Transformer:这个模型架构就是摒弃了所有的循环结构,完全依赖于注意力机制对源语言序列和目标语言序列全局依赖的建模
对于循环神经网络来说,上下文的语义依赖是通过维护循环单元中的隐状态实现的。在编码过程中,每一个时间步的输入建模都涉及到对隐藏状态的修改。随着序列长度的增加,编码在隐藏状态中的序列早期的上下文信息被逐渐遗忘。尽管注意力机制的引入在一定程度上缓解了这个问题,但循环网络在编码效率方面仍存在很大的不足之处。由于编码端和解码端的每一个时间步的隐藏状态都依赖于前一时间步的计算结果,这就造成了在训练和推断阶段的低效。
Transformer的结构
Transformer的主要组件包括编码器(Encoder)、解码器(Decoder)和注意力层。其核心是利用多头自注意力机制(Multi-Head Self-Attention),使每个位置的表示不仅依赖于当前位置,还能够直接获取其他位置的表示
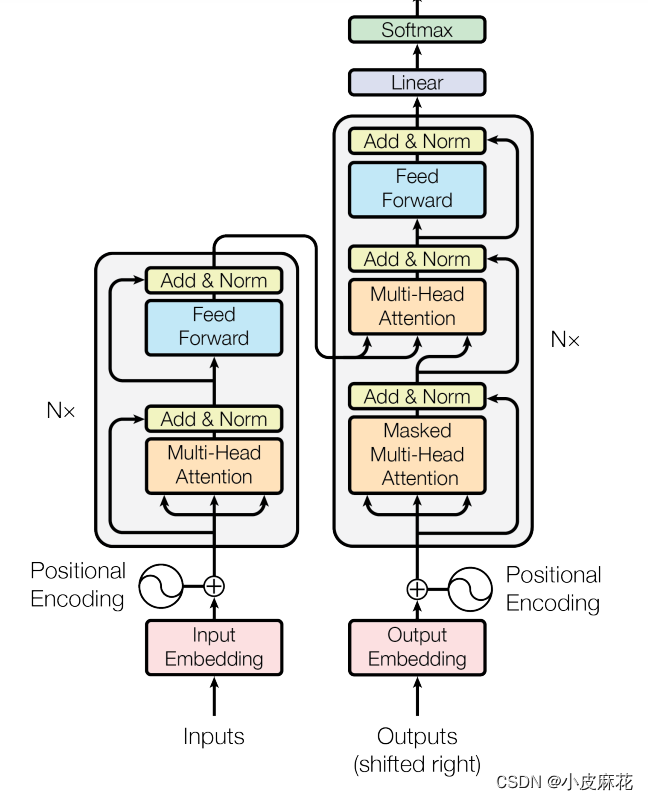
从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。第⼀个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。
嵌入表示层
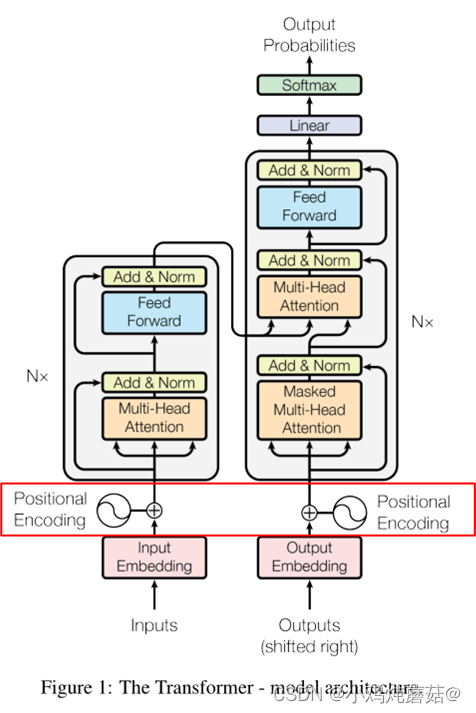
在transformer的encoder和decoder的输入层中,使用了Positional Encoding,使得最终的输入满足:
input = input_embedding + positional_embedding
对于输入文本序列,先通过一个输入嵌入层(Input Embedding)将每个单词转换为其相对应的向量表示。通常直接对每个单词创建一个向量表示。由于 Transfomer 模型不再使用基于循环的方式建模文本输入,序列中不再有任何信息能够提示模型单词之间的相对位置关系。在送入编码器端建模其上下文语义之前,一个非常重要的操作是在词嵌入中加入位置编码(Positional Encoding)这一特征。具体来说,序列中每一个单词所在的位置都对应一个向量。
位置编码(Positional Encoding)是一种用词的位置信息对序列中的每个词进行二次表示的方法,让输入数据携带位置信息,是模型能够找出位置特点。正如前文所述,Transformer模型本身不具备像RNN那样的学习词序信息的能力,需要主动将词序信息喂给模型。那么,模型原先的输入是不含词序信息的词向量,位置编码需要将词序信息和词向量结合起来形成一种新的表示输入给模型,这样模型就具备了学习词序信息的能力
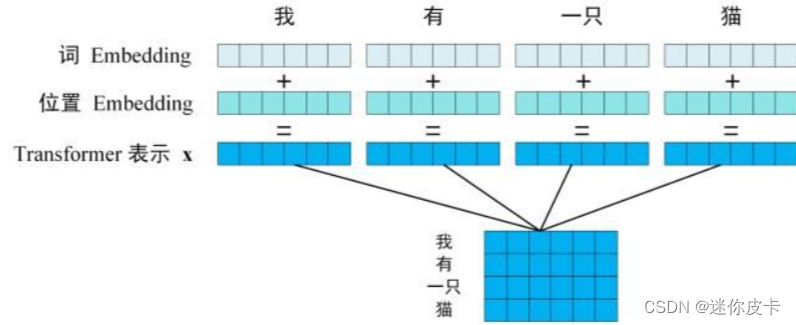
Positional encoding和input embedding是同等维度的,所以可以将两者进行相加得到输入向量
这一向量会与单词表示对应相加并送入到后续模块中做进一步处理。在训练的过程当中,模型会自动地学习到如何利用这部分位置信息。不同位置对应的编码,Transformer 模型使用不同频率的正余弦函数如下所示:
\(PE_{(pos,2i)}=\sin(pos/10000^{2i/d})\\PE_{(pos,2i+1)}=\cos(pos/10000^{2i/d})\)
- \[pos$$ 表示token在sequence中的位置 \]
从图像的角度理解,可以认为pos代表图像的行,i代表当前行对应的列,这样就可以对图像中的每一个像素点进行编码了
- \[d$$则对应词嵌入的总维度 \]
- 基本背景:
当我们选取一个简单的Positional Encoding表达方法,最简单的位置编码就是计数,即使用作为文本中每个字的位置编码(例如第2个字的Positional Encoding=[1,1,...,1])。但是这种编码有两个缺点:
- 如果一个句子的字数较多,则后面的字比第一个字的Positional Encoding大太多,和word embedding合并以后难免会出现特征在数值上的倾斜;
- 这种位置编码的数值比一般的word embedding的数值要大,对模型可能有一定的干扰。
- 加入归一化操作可以解决上述问题,最简单的操作就是将所有值同时初以一个常数T,例如第2个字的Positional Encoding=[1/T,1/T,...,1/T]。这样固然使得所有位置编码都落入区间,但是问题也是显著的:不同长度文本的位置编码步长是不同的,在较短的文本中紧紧相邻的两个字的位置编码差异,会和长文本中相邻数个字的两个字的位置编码差异一致,如下图所示

可以看到第一句的第2个字pos=0.5,第二句中的第5个字pos=0.5,虽然两者的pos值是一样的,但是很明显两者之间位置差异是很大的
- 使用三角函数计算位置编码
优点是:
- 可以使PE分布在区间。
- 不同语句相同位置的字符PE值一样(如:当pos=0时,PE=0)。
缺点是:
三角函数具有周期性,可能出现pos值不同但是PE值相同的情况。
为了解决这个缺陷,我们可以在原始PE的基础上再增加一个维度:\(PE=[sin(\frac{pos}{\alpha}),sin(\frac{pos}{\beta})]\),虽然还是可能出现pos值不同但是PE值相同的情况,但是整个PE的周期明显变长。如果我们把PE的长度加长到和word embedding一样长,就像\(PE=[sin(\frac{pos}{10000^{0/d_{model}}}),sin(\frac{pos}{10000^{2/d_{model}}}),...,sin(\frac{pos}{10000^{2i/d_{model}}})]\),PE的周期就可以看成是无限长的了,换句话说不论pos有多大都不会出现PE值相同的情况。
为了让PE值的周期更长,交替使用sin/cos来计算PE的值可以更好,于是就得到了计算公式:
\(PE_{(pos,2i)}=\sin(pos/10000^{2i/d})\\PE_{(pos,2i+1)}=\cos(pos/10000^{2i/d})\)
最后,位置编码的维度和词嵌入向量的维度相同( 均为 d_model),模型通过将二者相加作为模型输入
注意力层
在Transformer模型中,注意力层是核心组件之一,特别是自注意力(Self-Attention)机制,它使得模型能够处理序列数据中的长距离依赖问题。
何为self-attention
首先我们要明白什么是attention,对于传统的seq2seq任务,例如中-英文翻译,输入中文,得到英文,即source是中文句子(x1 x2 x3),英文句子是target(y1 y2 y3)
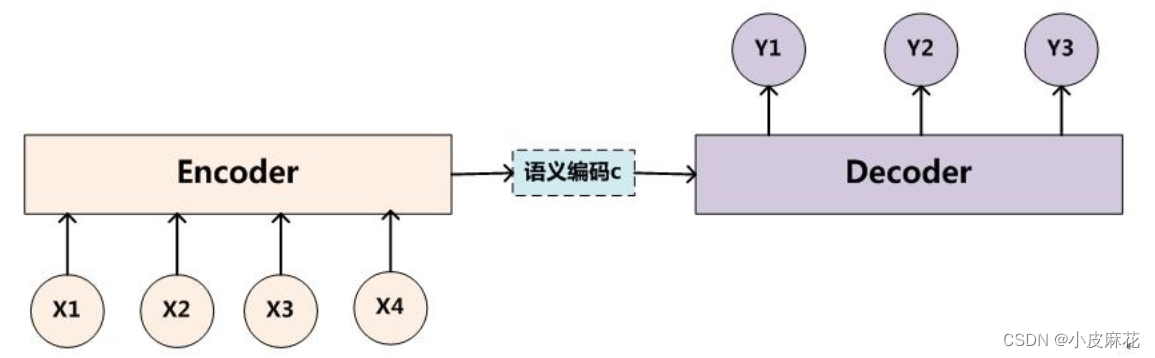
attention机制发生在target的元素和source中的所有元素之间。简单的将就是attention机制中的权重计算需要target参与,即在上述Encoder-Decoder模型中,Encoder和Decoder两部分都需要参与运算。
而对于self-attention,它不需要Decoder的参与,而是source内部元素之间发生的运算
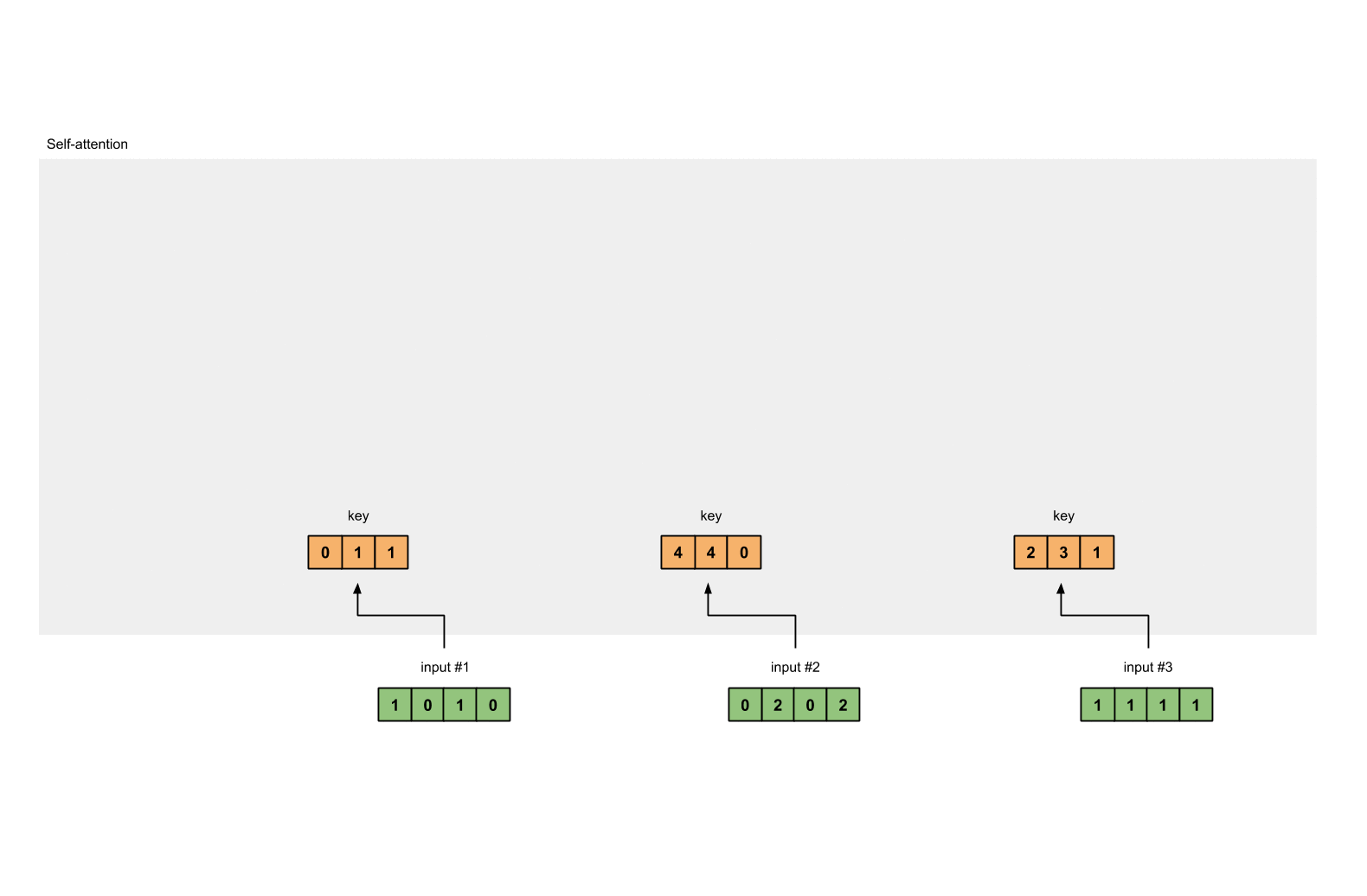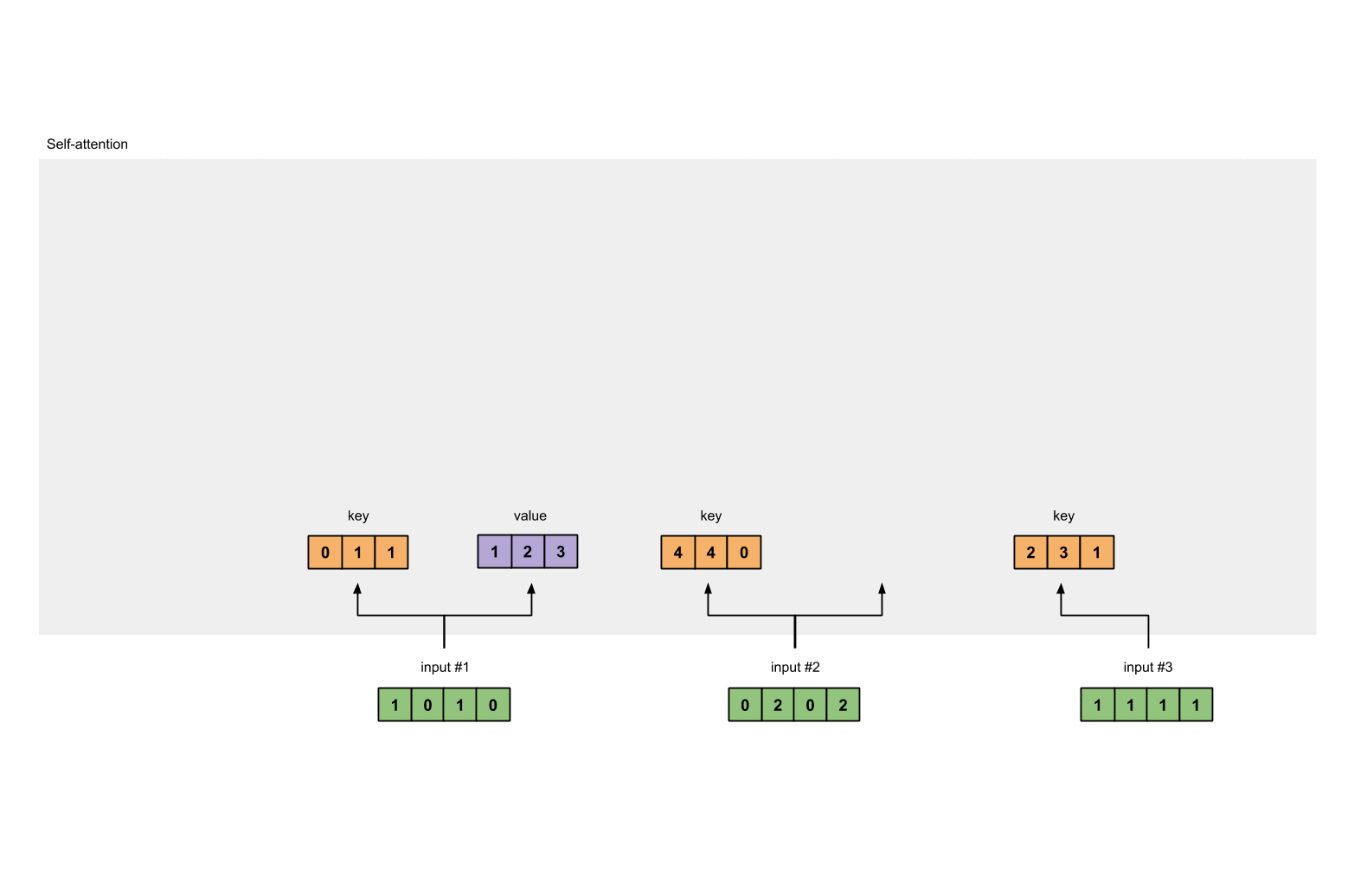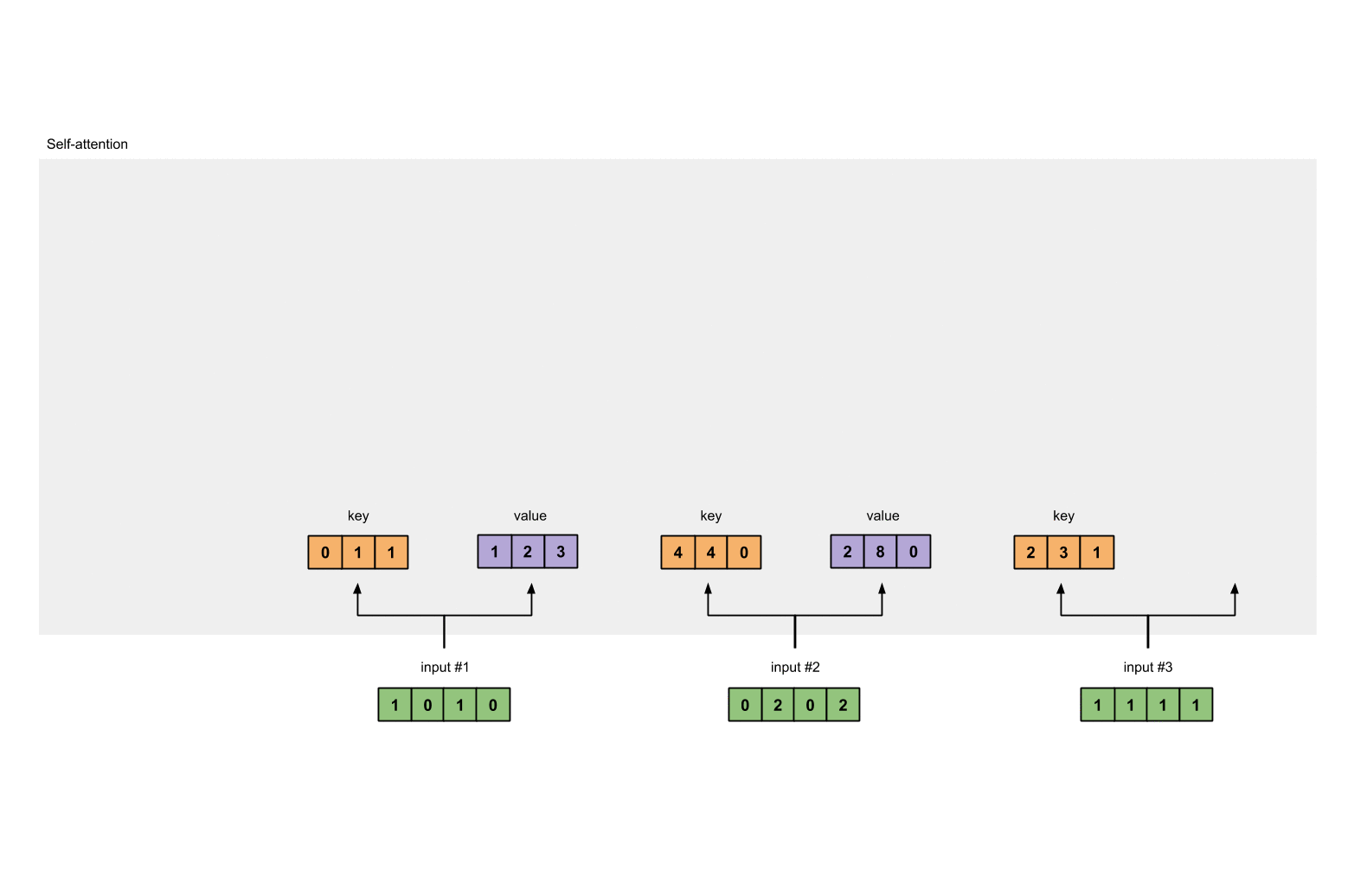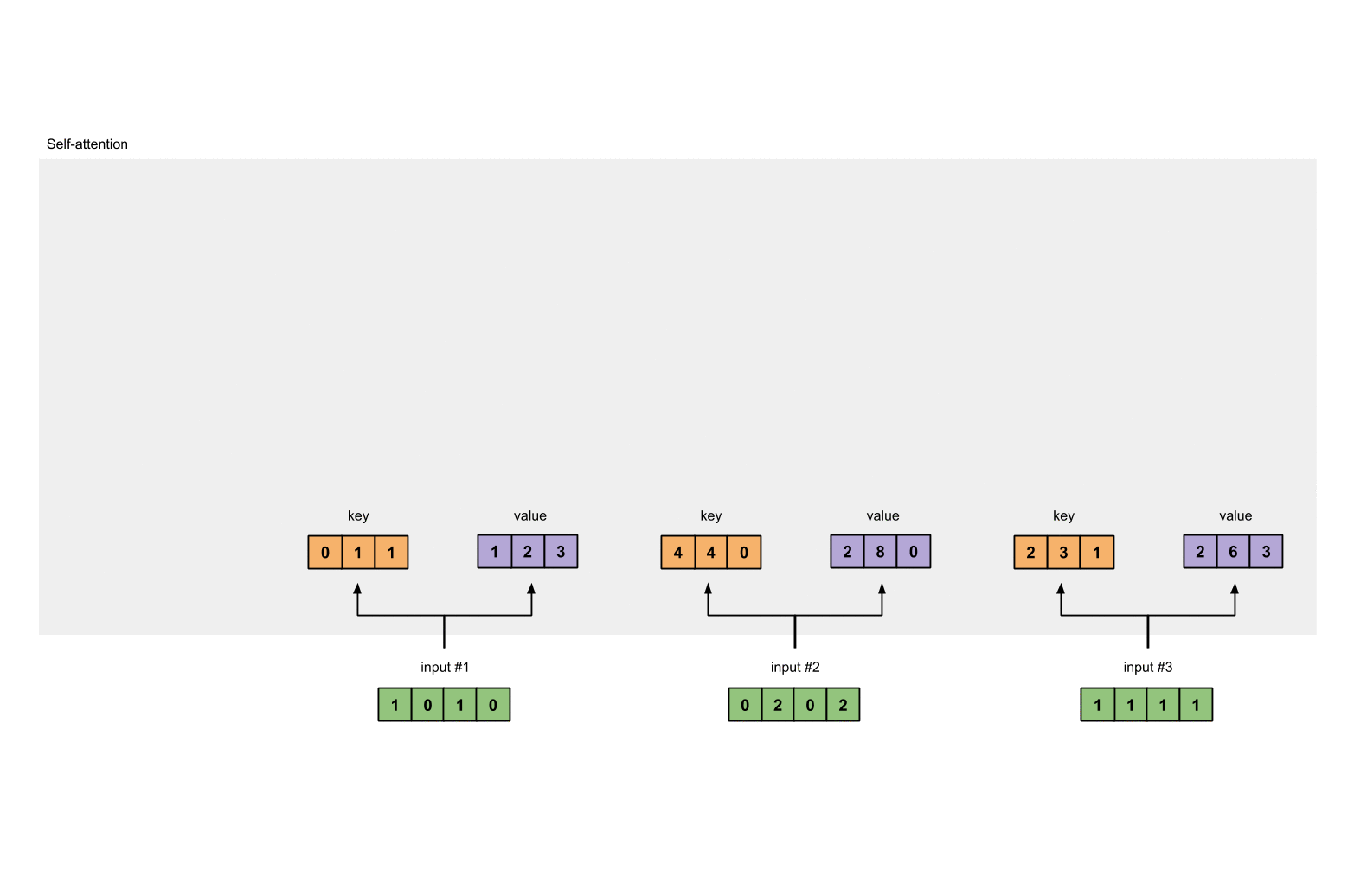
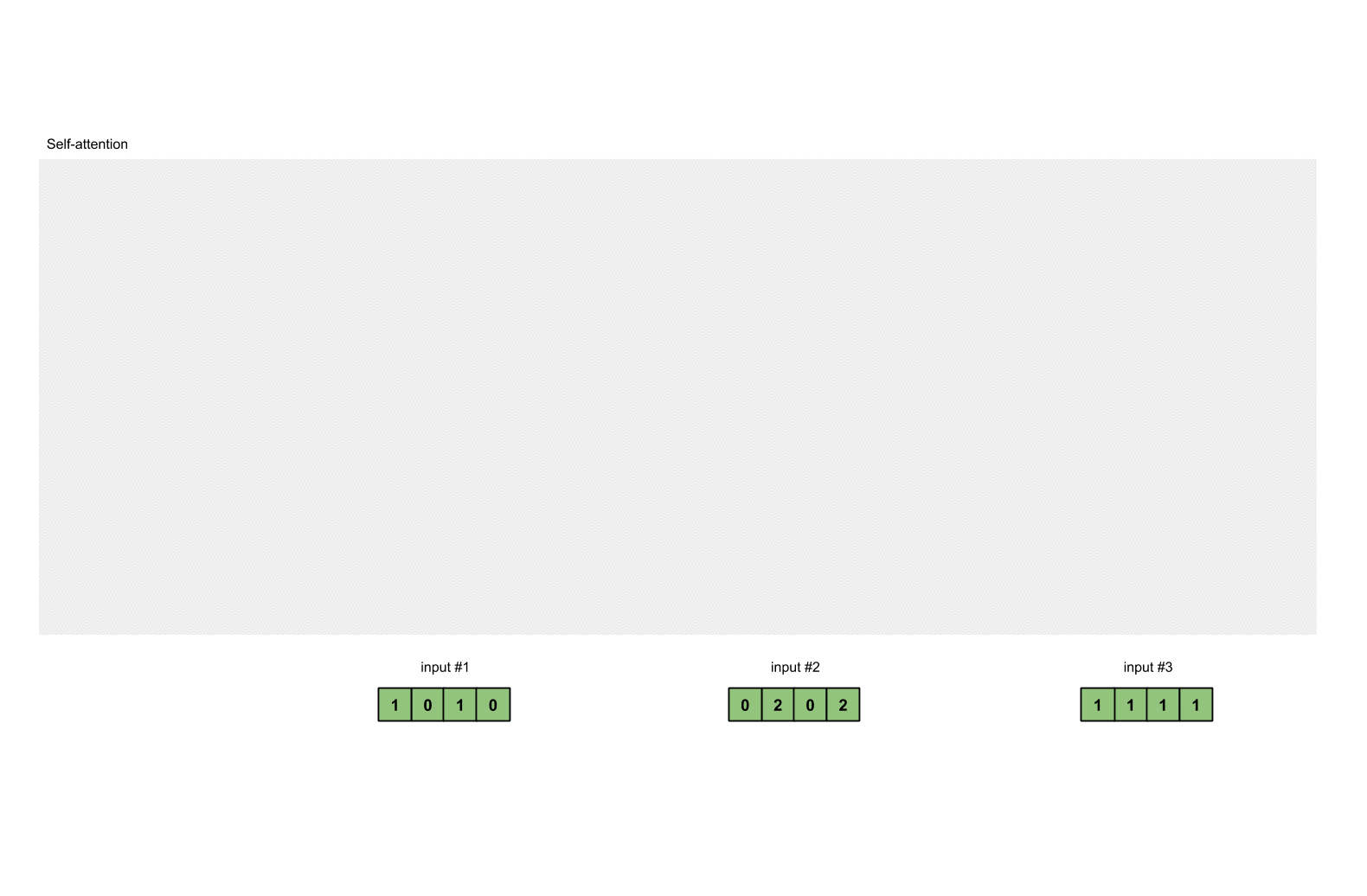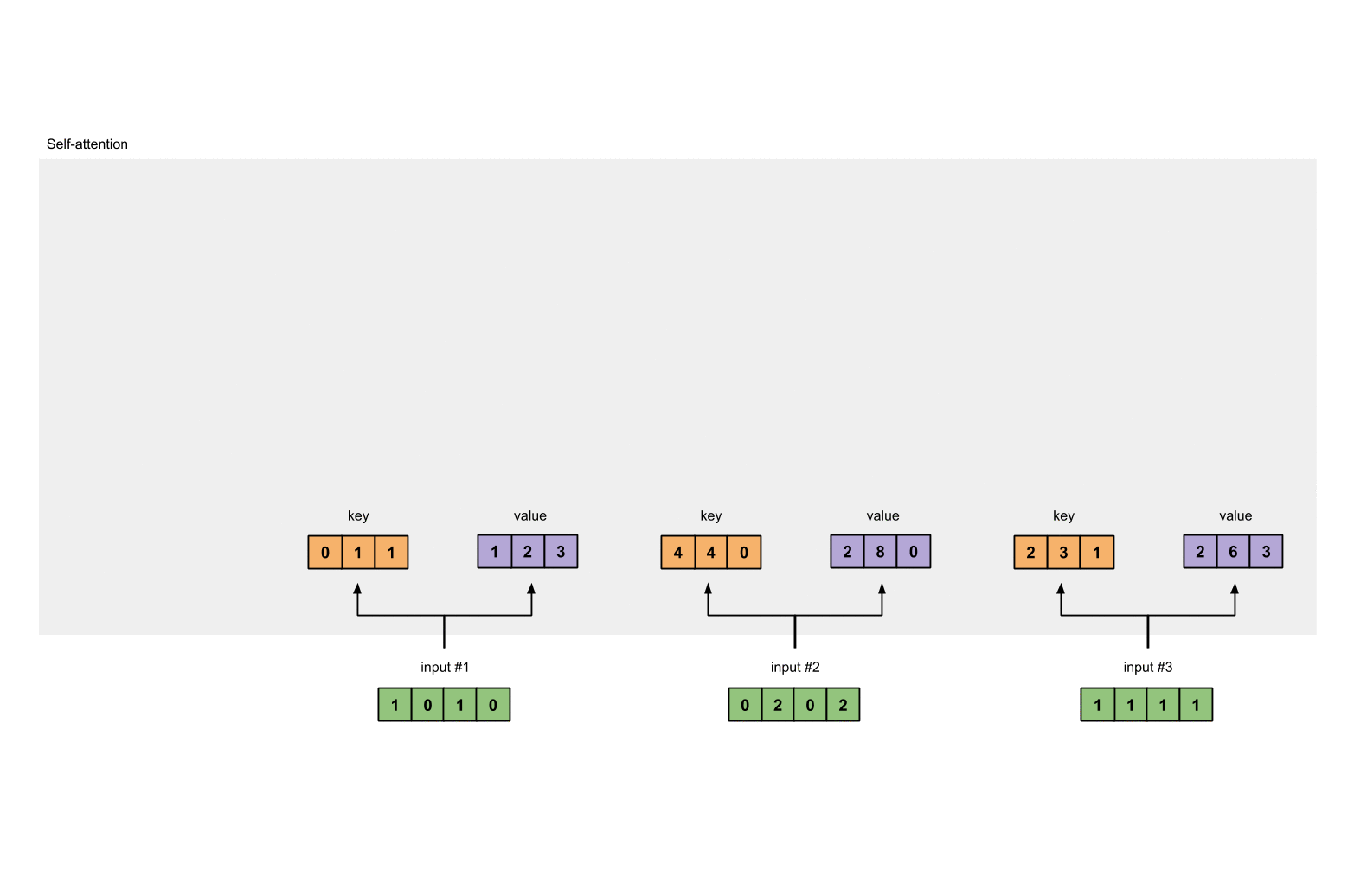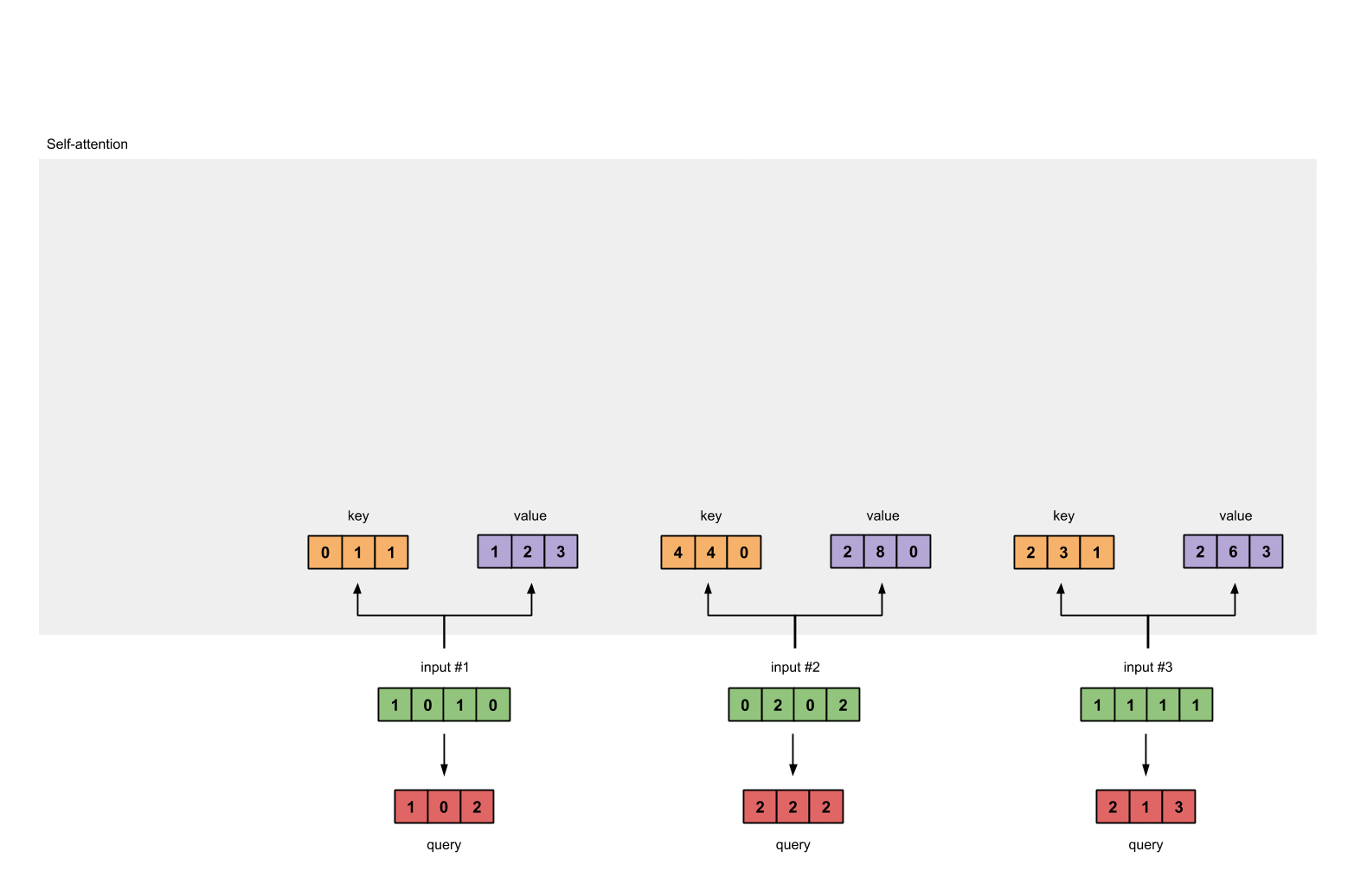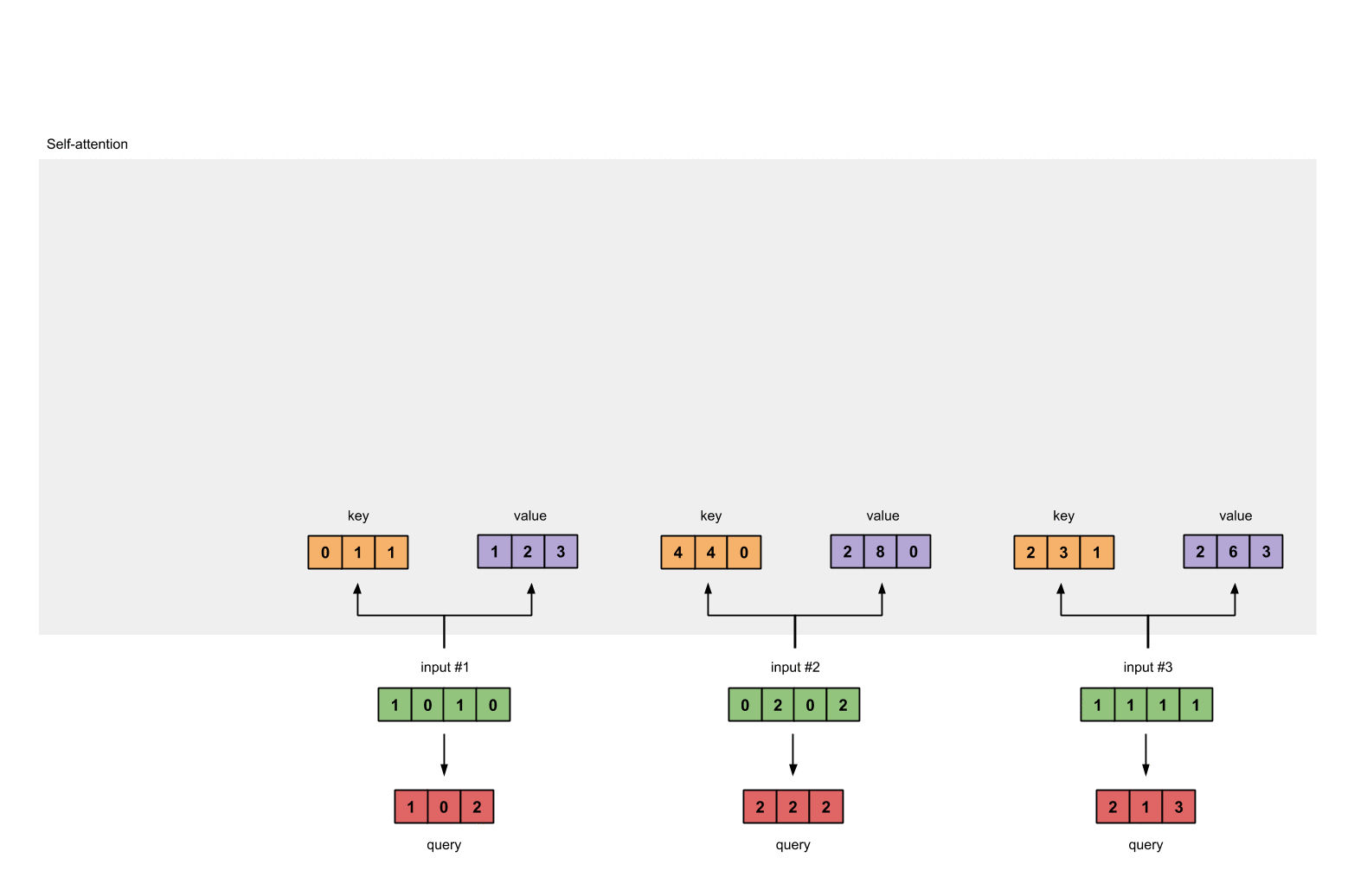
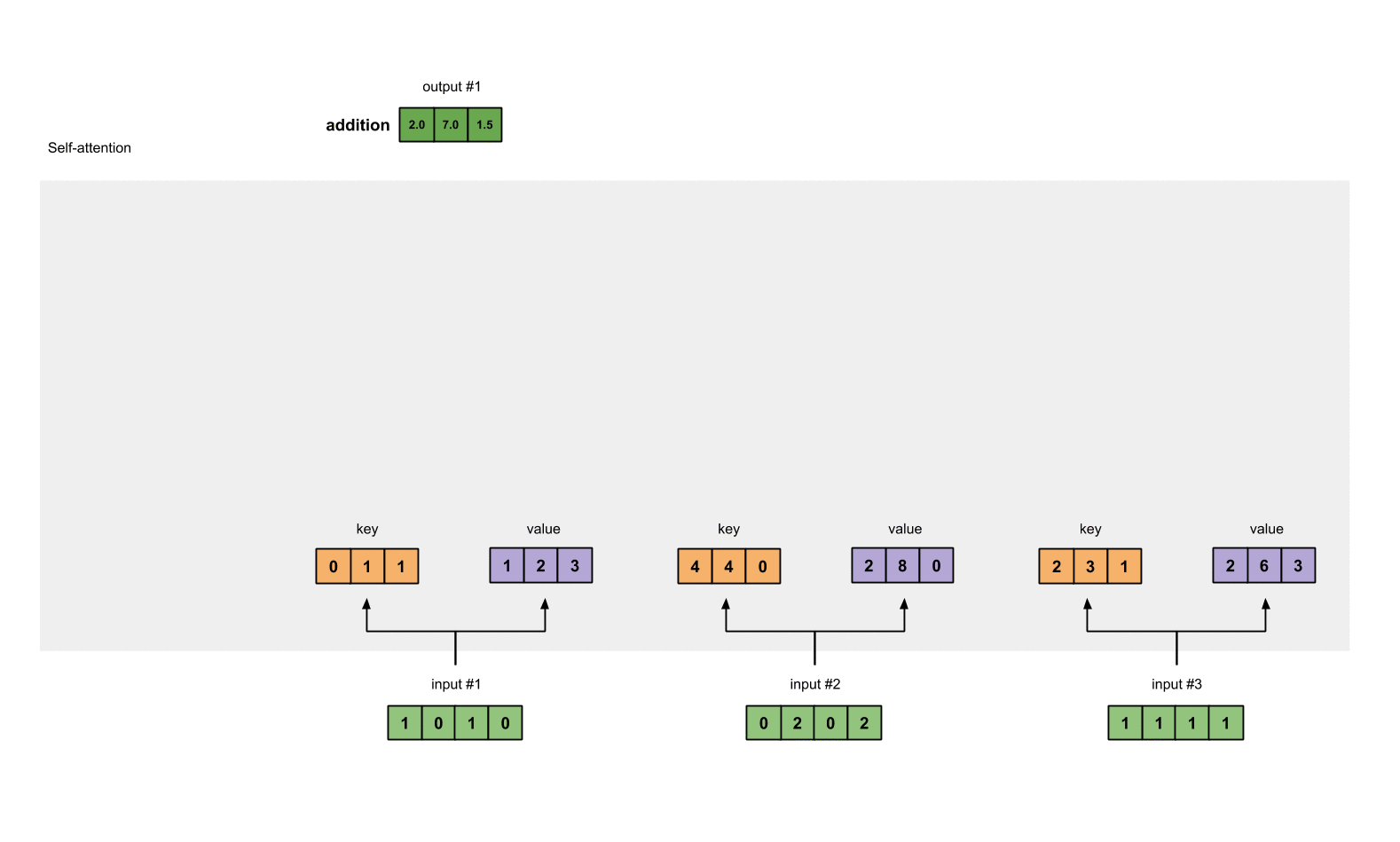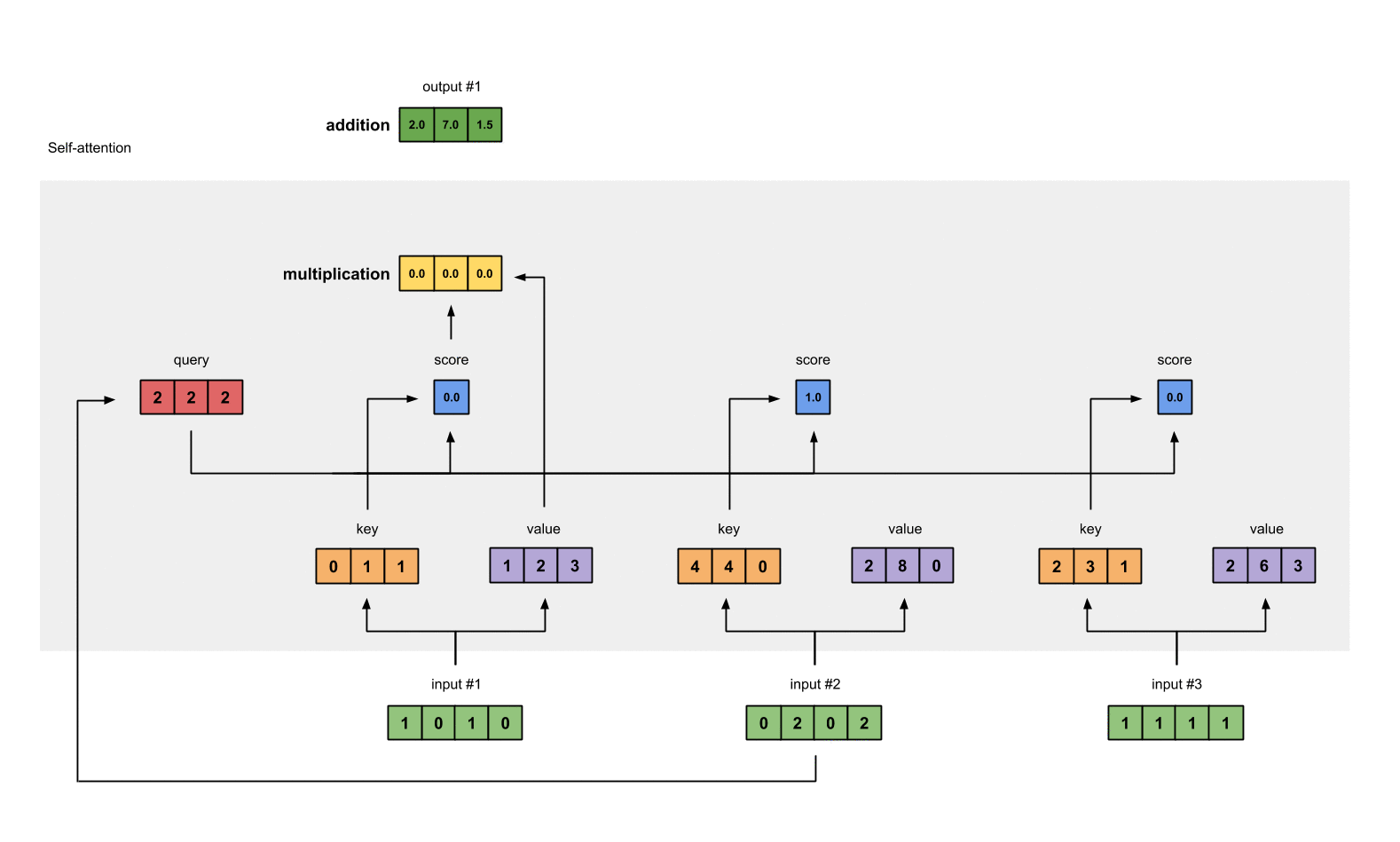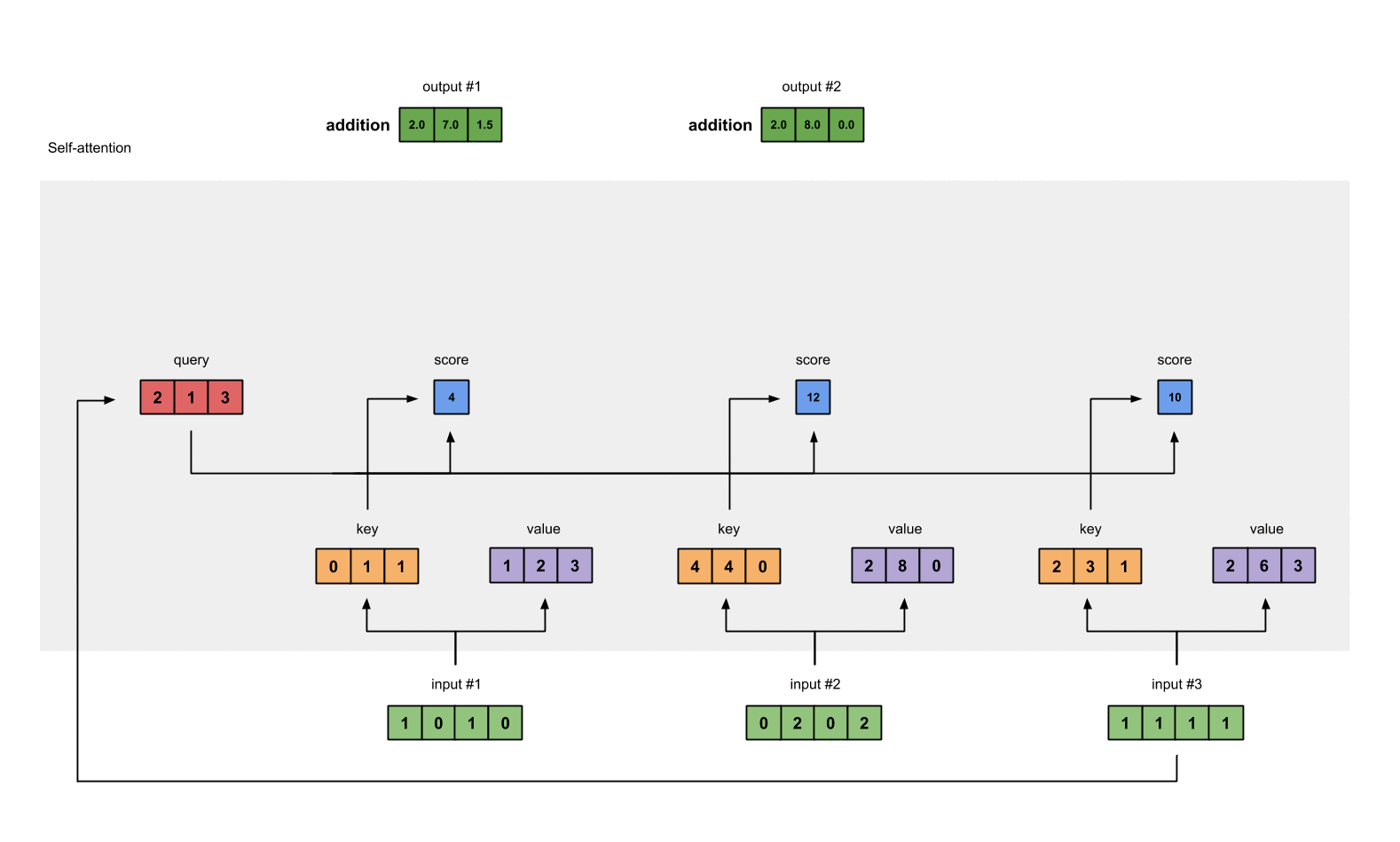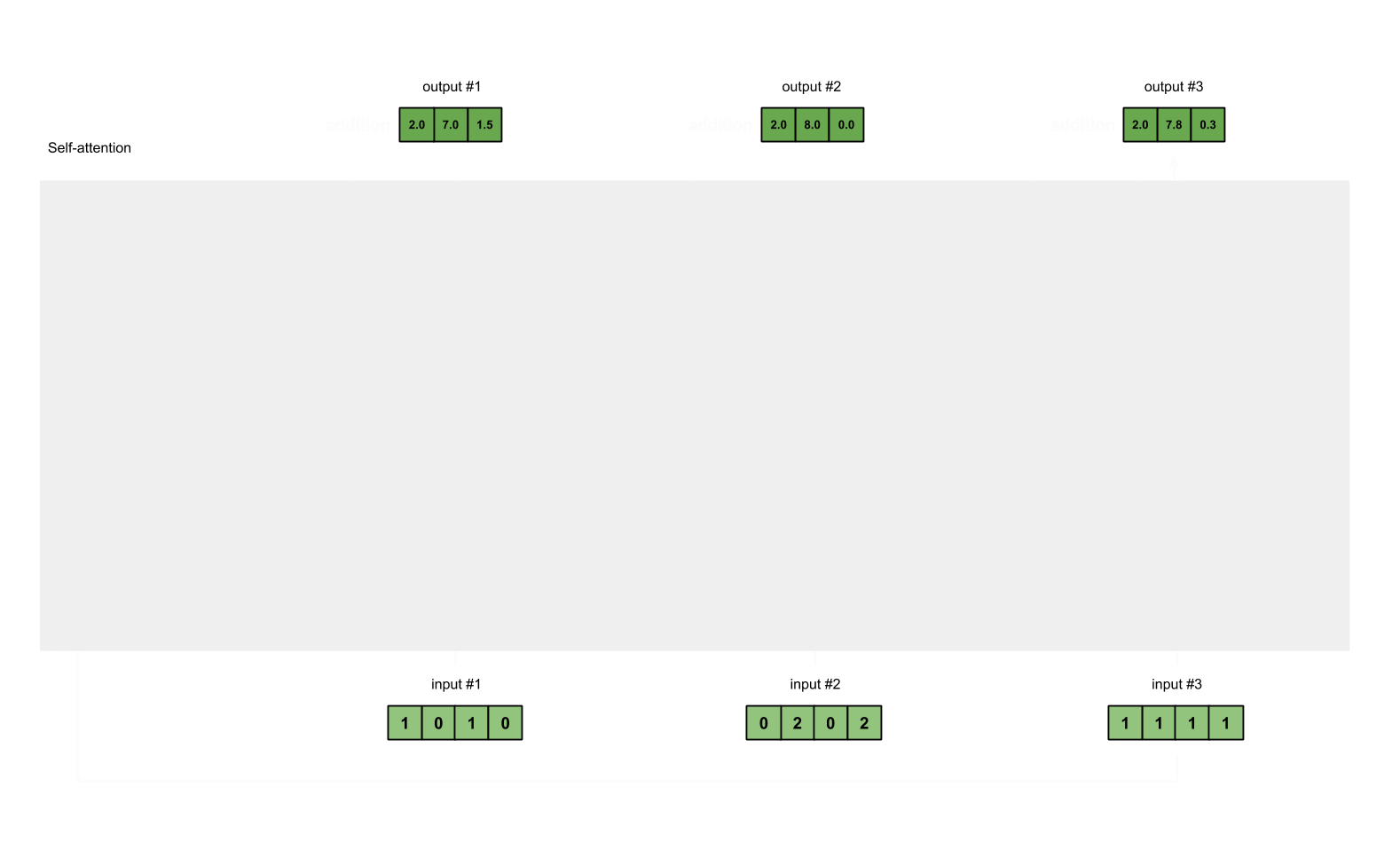
- 对于输入向量X,对其做线性变换,分别得到Q、K、V矩阵
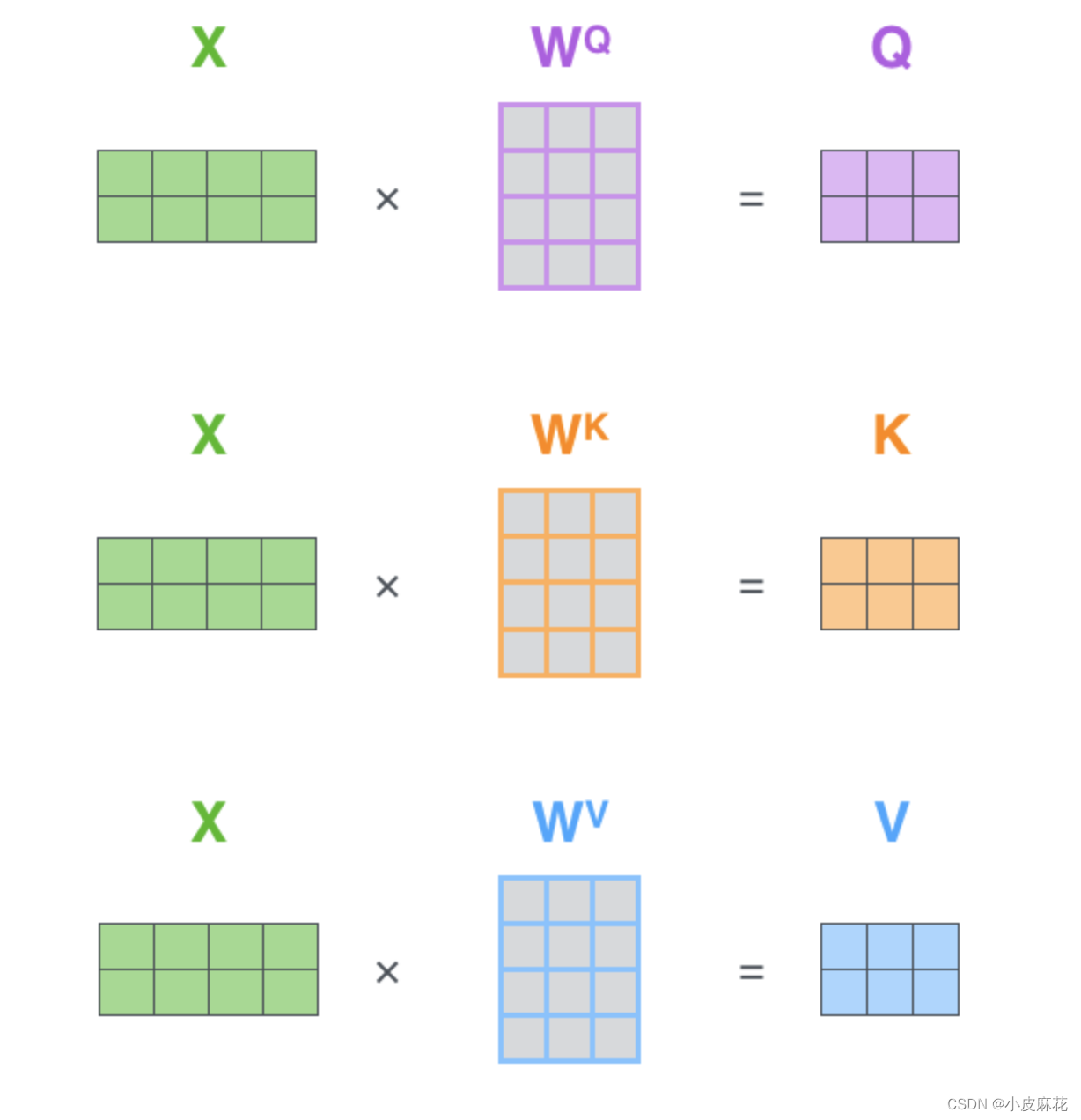
例如,对于输入向量X
Input 1: [1, 0, 1, 0]
Input 2: [0, 2, 0, 2]
Input 3: [1, 1, 1, 1]
对于初始化权重,分别是query的Wq,key的Wk以及value的Wv,这三个权重分别初始化为
Wk矩阵为:
[[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]]
Wq矩阵为:
[[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]]
Wv矩阵为:
[[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]]
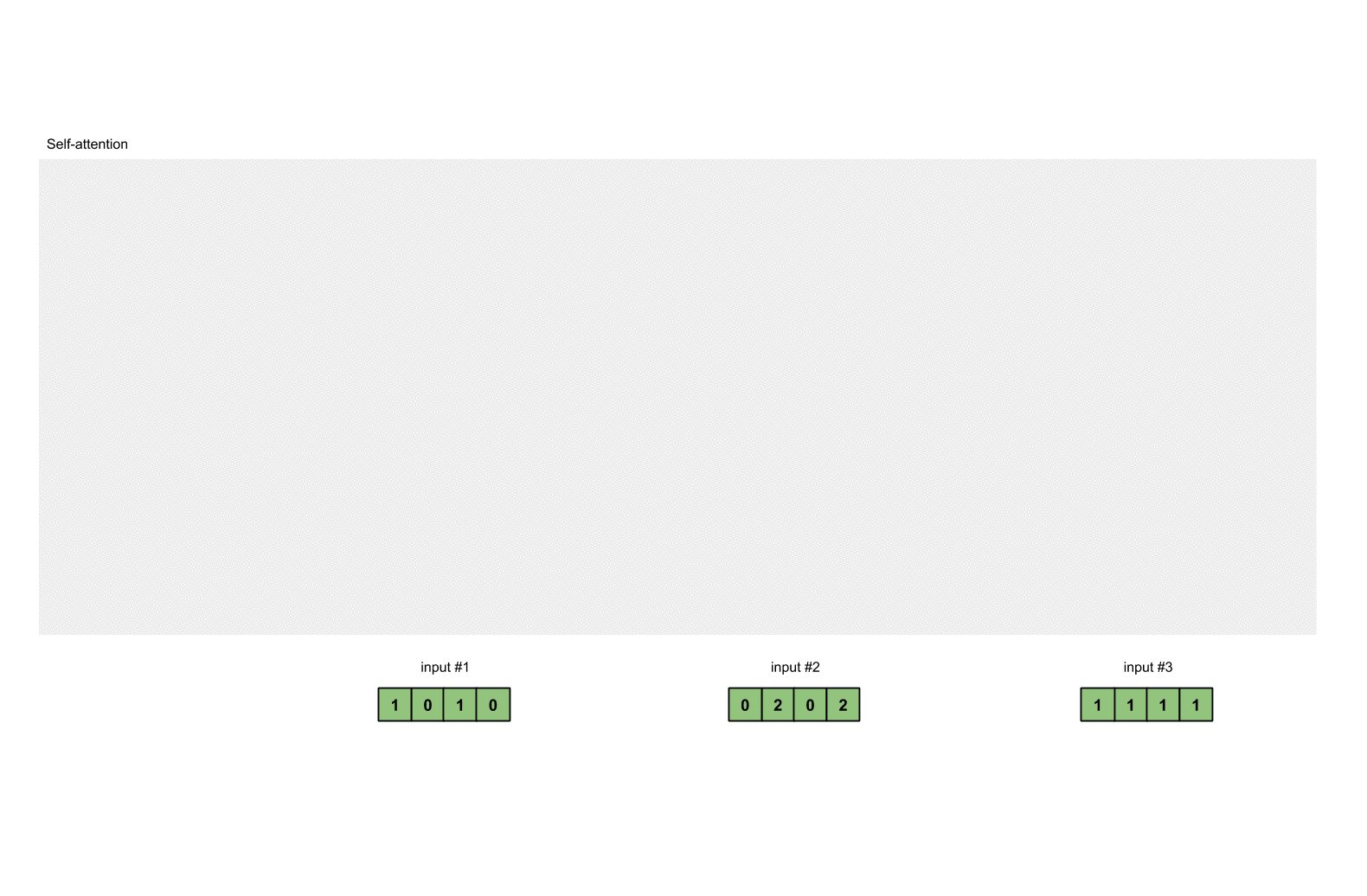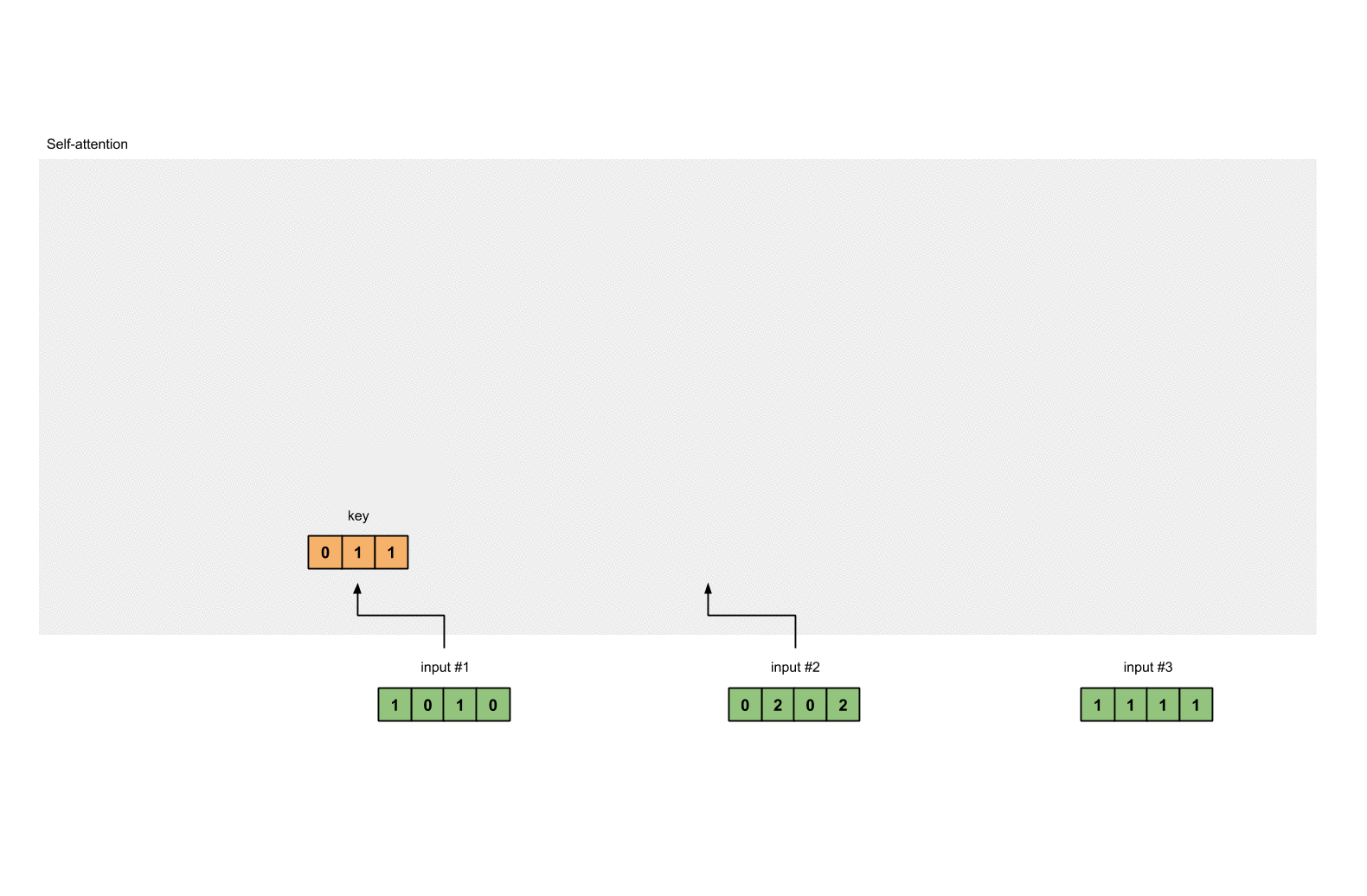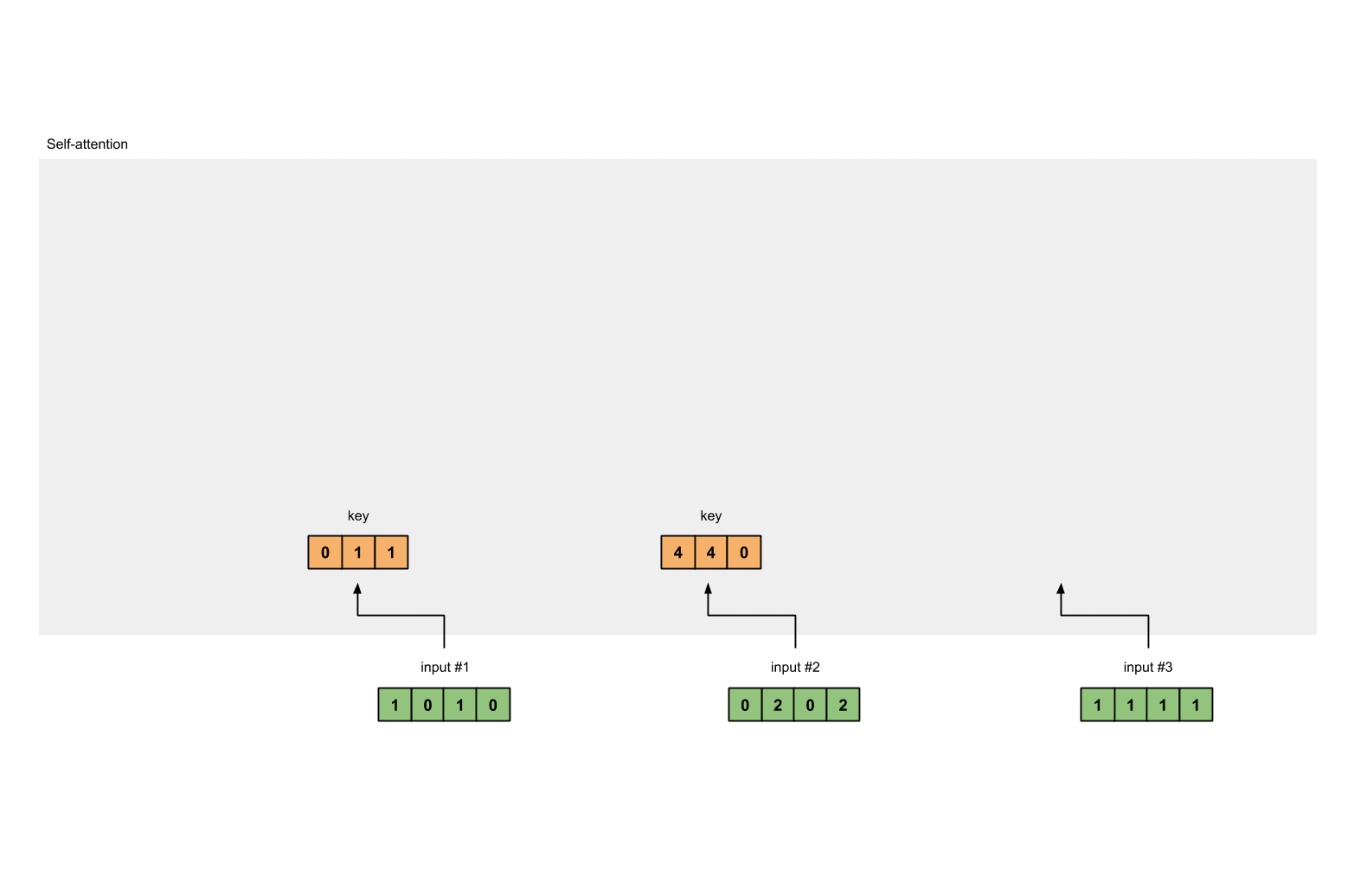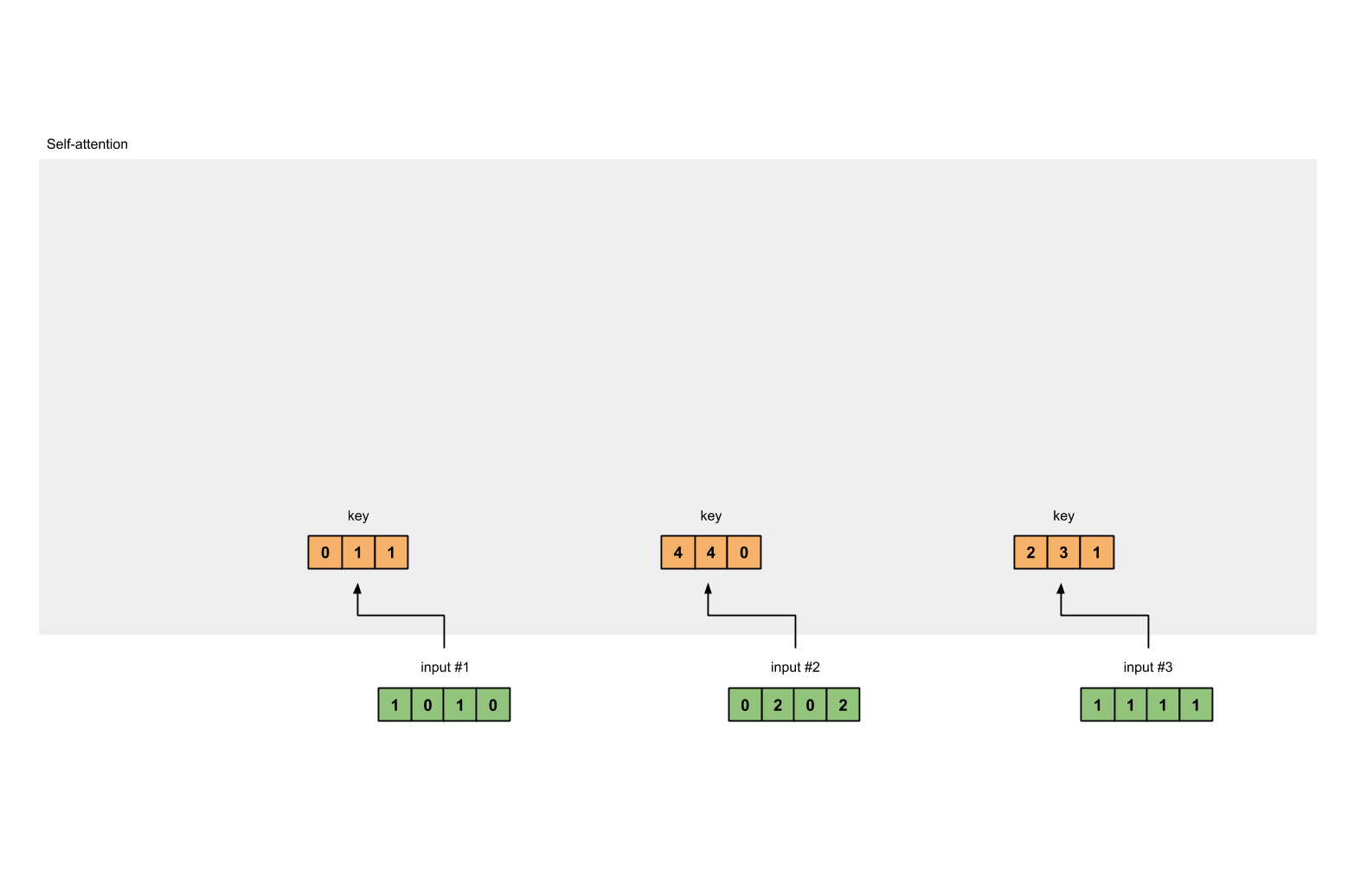
用矩阵的乘法来计算输入的Key为:
[0, 0, 1]
[1, 0, 1, 0] [1, 1, 0] [0, 1, 1]
[0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 3, 1]
同理我们计算value的结果为:
[0, 2, 0]
[1, 0, 1, 0] [0, 3, 0] [1, 2, 3]
[0, 2, 0, 2] x [1, 0, 3] = [2, 8, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 6, 3]
最后我们计算query的结果:
[1, 0, 1]
[1, 0, 1, 0] [1, 0, 0] [1, 0, 2]
[0, 2, 0, 2] x [0, 0, 1] = [2, 2, 2]
[1, 1, 1, 1] [0, 1, 1] [2, 1, 3]
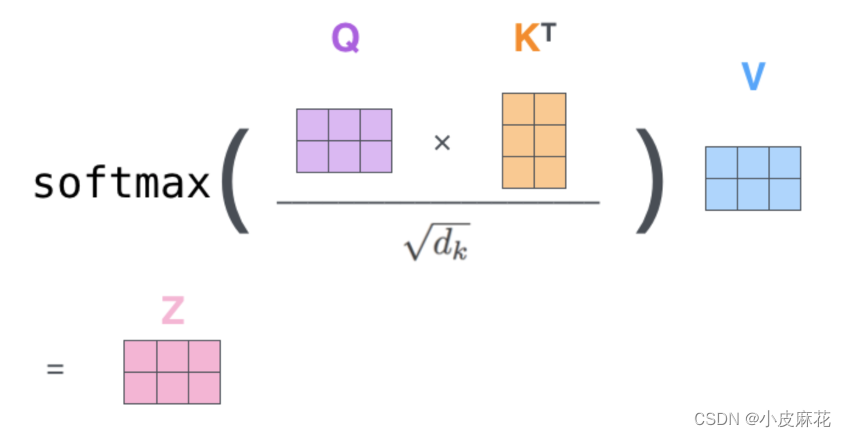
- 然后计算输入值的注意力得分,注意力的得分是通过Q、K点乘得到初步的权重因子,并对Q、K点乘结果进行放缩,除以sqrt(dk)。Q、K点乘之后的方差会随着维度的增大而增大,而大的方差会导致极小的梯度,为了防止梯度消失,所以除以sqrt(dk)来减小方差
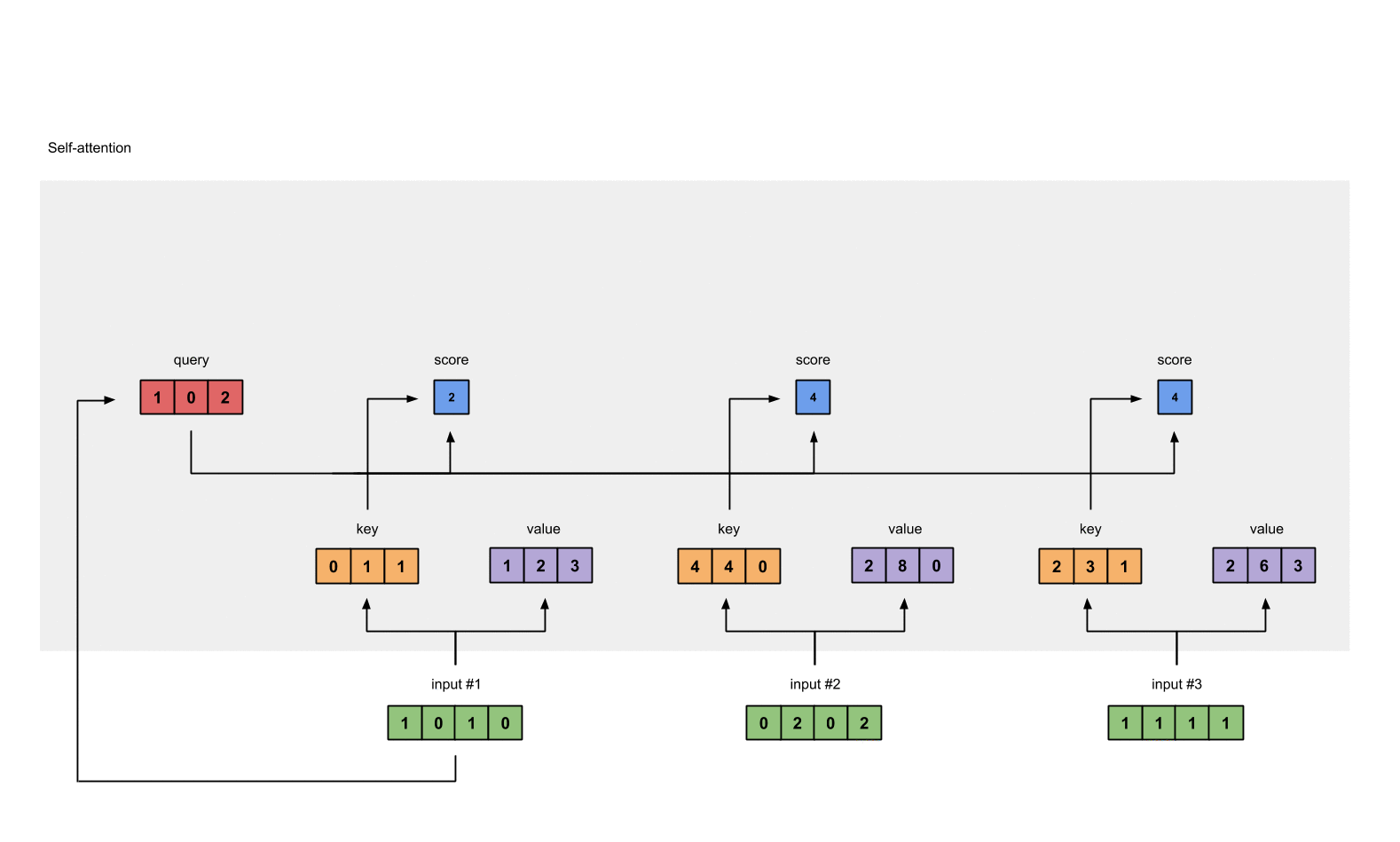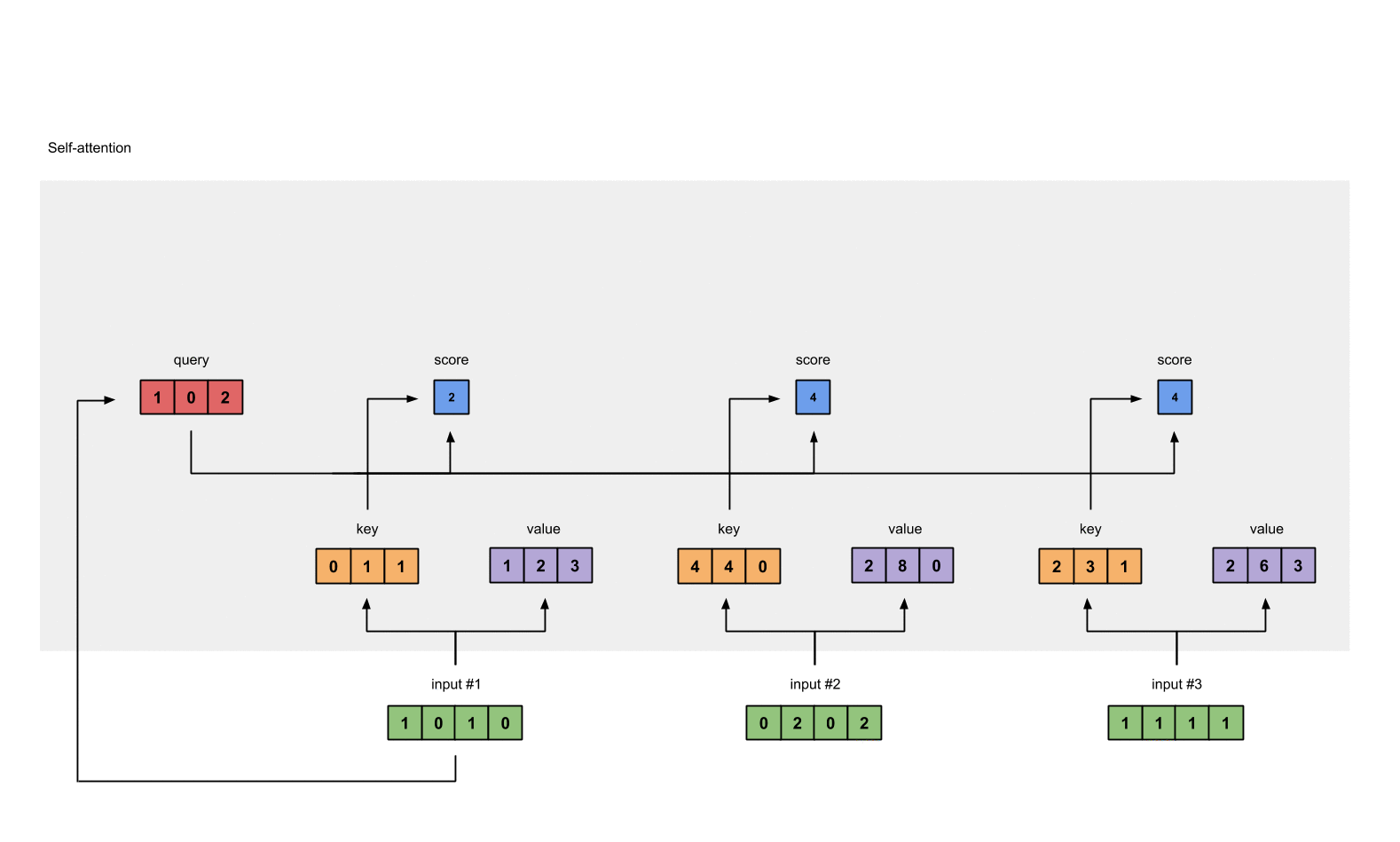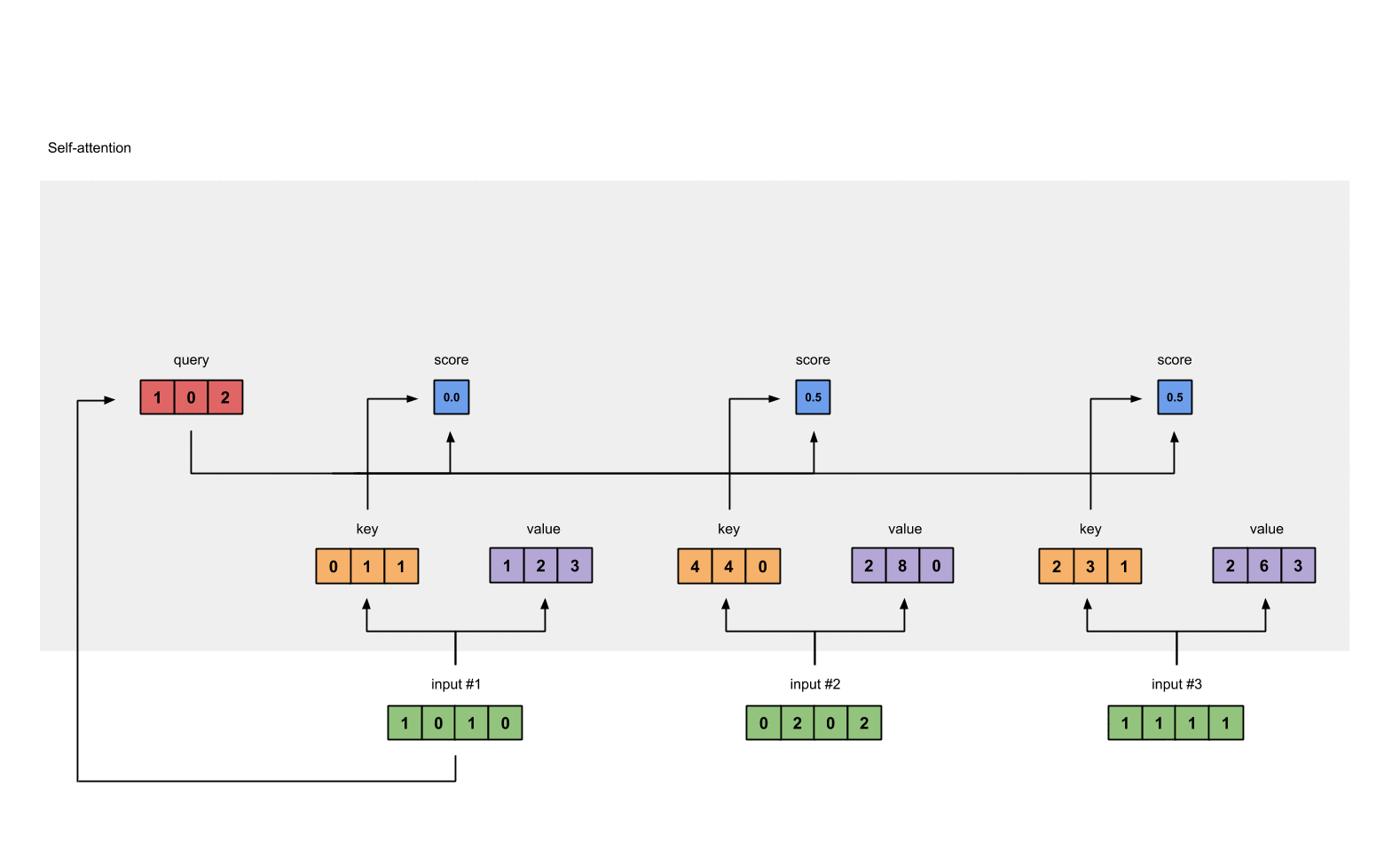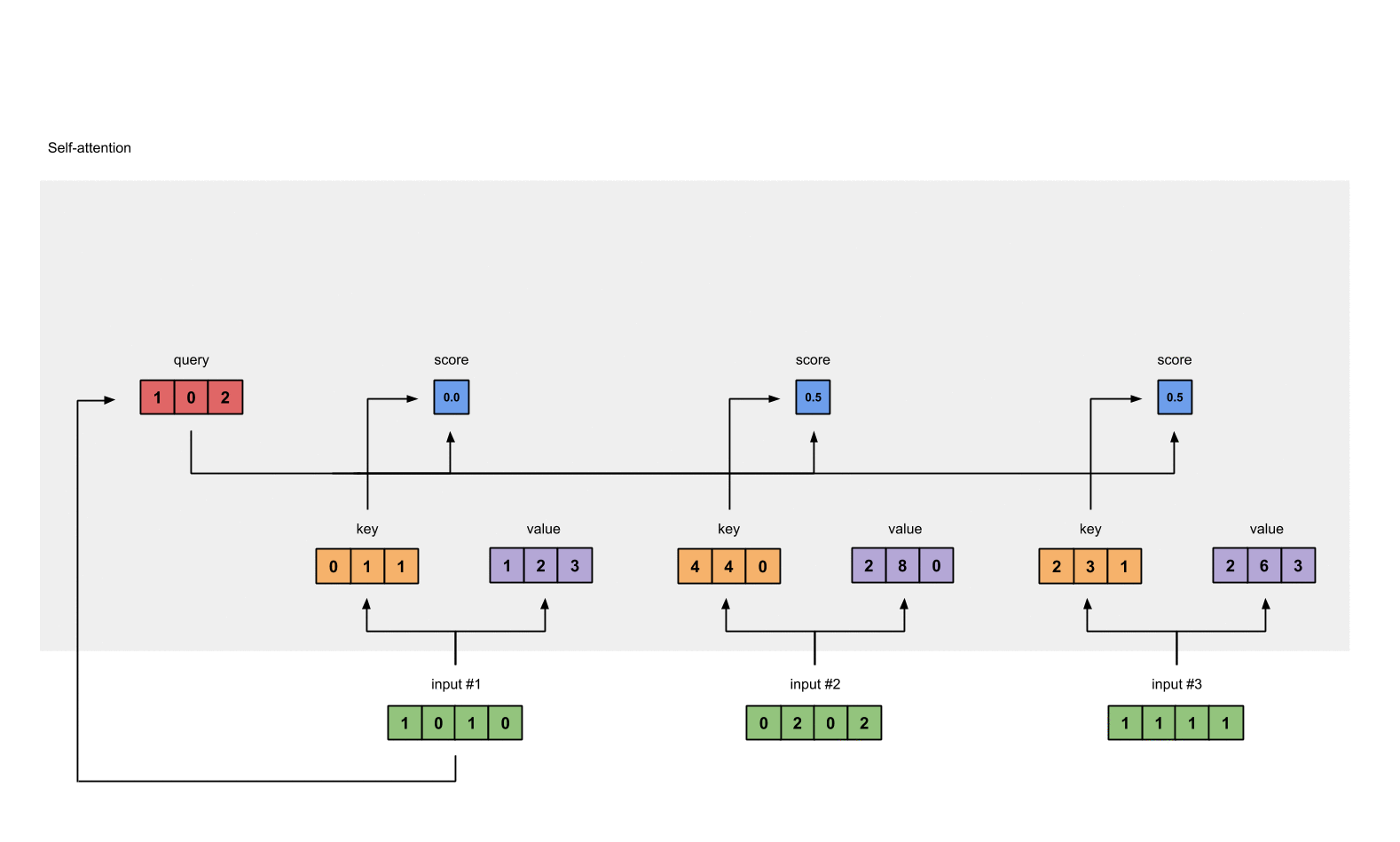
例如对于第一个query(红色)分别与三个key(橙色)相乘,得到结果(蓝色)就是注意力得分
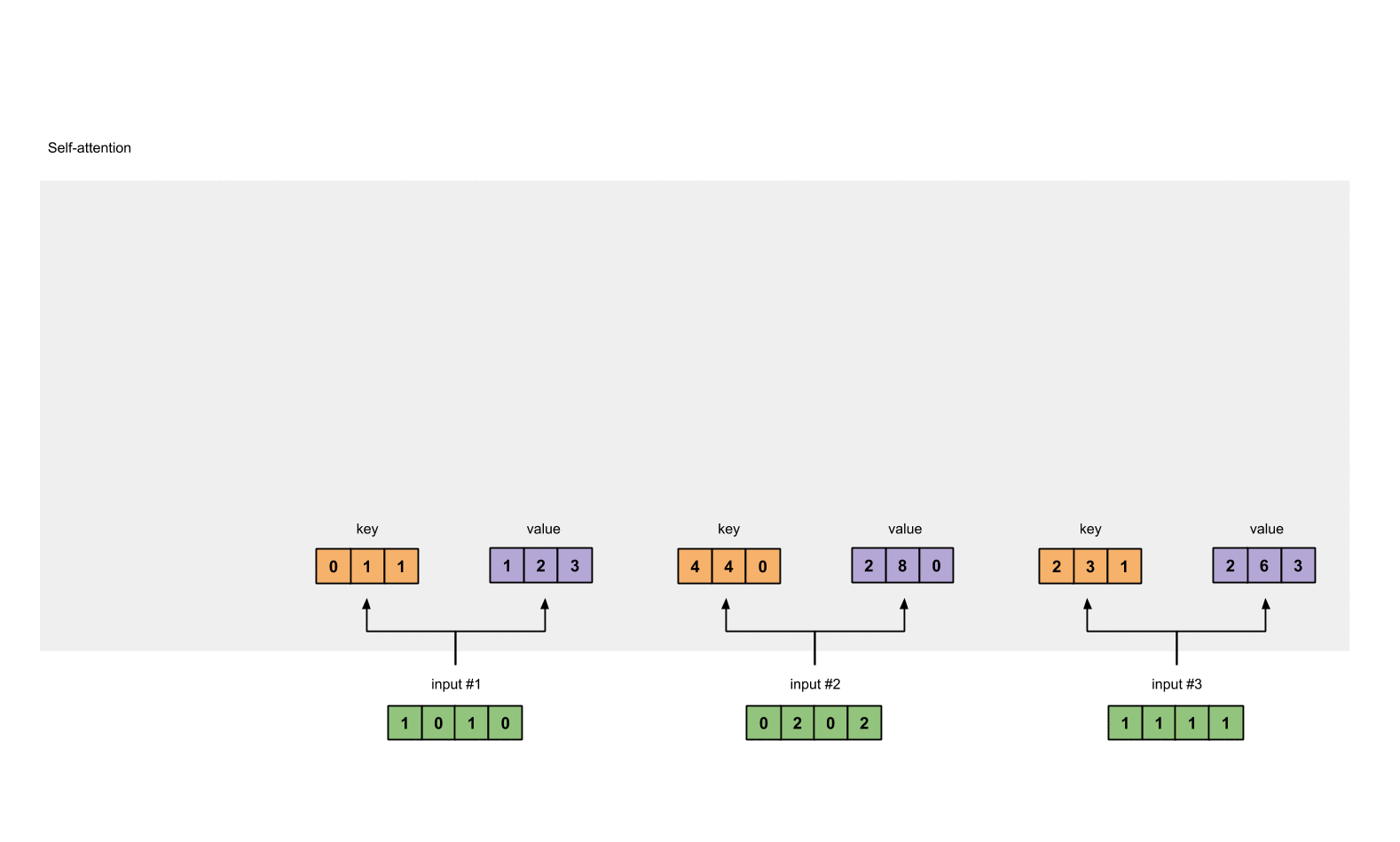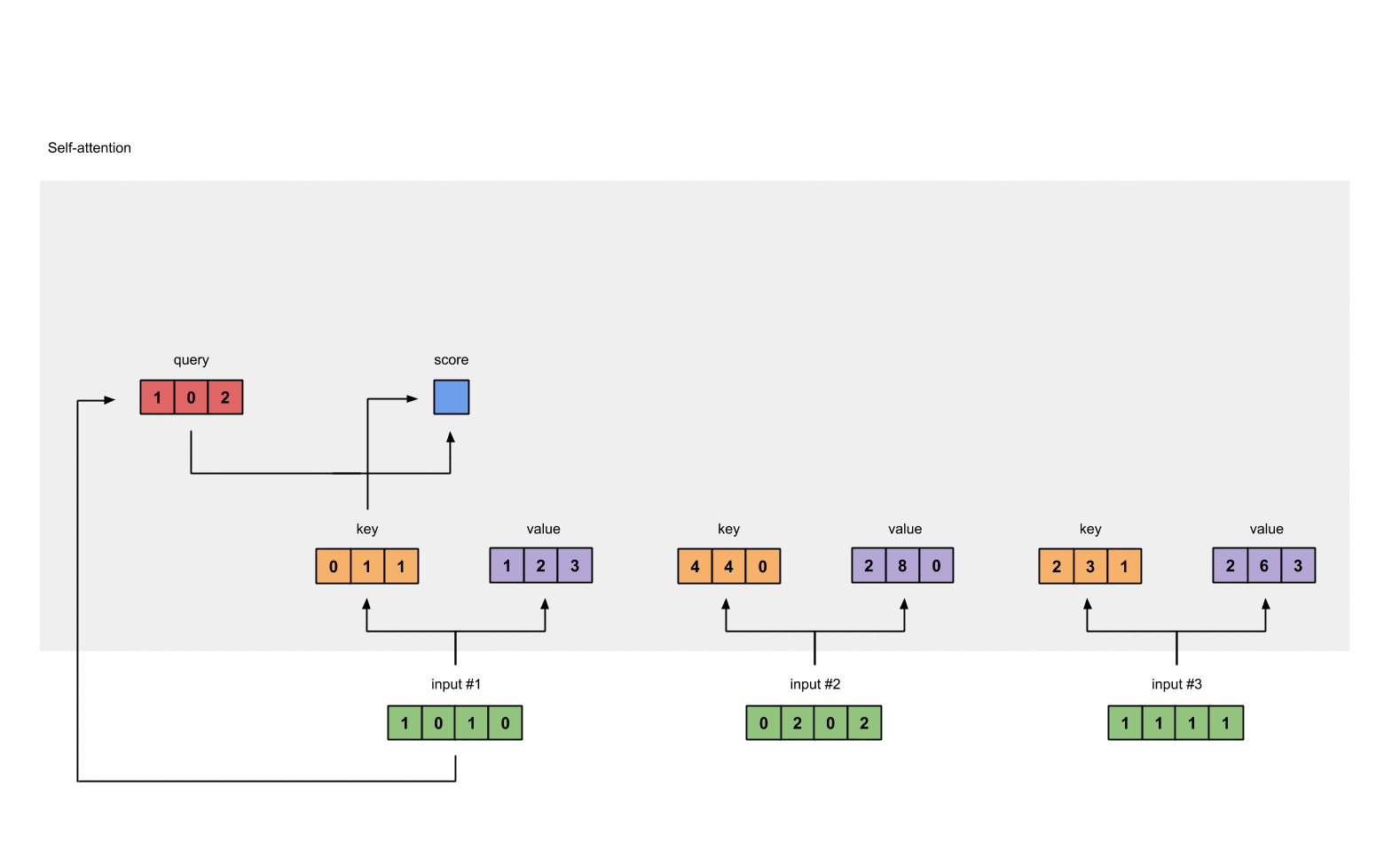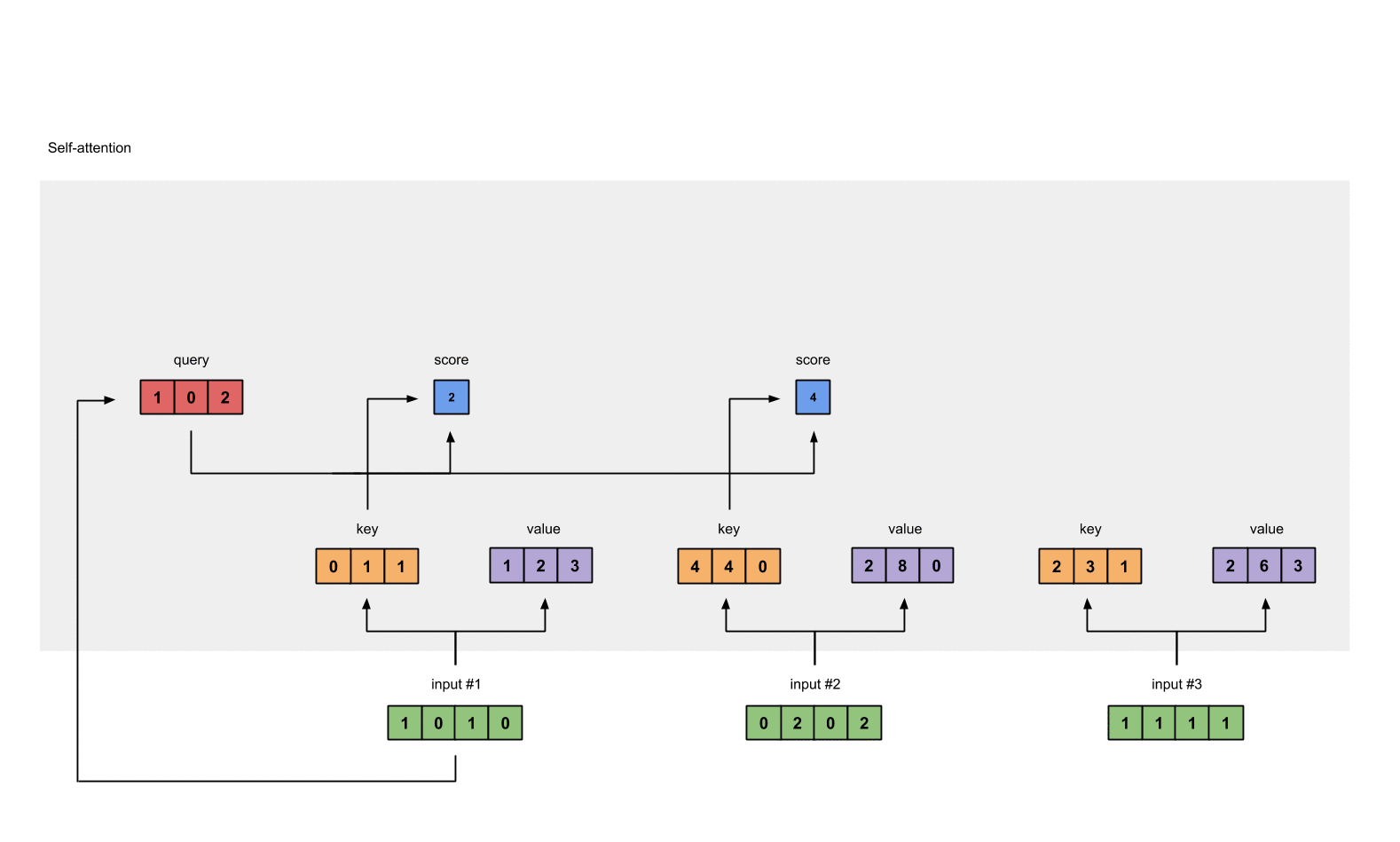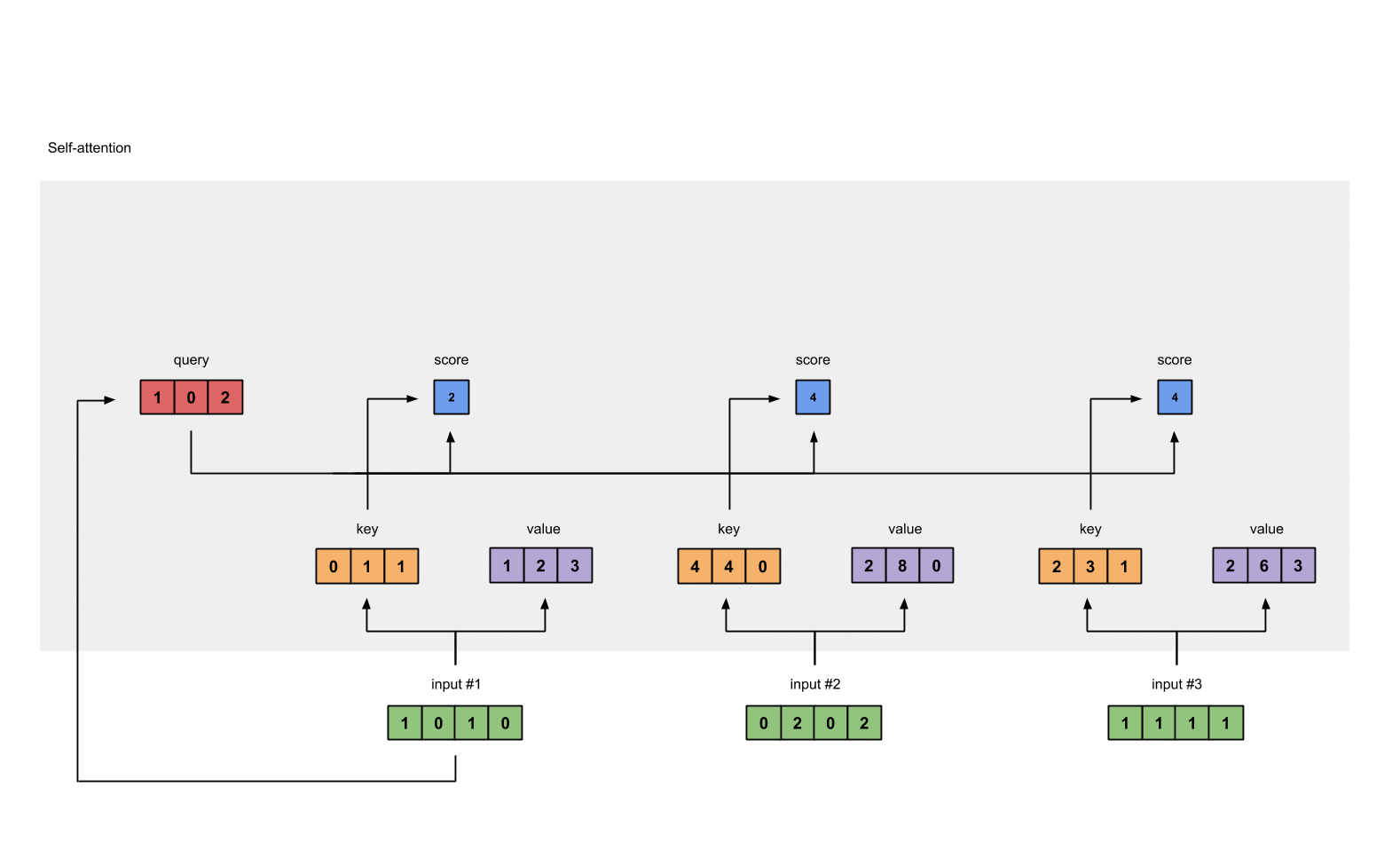
计算结果为:
[0, 4, 2]
[1, 0, 2] x [1, 4, 3] = [2, 4, 4]
[1, 0, 1]
- 加一个softmax对上一步中的注意力得分做归一化处理,得到self attention的输出
softmax([2, 4, 4]) = [0.0, 0.5, 0.5]
- 得分与value相乘:得到每个得分值与自身的value直接相乘
1: 0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]
2: 0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]
3: 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
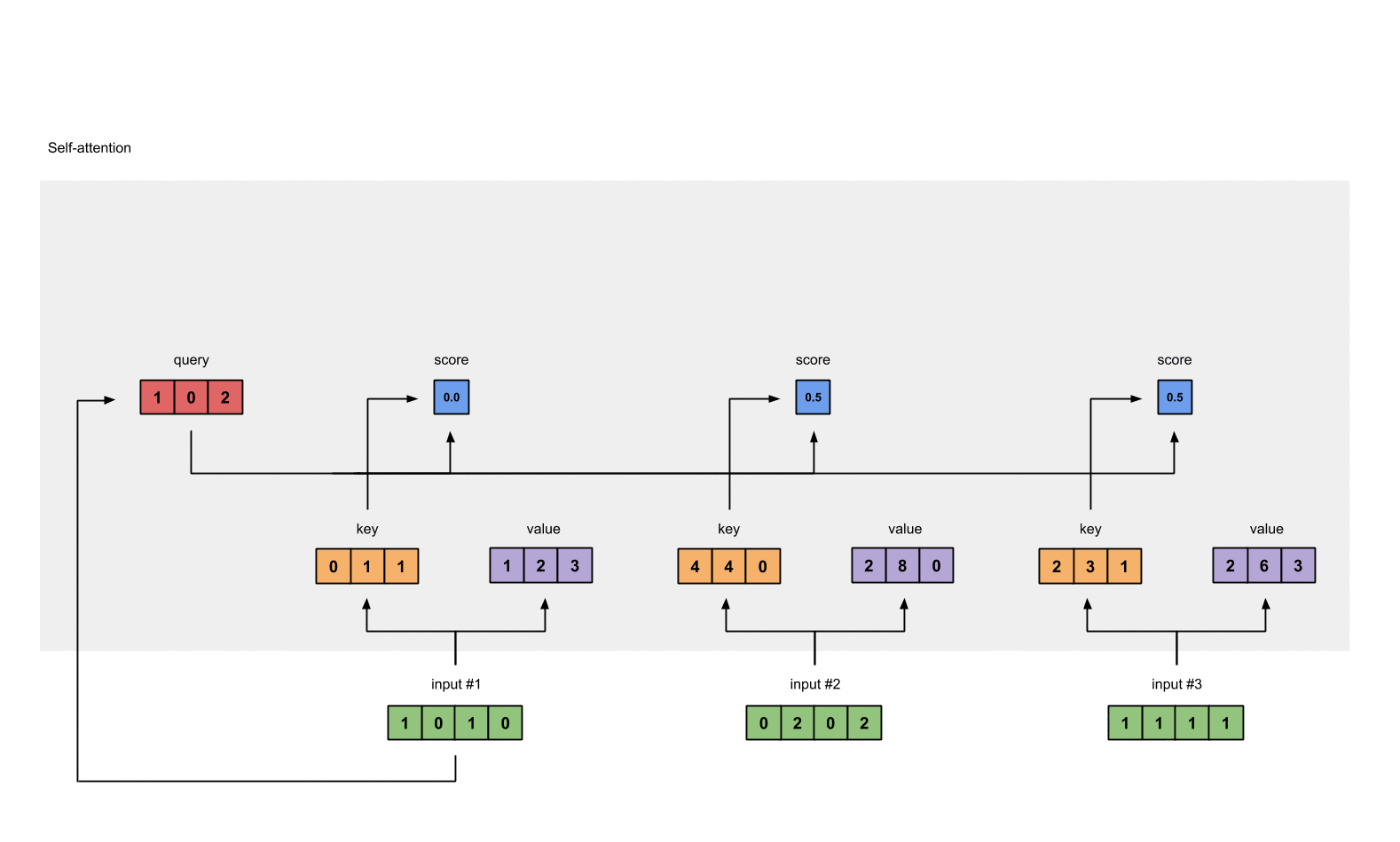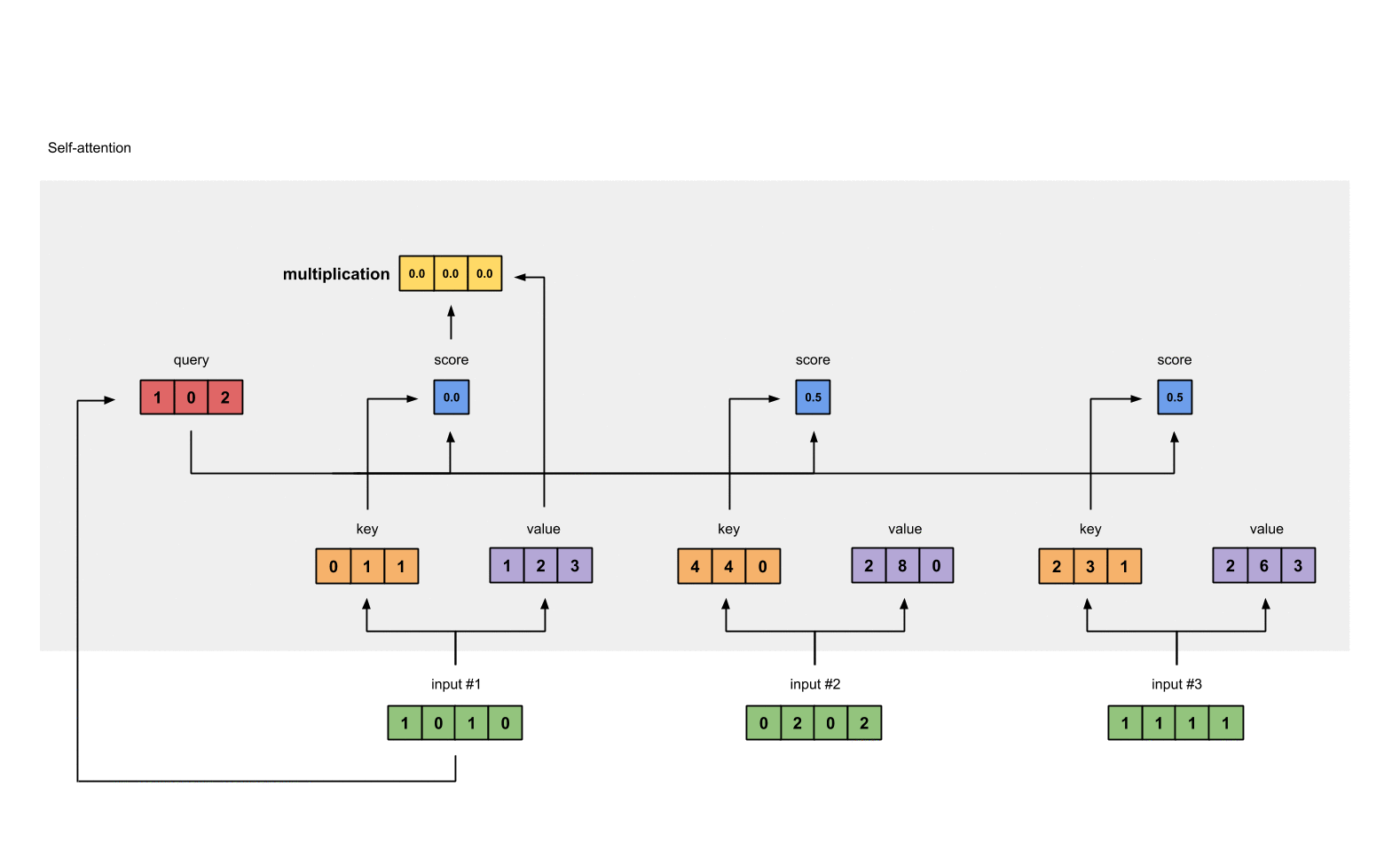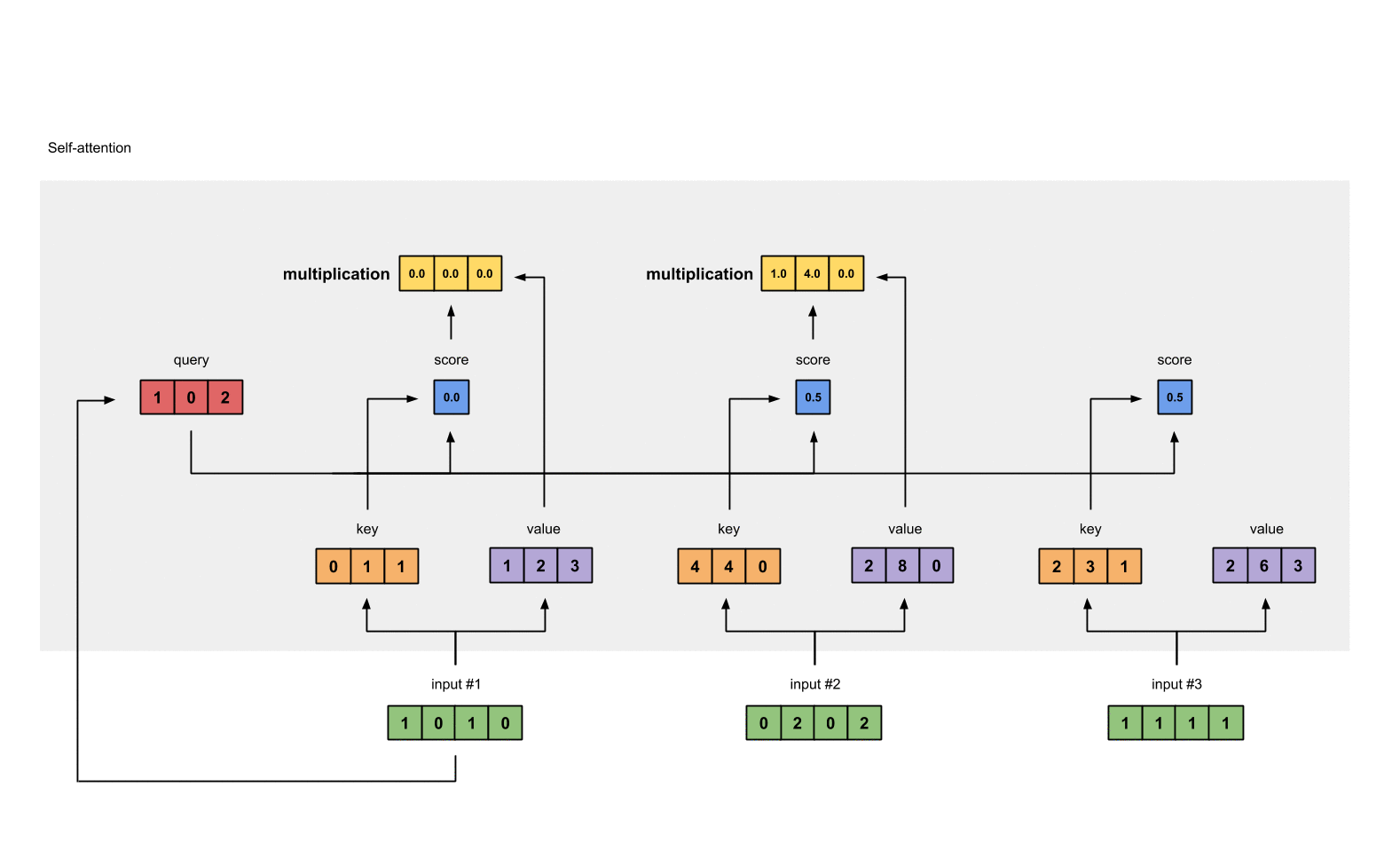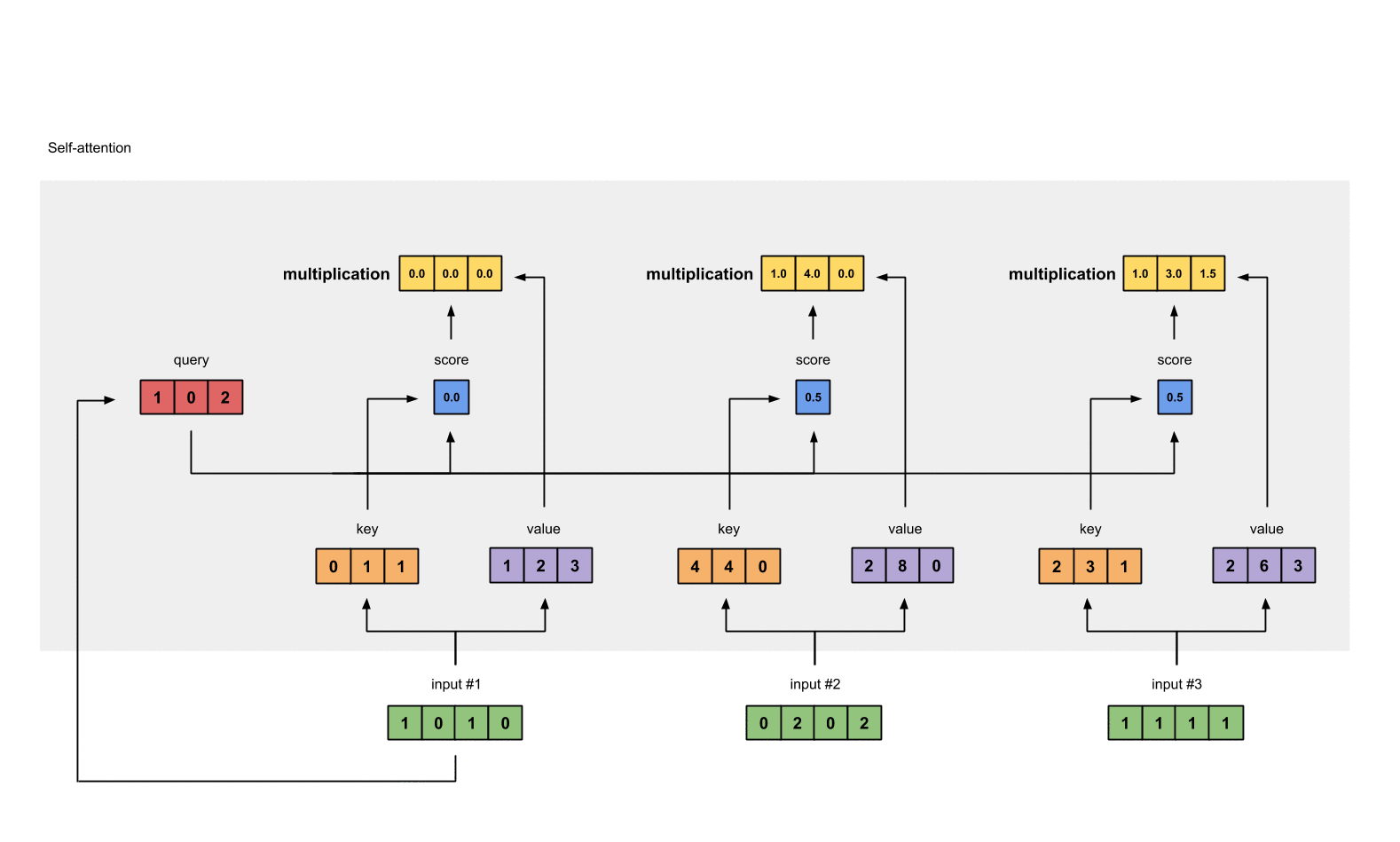
- 对结果求和,并得到第一个输出值
[0.0, 0.0, 0.0]
- [1.0, 4.0, 0.0]
- [1.0, 3.0, 1.5]
= [2.0, 7.0, 1.5]
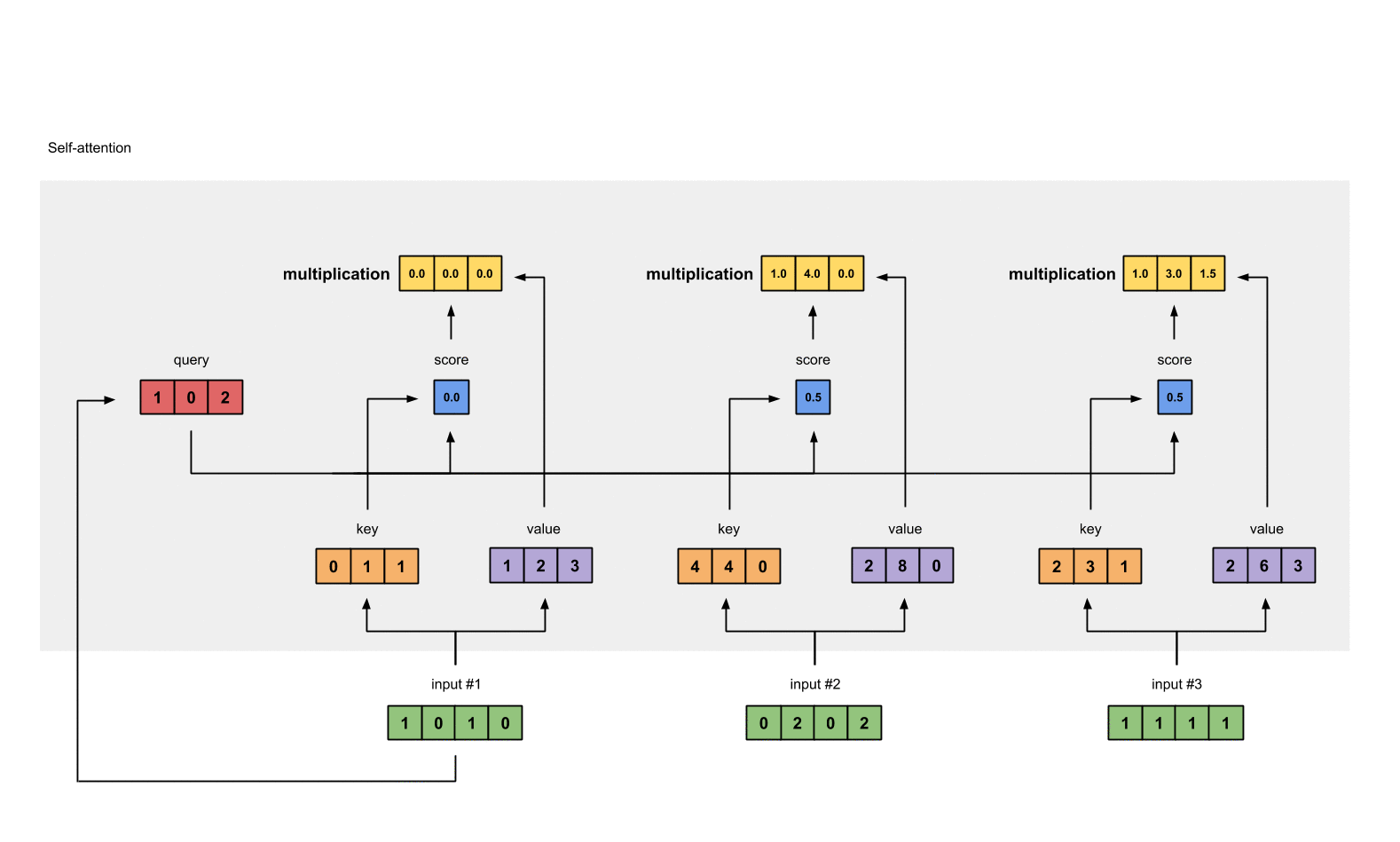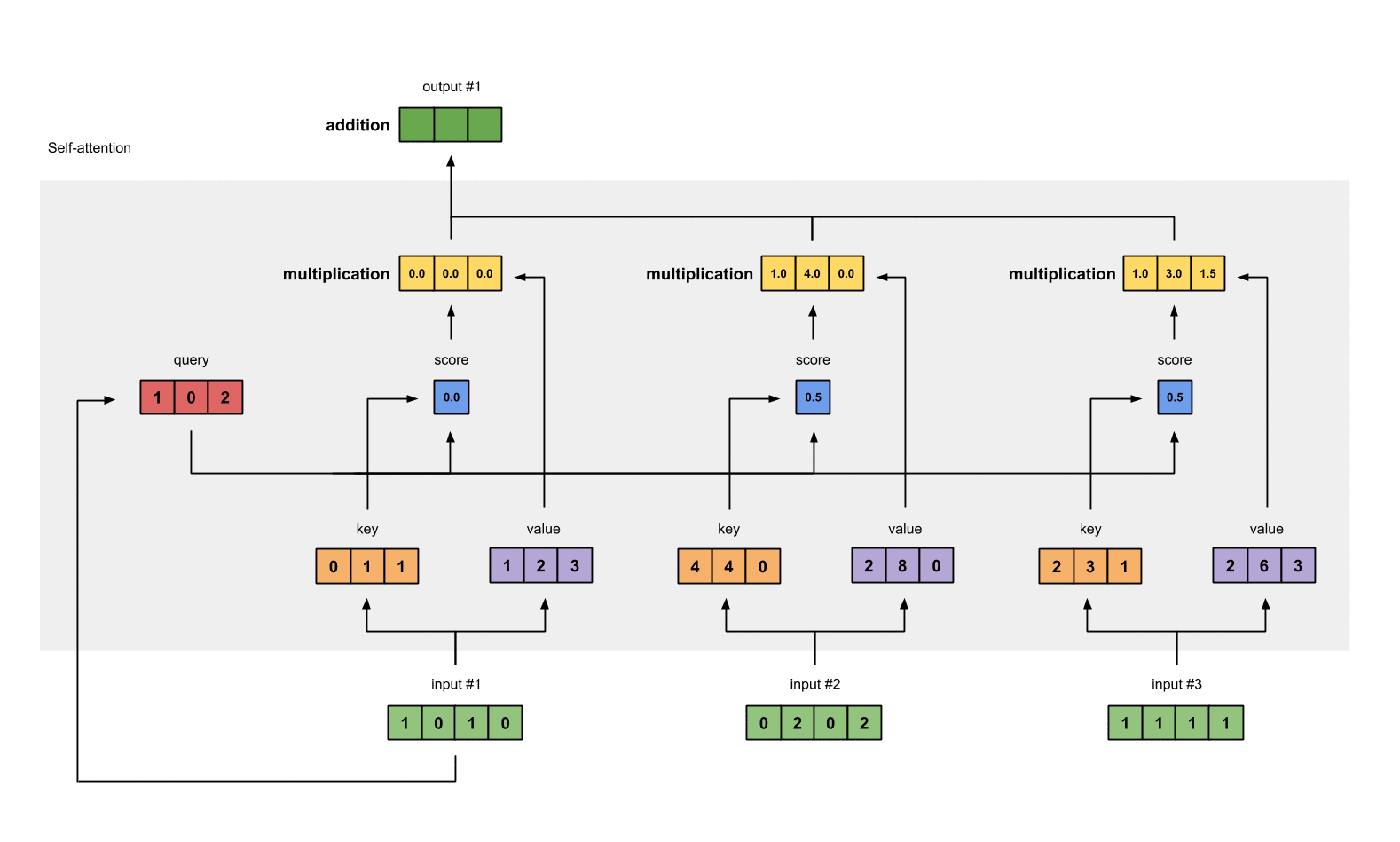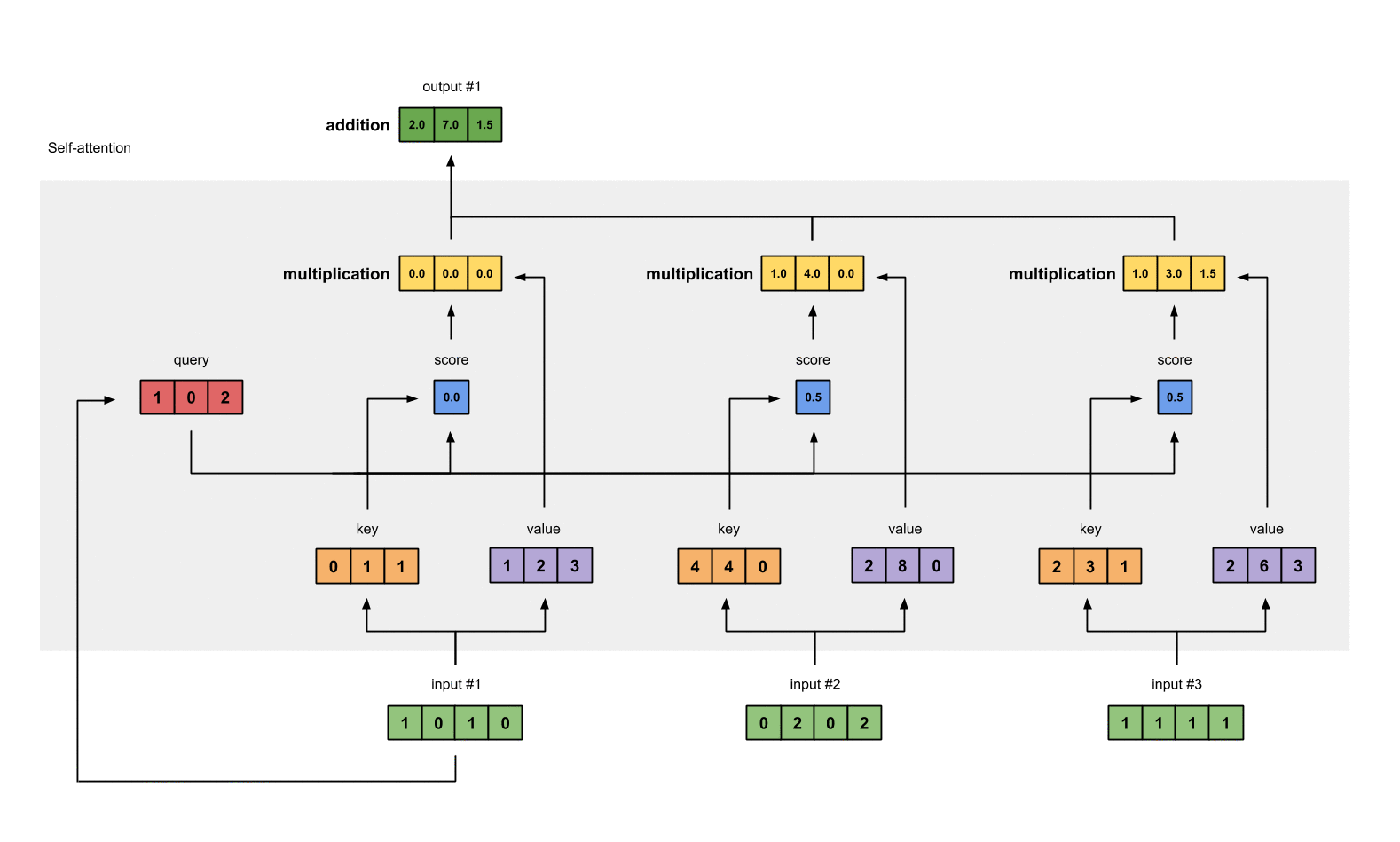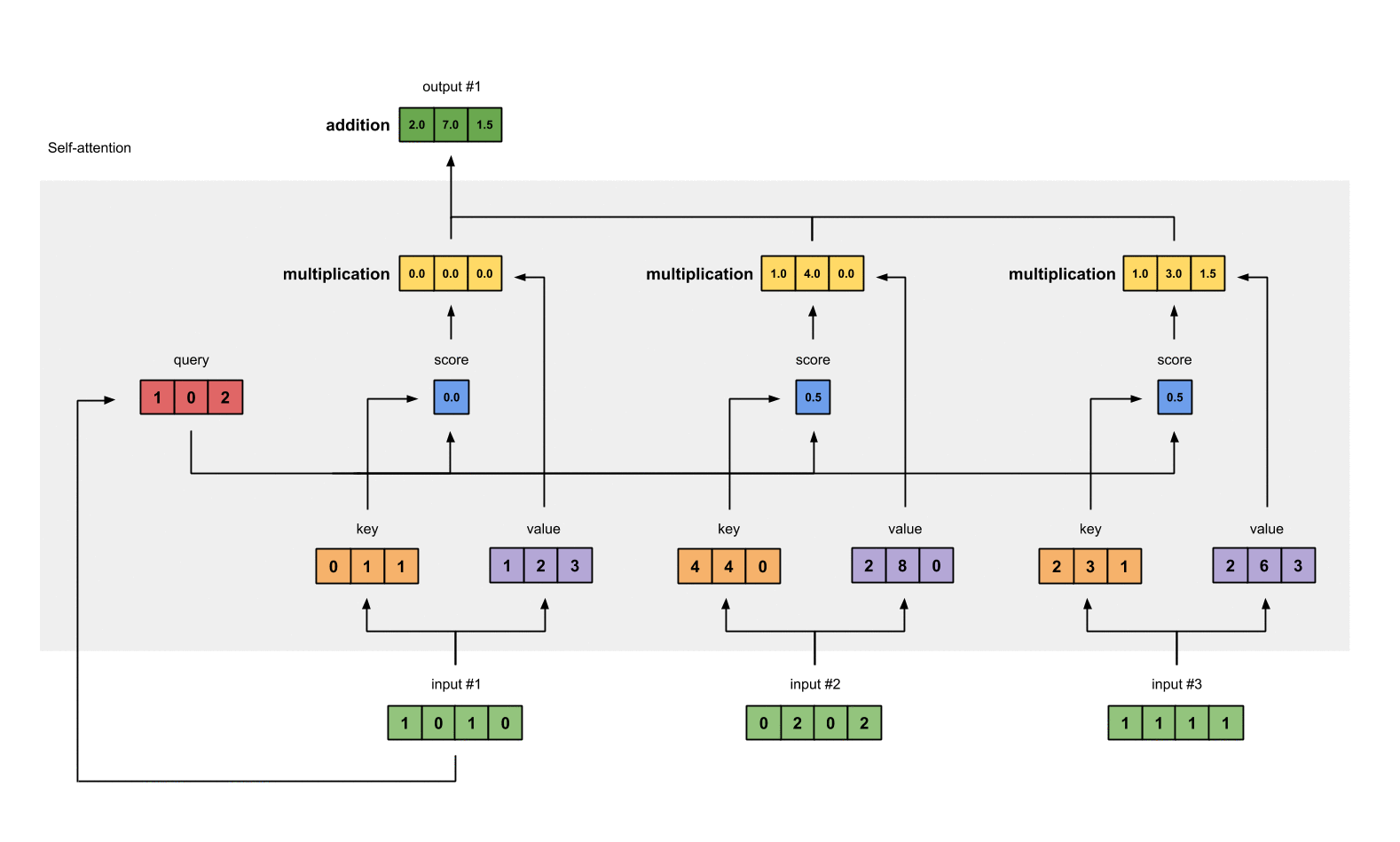
- 重复计算,分别得到第二个和第三个输出值
Multi–head-attention
Multi–head-attention使用了多个头进行运算,它通过并行地运行多个独立的注意力机制来获取输入序列的不同子空间的注意力分布,从而更全面地捕获序列中潜在的多种语义关联。多头的数量用h表示,一般h=8,表示8个头

如何将输入序列通过不同的注意力头(heads)进行处理。具体来说,这个过程包括以下几个步骤:
-
输入序列的处理:输入序列 (ai) 首先通过三个不同的权重矩阵 (Wq,Wk,Wv) 进行映射,得到对应的 (qi,ki,vi)。。
-
多头注意力的分割:接着,根据使用的头的数目 (h),将得到的 (qi,ki,vi) 均分成 (h) 份。这意味着每个头将处理输入序列的一部分,而不是整个序列。
-
示例说明:以 (h=2) 为例,如果输入序列 (q1) 被映射后,它将被分割成两部分 (q1,1) 和 (q1,2)。其中,(q1,1) 属于第一个头(head1),而 (q1,2) 属于第二个头(head2)。同样的分割也适用于 (k1)和(v1)。
-
多头并行处理:每个头将独立地计算其对应的Self-Attention,然后将所有头的输出结果合并起来,以获得最终的Multi-Head Attention输出。

论文中提到的是通过 ( W^Q_i ), ( W^K_i ), ( W^V_i ) 映射得到每个头的 ( Q_i ), ( K_i ), ( V_i ):
[ \text{head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i) ]
但在GitHub上的一些源码中,一些代码是直接对输入进行简单的均分(例如分块)。其实,这也可以通过选择特定的 ( W^Q_i ), ( W^K_i ), ( W^V_i ) 来实现均分的效果。例如,某些实现中 ( Q ) 通过特定的 ( W^Q_1 ) 映射,就能得到均分后的 ( Q_1 )。
- 将每个head得到的结果进行concat拼接。例如,head1 得到的b_1,1_和 head2 得到的b_1,2_拼接在一起。

- 拼接后的结果通过可学习的参数WO进行线性变换,得到最终的输出结果

ADD&Norm层
在Encoder层和Decoder层中都用到了Add&Norm操作,即残差连接和层归一化操作。
ADD层:即为残差连接
就是把网络的输入和输出相加,即网络的输出为F(x)+x,在网络结构比较深的时候,网络梯度反向传播更新参数时,容易造成梯度消失的问题,但是如果每层的输出都加上一个x的时候,就变成了F(x)+x,对x求导结果为1,所以就相当于每一层求导时都加上了一个常数项‘1’,有效解决了梯度消失问题。
Norm操作
假设我们输入的词向量的形状是(2,3,4),2为批次(batch),3为句子长度,4为词向量的维度,生成以下数据:
[[w11, w12, w13, w14], [w21, w22, w23, w24], [w31, w32, w33, w34]
[w41, w42, w43, w44], [w51, w52, w53, w54], [w61, w62, w63, w64]]
如果是在做BatchNorm(BN)的话,其计算过程如下:BN1=(w11+w12+w13+w14+w41+w42+w43+w44)/8,同理会得到BN2和BN3,最终得到[BN1,BN2,BN3] 3个mean
如果是在做LayerNorm(LN)的话,则会进如下计算:LN1=(w11+w12+w13+w14+w21+w22+w23+w24+w31+w32+w33+w34)/12,同理会得到LN2,最终得到[LN1,LN2]两个mean
如果是在做InstanceNorm(IN)的话,则会进如下计算:IN1=(w11+w12+w13+w14)/4,同理会得到IN2,IN3,IN4,IN5,IN6,六个mean,[[IN1,IN2,IN3],[IN4,IN5,IN6]]

- LayerNorm 示例
步骤:
- 生成数据:首先生成形状为 [2, 3, 4] 的随机数据,表示一个 batch 中有 2 个序列,每个序列长度为 3,每个元素的维度为 4。
- 定义 LayerNorm:使用 PyTorch 中的
LayerNorm模块,指定要对最后一个维度(dim=4)进行归一化,设置elementwise_affine=False表示不使用可学习的参数。 - 应用 LayerNorm:将生成的数据传入
LayerNorm模块进行归一化。
import torch
from torch.nn import LayerNorm
random_seed = 123
torch.manual_seed(random_seed)
batch_size, seq_size, dim = 2, 3, 4
embedding = torch.randn(batch_size, seq_size, dim)
layer_norm = torch.nn.LayerNorm(dim, elementwise_affine=False)
print("y: ", layer_norm(embedding))
输出:
y: tensor([[[ 1.5524, 0.0155, -0.3596, -1.2083],
[ 0.5851, 1.3263, -0.7660, -1.1453],
[ 0.2864, 0.0185, 1.2388, -1.5437]],
[[ 1.1119, -0.3988, 0.7275, -1.4406],
[-0.4144, -1.1914, 0.0548, 1.5510],
[ 0.3914, -0.5591, 1.4105, -1.2428]]])
解释:
LayerNorm对最后一个维度进行归一化,使每个维度上的数据分布均值为0,方差为1。
- 手动计算 LayerNorm
步骤:
- 计算均值:对每个样本(最后一个维度)计算均值。
- 计算方差:计算每个样本的方差。
- 归一化:将每个样本减去均值,再除以标准差。
eps: float = 0.00001
mean = torch.mean(embedding[:, :, :], dim=(-1), keepdim=True)
var = torch.square(embedding[:, :, :] - mean).mean(dim=(-1), keepdim=True)
print("mean: ", mean.shape)
print("y_custom: ", (embedding[:, :, :] - mean) / torch.sqrt(var + eps))
输出:
mean: torch.Size([2, 3, 1])
y_custom: tensor([[[ 1.1505, 0.5212, -0.1262, -1.5455],
[-0.6586, -0.2132, -0.8173, 1.6890],
[ 0.6000, 1.2080, -0.3813, -1.4267]],
[[-0.0861, 1.0145, -1.5895, 0.6610],
[ 0.8724, 0.9047, -1.5371, -0.2400],
[ 0.1507, 0.5268, 0.9785, -1.6560]]])
解释:
- 通过手动计算均值和方差,得到的归一化结果与
LayerNorm模块的张量维度结果一致,会给我们[batch,sqe_length]形状的平均值,验证了 LayerNorm 的正确性。
- BatchNorm 示例
步骤:
- 定义 LayerNorm:这次对 [seq_size, dim] 进行归一化。
- 计算均值:对整个 batch 进行归一化,计算均值。
- 计算方差:计算整个 batch 的方差。
- 归一化:将每个样本减去均值,再除以标准差。
layer_norm = torch.nn.LayerNorm([seq_size, dim], elementwise_affine=False)
eps: float = 0.00001
mean = torch.mean(embedding[:, :, :], dim=(-2, -1), keepdim=True)
var = torch.square(embedding[:, :, :] - mean).mean(dim=(-2, -1), keepdim=True)
print("mean: ", mean.shape)
print("y_custom: ", (embedding[:, :, :] - mean) / torch.sqrt(var + eps))
输出:
mean: torch.Size([2, 1, 1])
y_custom: tensor([[[ 1.1822, 0.4419, -0.3196, -1.9889],
[-0.6677, -0.2537, -0.8151, 1.5143],
[ 0.7174, 1.2147, -0.0852, -0.9403]],
[[-0.0138, 1.5666, -2.1726, 1.0590],
[ 0.6646, 0.6852, -0.8706, -0.0442],
[-0.1163, 0.1389, 0.4454, -1.3423]]])
解释:
- BatchNorm 是在对最后一个维度求平均,均值形状为 [2, 1, 1],与 LayerNorm 的结果不同。
- InstanceNorm 示例
步骤:
- 定义 InstanceNorm:使用
InstanceNorm2d模块。 - 调整数据形状:将数据调整为
InstanceNorm2d需要的形状 (N, C, H, W)。 - 应用 InstanceNorm:对数据进行归一化。
from torch.nn import InstanceNorm2d
instance_norm = InstanceNorm2d(3, affine=False)
output = instance_norm(embedding.reshape(2, 3, 4, 1)) # InstanceNorm2D需要(N,C,H,W)的shape作为输入
layer_norm = torch.nn.LayerNorm(4, elementwise_affine=False)
print(layer_norm(embedding))
输出:
tensor([[[ 1.1505, 0.5212, -0.1262, -1.5455],
[-0.6586, -0.2132, -0.8173, 1.6890],
[ 0.6000, 1.2080, -0.3813, -1.4267]],
[[-0.0861, 1.0145, -1.5895, 0.6610],
[ 0.8724, 0.9047, -1.5371, -0.2400],
[ 0.1507, 0.5268, 0.9785, -1.6560]]])
解释:
- InstanceNorm 和 LayerNorm 结果一致,说明它们在计算过程中本质上是相同的。
结论:
- LayerNorm 和 InstanceNorm 对最后一个维度进行归一化,结果一致。
- BatchNorm 对整个 batch 进行归一化,均值形状不同,结果也不同。
- LayerNorm 实际上是在做 InstanceNorm。
前馈层(FeedForward)
前馈层接受自注意力子层的输出作为输入(Multi-Head Attention的输出做了残差连接和Norm之后的数据)。然后,FeedForward 模块通过两次线性变换和非线性激活函数进一步提取特征。实验证明,这一非线性变换会对模型最终的性能产生十分重要的影响。
\[FFN(x)=Relu(xW_1_+b_1_)W_2_+b_2_ \]\[W_{1},b_{1},W_{2},b_{2}$$ 表示前馈子层的参数  以往的训练发现,增大前馈子层隐状态的维度有利于提升最终翻译结果的质量,因此,前馈子层隐状态的维度一般比自注意力子层要大。 所以FeedForward的作用是:通过线性变换,先将数据映射到高纬度的空间再映射到低纬度的空间,提取了更深层次的特征。 ### MASK MASK在Encoder和Decoder两个结构中都有使用。Transformer中的MASK主要分为两部分:Padding Mask和Sequence Mask两部分 #### [Padding Masked——处理输入不定长](https://zhuanlan.zhihu.com/p/353365423) 对于 Transformer 而言,每次的输入形状为 [batch_size, seq_length, d_model]。由于句子通常长度不一,而输入的数据需要固定的格式,所以要对句子进行预处理。 通常的做法是将每个句子按照最大长度进行补齐(padding)。当句子长度不够时,需要进行补 0 操作,以保证输入数据的结构完整性。 但是在计算注意力机制时,Softmax 函数会对所有输入进行计算,包含补齐的 0 值。但是用0填充的位置的信息是完全没有意义的(多余的),经过softmax操作也会有对应的输出,会影响全局概率值,因此我们希望这个位置不参与后期的反向传播过程。以此避免最后影响模型自身的效果,既在训练时将补全的位置给Mask掉,也就是在这些位置上补一些无穷小(负无穷)的值,经过softmax操作,这些值就成了0,就不在影响全局概率的预测。 #### [Sequence MASK](https://zhuanlan.zhihu.com/p/368592551) sequence MASK是只存在decoder的第一个mutil_head_self_attention里,为什么这样做?是因为在测试验证阶段,模型并不知道当前时刻的输入和未来时刻的单词信息。也就是对于一个序列中的第i个token解码的时候只能够依靠i时刻之前(包括i)的的输出,而不能依赖于i时刻之后的输出。因此我们要采取一个遮盖的方法(Mask)使得其在计算self-attention的时候只用i个时刻之前的token进行计算。\] 标签:Transformer,归一化,Al,Datawhale,pos,PE,LayerNorm,输入,mean From: https://www.cnblogs.com/cauwj/p/18313506