背景
Kubernetes是容器集群管理系统,为容器化的应用提供资源调度、部署运行、滚动升级、扩容缩容等功能。容器集群管理给业务带来了便利,但是随着业务的不断增长,应用数量可能会发生爆发式的增长。那在这种情况下,Kubernetes能否快速地完成扩容、扩容到大规模时Kubernetes管理能力是否稳定成了挑战。
提前测试目前 Kubernetes 能承载的最大 Node、Pod 数量。
SLI & SLO
SLI(Service Level Indicator):服务等级指标,其实就是我们选择哪些指标来衡量我们的稳定性。
SLO(Service Level Objective):服务等级目标,指的就是我们设定的稳定性目标,比如“几个 9”这样的目标。
SLO 是 SLI 要达成的目标,我们需要选择合适的 SLI,设定对应的 SLO。
官方提供了三个指标,如下
| SLI | SLO | 测试方法 |
|---|---|---|
| Latency of processing mutating API calls for single objects for every (resource, verb) pair, measured as 99th percentile over last 5 minutes | 99Line <= 1s | 官方 Kubemark + perf-test |
| Latency of processing non-streaming read-only API calls for every (resource, scope) pair, measured as 99th percentile over last 5 minutes | (a) <= 1s if scope=resource (b) <= 30s otherwise (if scope=namespace or scope=cluster) |
官方 Kubemark + perf-test |
| Startup latency of schedulable stateless pods, excluding time to pull images and run init containers, measured from pod creation timestamp to when all its containers are reported as started and observed via watch, measured as 99th percentile over last 5 minutes | 99Line <= 5s | 官方 Kubemark + perf-test |
上面我们有了“性能指标”,以及这些性能指标的“判断条件”。那么怎么测试?
Kubernetes开源了Clusterloader2性能测试框架,帮助我们完成上面的测试过程,并且统计测试结果。
Clusterloader2主要提供了两个测试用例:
(1)密度测试:该测试用例主要用来测试节点规模和容器规模的性能指标。它的大致思路是:在一个有N个节点的集群中,连续创建30*N个Pod,然后再删除这些Pod,然后跟踪这个过程中,上面的三个SLO是否满足。
(2)负载测试:该测试用例的主要思路是,向K8S进行大量的各种类型的资源创建、删除、LIST以及其他操作,然后跟踪这个过程中,上面的三个SLO是否满足。
另外,由于在大多数场景中,无法真实创建5000个节点,Kubernetes开源了一个kubemark项目,用来模拟真实节点。
使用 kubemark 模拟100个 Node 节点
环境说明:
- work 环境作为 性能测试环境
- test 环境节点,作为 node 提供方
kubemark项目编译及镜像制作
# 下载指定版本源码
git clone -b v1.18.10 https://github.com/kubernetes/kubernetes.git
cd kubernetes/
./hack/build-go.sh cmd/kubemark/
cp _output/bin/kubemark cluster/images/kubemark/
cd cluster/images/kubemark/
# 修改 Dockerfile 中镜像为 centos:7
make build
# 改镜像仓库,改tag,push,方便其他节点使用
docker tag staging-k8s.gcr.io/kubemark:latest wangzhichidocker/kubemark:0.1
docker push wangzhichidocker/kubemark:0.1
# test master 操作
kubectl create ns kubemark
kubectl create configmap node-configmap -n kubemark --from-literal=content.type="test-cluster"
# 将 work 环境master 节点的 /root/.kube/config 拷贝过来
kubectl create secret generic kubeconfig --type=Opaque --namespace=kubemark --from-file=kubelet.kubeconfig=config --from-file=kubeproxy.kubeconfig=config
# 打标签
kubectl label node $NodeName name=hollow-node
# NodeName 修改maxPods值 2000
kubectl apply -f deploy.yaml
# deploy.yaml 内容如下
kubemark 虚化建立 100 个 node
apiVersion: apps/v1
kind: Deployment
metadata:
name: hollow-node
namespace: kubemark
labels:
name: hollow-node
spec:
replicas: 100 ###启动的虚拟节点的数量
selector:
matchLabels:
name: hollow-node
template:
metadata:
labels:
name: hollow-node
spec:
nodeSelector:
name: hollow-node
initContainers:
- name: init-inotify-limit
image: busybox
imagePullPolicy: IfNotPresent
command: ['sysctl', '-w', 'fs.inotify.max_user_instances=524288']
securityContext:
privileged: true
volumes:
- name: kubeconfig-volume
secret:
secretName: kubeconfig
containers:
- name: hollow-kubelet
image: wangzhichidocker/kubemark:0.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 4194
- containerPort: 10250
- containerPort: 10255
env:
- name: CONTENT_TYPE
valueFrom:
configMapKeyRef:
name: node-configmap
key: content.type
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
command:
- /bin/sh
- -c
- /kubemark --morph=kubelet --name=$(NODE_NAME) --kubeconfig=/kubeconfig/kubelet.kubeconfig $(CONTENT_TYPE) --alsologtostderr --v=2
volumeMounts:
- name: kubeconfig-volume
mountPath: /kubeconfig
readOnly: true
securityContext:
privileged: true
- name: hollow-proxy
image: wangzhichidocker/kubemark:0.1
imagePullPolicy: IfNotPresent
env:
- name: CONTENT_TYPE
valueFrom:
configMapKeyRef:
name: node-configmap
key: content.type
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
command:
- /bin/sh
- -c
- /kubemark --morph=proxy --name=$(NODE_NAME) --use-real-proxier=false --kubeconfig=/kubeconfig/kubeproxy.kubeconfig $(CONTENT_TYPE) --alsologtostderr --v=2
volumeMounts:
- name: kubeconfig-volume
mountPath: /kubeconfig
readOnly: true
tolerations:
- operator: "Exists"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
nodeSelectorTerms:
- matchExpressions:
- key: name
operator: In
values:
- hollow-node
使用 Clusterloader2 进行性能测试
cd /root/go/src/k8s.io
git clone -b release-1.18 https://github.com/kubernetes/perf-tests.git --depth 1
cd perf-tests/clusterloader2/
go env -w GO111MODULE=off
go build -o clusterloader './cmd/'
# 找到测试目录
cd testing/density/
cp config.yaml config.yaml.bak
# 修改 config.yaml 中的变量
NODES_PER_NAMESPACE 改为 10
# pkg/execservice/manifest/exec_deployment.yaml 和 testing/density/deployment.yaml 镜像地址
# 安装配置 Prometheus 抓取指标
git clone https://github.com/prometheus-operator/kube-prometheus.git --depth 1
kubectl create -f manifests/setup
kubectl create -f manifests/
# 删除 Prometheus 的网络策略 和不必要的 target
# 否则网络不通,同时创建性能测试时会卡住
kubectl -n monitoring delete networkpolicies.networking.k8s.io prometheus-k8s
kubectl -n monitoring delete networkpolicies.networking.k8s.io grafana
kubectl -n monitoring delete servicemonitors.monitoring.coreos.com kubelet
kubectl -n monitoring delete servicemonitors.monitoring.coreos.com node-exporter
kubectl -n monitoring delete daemonsets.apps node-exporter
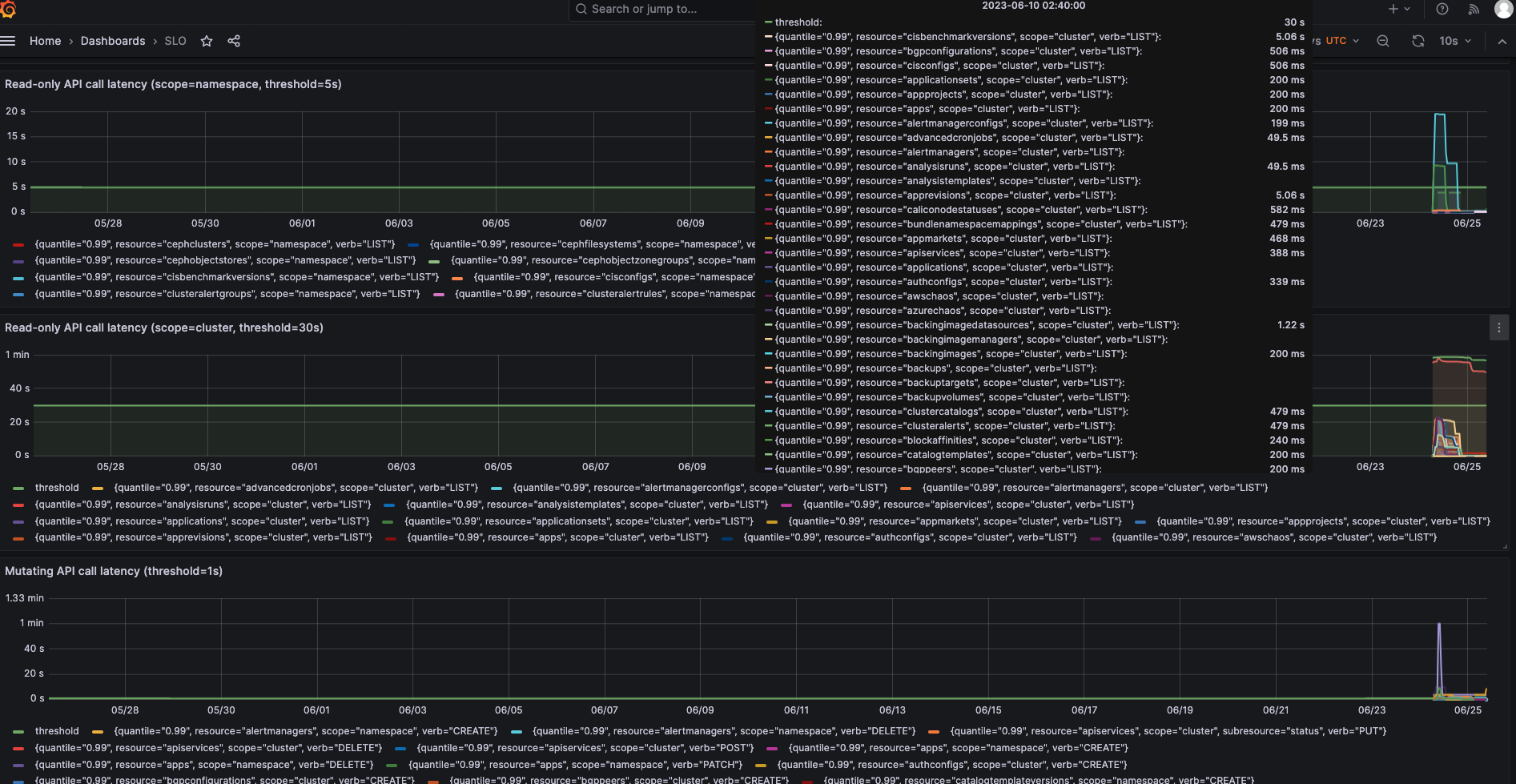
# 导入 SLO dashboard(pkg/prometheus/manifests/dashboards/slo.json),更改规则,record metric
kubectl apply -f pkg/prometheus/manifests/prometheus-rules.yaml
# 配置全局的变量
cp /root/.ssh/id_rsa /root/.ssh/google_compute_engine # benchmark 需要
cd ../..
KUBE_CONFIG=${HOME}/.kube/config
PROVIDER='kubemark'
MASTER_SSH_IP=$MASTER_SSH_IP
KUBE_SSH_KEY_PATH=$HOME/.ssh/id_rsa
MASTER_SSH_USER_NAME=root
TEST_CONFIG='./testing/density/config.yaml'
./clusterloader --kubeconfig=$KUBE_CONFIG --provider=$PROVIDER --masterip=$MASTER_SSH_IP --testconfig=$TEST_CONFIG --report-dir="./reports" --alsologtostderr --enable-prometheus-server=true --tear-down-prometheus-server=false --kubemark-root-kubeconfig=$KUBE_CONFIG 2>&1 | tee test.log
# 此工具会先启动三个名为exec-pod的pod,之后通过配置的depolyment启动pod
分析报告
# APIResponsivenessPrometheus
cat APIResponsivenessPrometheus_density_2023-06-25T15\:25\:39+08\:00.json | grep Perc99 | grep -v '"Perc99": 0'
# 找到耗时较高的数值进行分析, Pod List 和 Node List 耗时较高
{
"data": {
"Perc50": 34.481725,
"Perc90": 95.6625,
"Perc99": 14323
},
"unit": "ms",
"labels": {
"Count": "1493",
"Resource": "pods",
"Scope": "cluster",
"SlowCount": "1490",
"Subresource": "",
"Verb": "LIST"
}
},
{
"data": {
"Perc50": 35.494424,
"Perc90": 1844.541666,
"Perc99": 4349
},
"unit": "ms",
"labels": {
"Count": "4634",
"Resource": "nodes",
"Scope": "cluster",
"SlowCount": "4629",
"Subresource": "",
"Verb": "LIST"
}
},
# vim PodStartupLatency_SaturationPodStartupLatency_density_2023-06-21T18\:01\:47+08\:00.json
# 分析调度延迟
{
"version": "1.0",
"dataItems": [
{
"data": {
"Perc50": 0,
"Perc90": 0,
"Perc99": 1000
},
"unit": "ms",
"labels": {
"Metric": "create_to_schedule"
}
},
{
"data": {
"Perc50": 0,
"Perc90": 1000,
"Perc99": 3000
},
"unit": "ms",
"labels": {
"Metric": "schedule_to_run"
}
},
{
"data": {
"Perc50": 212966.461221,
"Perc90": 396976.212344,
"Perc99": 445981.781733
},
"unit": "ms",
"labels": {
"Metric": "run_to_watch"
}
},
{
"data": {
"Perc50": 212973.348171,
"Perc90": 396985.062556,
"Perc99": 446977.294416
},
"unit": "ms",
"labels": {
"Metric": "schedule_to_watch"
}
},
{
"data": {
"Perc50": 212975.328713,
"Perc90": 396985.234373,
"Perc99": 446979.922275
},
"unit": "ms",
"labels": {
"Metric": "pod_startup"
}
}
]
}
参考链接:
Kubernetes 官方 slosopen in new window
clusterloader2 测试使用文档open in new window
kubemark 设置文档open in new window
标签:kubemark,node,name,Kubernetes,kubectl,--,基准,kubeconfig,Master From: https://www.cnblogs.com/david-cloud/p/18291763