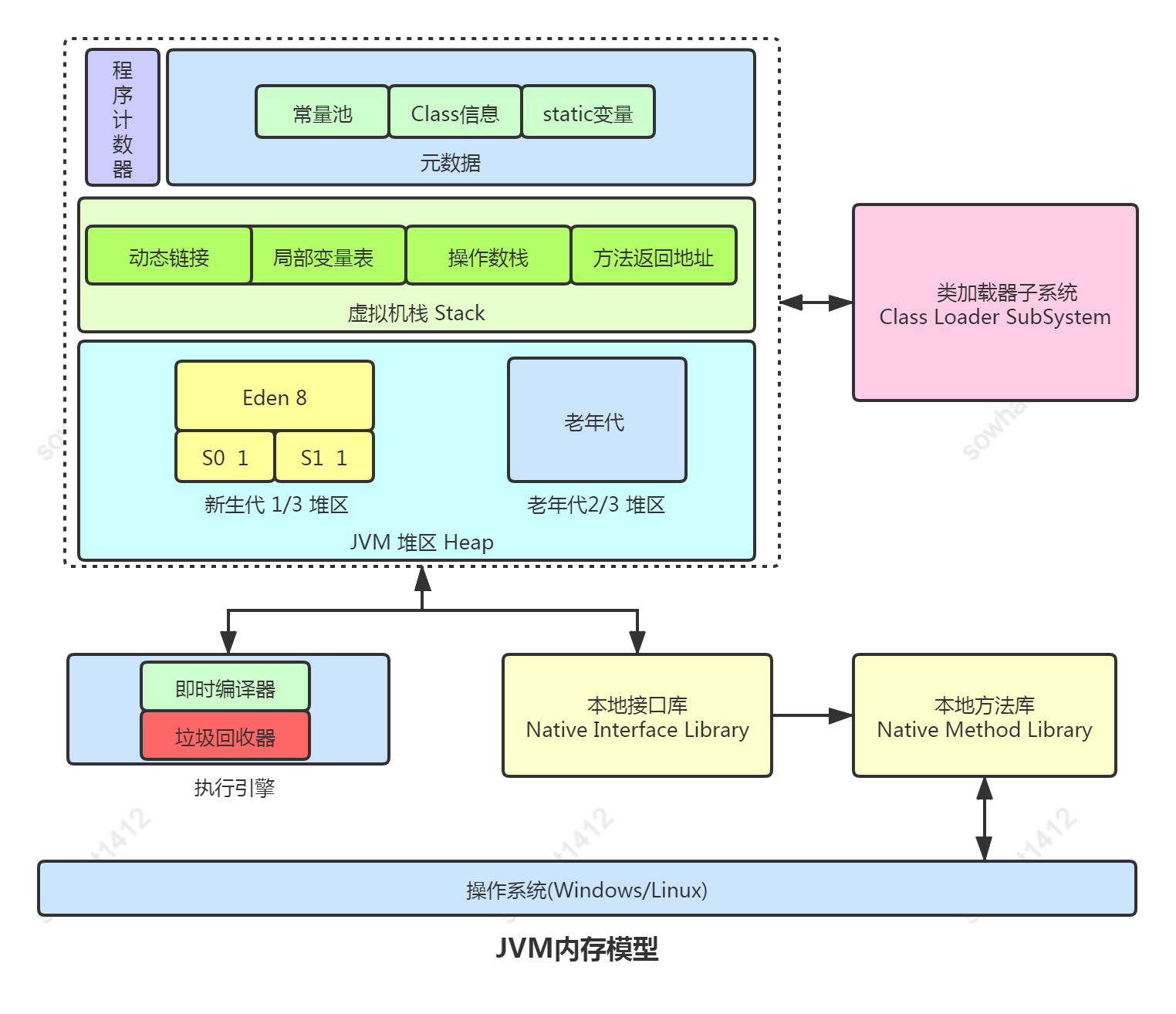
接下来从内存模型简单流转来看一个对象的生命周期,对JVM的回收有一个概念,其中弱化堆栈和程序计数器
1.首先我们写的.java文件通过java编译器javac编译成.class文件
2.类被编译成.class文件后,通过类加载器(双亲委派模型)加载到JVM的元空间中
3.当创建对象时,JVM在堆内存中为对象分配空间,通常首先在年轻代的E区(这里只讨论在堆上分配的情况)
4.对象经历YGC后,如果存活移动到S区,多次存活后晋升到老年代
5.当对象不再被引用下一次GC,垃圾收集器会回收对象并释放其占用的内存。
1.1 年轻代回收原理
对象创建会在年轻代的E区分配内存,当失去引用后,变成垃圾存在E区中,随着程序运行E区不断创建对象,就会逐步塞满,这时候E区中绝大部分都是失去引用的垃圾对象,和一小部分正在运行中的线程产生的存活对象。这时候会触发YGC(Young Gc)回收年轻代。然后把存活对象都放入第一个S区域中,也就是S0区域,接着垃圾回收器就会直接回收掉E区里全部垃圾对象,在整个这个垃圾回收的过程中全程会进入Stop the Wold状态,系统代码全部停止运行,不允许创建新的对象。YGC结束后,系统继续运行,下一次如果E区满了,就会再次触发YGC,把E区和S0区里的存活对象转移到S1区里去,然后直接清空掉E区和S0区中的垃圾对象
1.2 、那么对象什么时候去老年代呢?
1.2.1、对象的年龄
躲过15次YGC之后的对象晋升到老年代,默认是15,这个值可以通过-XX:MaxTenuringThreshold设置
这个值设置的随意调整会有什么问题?
现在java项目普遍采用Spring框架管理对象的生命周期。Spring默认管理的对象都是单例的,这些对象是长期存活的应该直接放到老年代中,应该避免它们在年轻代中来回复制。调大晋升阀值会导致本该晋升的对象停留在年轻代中,造成频繁YGC。但是如果设置的过小会导致程序中稍微存在耗时的任务,就会导致大量对象晋升到老年代,导致老年代内存持续增长,不要盲目的调整晋升的阀值。
1.2.2、动态对象年龄判断
JVM都会检查S区中的对象,并记录下每个年龄段的对象总大小。如果某个年龄段及其之前所有年龄段的对象总大小超过了S区的一半,则从该年龄段开始的所有对象在下一次GC时都会被晋升到老年代。假设S区可以容纳100MB的数据。在进行一次YGC后,JVM统计出如下数据:
•年龄1的对象总共占用了10MB。 •年龄2的对象总共占用了20MB。 •年龄3的对象总共占用了30MB。此时,年龄1至3的对象总共占用了60MB,超过了S区一半的容量(50MB)。根据动态对象年龄判断规则,所有年龄为3及以上的对象在下一次GC时都将被晋升到老年代,而不需要等到它们的年龄达到15。(注意:这里S区指的是S0或者S1的空间,而不是总的S,总的在这里是200MB)
这个机制使得JVM能够根据实际情况动态调整对象的晋升策略,从而优化垃圾收集的性能。通过这种方式,JVM尽量保持S区空间的有效利用,同时减少因年轻代对象过多而导致的频繁GC。
1.2.3.大对象直接进入老年代
如果对象的大小超过了预设的阈值(可以通过-XX:PretenureSizeThreshold参数设置),这个对象会直接在老年代分配,因为大对象在年轻代中经常会导致空间分配不连续,从而提早触发GC,避免在E区及两个S区之间来回复制,减少垃圾收集时的开销。
1.2.4.临时晋升
在某些情况下,如果S区不足以容纳一次YGC后的存活对象,这些对象也会被直接晋升到老年代,即使它们的年龄没有达到晋升的年龄阈值。这是一种应对空间不足的临时措施。
1.3老年代的GC触发时机
一旦老年代对象过多,就可能会触发FGC(Full GC),FGC必然会带着Old GC,也就是针对老年代的GC 而且一般会跟着一次YGC,也会触发永久代的GC,但具体触发条件和行为还取决于使用的垃圾收集器,文章的最后会简单的介绍下垃圾收集器。
•Serial Old/Parallel Old当老年代空间不足以分配新的对象时,会触发FGC,这包括清理整个堆空间,即年轻代和老年代。
•CMS当老年代的使用达到某个阈值(默认情况下是68%)时,开始执行CMS收集过程,尝试清理老年代空间。如果在CMS运行期间老年代空间不足以分配新的对象,可能会触发一次Full GC。 启动CMS的阈值参数:-XX:CMSInitiatingOccupancyFraction=75,-XX:+UseCMSInitiatingOccupancyOnly
• G1G1收集器将堆内存划分为多个区域(Region),包括年轻代和老年代区域。当老年代区域中的空间使用率达到一定比例(基于启发式方法或者显式配置的阈值)默认45%时,G1会计划并执行Mixed GC,这种GC包括选定的一些老年代区域和所有年轻代区域的垃圾收集。
Mixed GC的阈值参数-XX:InitiatingHeapOccupancyPercent=40,-XX:MaxGCPauseMillis=200
2.JVM优化调优目标:
2.1JVM调优指标
•低延迟(Low Latency):GC停顿时间短。 •高吞吐量(High Throughput):单位时间内能处理更多的工作量。更多的是CPU资源来执行应用代码,而非垃圾回收或其他系统任务。 •大内存(Large Heap):支持更大的内存分配,可以存储更多的数据和对象。在处理大数据集或复杂应用时尤为重要,但大内存堆带来的挑战是GC会更加复杂和耗时。但是不同目标在实现是本身时有冲突的,为什么难以同时满足?
•低延迟 vs. 高吞吐量:要想减少GC的停顿时间,就需要频繁地进行垃圾回收,或者采用更复杂的并发GC算法,这将消耗更多的CPU资源,从而降低应用的吞吐量。 •低延迟 vs. 大内存:大内存堆意味着GC需要管理和回收的对象更多,这使得实现低延迟的GC变得更加困难,因为GC算法需要更多时间来标记和清理不再使用的对象。 •高吞吐量 vs. 大内存:虽然大内存可以让应用存储更多数据,减少内存管理的开销,但是当进行全堆GC时,大内存堆的回收过程会占用大量CPU资源,从而降低了应用的吞吐量。2.2如何权衡
在实际应用中,根据应用的需求和特性,开发者和运维工程师需要在这三个目标之间做出权衡:
2.2.1Web应用和微服务 - 低延迟优先
场景描述:对于用户交互密集的Web应用和微服务,快速响应是提供良好用户体验的关键。在这些场景中,低延迟比高吞吐量更为重要。
推荐收集器:大内存应用推荐G1,内存偏小可以使用CMS,CMS曾经是低延迟应用的首选,因其并发回收特性而被广泛使用。不过由于CMS在JDK 9中被标记为废弃,并在后续版本中被移除可以使用极低延迟ZGC或Shenandoah。这两种收集器都设计为低延迟收集器,能够在大内存堆上提供几乎无停顿的垃圾回收,从而保证应用的响应速度,但是支持这两个回收器的JDK版本较高,在JDK8版本还是CMS和G1的天下。
2.2.2 大数据处理和科学计算 - 高吞吐量优先
场景描述:大数据处理和科学计算应用通常需要处理大量数据,对CPU资源的利用率要求极高。这类应用更注重于高吞吐量,以完成更多的数据处理任务,而不是每个任务的响应时间。
推荐收集器:Parallel GC。这是一种以高吞吐量为目标设计的收集器,通过多线程并行回收垃圾,以最大化应用吞吐量,非常适合CPU资源充足的环境。
2.2.3. 大型内存应用 - 大内存管理优先
场景描述:对于需要管理大量内存的应用,例如内存数据库和某些缓存系统,有效地管理大内存成为首要考虑的因素。这类应用需要垃圾回收器能够高效地处理大量的堆内存,同时保持合理的响应时间和吞吐量。
推荐收集器:G1 GC或ZGC。G1 GC通过将堆内存分割成多个区域来提高回收效率,适合大内存应用且提供了平衡的延迟和吞吐量。ZGC也适合大内存应用,提供极低的延迟,但可能需要对应用进行调优以实现最佳性能。
3.JVM优化一般是针对于两种场景
3.1新应用上线,通过预估核心接口流量进行压测,观察JVM的GC情况并调优
压测需要观察那些重要的指标呢
•YGC与FGC频率和耗时 •YGC过后多少对象存活 • 老年代的对象增长速率通过jstat观察出来上述JVM运行指标!
3.2老应用通过监控收到JVM异常反馈,或者程序出现下列问题进行优化
3.2.1应用出现OutOfMemory等内存异常
(1)堆内存溢出 Java heap space
对象持续创建而不被回收或者来不及回收,导致堆内存耗尽。
•超预期请求:面临突发的高并发请求或处理大量数据时,创建了大量线程和对象,GC回收后的空间,不足以放下存活的对象就会造成OOM。需要我们做好流量控制和预估,然后针对这种情况提前扩容或者限流。 •内存泄漏:大量对象引用没有释放,JVM 无法对其自动回收,常见于使用了 File 等资源没有回收,是否使用JDK线程池工具等,都是编码异常需要导出dump文件针对代码进行分析。 •滥用缓存:本地缓存工具占用大量内存,导致堆使用空间变小,需要合理设置缓存大小以及超时时间 •大量对象:再循环中创建大量对象导致堆内存被占满,避免在循环中创建对象。重复对象使用池化技术 •大对象或大数组:创建超大数组,上传或者导出大文件,查询不带条件拖库,编码做好边界限制,有一个良好的编码习惯。(2)元空间溢出 Metaspace
元空间的溢出通常是因为加载的 class 数目太多或体积太大
例如:动态生成大量Class对象,比如某些框架(如OSGi、ASM)动态生成大量的类,这些类占用的空间可能超过了元空间的限制,或者加载了大量的第三方库,这些库中包含的类和常量占用了大量的方法区空间。如果是正常类加载需要调大元空间-XX:MaxMetaspaceSize,否则需要导出DUMP文件,分析是否存在重复类
(3)虚拟机栈和本地方法栈溢出
线程请求的栈深度超过了虚拟机栈和本地方法栈允许的最大深度。这种情况通常发生在深度递归调用的情况下(-Xss参数设置栈的大小)。
应用创建了过多线程,超出了系统承载能力,尤其是在32位系统上,每个线程的栈空间(默认1MB)会占用一定的地址空间,可能会导致系统无法分配足够的地址空间给新的线程。
(4)直接内存溢出 Direct buffer memory
Java 允许应用程序通过 Direct ByteBuffer 直接访问堆外内存,许多高性能程序通过 Direct ByteBuffer 结合内存映射文件(Memory Mapped File)实现高速 IO。Direct ByteBuffer 的默认大小为 64 MB
•检查堆外内存使用代码,排查是否正确使用ByteBuffer.allocateDirect •检查是否直接或间接使用了 NIO,如 netty,jetty 等。 •通过启动参数 -XX:MaxDirectMemorySize 调整 Direct ByteBuffer 的上限值。3.2.2 Heap内存(老年代)持续上涨达到设置的最大内存值;
老年代持续上涨是JVM优化的重要指标,但是老年代持续上涨有多种原因
内存泄漏:最开始的表现也是老年代的持续上涨,触发FGC无法回收抛出OOM,系统宕机!
正常情况:可能是因为流量徒增导致年轻代处理不过来,临时移入老年代,执行FGC后内存明显下降!
大对象:大对象直接分配在老年代,触发FGC后内存明显下降!
年轻代的S区设置过小:E区正常回收后存活的对象,在S区放不下直接晋升到老年代,有一个大坑就是JAVA8默认收集器Parallel Scavenge为了处理更大的吞吐量会动态调整S区,在线上运行一段时间后S区会变得很小,导致大量对象进入到老年代,我在优化实战中排查过这个问题
3.2.3 FGC 次数频繁
频繁进行FGC如果出现OOM按照3.2.1进行排查
频繁FGC但是内存能被回收按照3.2.2进行排查
3.2.4 GC 停顿时间长
YGC停顿
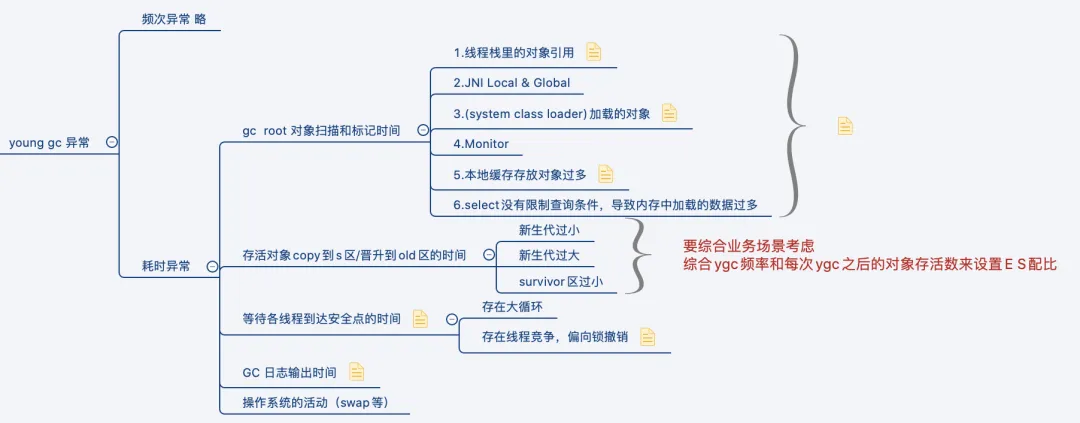
可以看看这篇文章总结的挺好的:JVM性能调优--YGC
FGC停顿
FGC的触发一般是老年代或者元空间内存不足,FGC执行本身是比较耗时的操作,会回收整个堆内存以及元空间,我们在优化JVM尽量避免FGC,或者尽量少的FGC。FGC停顿指标需要结合FGC执行频率,以及历史执行时间来看如果是因为内存空间大导致回收慢可以选择G1针对大内存进行处理
总结:
JVM优化没有拿过来直接用的方案,所有好的JVM优化方案都是在当前应用背景下的,还是开头那句话 JVM调优不是常规手段,如果没有发现问题尽量不主动优化JVM,但是一定要了解应用的JVM运行情况,这时候好的监控就显得格外重要。
那么好的JVM应该是什么样的呢?简单的说就是尽量让每次YGC后的存活对象小于S区域的50%,都留存在年轻代里。尽量别让对象进入老年代。尽量减少FGC的频率,避免频繁FGC对JVM性能的影响。
了解了JVM优化的基本原理之后,实战就需要在日常中积累了,墨菲定律我觉得在这个场景很适用,不要相信线上的机器是稳定的,如果观察到监控有异常,过一会可能恢复了就不了了之,要敢于去排查问题,未知的总是令人恐惧的,在排查的过程中会加深自己对JVM的理解的同时,也会对应用更有信心。
4.线上优化实战:

 标签:JVM,对象,回收,GC,内存,聊聊,优化,FGC
From: https://www.cnblogs.com/Jcloud/p/18343816
标签:JVM,对象,回收,GC,内存,聊聊,优化,FGC
From: https://www.cnblogs.com/Jcloud/p/18343816