刚刚,备受瞩目的LIama 3.1震撼问世,荣耀加冕为大模型领域的最新王者!
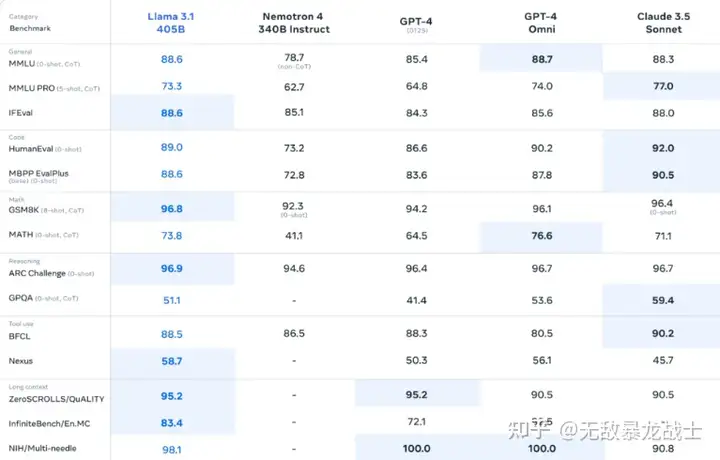
在横跨150余项基准测试的挑战中,LIama 3.1的405B版本以其卓越性能,不仅与当前顶尖的SOTA模型——GPT-4o及Claude 3.5 Sonnet并驾齐驱,更在多个维度上实现了超越,树立了新的性能标杆。
这一里程碑式的成就标志着,LIama 3.1作为最强开源模型的身份,已无可争议地成为了当前整体实力最强的模型之一,引领着大模型技术的新一轮飞跃。
确实,Llama 3.1的正式发布可谓是众望所归,此前的多番曝光与泄露早已激起了业界内外的广泛讨论与期待。如今,随着其正式亮相,所有关注者的目光都被这一卓越成果深深吸引。
自即日起,广大开发者与研究人员可通过官方渠道轻松下载Llama 3.1模型,并立即投入实践与应用之中。同时,Meta AI还贴心提供了在线试玩平台,让用户能够直观体验这一大模型所带来的创新与变革。
尤为值得一提的是,伴随Llama 3.1发布的近100页详细论文,无疑是研究社区的一份宝贵财富。该论文不仅全面阐述了Llama 3.1的诞生历程,更深入剖析了预训练数据的筛选与过滤、退火技术的运用、合成数据的生成、缩放定律的遵循、训练基础设施的构建与优化、并行计算的高效实现、训练配方的精细调整、训练后适应的策略、各类工具的应用技巧、基准测试的全面覆盖、推理策略的精心设计、模型量化的技术挑战以及视觉、语音、视频等多模态处理的创新探索。这一系列详尽的内容,为整个研究社区提供了宝贵的参考与启示。
对此,HuggingFace的首席科学家给予了高度评价,他建议所有从零开始探索大模型领域的研究者,都应将这篇论文视为必读之作。这不仅是因为其内容的全面性与深度,更是因为它所展现出的科研精神与创新思维,将为大模型技术的未来发展提供源源不断的动力与灵感。

小扎扎克伯格还在最新接受彭博社采访时专门嘲讽了一把OpenAI。
奥特曼的领导能力值得称赞,但有点讽刺的是公司名为OpenAI却成为构建封闭式人工智能模型的领导者。

小扎还专门为此撰写了一篇长文:开源AI是前进的道路。
以往,开源模型在性能、功能等方面大多落后于闭源模型,但现在:
就像开源的Linux在一众闭源系统中脱颖而出获得普及,并逐渐变得更先进、更安全,拥有比闭源系统更广泛的生态。
我相信Llama 3.1将成为行业的一个转折点。

迄今为止,所有Llama 版本的总下载量已超过 3 亿次,Meta也是放下豪言:
这仅仅是个开始。
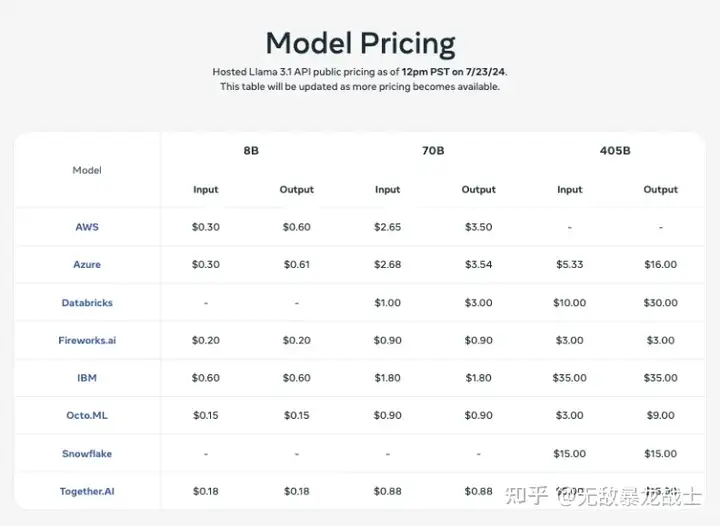
各大云厂商也在第一时间上线了的Llama 3.1的支持,价格是这样的:
LIama 3.1震撼发布:模型能力再创新高
今日,我们迎来了人工智能领域的一个重要里程碑——LIama 3.1的官方正式发布。这款备受期待的模型在能力上实现了全面升级,为用户带来了前所未有的智能体验。
首先,让我们聚焦于LIama 3.1的核心能力升级。最引人注目的莫过于其对上下文长度的扩展,从之前的限制一举跃升至惊人的128K。这一变革不仅意味着模型能够处理更加复杂和深入的对话场景,还为用户提供了更加连贯、自然的交互体验。
此外,LIama 3.1还新增了对八种语言的支持,进一步拓宽了其应用场景和全球用户的覆盖范围。这一举措不仅展示了模型在跨语言处理方面的强大能力,也体现了其致力于服务全球用户的决心和愿景。
而说到LIama 3.1的旗舰版本——405B超大杯,其表现更是令人瞩目。在常识推理、可操纵性、数学计算、工具使用以及多语言翻译等多个关键领域,该版本均展现出了与现有顶尖模型相媲美甚至超越的实力。这些能力的全面升级,不仅让LIama 3.1在人工智能领域中脱颖而出,更为用户带来了更加智能、高效的解决方案。
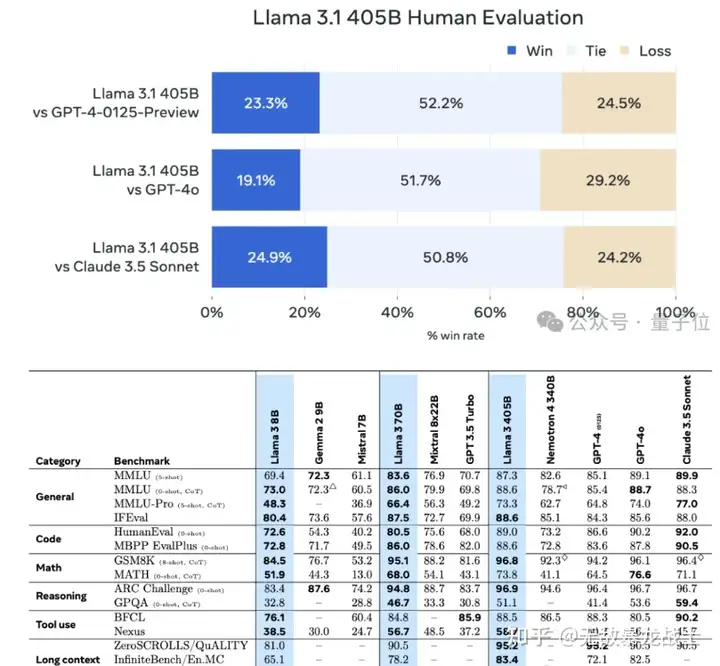
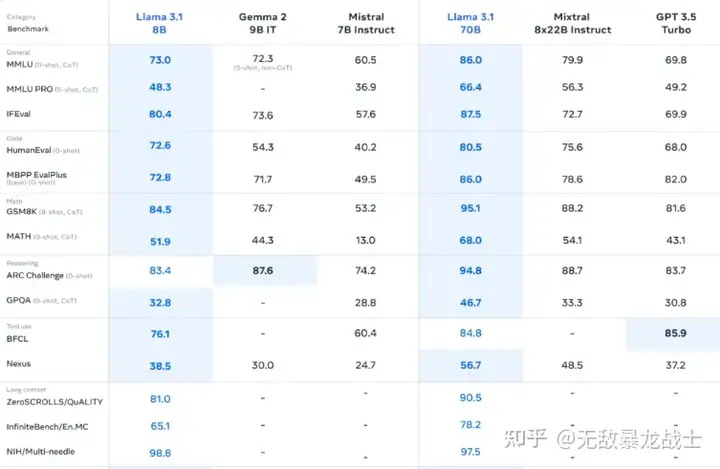
除此之外,也推出了8B和70B模型的升级版本,能力与同等参数下的顶尖模型基本持平。
再来看模型架构。
官方介绍,要在超15万亿个token上训练 Llama 3.1 405B模型挑战很大。
为此他们大幅优化了整个训练栈,并把模型算力规模首次扩展到了超过16000个H100 GPU。

LIama 3.1在技术层面实现了多项重大突破,首先,它依旧采用经典的仅解码器Transformer架构,但在此基础上进行了细致的微调与优化,旨在进一步提升模型的性能与效率。在训练流程上,LIama 3.1引入了迭代的post-training策略,通过多轮次的监督微调(SFT)和直接偏好优化(DPO),针对模型的各项能力进行精准提升,确保其在常识、可操纵性、数学、工具使用及多语言翻译等领域达到或超越现有顶尖水平。
与Llama系列的前代产品相比,LIama 3.1在预训练和post-training阶段所使用的数据量与质量均实现了显著提升。这一改进不仅增强了模型的泛化能力,还使其能够更好地理解和应对多样化的输入场景。
面对405B这样大规模模型的推理挑战,Meta采取了创新的量化技术,将模型从16位(BF16)精度成功量化至8位(FP8)精度,从而在保持模型性能的同时,大幅降低了计算资源的需求。这一举措使得LIama 3.1能够在单个服务器节点内高效运行,为大规模生产推理提供了有力支持。
在指令微调方面,Meta对LIama 3.1进行了深度优化,显著提升了模型对用户指令的响应速度和准确性,同时增强了其遵循复杂指令的能力。此外,团队还特别注重模型的安全性,确保其在处理各类指令时能够遵循伦理规范与数据安全原则。
在post-training阶段,Meta采取了多轮次对齐的策略,每轮均包含SFT、拒绝采样(RS)和DPO等关键技术环节。其中,SFT过程大量依赖于合成数据生成技术,通过多次迭代和精细的数据处理流程,确保了训练示例的高质量与多样性。同时,团队还借鉴了Deepseek等先进方法,对代码和数学相关的数据处理流水线进行了优化与升级。

除了最基本的根据提示词响应,Meta官方表示,任何普通开发者可以用它做些高级的事情,比如:
- 实时和批量推理
- 监督微调
- 针对特定应用评估模型
- 持续预训练
- 检索增强生成 (RAG)
- 函数调用
- 合成数据生成
而这背后也是由它的强大生态伙伴支持。

小札撰写长文:小扎力推开源AI:迈向未来的必由之路
回望高性能计算的早期岁月,大型科技公司纷纷斥巨资打造各自的闭源Unix系统,那时,闭源似乎是通往先进软件的唯一途径。然而,历史的车轮滚滚向前,开源的Linux操作系统以其独特的魅力——代码自由修改、成本效益显著,逐渐赢得了全球开发者的青睐。随着时间的推移,Linux不仅技术日益精进,安全性显著提升,更构建了一个庞大而多元的生态系统,其功能之丰富远超任何闭源Unix系统。如今,Linux已成为云计算与移动设备的基石,深刻影响着我们的生活与工作,带来了前所未有的便捷与高效。
我坚信,人工智能领域也将沿着这一轨迹前行。当前,虽有几家科技公司引领着闭源AI模型的发展,但开源的力量正迅速崛起,不断缩小与前沿技术的差距。以Llama系列为例,从Llama 2的初露锋芒,到Llama 3与顶尖模型并驾齐驱,乃至未来Llama模型有望登顶行业之巅,其开放、可修改及成本效益高的特性已显露无遗。
今天,我们自豪地宣布,Meta正引领着“开源人工智能成为行业标准”的浪潮。我们推出了Llama 3.1 405B这一前沿级别的开源AI模型,以及70B和8B等优化版本。这些模型不仅在成本/性能比上远超闭源竞品,更以其开放的特性,成为微调与蒸馏小型模型的理想选择。
为了构建更加繁荣的开源AI生态,我们正携手亚马逊、Databricks、英伟达等业界巨头,共同推出一系列服务,助力开发者轻松实现模型的微调与蒸馏。同时,Groq等创新企业也为我们提供了低延迟、低成本的推理服务,确保新模型能够高效运行于各大云平台之上,包括AWS、Azure、Google Cloud及Oracle等。此外,Scale.AI、Dell、德勤等知名企业已蓄势待发,准备助力企业采用Llama模型,并基于自身数据训练定制化AI模型。
Meta深知,开源AI不仅是技术进步的加速器,更是推动社会进步的重要力量。因此,我们坚定不移地致力于开源AI的发展,旨在打造一个长期可持续的平台,让AI的福祉惠及每一个人。我相信,随着开源AI生态的日益壮大,我们将共同见证一个更加智能、更加包容的未来世界的到来。
开源人工智能为何成为开发者的优选
在与全球各地的开发者、企业领袖及政策制定者的交流中,我深刻感受到开源人工智能(AI)对开发者而言,具有不可估量的价值。以下是几个核心原因:
1. 定制化的模型训练与微调能力
每个组织都拥有其独特的数据集和业务需求,因此,最适合的AI模型必然是那些能够根据其特定数据进行训练或微调的模型。无论是针对设备上的简单任务,还是处理复杂问题的挑战,开源AI提供了灵活的解决方案。开发者可以利用最前沿的Llama模型作为基础,结合自身数据进一步训练,并通过蒸馏技术优化模型大小,以完美匹配实际需求。这一过程完全自主掌控,无需担心数据泄露给第三方。
2. 掌控命运,避免闭源束缚
许多组织担忧闭源AI模型的潜在风险,包括无法自主运行和控制模型、模型更新带来的使用条款变更、甚至服务突然中断等。这些不确定性限制了组织的长期发展规划。相比之下,开源AI赋予了组织更大的自主权,确保他们不会被单一供应商所限制。同时,开源生态的广泛性使得工具链兼容性更强,便于在不同平台间轻松迁移,为组织带来更大的灵活性和稳定性。
3. 数据安全的有力保障
对于处理敏感数据的组织而言,数据安全是首要考虑的问题。闭源AI模型往往需要通过云API传输数据,这增加了数据泄露的风险。而开源AI则允许组织在本地或受信任的环境中运行模型,从而有效保护数据安全。此外,开源软件的透明开发过程也普遍被认为能够提高软件的安全性,因为更多的眼睛能够发现潜在的安全漏洞。
4. 成本效益与运行效率
在成本方面,开源AI同样展现出巨大优势。开发者可以在自己的基础设施上部署Llama 3.1 405B等开源模型,并以远低于闭源模型(如GPT-4)的成本进行推理任务。这种成本优势不仅体现在基础设施投入上,还包括了长期维护和升级的费用。同时,开源AI模型通常经过优化,能够在保证性能的同时降低资源消耗,提高运行效率。
5. 面向未来的长期投资
最后,开源AI代表了未来的发展趋势。随着技术的不断进步和开源社区的日益壮大,开源AI的发展速度往往超过闭源模型。对于希望建立长期竞争优势的组织而言,投资于开源AI生态系统意味着站在了技术发展的前沿。这不仅有助于他们快速适应市场变化,还能在未来的竞争中占据有利地位。
为什么开源人工智能对Meta至关重要
Meta的核心使命在于为人们提供无与伦比的体验与服务。为实现这一目标,我们深知必须紧跟技术前沿,同时避免陷入竞争对手构建的闭源生态系统陷阱,以免束缚我们的创新步伐。
过往的经验,特别是与苹果等平台的互动,让我们深刻体会到闭源限制对服务发展的阻碍。无论是高额的开发者费用、突如其来的规则变更,还是对产品创新的阻碍,都让我们意识到,构建一个开放、自由的生态系统对于推动技术创新和服务优化至关重要。这一哲学理念,正是我们致力于在人工智能及AR/VR领域打造开放生态系统的根本动力。
关于开源Llama是否会削弱我们的技术优势,我的看法是,这实际上是对大局的误解。原因有四:
首先,Llama的未来发展离不开一个完善的工具生态系统,这包括效率提升、硬件优化及多领域集成。若我们独自闭门造车,不仅生态系统难以成形,我们的技术表现也将难以超越那些成熟的闭源系统。
其次,人工智能领域的竞争异常激烈,技术迭代迅速。开源某一模型并不会立即赋予我们长期不可撼动的优势,关键在于持续保持技术竞争力、提升效率和保持开放性,让Llama在竞争中不断进化,成为行业标准。
第三,与某些闭源模型提供商不同,Meta的商业模式并不依赖于出售AI模型访问权。因此,公开发布Llama不仅不会削弱我们的盈利能力、可持续性或研发投入,反而有助于我们通过生态系统的繁荣实现共赢。
最后,Meta拥有悠久的开源历史和成功案例。从Open Compute项目到PyTorch、React等开源工具的发布,我们始终致力于通过开源促进技术创新和生态系统发展。这一长期策略不仅为我们节省了巨额成本,更让我们从全球开发者的创新中受益匪浅。我们坚信,坚持开源道路将是Meta持续成功的关键。
为什么开源人工智能对世界至关重要
我坚信,开源是塑造人工智能积极未来的关键所在。人工智能作为现代科技的巅峰之作,其潜力无可估量,不仅能够极大地提升人类的生产效率、激发无限创造力,还能显著改善我们的生活质量,加速经济繁荣,并推动医学与科学研究的飞跃性进步。开源模式的引入,将确保这一强大技术的红利惠及全球更广泛的人群,防止技术垄断于少数企业之手,促进技术资源的均衡分配与安全应用。
关于开源人工智能模型的安全性,我的观点是,相较于其他模式,开源将带来更高的安全标准。安全框架的构建需防范两类风险:无意伤害与故意伤害。无意伤害源自技术本身可能产生的非预期负面效应,如健康建议的误导或未来可能出现的系统失控等。而故意伤害则指恶意行为者利用AI模型实施破坏活动。在这两方面,开源因其透明度与广泛的审查机制,能够更有效地降低风险。历史经验证明,开源软件在安全性上往往表现更佳。因此,Llama等开源AI模型及其配套的安全系统(如Llama Guard)有望比闭源模型提供更加安全可靠的保障。
我们深知安全性的重要性,因此建立了严格的安全流程,包括全面的测试与红队演练,以评估模型可能带来的潜在危害,并在发布前将风险降至最低。由于模型的开放性,任何人均可参与测试,进一步增强了安全性的保障。同时,我们认识到这些模型是基于互联网上的公开信息训练的,其安全性评估应基于与现有信息获取渠道(如搜索引擎)的比较,以确保其不会带来额外的风险。
展望未来,开源人工智能不仅是技术创新的重要驱动力,更是全球经济机会与安全的重要基石。历史上,众多科技巨头与科研突破均植根于开源软件的肥沃土壤。我们有理由相信,通过全球共同投资与努力,下一代的企业与科研机构将更加依赖开源人工智能,推动人类社会迈向更加繁荣与安全的未来。
总之,开源人工智能不仅是技术进步的象征,更是实现全球共享技术红利、促进经济繁荣与安全的重要途径。它代表着人类利用智能科技为每个人创造最大福祉的最佳选择。
携手共创未来:共建Llama生态系统
回顾往昔,Meta在推出Llama模型时,虽已自行研发并成功发布,但在构建广泛生态系统方面尚有未尽之力。而今,我们采取了一种全新的策略,旨在开启一个全新的篇章。
我们正积极在内部组建一支强大的团队,致力于让Llama成为更多开发人员和合作伙伴手中的利器。同时,我们也主动出击,积极寻求并建立广泛的合作伙伴关系,力求将Llama的潜力最大化,让生态系统中的每一家公司都能基于Llama为他们的客户量身打造独特的功能与价值。
我坚信,Llama 3.1的发布将是行业发展的一个重要里程碑,它不仅标志着开源在人工智能领域的进一步深入,更预示着大多数开发人员将开始将开源作为他们的首选。这一趋势,正如初升的太阳,光芒万丈,预示着无限的可能与希望。
在此,我诚挚地邀请您加入我们的行列,成为这一伟大旅程中的一员。让我们携手并进,共同探索人工智能的无限可能,将这份科技的力量带给世界的每一个角落,让每个人都能享受到人工智能带来的便利与福祉。这不仅仅是一场技术的革命,更是一次人类智慧的共同飞跃。
你好!我是LCAB-LJJ,一名热爱AIGC的博主,如果你觉得我的文章内容还不错请点赞收藏转发吧,我会持续更新最热最新的新闻热点教程等,更多内容在宝藏小站,教程