开通灵识服务
首先需要到阿里云-模型服务灵积开通账户,获得apiKey
模型服务灵积 https://dashscope.aliyun.com/
进入控制台 ,在API-KEY管理里,创建一个新的API-KEY,然后保存起来,后面会用到。
模型服务灵积服务所有API文档地址 https://help.aliyun.com/zh/dashscope/developer-reference
快速开始
创建项目
创建一个文件,例如“chainlit_chat”
mkdir chainlit_chat
进入 chainlit_chat文件夹下,执行命令创建python 虚拟环境空间(需要提前安装好python sdk。 Chainlit 需要python>=3.8。,具体操作,由于文章长度问题就不在叙述,自行百度),命令如下:
创建虚拟环境
python -m venv .venv
- 这一步是避免python第三方库冲突,省事版可以跳过
.venv是创建的虚拟空间文件夹可以自定义
接下来激活你创建虚拟空间,命令如下:
#linux or mac
source .venv/bin/activate
#windows
.venv\Scripts\activate
创建requirements.txt文件
在项目根目录下创建requirements.txt,内容如下:
chainlit~=1.1.306
openai~=1.37.0
创建app.py文件
在项目根目录下创建app.py文件,代码如下:
import base64
from io import BytesIO
from pathlib import Path
import chainlit as cl
from chainlit.element import ElementBased
from chainlit.input_widget import Select, Slider, Switch
from openai import AsyncOpenAI
client = AsyncOpenAI()
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
@cl.on_settings_update
async def on_settings_update(settings: cl.chat_settings):
cl.user_session.set("settings", settings)
@cl.on_chat_start
async def start_chat():
settings = await cl.ChatSettings(
[
Select(
id="Model",
label="Model",
values=["qwen-turbo", "qwen-plus", "qwen-max"],
initial_index=0,
),
Slider(
id="Temperature",
label="Temperature",
initial=1,
min=0,
max=2,
step=0.1,
),
Slider(
id="MaxTokens",
label="MaxTokens",
initial=1000,
min=1000,
max=3000,
step=100,
),
Switch(id="Streaming", label="Stream Tokens", initial=True),
]
).send()
cl.user_session.set("settings", settings)
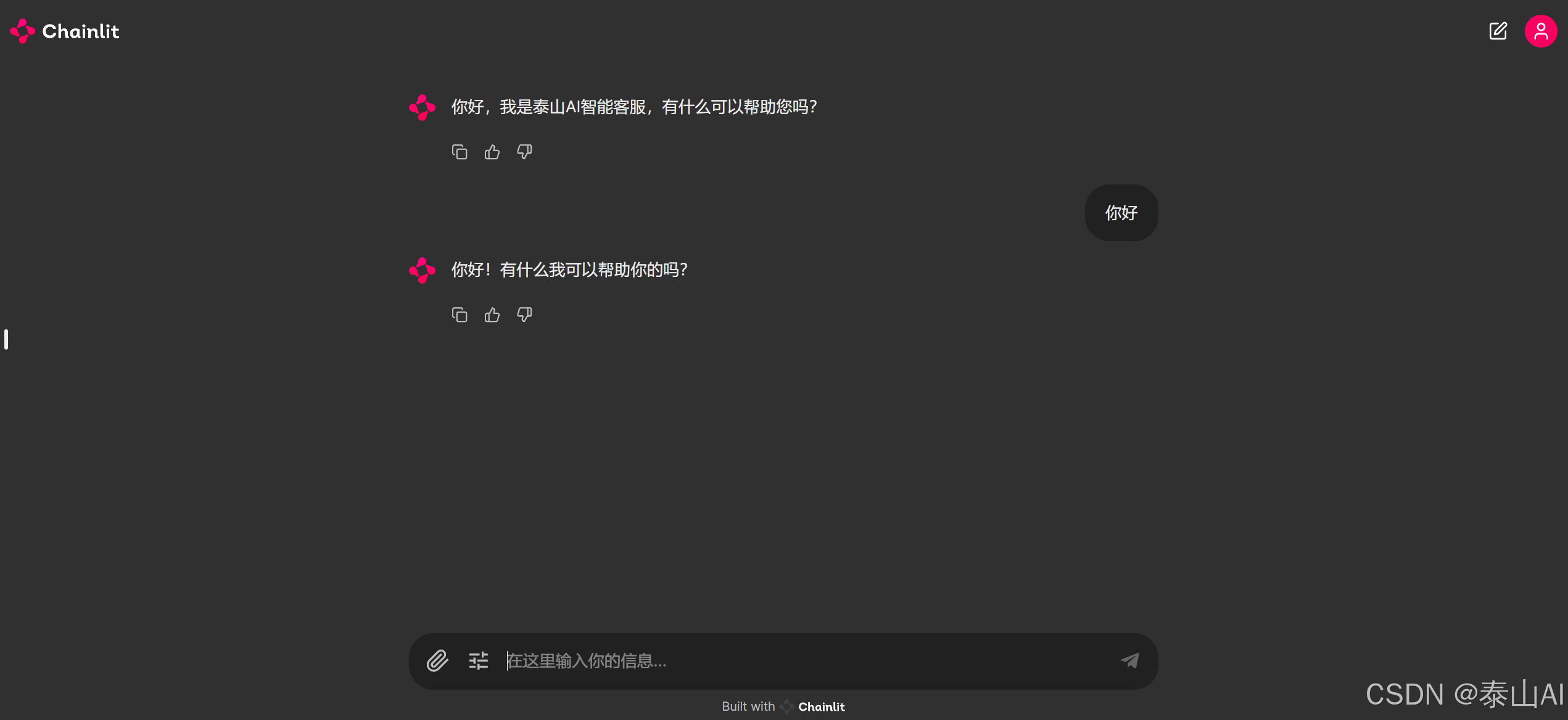
content = "你好,我是泰山AI智能客服,有什么可以帮助您吗?"
msg = cl.Message(content=content)
await msg.send()
@cl.on_message
async def on_message(message: cl.Message):
settings = cl.user_session.get("settings")
print('settings', settings)
streaming = settings['Streaming']
model = settings['Model']
print('elements', message.elements)
images = [file for file in message.elements if "image" in file.mime]
files = [file for file in message.elements if "application" in file.mime]
messages = cl.chat_context.to_openai()
if files:
model = "qwen-long"
files = files[:3]
pdfs_content = []
for file in files:
file_object = await client.files.create(file=Path(file.path), purpose="file-extract")
print('file_object', file_object)
pdfs_content.append({
"role": "system",
"content": f"fileid://{file_object.id}",
})
pdfs_content.append({"role": "user", "content": message.content})
messages = pdfs_content
if images and model in ["qwen-plus", "qwen-max"]:
# Only process the first 3 images
images = images[:3]
images_content = [
{
"type": "image_url",
"image_url": {
"url": f"data:{image.mime};base64,{encode_image(image.path)}"
},
}
for image in images
]
model = "qwen-vl" + model[4:]
messages = [
{
"role": "user",
"content": [{"type": "text", "text": message.content}, *images_content],
}
]
msg = cl.Message(content="", author="tarzan")
await msg.send()
print('messages', messages)
response = await client.chat.completions.create(
model=model,
messages=messages,
temperature=settings['Temperature'],
max_tokens=int(settings['MaxTokens']),
stream=streaming
)
if streaming:
async for part in response:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
else:
if token := response.choices[0].message.content or "":
await msg.stream_token(token)
await msg.update()
- 根据
qwen的接口文档,文档类的需要用qwen-long模型处理,图片需要用qwen-vl模型处理
创建.env文件
在项目根目录下创建.env环境变量,配置如下:
OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENAI_API_KEY=""
- 由于国内open ai 的限制使用,代码中使用的灵识服务提供兼容
open ai的接口 OPENAI_BASE_URL是为固定地址OPENAI_API_KEY是你创建灵识服务的API-KEY
安装依赖
执行以下命令安装依赖:
pip install -r .\requirements.txt
- 安装后,项目根目录下会多出
.chainlit和.files文件夹和chainlit.md文件
运行应用程序
要启动 Chainlit 应用程序,请打开终端并导航到包含的目录app.py。然后运行以下命令:
chainlit run app.py -w
- 该
-w标志告知Chainlit启用自动重新加载,因此您无需在每次更改应用程序时重新启动服务器。您的聊天机器人 UI 现在应该可以通过http://localhost:8000访问。
使用体验:


相关文章推荐
《使用 Xinference 部署本地模型》
《Fastgpt接入Whisper本地模型实现语音输入》
《Fastgpt部署和接入使用重排模型bge-reranker》
《Fastgpt部署接入 M3E和chatglm2-m3e文本向量模型》
《Fastgpt 无法启动或启动后无法正常使用的讨论(启动失败、用户未注册等问题这里)》
《vllm推理服务兼容openai服务API》
《vLLM模型推理引擎参数大全》
《解决vllm推理框架内在开启多显卡时报错问题》
《Ollama 在本地快速部署大型语言模型,可进行定制并创建属于您自己的模型》