哈喽大家好,我是咸鱼。
好久没发文了,最近这段时间都在学 K8S。不知道大家是不是和咸鱼一样,刚开始学 K8S、Docker 的时候,往往被 CRI、OCI、CRI shim、containerd 这些名词搞得晕乎乎的,不清楚它们到底是干什么用的。所以今天,咸鱼打算借这篇文章来解释一下这些名词,帮助大家理清它们的关系。
我们以 K8S 创建容器的过程为例,来引申出各个概念。
K8S 如何创建容器?
下面这张图,就是经典的 K8S 创建容器的步骤,可以说是冗长复杂,至于为什么设计成这样的架构,继续往下读。
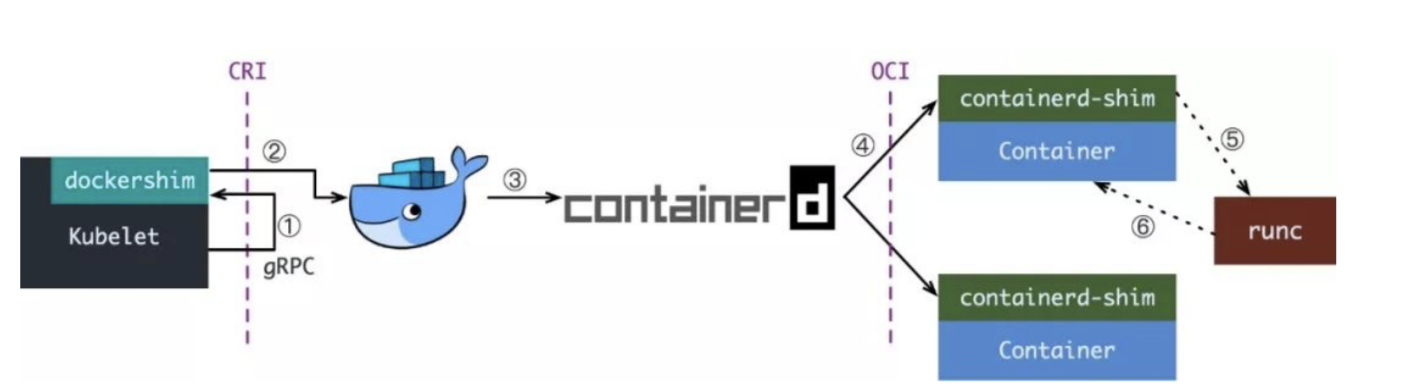
前半部分
- CRI(Container Runtime Interface,容器运行时接口)
在 K8S 中,真正负责创建容器运行时的是 kubelet 这个组件。
当 kubelet 对容器运行时进行操作时,并不会直接调用 Docker 的 API,而是通过一组叫作 CRI 的 gRPC 接口来间接执行的。
其实对于 1.6 版本之前的 K8S 来讲,kubelet 是直接与 Docker 的 API 交互的,为什么要单独多出这一层抽象,其实是商战的结果。
当时,Docker 风靡全球,许多公司都希望能在这一领域分一杯羹,纷纷推出了自家的容器运行时。其中最著名的要属 CoreOS 公司的 rkt 项目。虽然 Docker 是 K8S 最依赖的容器运行时,但凭借与 Google 的特殊关系,CoreOS 公司在 2016 年成功地将对 rkt 容器的支持写进了 kubelet 的主代码里。
这下把专门维护 kubelet 的小组 sig-node 坑惨了。因为在这种情况下,kubelet 的任何重要功能更新都必须同时考虑 Docker 和 rkt 这两种容器运行时的处理场景,并分别更新 Docker 和 rkt 的代码。
更麻烦的是,由于 rkt 比较小众,每次修改 rkt 代码都必须依赖 CoreOS 公司的员工。这不仅降低了开发效率,还给项目的稳定性带来了极大的隐患。
sig-node 一看这可不行,今天出个 rkt,明天出个 xxx,这下我们组也不用干活了,每天使劲折腾兼容性得了。所以把 kubelet 对容器运行时的操作统一抽象成了一个 gRPC 接口,然后告诉大家,你们想做容器运行时可以啊,我热烈欢迎,但是前提是必须用我这个接口。
这一层统一的容器操作接口,就是 CRI ,这样 kubelet 就只需要跟这个接口打交道就可以了。而作为具体的容器项目,比如 Docker、 rkt,它们就只需要自己提供一个该接口的实现,然后对 kubelet 暴露出 gRPC 服务即可。
下面这幅图展示了 CRI 里主要的接口:
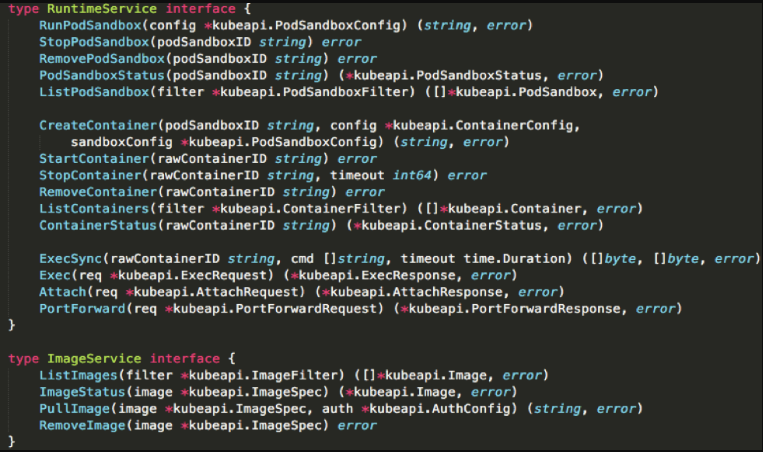
可以简单把 CRI 分为两组:
- 第一组,是
RuntimeService。它提供的接口,主要是跟容器相关的操作。比如,创建和启动容器、删除容器、执行exec命令等等。 - 而第二组,则是
ImageService。它提供的接口,主要是容器镜像相关的操作,比如拉取镜像、删除镜像等等。
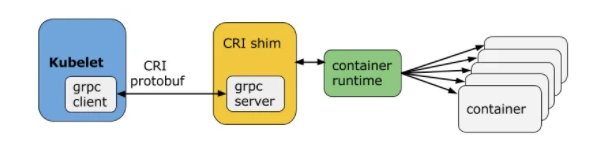
- CRI shim
但是说到底 CRI 只是 K8S 推出的一个标准而已,当时的 K8S 还没有达到如今这般武林盟主的统治地位,各家公司的容器项目也不能说我只跟 K8S 绑死,只适配 CRI 接口。所以, shim (垫片)就诞生了。
一个 shim 的工作就是就是作为适配器将各种容器运行时本身的接口适配到 K8S 的 CRI 接口上,以便用来响应 kubelet 发起的 CRI 请求。
每一个容器运行时都可以自己实现一个 CRI shim,用来把 CRI 请求 “翻译”成自家容器运行时能够听懂的请求。
如果你用 Docekr 作为容器运行时,那你的 CRI shim 就是 dockershim,因为当时 Docker 的江湖地位很高,kubelet 是直接集成了 dockershim 的,所以 K8S 创建容器的前半部分如下图红框所示:
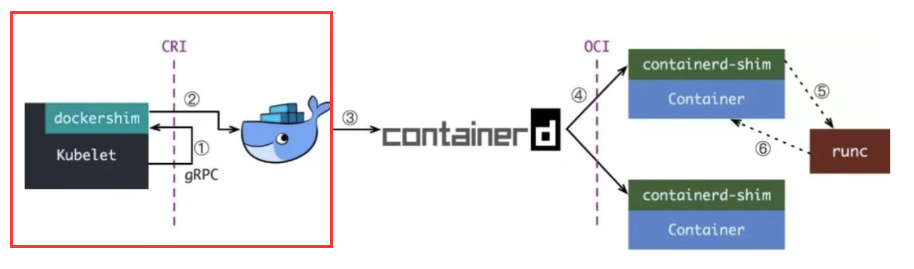
后半部分
当 dockershim 收到 CRI 请求之后,它会把里面的内容拿出来,然后组装成 Docker API 请求发送给 Docker daemon。
请求到了 Docker daemon 之后就是 Docker 创建容器的流程了。
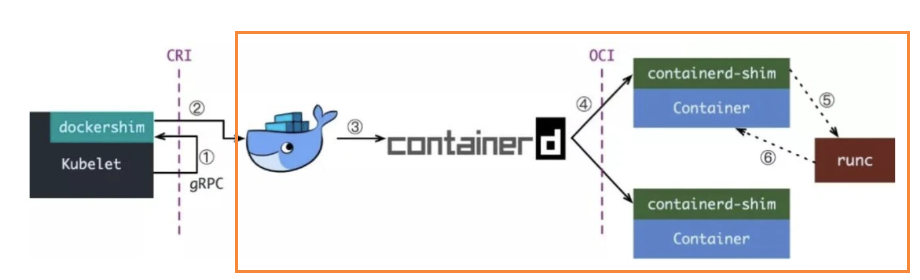
从 Docker 1.11 版本开始,Docker 容器就不再是通过简单的 Docker Daemon 来启动了,而是通过一个守护进程 containerd 来完成的,因此 Docker Daemon 仍然不能帮我们创建容器,而是要请求 containerd 创建一个容器。

containerd 收到请求之后也并不会直接去操作容器,而是创建一个叫 containerd-shim 的进程来处理,这是因为容器需要一个父进程来做状态收集、维持 stdin 等 fd 打开等工作的。
假如这个父进程就是 containerd,如果 containerd 挂掉的话,整个宿主机上所有的容器都得退出了,而引入 containerd-shim 就可以避免这种问题。
我在这篇文章《两个关键词带你了解容器技术的实现》里提到过,容器其实是宿主机上的一个进程,只不过通过 Linux 内核的 namespace 和 cgroups 机制,以及挂载 root 文件系统等操作来实现隔离和资源限制。
对于 namespaces 和 cgroups 的配置,以及挂载 root 文件系统等操作这块内容已经有了标准的规范,那就是 OCI (Open Container Initiative,开放容器标准)。
OCI 标准其实就是一个文档,主要规定了容器镜像的结构、以及容器需要接收哪些操作指令:
- 容器镜像要长啥样,即
ImageSpec。里面的大致规定就是你这个东西需要是一个压缩了的文件夹,文件夹里以 xxx 结构放 xxx 文件; - 容器要需要能接收哪些指令,这些指令的行为是什么,即
RuntimeSpec。这里面的大致内容就是“容器”要能够执行create,start,stop,delete这些命令。
OCI 有一个参考实现,那就是 runc(Docker 被逼无耐将 libcontainer 捐献出来然后改名为 runc )。既然是标准肯定就有其他 OCI 实现,比如 Kata、gVisor 这些容器运行时都是符合 OCI 标准的。
所以实际上 containerd-shim 通过调用 runc 来创建容器,runc 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程。
另一个容器运行时:containerd
从上面的内容我们可以看到,真正容器相关的操作其实在 containerd 那一块,至于前面的 docker shim 和 docker daemon 的操作不但复杂,而且对 K8S 来讲大部分功能都是用不上的。
所以从 K8S 1.20 版本开始,K8S 宣布弃用 Docker,推荐使用 containerd 作为容器运行时。
至于为什么要用 containerd 作为容器运行时,也有商业竞争的原因。当时 docker 公司为了跟 K8S 竞争,搞了个 Docker Swarm,并且把架构进行了切分:把容器操作都移动到一个单独的 containerd 进程中去,让 Docker Daemon 专门负责上层的封装编排。
可惜在 K8S 面前 swarm 就是弟弟,根本打不过,于是 Docker 公司只能后退一步,将 containerd项目捐献给 CNCF 基金会,而 K8S 也见好就收,既然 Docker 已先退了一步,那就干脆优先支持原生Docker 衍生的容器运行时:containerd 。
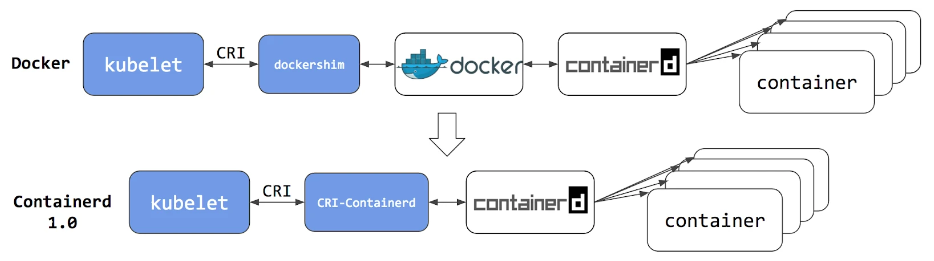
使用 containerd 作为容器运行时之后,就不能再使用 docker ps 或 docker inspect 命令来获取容器信息。由于不能列出容器,因此也不能获取日志、停止容器,甚至不能通过 docker exec 在容器中执行命令。
当然我们仍然可以下载镜像,或者用 docker build 命令构建镜像,但用 Docker 构建、下载的镜像,对于容器运行时和 K8S,均不可见。
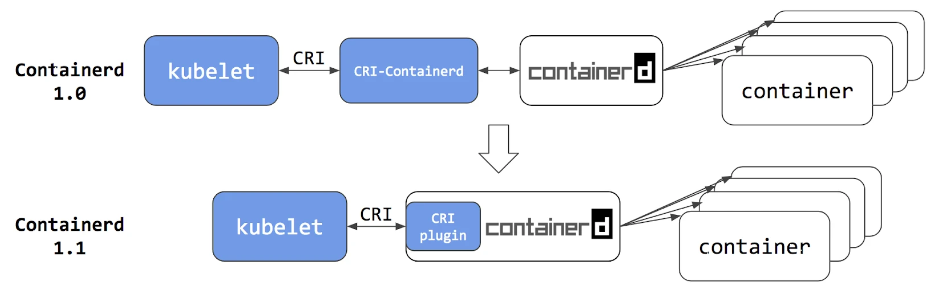
而且为了适配 CRI 标准,专门起了一个单独的进程:CRI-containerd,这是因为还没有捐给 K8S 的时候 containerd 会去适配其他的项目(Docker Swarm)
到了 containerd 1.1 版本,K8S 去掉了 CRI-Contained 这个 shim,直接把适配逻辑作为插件的方式集成到了 containerd 主进程中,现在这样的调用就更加简洁了。
除此之外,K8S 社区也做了一个专门用于 K8S 的运行时 CRI-O,它直接兼容 CRI 和 OCI 规范。
上图中的 conmon 对于 containerd-shim
参考文章:
45 | 幕后英雄:SIG-Node与CRI-深入剖析 Kubernetes-极客时间 (geekbang.org)
K8S Runtime CRI OCI contained dockershim 理解_cri contained-CSDN博客
https://www.qikqiak.com/post/containerd-usage/
标签:OCI,容器,K8S,shim,containerd,Docker,CRI From: https://www.cnblogs.com/edisonfish/p/18303667