本博客内容翻译自作者于 2024 年 7 月在亚马逊云科技开发者社区发表的同名博客:
“Mastering Amazon Bedrock Custom Models Fine-tuning (Part 1): Getting started with Fine-tuning”:
https://community.aws/content/2jNtByVshH7vnT20HEdPuMArTJL?trk=cndc-detail
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
引言和综述
在当今方兴未艾的大型语言模型(LLM)领域,如 Meta 的 Lllama、Cohere 的 Command、Amazon 的 Titan 和 Anthropic 的 Claude 等,这些大模型彻底改变了我们处理语言任务的方式。它们在大量文本数据上进行了预训练,并可以通过称为微调(fine-tuning)的过程适应各种下游任务。
微调(Fine-tuning)是一种技术,涉及使用与该任务相关的较小数据集进一步训练特定任务或领域的预训练语言模型。通过这样做,模型可以学会更好地理解和生成针对特定上下文的文本,从而提高性能和准确性。
但是,在某些情况下,微调可能不是最合适的方法。在这种情况下,检索增强生成 RAG(retrieval-augmented generation)方法可能更合适。RAG 将基础模型的强大功能与外部知识源相结合,允许它们在生成过程中访问和整合来自数据库或文档集合的相关信息。
在这篇技术博客中,我们将探讨微调和 RAG 的基础知识,并分享为不同业务用例选择正确方法(微调或 RAG)的实践经验。我们将介绍:
-
模型微调概述
-
检索增强生成(RAG)概述
-
在模型微调和 RAG 之间进行选择的标准
-
开始使用模型微调
微调(Fine-tuning)概述
当您需要将基础模型适应专门的任务或领域时,微调是一种强大的技术。例如,如果正在为某个特定行业构建客户服务聊天机器人,那么根据该行业的相关客户服务数据对预先训练的模型进行微调,可以显著增强其对特定领域术语、行话和上下文的理解。
与检索增强生成(RAG)方法相比,模型微调的一个关键优势是:因为不涉及额外的检索步骤,它有可能在推理过程中提高性能并降低延迟。这使得微调模型非常适合低延迟和高吞吐量至关重要的场景,例如实时对话式 AI 应用程序。
然而,模型微调也有其自身的挑战。与检索增强生成(RAG)相比,它通常需要更大的计算资源投入。因为它需要标记、精选数据进行训练,以及微调过程本身的额外计算资源。此外,微调模型可能会难以应对快速变化的数据,因为模型需要定期重新训练才能有效地整合新信息。
模型微调方法可以用以下功能概要图示来说明:

Illustration diagram of fine-tuning generated by Claude 3 Sonnet in Amazon Bedrock
可以在“Generative AI on AWS”一书中找到模型微调的实际示例。该书作者提供了示例代码,指导用户使用 Amazon SageMaker JumpStart 在 Dolly 数据集的子集上微调 Llama 2 模型。
该示例涵盖了模型微调的各个方面:包括数据准备、定义微调超参数、创建 Amazon SageMaker 估算器、启动微调作业、评估微调模型的性能以及将其部署到 Amazon SageMaker 终端节点。示例的 notebook 文件完整展示了利用 Amazon SageMaker 的功能对大型语言模型进行高效且可扩展的微调,提供了从头到尾的全面工作流程代码实现,我们还将在后面的章节中详细展开分析这些代码。
检索增强生成(RAG)概述
检索增强生成(RAG)是一种将大语言模型(LLM)的强大功能与信息检索技术相结合的方法。在 RAG 设置中,模型可以根据提供的提示生成文本,从知识库或语料库中获取相关信息以增强模型的输出。
在处理频繁变化的数据或领域知识太广泛而无法仅通过微调模型有效捕获时,RAG 特别有用。新闻机构、媒体和处理快速变化信息的组织通常会受益于 RAG 方法,因为他们可以轻松更新知识库,而无需重新训练整个模型。
RAG 的关键优势之一在于其灵活性和易于实施性。由于不需要大量训练,因此与微调相比,RAG 系统可以相对快速地建立,并且初始成本较低。但是,由于额外的检索步骤,RAG 往往比微调模型慢,并且由于涉及多个组件(如矢量数据库、嵌入模型和文档加载器)的协同工作,使得其实现的架构可能会变得比较复杂。
检索增强生成(RAG)方法可以用以下功能概要图示来说明:
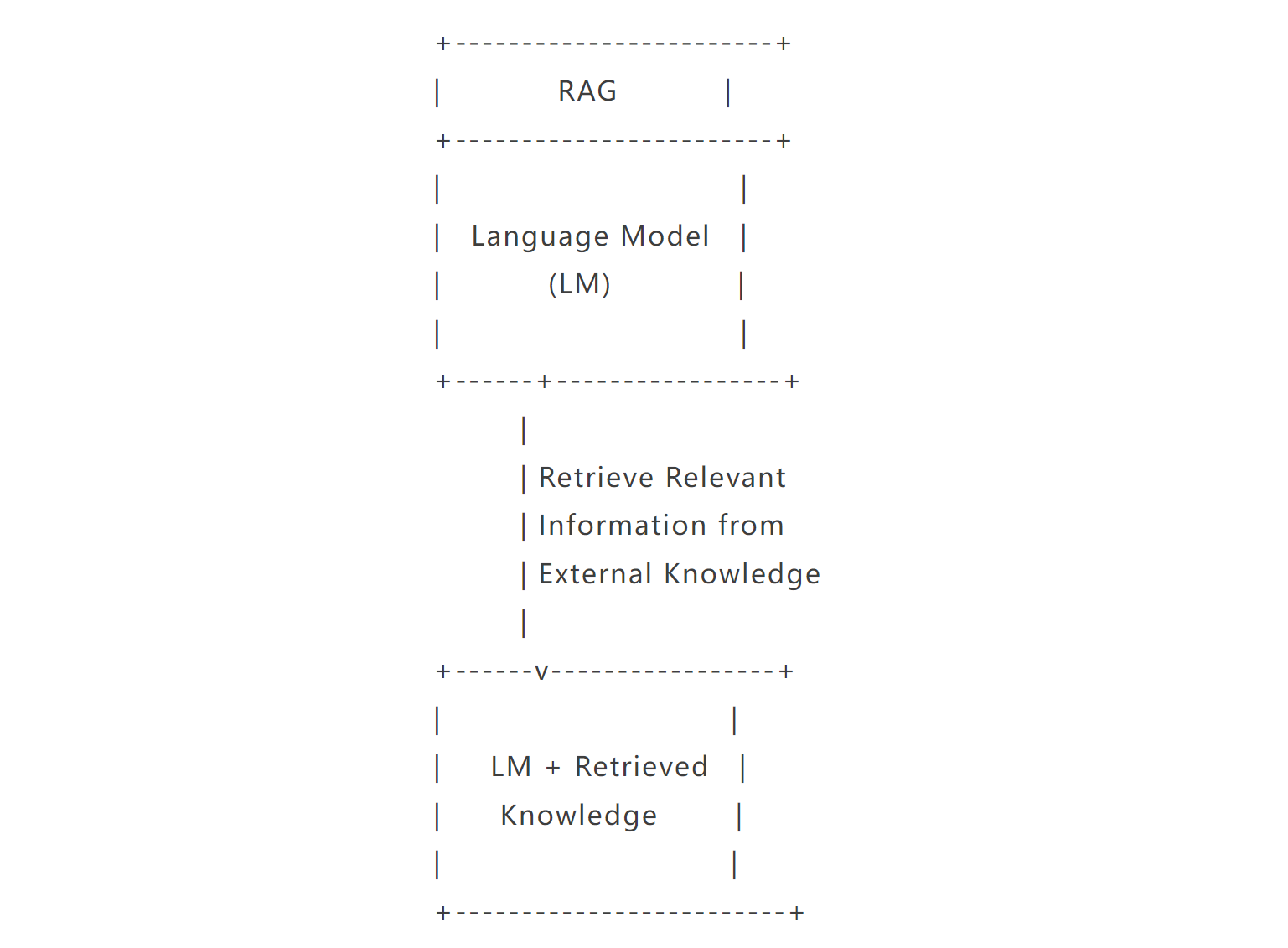
Illustration diagram of RAG generated by Claude 3 Sonnet in Amazon Bedrock
关于基于 RAG 搭建的完整实现代码示例,可以参考 Amazon Bedrock workshop 提供的一个精彩案例。该案例以亚马逊云科技过去几年来的致股东信作为外部文本语料库,这个外部知识库允许 RAG 系统通过从语料库中检索相关信息来获得更好的问答结果。通过利用这些检索到的知识增强语言模型的输出,基础模型可以生成更多针对特定上下文且准确的响应,而无需持续重新训练。
该 Workshop 中的 RAG 实现示例的一个显著优势是:可以检索到信息的来源归因,这在很大程度上提高了信息的透明度,并降低了模型幻觉的风险,从而确保最终生成的响应是基于事实基准的数据。
该 Workshop 的代码完整实现还详细说明了客户定制 RAG 的完整工作流程,其中语言模型和检索组件以协同工作的方式来生成增强响应。下图为工作流程的功能结构图示
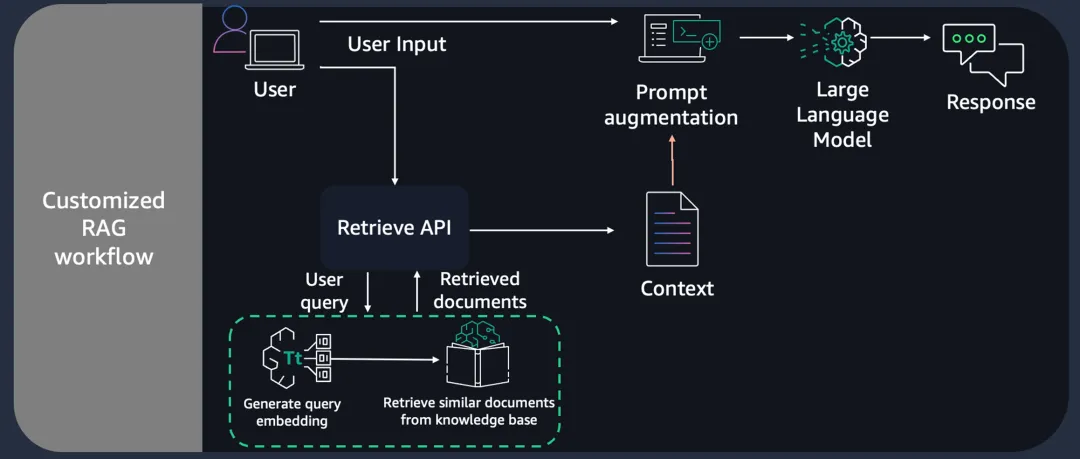
在这个定制的 RAG 工作流程(Customized RAG Workflow)中,模型根据输入提示生成初始响应,而检索组件同时从亚马逊云科技致股东信的语料库中获取相关信息。然后将检索到的知识与模型的输出结果集成,最终产生一个增强响应,这个增强响应结合了模型输出结果和外部知识源的共同信息。
该完整实现代码可通过 GitHub 链接访问获得。
模型微调还是 RAG?
那么,什么时候应该选择微调而不是 RAG?反之亦然。这取决于你所面对的业务场景具体要求和用例。以下是一些一般准则供参考:
微调
何时使用微调:
-
领域专门任务:微调非常适合精度和性能至关重要的领域专门任务。例如,如果你正在开发医学诊断模型,则对精选的医疗记录数据集进行微调将产生更高更准确的模型输出结果。
-
高性能和低延迟:如果你的应用程序需要低延迟和高吞吐量,则模型微调是更好的选择。微调模型不需要额外的检索步骤,从而使其推理速度更快。
-
精选数据集:如果你可以访问与特定任务相关的定义明确、标记和精选的数据集,则微调可以利用这些数据来优化性能。
-
预测质量:对于预测质量和准确性至关重要的任务,模型微调允许你根据特定要求定制模型。
微调的优势:
-
高性能:针对特定任务进行了优化,从而提高了模型输出的准确性和性能。
-
低延迟:推理时间更快,因为不需要额外的检索步骤。
-
任务特异性:经过量身定制,可在所训练的特定任务上表现出色。
微调的权衡(Trade-Offs):
-
成本:微调需要大量的模型训练所需的计算资源投入,包括抓取、转换和清理数据等数据预处理的成本。
-
缺乏泛化能力:微调模型高度专业化,这意味着不同的任务需要不同的模型。
-
不适合频繁变化的数据:由于模型是在静态数据集上训练的,因此它不能很好地适应动态数据环境。
检索增强生成(RAG)
何时使用 RAG:
-
频繁变化的数据:当数据频繁变化时,例如在新闻机构或媒体机构中,由于信息变化量巨大,因此 RAG 是首选,模型无需重新训练即可检索最新信息。
-
广泛的领域知识:如果你的应用程序涵盖广泛的主题或领域,RAG 可以通过动态检索相关信息来有效地处理多样性。
-
标记数据有限:当缺少大量优质的标记数据时,RAG 就非常有帮助。它可以使用预先训练的模型从外部数据源来检索上下文,从而减少对大量训练数据的需求。
-
成本和时间效率:RAG 可以快速实施,初始成本较低,因为它避免了极为耗时耗资源的模型再训练过程。
RAG 的优点:
-
灵活性:通过动态检索相关信息来处理各种各样的任务。
-
较低的初始成本:避免与训练相关的成本,使其更易于访问和部署更快。
-
保留泛化:基础模型保持不变,保持其在不同任务中进行泛化的能力。
RAG 的权衡:
-
推理速度较慢:由于 RAG 架构中增加了外部信息源检索这一步骤,因此会相应增加延迟,使 RAG 与微调模型相比响应速度会更慢。
-
复杂性:由于 RAG 涉及多个组件,例如矢量数据库、嵌入模型和文档加载器,这可能会使系统复杂化。
-
更高的令牌(Token)使用率:由于 RAG 需要解析查询和上下文,从而导致每个提示的令牌使用量增加。
选择准则小结
-
性能敏感性:如果你的应用程序需要高性能、低延迟和针对狭窄领域的高质量预测,则建议使用模型微调方法。
-
动态数据环境:对于处理频繁更新信息或广泛领域知识的应用程序,RAG 通常是更实用且更具成本效益的解决方案。
通过仔细评估你的用例和要求,你可以选择最合适的方法,平衡成本、性能和复杂性之间的权衡。无论你选择微调还是 RAG,每种方法都具有独特的优势,可以利用这些优势来满足你的特定业务需求。
开始使用模型微调
如果你已经确定模型微调是适合你用例的最佳方法,那么下一步就是准备数据并配置模型微调过程。以下是一些关键注意事项:
1. 数据准备:模型微调需要与你的任务相关的高质量标记数据集。这可能涉及从各种来源收集数据、清理和转换数据,并使用适当的标签对其进行注释。数据质量至关重要,因为质量差的数据会导致模型性能不佳。
在《Generative AI on AWS》一书中的 Llama 2 模型微调代码实现中,使用了 Dolly 数据集(用于开放域对话的大型数据集)的一个子集。代码片段演示了预处理和过滤数据以创建适合微调的较小子集。然而,在现实世界中,你需要仔细整理和预处理自己的数据集,以确保微调任务的高质量和相关数据。相关代码片段如下所示:
from datasets import load_dataset
dolly_dataset = load_dataset("databricks/databricks-dolly-15k", split="train")
# To train for question answering/information extraction, you can replace the assertion in next line to example["category"] == "closed_qa"/"information_extraction".
summarization_dataset = dolly_dataset.filter(lambda example: example["category"] == "summarization")
summarization_dataset = summarization_dataset.remove_columns("category")
# We split the dataset into two where test data is used to evaluate at the end.
train_and_test_dataset = summarization_dataset.train_test_split(test_size=0.1)
train_and_test_dataset["test"][0]
2. 模型选择:选择合适的预训练模型作为起点。在此示例中,其选择的微调模型是由 Meta AI 开发的语言模型 Llama 2。Llama 模型目前可通过 Amazon SageMaker JumpStart 获得,这简化了使用亚马逊云科技资源访问和微调模型的过程。
3. 微调超参数:选择模型后,在使用 Amazon SageMaker 对其进行微调之前,我们需要定义用于微调的实例。然后,我们可以尝试不同的超参数,例如学习率、批处理大小、epoch、最大输入长度,以优化特定任务和数据集的微调过程。
此 Llama 2 微调示例中提供的代码片段演示了如何设置各种微调超参数,包括启用指令调整模式、设置最大输入长度为 1024 以及运行 5 个 epoch 等等。必须注意的是,这些超参数值可能并非对所有任务或数据集都是最佳的。尝试不同的配置以找到适合你特定用例的最佳设置至关重要。相关代码片段如下所示:
from sagemaker.jumpstart.estimator import JumpStartEstimator
estimator = JumpStartEstimator(
model_id=model_id,
model_version=model_version,
instance_type="ml.g5.12xlarge",
instance_count=2,
environment={"accept_eula": "true"}
)
# By default, instruction tuning is set to false. Thus, to use instruction tuning dataset you use
estimator.set_hyperparameters(instruction_tuned="True",
epoch="5",
max_input_length="1024")
estimator.fit({"training": train_data_location})
4. 评估和迭代:使用适当的指标和测试数据集定期评估微调模型的性能。微调是一个迭代过程,你可能需要调整数据、超参数甚至预训练模型以获得最佳结果。持续监控和改进对于提高模型性能并确保其满足你的业务要求至关重要。
在微调 Llama 2 示例中,它包含用于评估微调模型在验证集上的性能的代码。根据评估结果,你可以确定微调模型是否满足你的要求,或者是否需要通过调整数据、超参数或尝试不同的预训练模型进行进一步迭代。
此外,建议在单独的测试数据集上评估微调模型的性能,以获得其实际性能的无偏估计。测试数据应代表目标域,并且在微调过程中看不见。你可以使用相关指标在此测试数据集上比较微调模型与预训练模型的性能。结果可以以表格或图形格式呈现,如提供的屏幕截图所示:

如果你有兴趣亲自探索微调 Llama 2 模型的细节,可以通过访问 GitHub 链接来访问微调示例的完整代码。
全篇小结
在这篇文章中,我们深入研究了模型微调(Fine-tuning)和检索增强生成(RAG)技术,提供了概述和建议,以便根据特定用例选择适当的方法。我们还提供了有关如何开始微调的见解,并提供了一个使用 Amazon SageMaker 微调 Llama 2 模型的示例,演示了数据预处理、超参数调整、评估等。这将有助于开发人员理解模型微调过程。
在即将发布的下一篇文章中,我们将探索如何使用 Amazon Bedrock 来微调基础模型,这简化了在亚马逊云科技上部署生成式 AI 的整个过程。Amazon Bedrock 通过预置的吞吐量提供数据隐私、网络安全、模型定制的灵活计费、存储和推理。它能够以保证的吞吐量水平运行自定义模型推理,并促进自定义模型部署。敬请期待。
说明:本文封面图片是使用 Amazon Bedrock 上的 SDXL 1.0 模型生成的。提示词如下:
“two developers sitting in the cafe discussing model fine-tuning, comic, graphic illustration, comic art, graphic novel art, vibrant, highly detailed, colored, 2d minimalistic”
 标签:检索,RAG,模型,微调,Amazon,Bedrock,数据
From: https://www.cnblogs.com/AmazonwebService/p/18330465
标签:检索,RAG,模型,微调,Amazon,Bedrock,数据
From: https://www.cnblogs.com/AmazonwebService/p/18330465