Pandas数据筛选
1.reindex()
df.reindex(index=列表,columns=列表)
import pandas as pd
data = [
['苹果', 5, '山东'],
['香蕉', 3, '海南'],
['橙子', 6, '江西'],
['西瓜', 2, '新疆'],
['草莓', 10, '辽宁'],
['葡萄', 8, '云南'],
['芒果', 7, '广西'],
['菠萝', 4, '广东'],
['梨', 4, '河北'],
['桃子', 5, '四川']
]
df = pd.DataFrame(data, columns=["水果", "价格", "产地"])
df1 = df.reindex([0, 1, 2, 4])
print(df1)

2.head() & tail()
df.head(n)
df.tail(n)
import pandas as pd
data = [
['苹果', 5, '山东'],
['香蕉', 3, '海南'],
['橙子', 6, '江西'],
['西瓜', 2, '新疆'],
['草莓', 10, '辽宁'],
['葡萄', 8, '云南'],
['芒果', 7, '广西'],
['菠萝', 4, '广东'],
['梨', 4, '河北'],
['桃子', 5, '四川']
]
df = pd.DataFrame(data, columns=["水果", "价格", "产地"])
print(df.head(2))
print("=================")
print(df.tail(2))
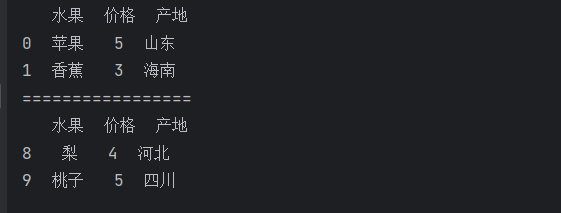
3.随机抽样
df.sample(n=整数) #具体个数
df.sample(frac=小数) #百分比抽取
import pandas as pd
data = [
['苹果', 5, '山东'],
['香蕉', 3, '海南'],
['橙子', 6, '江西'],
['西瓜', 2, '新疆'],
['草莓', 10, '辽宁'],
['葡萄', 8, '云南'],
['芒果', 7, '广西'],
['菠萝', 4, '广东'],
['梨', 4, '河北'],
['桃子', 5, '四川']
]
df = pd.DataFrame(data, columns=["水果", "价格", "产地"])
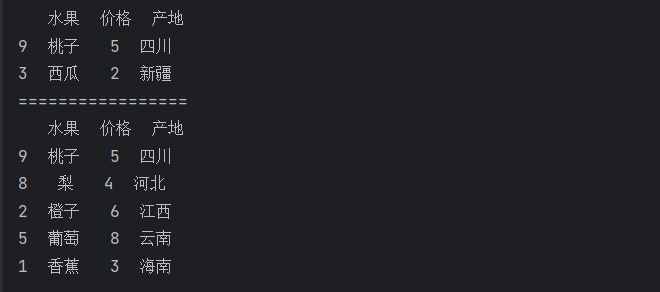
print(df.sample(n=2))
print("=================")
print(df.sample(frac=0.5))
4.逻辑比较
| 运算符 | 说明 |
|---|---|
| & | 与 |
| | | 或 |
| ~ | 非 |
df[条件]
import pandas as pd
data = [
['苹果', 5, '山东'],
['香蕉', 3, '海南'],
['橙子', 6, '江西'],
['西瓜', 2, '新疆'],
['草莓', 10, '辽宁'],
['葡萄', 8, '云南'],
['芒果', 7, '广西'],
['菠萝', 4, '广东'],
['梨', 4, '河北'],
['桃子', 5, '四川']
]
df = pd.DataFrame(data, columns=["水果", "价格", "产地"])
print(df[df["价格"] > 5])

5.过滤操作
(1)query()
df.query(判断条件)
import pandas as pd
data = [
['苹果', 5, '山东'],
['香蕉', 3, '海南'],
['橙子', 6, '江西'],
['西瓜', 2, '新疆'],
['草莓', 10, '辽宁'],
['葡萄', 8, '云南'],
['芒果', 7, '广西'],
['菠萝', 4, '广东'],
['梨', 4, '河北'],
['桃子', 5, '四川']
]
df = pd.DataFrame(data, columns=["水果", "价格", "产地"])
print(df.query("价格>5"))
(2)filter()
df.filter(items,like,regex)
# items 列表 表示选取哪些列
# like 字符串 模糊选择
# regex 正则表示式 表示根据正则表达式列选取列
三个参数是互斥的,选一个即可,items,like和regex的对象都是列名
import pandas as pd
data = [
['苹果', 5, '山东'],
['香蕉', 3, '海南'],
['橙子', 6, '江西'],
['西瓜', 2, '新疆'],
['草莓', 10, '辽宁'],
['葡萄', 8, '云南'],
['芒果', 7, '广西'],
['菠萝', 4, '广东'],
['梨', 4, '河北'],
['桃子', 5, '四川']
]
df = pd.DataFrame(data, columns=["水果", "价格", "产地"])
print(df.filter(items=["水果"]))
print("================")
print(df.filter(like="地"))
print("================")
print(df.filter(regex=".格"))


6.模式匹配
| 方法 | 说明 |
|---|---|
| contains(A) | 判断是否包含A |
| startswith | 判断是否以A开头 |
| endswith | 判断是否以A结尾 |
import pandas as pd
data = [
['苹果', 5, '山东'],
['香蕉', 3, '海南'],
['橙子', 6, '江西'],
['西瓜', 2, '新疆'],
['草莓', 10, '辽宁'],
['葡萄', 8, '云南'],
['芒果', 7, '广西'],
['菠萝', 4, '广东'],
['梨', 4, '河北'],
['桃子', 5, '四川']
]
df = pd.DataFrame(data, columns=["水果", "价格", "产地"])
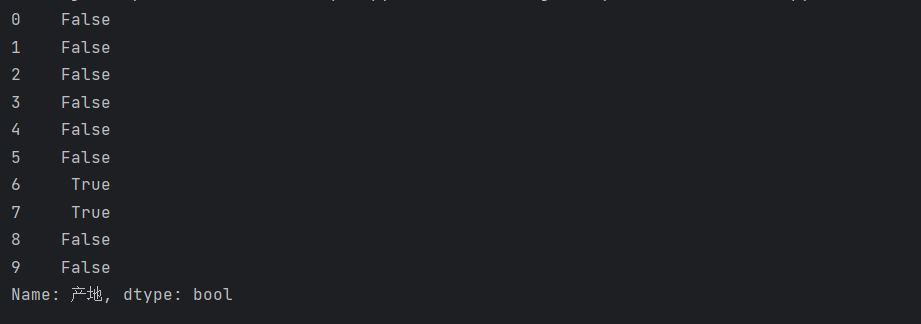
print(df["产地"].str.startswith("广"))
 标签:df,data,pd,print,import,筛选,数据,Pandas,columns
From: https://www.cnblogs.com/hanstary/p/18279417
标签:df,data,pd,print,import,筛选,数据,Pandas,columns
From: https://www.cnblogs.com/hanstary/p/18279417