MoneyPrinterPlus之前使用的是各种云厂商的语音识别服务来进行语音的视频和字幕的识别工作。
但是很多小伙伴说云服务用不起。
那么没办法,MoneyPrinterPlus上线最新版本,支持fasterWhisper本地语音识别模型。
赶紧来体验吧。
软件准备
当然,前提条件就是你需要下载MoneyPrinterPlus软件啦。
下载地址: https://github.com/ddean2009/MoneyPrinterPlus
用得好的朋友,不妨给个star支持一下。 在软件v4.1版本之后,MoneyPrinterPlus已经支持fasterWhisper本地语音识别模型。
安装fasterWhipser的模型
fasterWhipser服务直接由MoneyPrinterPlus调用。所以不需要第三方的fasterWhisper服务。
但是我们需要下载对应的fasterWhipser模型到MoneyPrinterPlus中。
fasterWhisper模型下载地址:https://huggingface.co/Systran
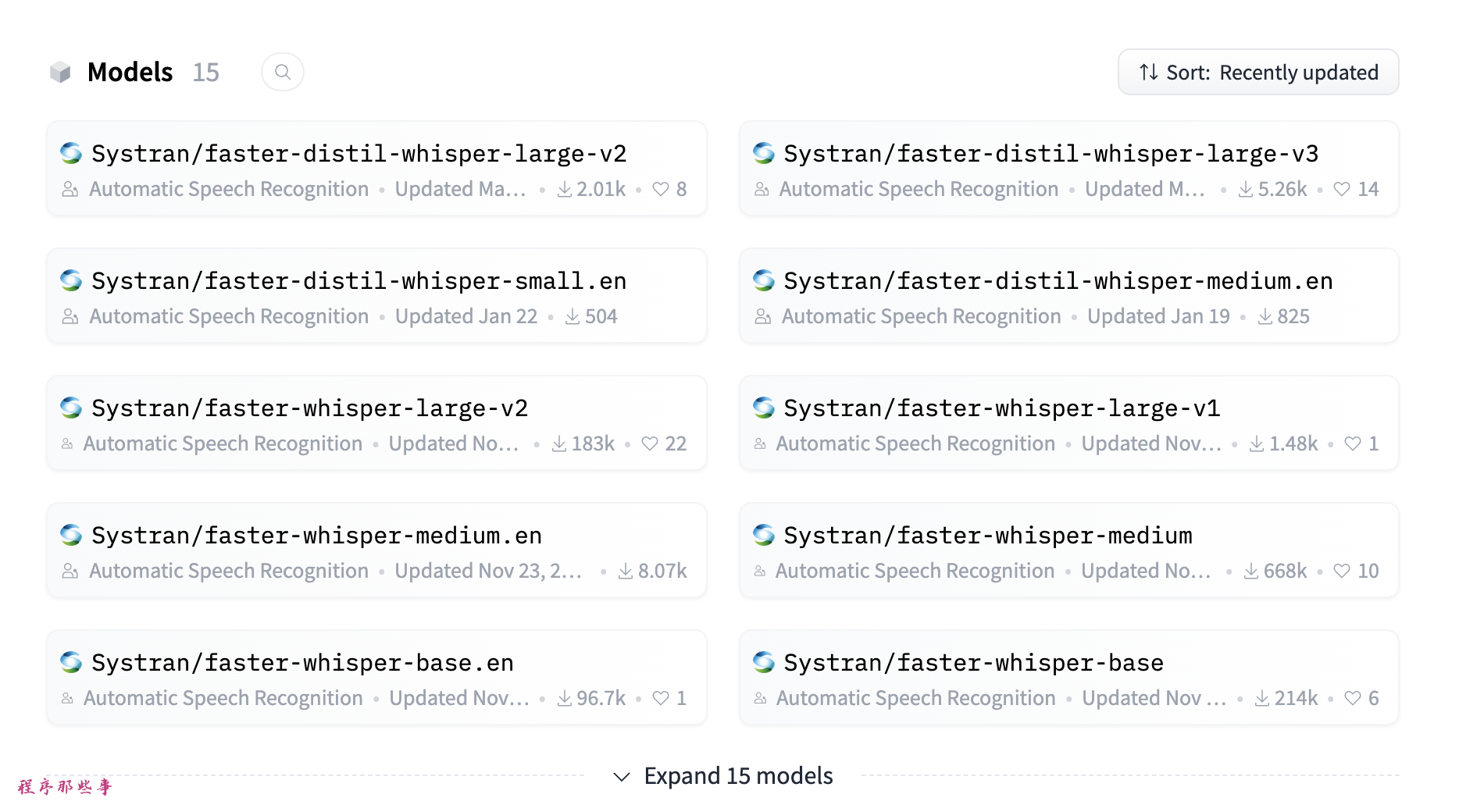
可以看到里面有很多种模型,大家可以根据需要自行下载对应的模型。
怎么下载呢?
进入到MoneyPrinterPlus的fasterwhisper目录下:
cd fasterwhisper
执行git clone命令:
git clone https://huggingface.co/Systran/faster-whisper-tiny tiny
目前MoneyPrinterPlus支持下面几种模型名称:
'large-v3', 'large-v2', 'large-v1', 'distil-large-v3', 'distil-large-v2', 'medium', 'base', 'small', 'tiny'
所以你在git clone的时候,需要把faster-whisper仓库中的模型目录重命名为MoneyPrinterPlus支持的模型名称。
比如faster-whisper-tiny, 对应的模型叫做tiny,所以我们git clone的时候同时做了重命名操作:
git clone https://huggingface.co/Systran/faster-whisper-tiny tiny
上面的命令会在本地创建一个tiny的目录。目录里面包含了faster-whisper-tiny的所有模型内容。
在MoneyPrinterPlus中配置faster-whisper
我们启动MoneyPrinterPlus。
在基本配置区域:
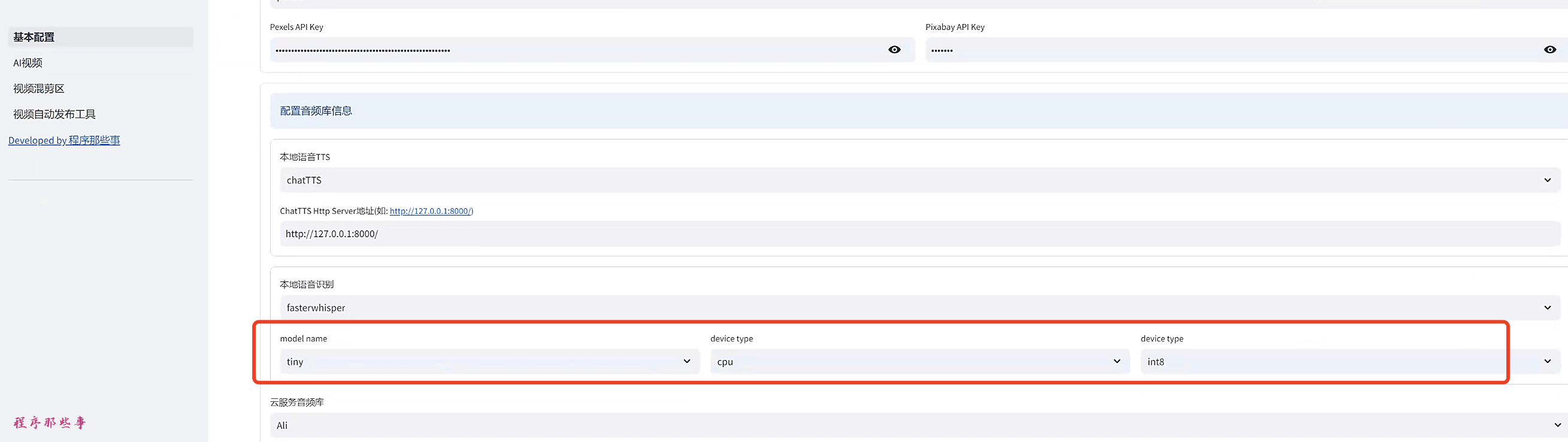
可以配置本地语音识别模型。
model name就是你下载下来的模型名字。
device type 可以选择cpu,cuda或者auto。
compute type 支持'int8','int8_float16','float16'这几种类型。
配置好之后,在AI视频区域。
语音识别配置中我们选择本地模型,即可使用到fasterWhisper了。

同样的在视频混剪区域,我们也可以选择本地模型,即可使用到fasterWhisper了。
总结
因为是本地运行的fasterWhisper,所以在运行中可能会出现一些环境的问题。大家可以参考fasterWhisper的说明来解决。
标签:MoneyPrinterPlus,faster,whisper,模型,tiny,fasterWhisper,无缝 From: https://www.cnblogs.com/flydean/p/18320436