数据仓库的学习
1. 分层设计
数仓分层阿里整体分为了5层,分别是ODS,DWD,DIM,DWS,ADS
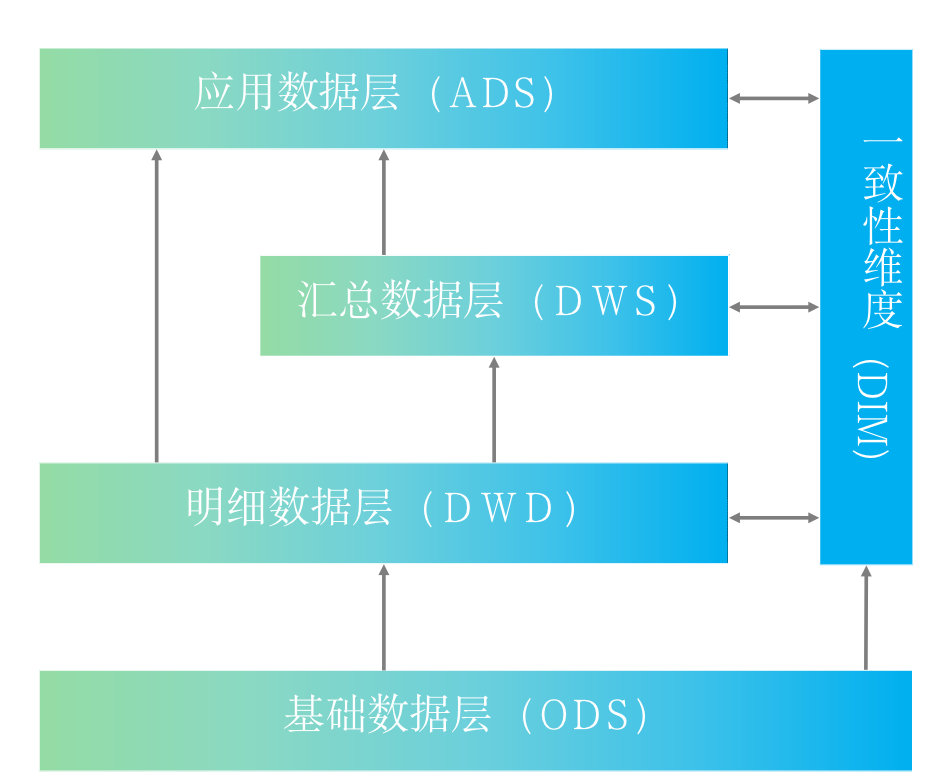
- ODS(Operational Data Store)
- 面向主题的”数据运营层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的 ETL 之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。
- 一般来讲,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的DWD层来做。
- DWD(Data Warehouse Detail)
- 该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层 的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
- 另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性。
- DWS(Data Warehouse Service)
- 又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后 续的业务查询,OLAP分析,数据分发等。
- 一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一 般也会称该层的表为宽表。在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计 算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成 一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在 放在DWS亦可。
- DIM(Dimension)
- 维表层主要包含两部分数据:
- 高基数维度数据:一般是用户维度表、商品维度表类似的维度表。数据量可能是千万级或者上亿级别。
- 低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
- 维表层主要包含两部分数据:
- ADS(Application Data Service)
- 数据应用层ADS(Application Data Service):存放数据产品个性化的统计指标数据。根据DWD和DWS层加工生成。
2. 事实表有那些类型
-
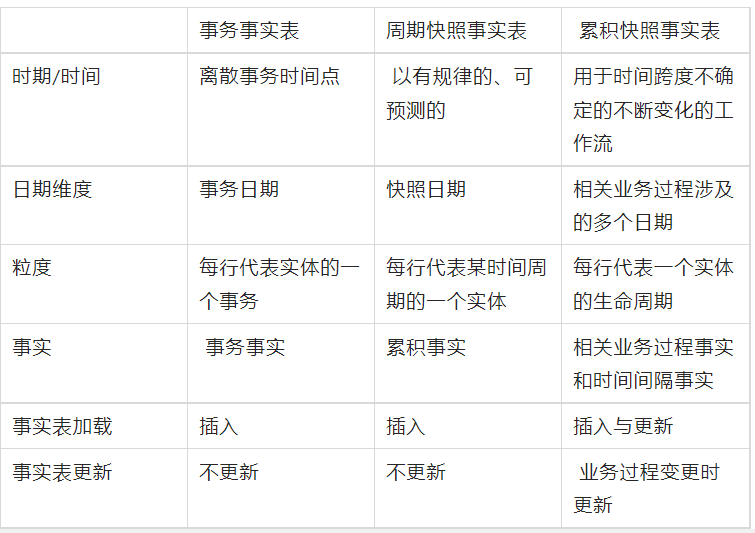
事实表有三种类型:事务事实表、周期事实表和累积快照事实表
-
事务事实表也称原子事实表,描述业务过程,跟踪控件或时间上某点的度量事件,保存的是最原子的数据
-
周期快照事实表以一个周期为时间间隔,来记录事实,一般周期可以是每天、每周、每月、每年等
-
累积快照事实表用来描述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点;当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改
-
三种事实表对比
3. 数仓建模的三大范式
- 第一范式:属性不可在分割
- 第二范式:所有非主属性都完全依赖于主关键字
- 第三范式:非主关键字不能依赖于其他非主关键字。即非主关键字之间不能有函数(传递)依赖关系
4. 数仓模型规范
- 禁止逆向调用
- 避免同层调用
- 优先使用公共层
- 避免跨层调用
5. 数仓中数据模型
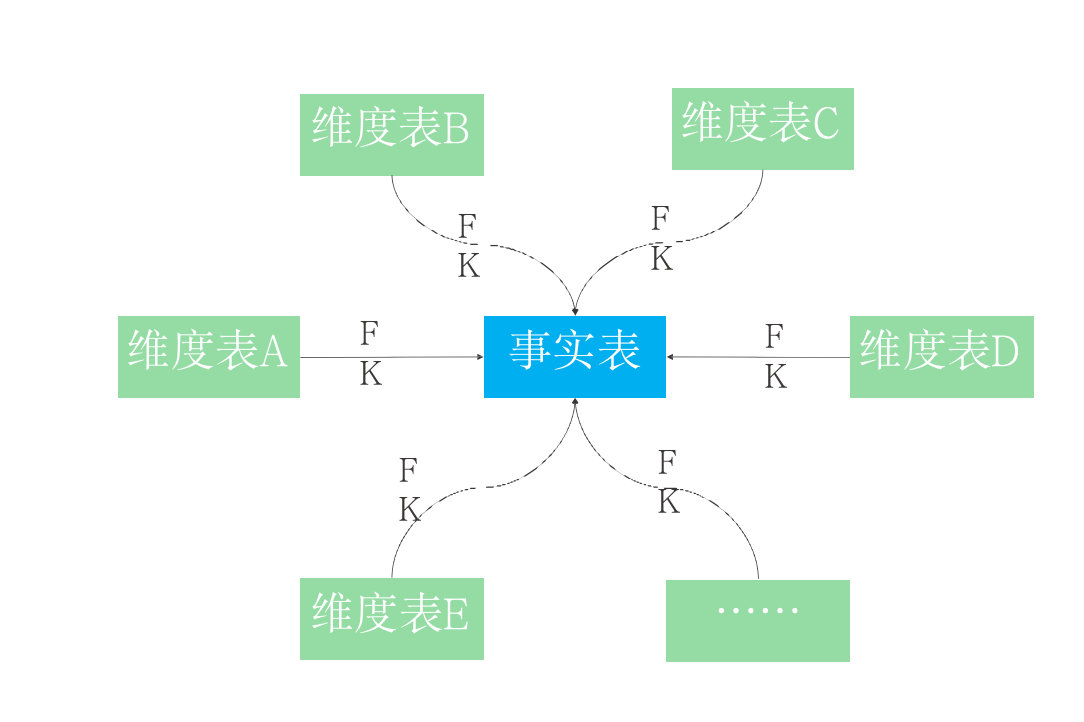
- 星型模型
- 在数据仓库建模中,星型模型是维度建模中的一种选择方式。星型模型是以一个事实表和一组维度表组合而成,并且以事实表为中心,所有的维度表直接与事实表相连。
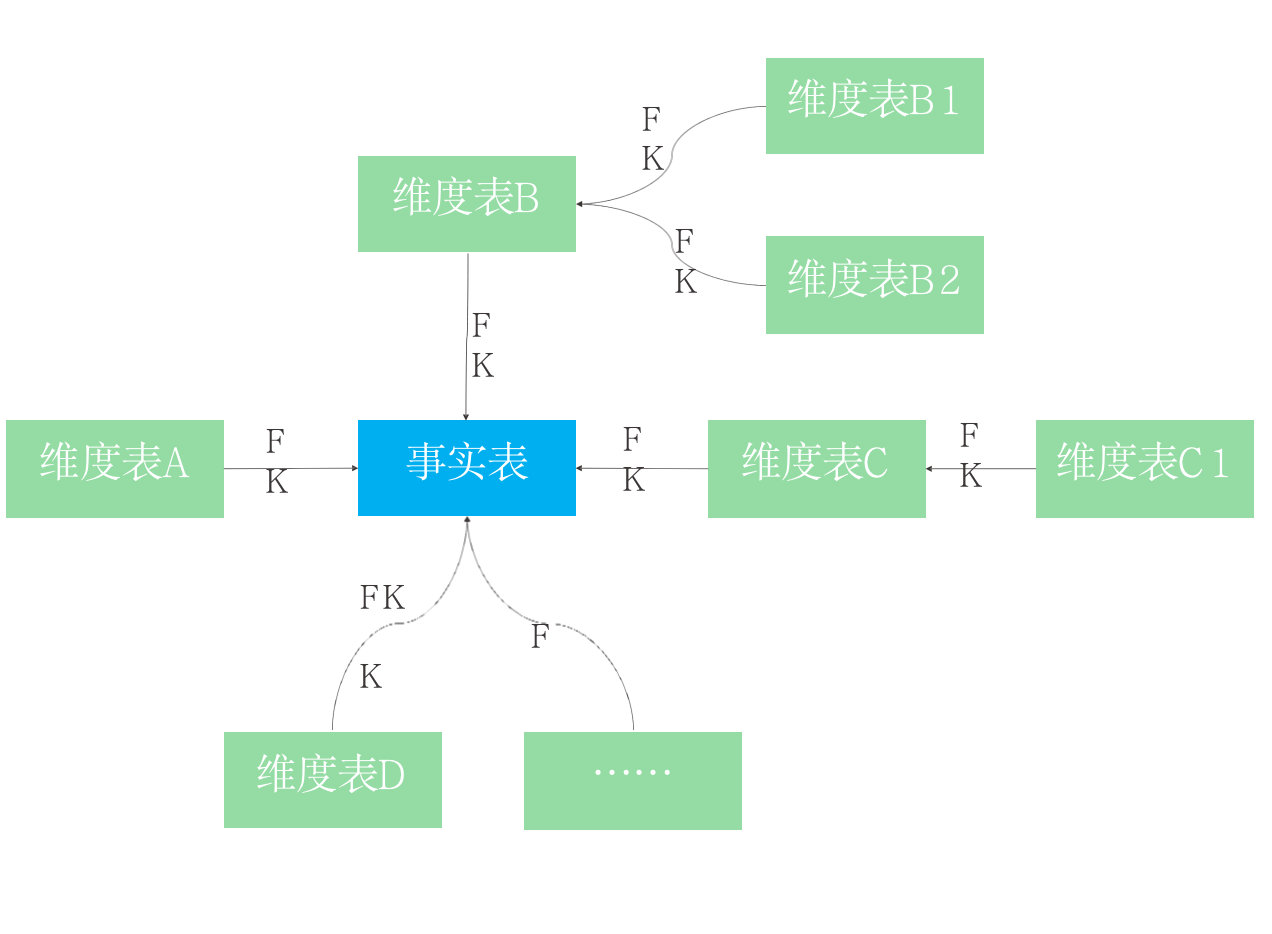
- 雪花型模型
- 雪花模型也是维度建模中的另一种选择,它是对星型模型的扩展,雪花模型的维度表可以拥有其他的维度表,并且维度表与维度表之间是相互关联的。因此,雪花模型相比星型模型更规范一些。但是,由于雪花模型需要关联多层的维度表,因此,性能也比星型模型要低,所以一般不是很常用。
- 星座模型
- 维表是共享状态的,可以被多个事实表关联使用,这种模式可以看做星型模式的汇集,因而称作星系模式或者事实星座模式
6. ODS层做哪些事情
- 保持数据原貌,不做任何修改
- 压缩采用LZO,压缩比是100g数据压缩完10g左右
- 创建分区表
7. DWD层做哪些事情
- 数据清洗
- 空值去除
- 过滤核心字段无意义的数据,比如订单表中订单id为null,支付表中支付id为空
- 将用户行为宽表和业务表进行数据一致性处理
- 脱敏
- 对手机号、身份证号等敏感数据脱敏
- 维度退化
- 对业务数据传过来的表进行维度退化和降维。(商品一级二级三级、省市县、年月日)
- 压缩LZO
- 列式存储parquet
8. 为什么要设计数据分层?
- 清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
- 统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径
- 复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
9. 数据仓库的定义
-
首先,用于支持决策,面向分析型数据处理;其次,对多个异构的数据源有效集成,集成后按照主题进行重组,并包含历史数据,而且存放在数据仓库中的数据一般不再修改。
-
数据仓库(Data Warehouse)是一个面向主题的(subject oriented)、集成的(integrated)、相对稳定的(non-volatile)、反应历史变化(time variant)的数据集合,用于支持管理决策(decision making support)。
10. 数据仓库和数据库的区别?
从目标、用途、设计来说
- 数据库是面向事物处理的,数据是由日常的业务产生的,常更新;数据仓库是面向主题的,数据来源多样,经过一定的规则转换得到,用来分析。
- 数据库一般用来存储当前事务性数据,如交易数据;数据仓库一般存储的历史数据。
- 数据库的设计一般是符合三范式的,有最大的精确度和最小的冗余度,有利于数据的插入;数据仓库的设计一般不符合三范式,有利于查询
11. 事实表设计流程
- 选择业务
- 在明确了业务需求以后,接下来需要进行详细的需求分析,对业务的整个生命周期进行分 析,明确关键的业务步骤,从而选择与需求有关的业务过程。业务过程通常使用行为动词 表示业务执行的活动
- 声明粒度
- 粒度的声明是事实表建模非常重要的一步,意味着确定事实表的每一行所表示的业务含义, 粒度传递的是与事实表度量有关的细节层次。明确的粒度能确保对事实表中行的意思的理 解不会产生混淆,保证所有的事实按照同样的细节层次记录
- 确定维度
- 完成粒度声明以后,也就意味着确定了主键,对应的维度组合以及相关的维度字段就可以 确定了,应该选择能够描述清楚业务过程所处的环境的维度信息
- 确定事实
- 事实可以通过回答“过程的度量是什么”来确定。应该选择与业务过程有关的所有事实, 且事实的粒度要与所声明的事实表的粒度一致。事实有可加性、半可加性、非可加性三 种类型,需要将不可加性事实分解为可加的组件
- 冗余维度
- 在大数据的事实表模型设计中,考虑更多的是提高下游用户的使用效率,降低数据获取 的复杂性,减少关联的表数量。所以通常事实表中会冗余方便下游用户使用的常用维度, 以实现对事实表的过滤查询、控制聚合层次、排序数据以及定义主从关系等操作