一.启动命令过程日志
启动命令bash ./run.sh -c local -i 0 -b hf -m Qwen-1_8B-Chat -t qwen-7b-chat。输入日志如下所示:
root@MM-202203161213:/mnt/l/20230918_RAG方向/QAnything# bash ./run.sh -c local -i 0 -b hf -m Qwen-1_8B-Chat -t qwen-7b-chat
From https://github.com/ai408/QAnything
* branch master -> FETCH_HEAD
当前master分支已是最新,无需更新。
请输入您使用的大模型B数(示例:1.8B/3B/7B): 1.8B
model_size=1.8B
GPUID1=0, GPUID2=0, device_id=0
llm_api is set to [local]
device_id is set to [0]
runtime_backend is set to [hf]
model_name is set to [Qwen-1_8B-Chat]
conv_template is set to [qwen-7b-chat]
tensor_parallel is set to [1]
gpu_memory_utilization is set to [0.81]
Do you want to use the previous ip: localhost? (yes/no) 是否使用上次的ip: ?(yes/no) 回车默认选yes,请输入:yes
Running under WSL
[+] Building 0.0s (0/0)
[+] Running 1/1
......
✔ Container qanything-container-local Started
qanything-container-local |
qanything-container-local | =============================
qanything-container-local | == Triton Inference Server ==
qanything-container-local | =============================
qanything-container-local |
qanything-container-local | NVIDIA Release 23.05 (build 61161506)
qanything-container-local | Triton Server Version 2.34.0
qanything-container-local |
qanything-container-local | Copyright (c) 2018-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
qanything-container-local |
qanything-container-local | Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
qanything-container-local |
qanything-container-local | This container image and its contents are governed by the NVIDIA Deep Learning Container License.
qanything-container-local | By pulling and using the container, you accept the terms and conditions of this license:
qanything-container-local | https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
qanything-container-local |
qanything-container-local | llm_api is set to [local]
qanything-container-local | device_id is set to [0]
qanything-container-local | runtime_backend is set to [hf]
qanything-container-local | model_name is set to [Qwen-1_8B-Chat]
qanything-container-local | conv_template is set to [qwen-7b-chat]
qanything-container-local | tensor_parallel is set to [1]
qanything-container-local | gpu_memory_utilization is set to [0.81]
qanything-container-local | checksum de2530187992077db2c08276fcdc8bce
qanything-container-local | default_checksum de2530187992077db2c08276fcdc8bce
qanything-container-local |
qanything-container-local | [notice] A new release of pip is available: 23.3.2 -> 24.0
qanything-container-local | [notice] To update, run: python3 -m pip install --upgrade pip
qanything-container-local | GPU ID: 0, 0
qanything-container-local | GPU1 Model: NVIDIA GeForce RTX 3090
qanything-container-local | Compute Capability: 8.6
qanything-container-local | OCR_USE_GPU=True because 8.6 >= 7.5
qanything-container-local | ====================================================
qanything-container-local | ******************** 重要提示 ********************
qanything-container-local | ====================================================
qanything-container-local |
qanything-container-local | /workspace/qanything_local/scripts/run_for_local_option.sh: line 208: [: 1.8: integer expression expected
qanything-container-local | 您当前的显存为 24576 MiB 推荐部署7B模型
qanything-container-local | /workspace/qanything_local/scripts/run_for_local_option.sh: line 276: [: 1.8: integer expression expected
qanything-container-local | The triton server for embedding and reranker will start on 0 GPUs
qanything-container-local | Executing hf runtime_backend
qanything-container-local | The rerank service is ready! (2/8)
qanything-container-local | rerank服务已就绪! (2/8)
qanything-container-local | The ocr service is ready! (3/8)
qanything-container-local | OCR服务已就绪! (3/8)
qanything-container-local | The qanything backend service is ready! (4/8)
qanything-container-local | qanything后端服务已就绪! (4/8)
qanything-container-local | Dependencies related to npm are obtained. (5/8)
qanything-container-local | The front_end/dist folder already exists, no need to build the front end again.(6/8)
qanything-container-local | Waiting for the front-end service to start...
qanything-container-local | 等待启动前端服务
qanything-container-local |
qanything-container-local | > [email protected] serve
qanything-container-local | > vite preview --port 5052
qanything-container-local |
qanything-container-local | The CJS build of Vite's Node API is deprecated. See https://vitejs.dev/guide/troubleshooting.html#vite-cjs-node-api-deprecated for more details.
qanything-container-local | ➜ Local: http://localhost:5052/qanything
qanything-container-local | ➜ Network: http://172.21.0.6:5052/qanything
qanything-container-local | The front-end service is ready!...(7/8)
qanything-container-local | 前端服务已就绪!...(7/8)
qanything-container-local | I0416 16:38:03.654302 131 grpc_server.cc:377] Thread started for CommonHandler
qanything-container-local | I0416 16:38:03.654861 131 infer_handler.cc:629] New request handler for ModelInferHandler, 0
qanything-container-local | I0416 16:38:03.655310 131 infer_handler.h:1025] Thread started for ModelInferHandler
qanything-container-local | I0416 16:38:03.655832 131 infer_handler.cc:629] New request handler for ModelInferHandler, 0
qanything-container-local | I0416 16:38:03.656273 131 infer_handler.h:1025] Thread started for ModelInferHandler
qanything-container-local | I0416 16:38:03.656863 131 stream_infer_handler.cc:122] New request handler for ModelStreamInferHandler, 0
qanything-container-local | I0416 16:38:03.657257 131 infer_handler.h:1025] Thread started for ModelStreamInferHandler
qanything-container-local | I0416 16:38:03.657673 131 grpc_server.cc:2450] Started GRPCInferenceService at 0.0.0.0:9001
qanything-container-local | I0416 16:38:03.658368 131 http_server.cc:3555] Started HTTPService at 0.0.0.0:9000
qanything-container-local | I0416 16:38:03.700441 131 http_server.cc:185] Started Metrics Service at 0.0.0.0:9002
qanything-container-local | I0416 16:38:47.479318 131 http_server.cc:3449] HTTP request: 0 /v2/health/ready
qanything-container-local | The embedding and rerank service is ready!. (7.5/8)
qanything-container-local | Embedding 和 Rerank 服务已准备就绪!(7.5/8)
qanything-container-local | 2024-04-17 00:38:07 | INFO | model_worker | args: Namespace(host='0.0.0.0', port=7801, worker_address='http://0.0.0.0:7801', controller_address='http://0.0.0.0:7800', model_path='/model_repos/CustomLLM/Qwen-1_8B-Chat', revision='main', device='cuda', gpus='0', num_gpus=1, max_gpu_memory=None, dtype='bfloat16', load_8bit=True, cpu_offloading=False, gptq_ckpt=None, gptq_wbits=16, gptq_groupsize=-1, gptq_act_order=False, awq_ckpt=None, awq_wbits=16, awq_groupsize=-1, enable_exllama=False, exllama_max_seq_len=4096, exllama_gpu_split=None, exllama_cache_8bit=False, enable_xft=False, xft_max_seq_len=4096, xft_dtype=None, model_names=None, conv_template='qwen-7b-chat', embed_in_truncate=False, limit_worker_concurrency=5, stream_interval=2, no_register=False, seed=None, debug=False, ssl=False)
qanything-container-local | 2024-04-17 00:38:07 | INFO | model_worker | Loading the model ['Qwen-1_8B-Chat'] on worker 138d0217 ...
qanything-container-local | 2024-04-17 00:38:09 | WARNING | transformers_modules.Qwen-1_8B-Chat.modeling_qwen | The model is automatically converting to bf16 for faster inference. If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to "AutoModelForCausalLM.from_pretrained".
qanything-container-local | 2024-04-17 00:38:09 | WARNING | transformers_modules.Qwen-1_8B-Chat.modeling_qwen | Try importing flash-attention for faster inference...
qanything-container-local | 2024-04-17 00:38:10 | WARNING | transformers_modules.Qwen-1_8B-Chat.modeling_qwen | Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
0%| | 0/2 [00:00<?, ?it/s]17 00:38:11 | ERROR | stderr |
qanything-container-local | % Total % Received % Xferd Average Speed Time Time Time Current
qanything-container-local | Dload Upload Total Spent Left Speed
100 13 100 13 0 0 3004 0 --:--:-- --:--:-- --:--:-- 3250
qanything-container-local | The llm service is starting up, it can be long... you have time to make a coffee :)
qanything-container-local | LLM 服务正在启动,可能需要一段时间...你有时间去冲杯咖啡 :)
......
qanything-container-local | The llm service is starting up, it can be long... you have time to make a coffee :)
qanything-container-local | LLM 服务正在启动,可能需要一段时间...你有时间去冲杯咖啡 :)
100%|██████████| 2/2 [06:35<00:00, 206.00s/it]46 | ERROR | stderr |
100%|██████████| 2/2 [06:35<00:00, 197.69s/it]46 | ERROR | stderr |
qanything-container-local | 2024-04-17 00:44:46 | ERROR | stderr |
qanything-container-local | 2024-04-17 00:44:46 | INFO | model_worker | Register to controller
qanything-container-local | 2024-04-17 00:44:46 | ERROR | stderr | INFO: Started server process [148]
qanything-container-local | 2024-04-17 00:44:46 | ERROR | stderr | INFO: Waiting for application startup.
qanything-container-local | 2024-04-17 00:44:46 | ERROR | stderr | INFO: Application startup complete.
qanything-container-local | 2024-04-17 00:44:46 | ERROR | stderr | INFO: Uvicorn running on http://0.0.0.0:7801 (Press CTRL+C to quit)
qanything-container-local | % Total % Received % Xferd Average Speed Time Time Time Current
qanything-container-local | Dload Upload Total Spent Left Speed
100 29 100 29 0 0 8638 0 --:--:-- --:--:-- --:--:-- 9666
qanything-container-local | The llm service is ready!, now you can use the qanything service. (8/8)
qanything-container-local | LLM 服务已准备就绪!现在您可以使用qanything服务。(8/8)
qanything-container-local | 开始检查日志文件中的错误信息...
qanything-container-local | /workspace/qanything_local/logs/debug_logs/rerank_server.log 中未检测到明确的错误信息。请手动排查 /workspace/qanything_local/logs/debug_logs/rerank_server.log 以获取更多信息。
qanything-container-local | /workspace/qanything_local/logs/debug_logs/ocr_server.log 中未检测到明确的错误信息。请手动排查 /workspace/qanything_local/logs/debug_logs/ocr_server.log 以获取更多信息。
qanything-container-local | /workspace/qanything_local/logs/debug_logs/sanic_api.log 中未检测到明确的错误信息。请手动排查 /workspace/qanything_local/logs/debug_logs/sanic_api.log 以获取更多信息。
qanything-container-local | Time elapsed: 408 seconds.
qanything-container-local | 已耗时: 408 秒.
qanything-container-local | Please visit the front-end service at [http://localhost:5052/qanything/] to conduct Q&A.
qanything-container-local | 请在[http://localhost:5052/qanything/]下访问前端服务来进行问答,如果前端报错,请在浏览器按F12以获取更多报错信息
二. run.sh脚本
1.update_or_append_to_env()函数
更新或追加键值对到.env文件:
update_or_append_to_env() {
local key=$1
local value=$2
local env_file=".env"
# 检查键是否存在于.env文件中
if grep -q "^${key}=" "$env_file"; then
# 如果键存在,则更新它的值
sed -i "/^${key}=/c\\${key}=${value}" "$env_file"
else
# 如果键不存在,则追加键值对到文件
echo "${key}=${value}" >> "$env_file"
fi
}
.env文件内容:
MODEL_SIZE=1.8B
GPUID1=0
GPUID2=0
LLM_API=local
DEVICE_ID=0
RUNTIME_BACKEND=hf
MODEL_NAME=Qwen-1_8B-Chat
CONV_TEMPLATE=qwen-7b-chat
TP=1
GPU_MEM_UTILI=0.81
USER_IP=localhost
WIN_VERSION=WIN11
OCR_USE_GPU=True
OFFCUT_TOKEN=0
RERANK_PORT=9001
EMBED_PORT=9001
LLM_API_SERVE_PORT=7802
LLM_API_SERVE_MODEL=Qwen-1_8B-Chat
LLM_API_SERVE_CONV_TEMPLATE=qwen-7b-chat
2.script_name=$(basename "$0")
解析:
(1)这行代码是在 Bash 脚本中获取当前脚本文件的名称。
(2)$0 是一个特殊变量,它在 Bash 脚本中表示当前脚本的文件名。
(3)basename 是一个命令行工具,它从输入的文件路径中去除目录和后缀,只返回文件名。
(4)basename "$0" 就是获取当前脚本的文件名,不包括路径和后缀。
(5)script_name=$(basename "$0") 就是将这个文件名赋值给变量 script_name。
3.usage()函数
解析:可以根据自己的设备条件选择最合适的服务启动命令:
(1)当设置 -i 0,1 时,本地嵌入/重排将在设备 gpu_id_1 上运行,否则默认使用 gpu_id_0。
(2)设置 -c cloud 将使用本地嵌入/重排和 OpenAI LLM API,这仅需要大约 4GB VRAM(推荐给 GPU 设备 VRAM <= 8GB 的情况)。
(3)当使用 OpenAI LLM API 时,将立即要求输入 {OPENAI_API_KEY, OPENAI_API_BASE, OPENAI_API_MODEL_NAME, OPENAI_API_CONTEXT_LENGTH}。
(4)-b hf 是运行公共 LLM 推理最推荐的方式,因为它的兼容性好,但性能较差。
(5)当为 QAnything 系统选择一个公共聊天 LLM 时,应该考虑到一个更合适的 **PROMPT_TEMPLATE**(路径/到/QAnything/qanything_kernel/configs/model_config.py)设置,考虑到不同的 LLM 模型。
usage() {
echo "Usage: $script_name [-c <llm_api>] [-i <device_id>] [-b <runtime_backend>] [-m <model_name>] [-t <conv_template>] [-p <tensor_parallel>] [-r <gpu_memory_utilization>] [-h]"
echo " -c : Options {local, cloud} to specify the llm API mode, default is 'local'. If set to '-c cloud', please mannually set the environments {OPENAI_API_KEY, OPENAI_API_BASE, OPENAI_API_MODEL_NAME, OPENAI_API_CONTEXT_LENGTH} into .env fisrt in run.sh"
echo " -i <device_id>: Specify argument GPU device_id"
echo " -b <runtime_backend>: Specify argument LLM inference runtime backend, options={default, hf, vllm}"
echo " -m <model_name>: Specify argument the path to load LLM model using FastChat serve API, options={Qwen-7B-Chat, deepseek-llm-7b-chat, ...}"
echo " -t <conv_template>: Specify argument the conversation template according to the LLM model when using FastChat serve API, options={qwen-7b-chat, deepseek-chat, ...}"
echo " -p <tensor_parallel>: Use options {1, 2} to set tensor parallel parameters for vllm backend when using FastChat serve API, default tensor_parallel=1"
echo " -r <gpu_memory_utilization>: Specify argument gpu_memory_utilization (0,1] for vllm backend when using FastChat serve API, default gpu_memory_utilization=0.81"
echo " -h: Display help usage message. For more information, please refer to docs/QAnything_Startup_Usage_README.md"
echo '
| Service Startup Command | GPUs | LLM Runtime Backend | LLM model |
| --------------------------------------------------------------------------------------- | -----|--------------------------| -------------------------------- |
| ```bash ./run.sh -c cloud -i 0 -b default``` | 1 | OpenAI API | OpenAI API |
| ```bash ./run.sh -c local -i 0 -b default``` | 1 | FasterTransformer | Qwen-7B-QAnything |
| ```bash ./run.sh -c local -i 0 -b hf -m MiniChat-2-3B -t minichat``` | 1 | Huggingface Transformers | Public LLM (e.g., MiniChat-2-3B) |
| ```bash ./run.sh -c local -i 0 -b vllm -m MiniChat-2-3B -t minichat -p 1 -r 0.81``` | 1 | vllm | Public LLM (e.g., MiniChat-2-3B) |
| ```bash ./run.sh -c local -i 0,1 -b default``` | 2 | FasterTransformer | Qwen-7B-QAnything |
| ```bash ./run.sh -c local -i 0,1 -b hf -m MiniChat-2-3B -t minichat``` | 2 | Huggingface Transformers | Public LLM (e.g., MiniChat-2-3B) |
| ```bash ./run.sh -c local -i 0,1 -b vllm -m MiniChat-2-3B -t minichat -p 1 -r 0.81``` | 2 | vllm | Public LLM (e.g., MiniChat-2-3B) |
| ```bash ./run.sh -c local -i 0,1 -b vllm -m MiniChat-2-3B -t minichat -p 2 -r 0.81``` | 2 | vllm | Public LLM (e.g., MiniChat-2-3B) |
Note: You can choose the most suitable Service Startup Command based on your own device conditions.
(1) Local Embedding/Rerank will run on device gpu_id_1 when setting "-i 0,1", otherwise using gpu_id_0 as default.
(2) When setting "-c cloud" that will use local Embedding/Rerank and OpenAI LLM API, which only requires about 4GB VRAM (recommend for GPU device VRAM <= 8GB).
(3) When you use OpenAI LLM API, you will be required to enter {OPENAI_API_KEY, OPENAI_API_BASE, OPENAI_API_MODEL_NAME, OPENAI_API_CONTEXT_LENGTH} immediately.
(4) "-b hf" is the most recommended way for running public LLM inference for its compatibility but with poor performance.
(5) When you choose a public Chat LLM for QAnything system, you should take care of a more suitable **PROMPT_TEMPLATE** (/path/to/QAnything/qanything_kernel/configs/model_config.py) setting considering different LLM models.
'
exit 1
}
4.解析命令行参数
解析:这段代码的主要作用是解析命令行参数,并将参数的值赋给相应的变量,这些变量后续可以在脚本中使用。
(1)这段代码是在 Bash 脚本中使用 getopts 函数来解析命令行参数。
(2)getopts 是一个用于解析位置参数的工具。在这个例子中,getopts ":c:i:b:m:t:p:r:h" 表示接受的参数有 -c、-i、-b、-m、-t、-p、-r 和 -h。每个参数后面都跟着一个冒号,表示这个参数需要一个值。
(3)while getopts 循环会依次处理每个参数。每次循环,getopts 会将当前参数的值赋给 opt 变量,如果该参数需要一个值,那么这个值会被赋给 OPTARG 变量。
(4)case $opt in 语句用于根据 opt 的值来执行不同的操作。例如,如果 opt 的值为 c,那么 llm_api=$OPTARG 会被执行,这行代码将参数 c 的值赋给 llm_api 变量。
while getopts ":c:i:b:m:t:p:r:h" opt; do
case $opt in
c) llm_api=$OPTARG ;;
i) device_id=$OPTARG ;;
b) runtime_backend=$OPTARG ;;
m) model_name=$OPTARG ;;
t) conv_template=$OPTARG ;;
p) tensor_parallel=$OPTARG ;;
r) gpu_memory_utilization=$OPTARG ;;
h) usage ;;
*) usage ;;
esac
done
5.接下来的过程
解析:
(1)设置大模型的B数
(2)设置GPUID1和GPUID2
(3)设置USER_IP=localhost
(4)Windows 11支持Qwen-7B-QAnything模型
(5)检测到 Docker Compose 版本
(6)启动docker-compose-windows.yaml
三.docker-compose-windows.yaml
1.etcd服务
解析:
etcd:
container_name: milvus-etcd-local
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
(1)environment
ETCD_AUTO_COMPACTION_MODE=revision:这是自动压缩模式,设置为 `revision`,表示按版本进行自动压缩。
ETCD_AUTO_COMPACTION_RETENTION=1000:这是自动压缩保留的版本数,设置为 1000,表示保留最近的 1000 个版本。
ETCD_QUOTA_BACKEND_BYTES=4294967296:这是后端数据库的配额,以字节为单位。设置为 4294967296,即 4GB,表示后端数据库的最大大小为 4GB。
ETCD_SNAPSHOT_COUNT=50000:这是触发新快照的提交事务数。设置为 50000,表示每当提交的事务数达到 50000 时,就会触发一个新的快照。
(2)volumes
-
${DOCKER_VOLUME_DIRECTORY:-.}是一个Bash参数扩展,它表示如果环境变量DOCKER_VOLUME_DIRECTORY已设置并且非空,那么就使用它的值,否则使用默认值 .(即当前目录)。 -
将宿主机上的
${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd目录,挂载到容器内部的/etcd目录。
(3)command
这段代码是用于配置etcd服务器的命令行参数。etcd是一个分布式键值存储系统,通常用于提供一致性和高可用性的数据存储。下面是对每个参数的解释:
-
-advertise-client-urls:这个参数指定了etcd服务器用于客户端通信的URL。在这个例子中,它被设置为http://127.0.0.1:2379,意味着etcd服务器将通过回环地址(即本地机器的IP地址)上的2379端口接受客户端的连接请求。 -
-listen-client-urls:这个参数定义了etcd服务器监听的客户端请求的URL。这里设置为http://0.0.0.0:2379,表示etcd服务器将监听所有网络接口上的2379端口,允许任何来源的连接。 -
--data-dir:这个参数指定了etcd存储其数据的目录。在这个例子中,数据将被存储在容器内部的/etcd目录下。
综合来看,这个命令是用来启动一个etcd实例,它将在所有网络接口上监听2379端口,接受来自任何IP的客户端连接。使用回环地址(127.0.0.1)上的2379端口作为客户端访问的正式URL。将持久化数据存储在容器内部的/etcd目录。这种配置通常用在Docker容器中,其中-listen-client-urls允许容器外的客户端连接到etcd实例,而-advertise-client-urls提供了一个稳定的URL,以便客户端知道如何连接到etcd实例。--data-dir确保了etcd的数据可以持久化存储,即使容器重启,数据也不会丢失。
(4)healthcheck
这段代码是一个Docker容器中使用的测试命令,通常用于健康检查或验证容器内部服务是否正常运行:
-
"CMD":这是Docker健康检查指令中指定的指令类型。使用CMD意味着接下来的参数将作为一个整体命令来执行。
-
"etcdctl":这是一个命令行工具,用于与etcd服务器进行交互。etcdctl可以用来执行多种操作,如获取etcd集群状态、管理键值对等。
-
"endpoint":这是etcdctl工具的一个子命令,用于指定与etcd集群交互的端点。
-
"health":这是endpoint子命令的一个参数,用于检查etcd集群的健康状况。
将这些元素组合起来,["CMD", "etcdctl", "endpoint", "health"] 定义了一个健康检查命令,该命令使用etcdctl工具来检查etcd服务的健康状况。当这个命令被Docker的健康检查机制执行时,它会返回0(表示健康)或非0值(表示不健康)。如果容器不健康,Docker将根据容器的重启策略采取行动,可能包括重启容器。
2.minio服务
解析:
minio:
container_name: milvus-minio-local
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
# ports:
# - "9001:9001"
# - "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
(1)command
这段代码是用来启动MinIO服务器的命令行指令。MinIO是一个高性能的分布式对象存储服务。下面是对命令及其参数的解释:
-
minio server:这是启动MinIO服务器的命令。 -
/minio_data:这是在宿主机上的一个目录路径,它将被用作MinIO数据的存储位置。当MinIO服务器启动时,它会在这个目录中存储所有数据。在Docker容器环境中,这通常是一个挂载的卷,将容器内部的存储挂载到宿主机的某个目录上。 -
--console-address ":9001":这是MinIO服务器的控制台或管理界面的配置参数。--console-address指定了控制台监听的地址和端口。
整个命令的作用是启动MinIO服务器,使用宿主机上的/minio_data目录作为数据存储,并且设置MinIO控制台在9001端口上可用。这样配置后,用户可以通过浏览器访问http://<host-ip>:9001来使用MinIO的Web界面进行数据管理和监控。
(2)healthcheck
这段代码是Docker容器中定义的健康检查(health check)指令,用于确定容器是否处于健康状态。综合来看,这个健康检查命令会尝试使用curl工具向MinIO服务的健康状况检查端点发送一个请求。如果请求失败(例如,如果MinIO服务没有运行或不可达),健康检查也会失败,Docker会认为容器处于不健康状态。这可以触发Docker根据预设的重启策略尝试重启容器。
在Docker容器的配置中,这个指令通常与HEALTHCHECK指令一起使用:
HEALTHCHECK --interval=30s --timeout=30s --retries=3 \
test ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
-
每30秒执行一次健康检查(--interval=30s)。
-
如果健康检查超过30秒没有响应,则超时(--timeout=30s)。
-
如果连续3次健康检查失败,Docker将认为容器不健康,并根据容器的重启策略采取行动(--retries=3)。
3.milvus服务
解析:
standalone:
container_name: milvus-standalone-local
image: milvusdb/milvus:v2.3.4
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "3"
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
# ports:
# - "19530:19530"
# - "9091:9091"
depends_on:
- "etcd"
- "minio"
(1)logging
-
logging: 这部分是Docker容器日志配置的开始,指定了日志记录的配置项。
-
driver: "json-file":这指定了日志记录的驱动程序。json-file驱动是Docker默认的日志驱动,它会将容器的日志信息以JSON格式存储在磁盘上。
-
options: 这是json-file驱动的配置选项。
-
max-size: "100m":这是一个配置选项,指定了每个日志文件的最大大小。在这个例子中,每个日志文件的大小被限制在100兆字节(M是兆字节的缩写)。当单个日志文件的大小达到这个限制时,Docker会创建一个新的日志文件来继续记录日志。
-
max-file: "3":这也是一个配置选项,指定了保留的日志文件的最大数量。这里设置为3意味着Docker会保留最新的3个日志文件。一旦超过这个数量,最旧的日志文件将被删除以腾出空间给新的日志文件。
(2)command
这个命令用于启动一个名为Milvus的服务,并让它以独立模式运行。Milvus是一个开源的向量数据库,用于嵌入向量的存储、检索和分析。在Docker容器中,这个命令会替换掉容器镜像中默认的启动命令,使得容器启动时直接运行Milvus服务。
(3)security_opt
-
seccomp:是"secure computing"的缩写,它是一个在Linux内核中实现的安全模块,用于控制和限制容器内进程可以进行的系统调用。通过限制容器内的应用能够调用的系统调用,seccomp可以减少容器逃逸攻击的风险。
-
unconfined:是seccomp的一个配置模式,表示容器将不会被限制在系统调用层面。在Docker中,如果一个容器配置为seccomp: unconfined,那么它将能够执行任何系统调用,而不会受到一定程度的限制或过滤。
4.mysql服务
解析:
mysql:
container_name: mysql-container-local
privileged: true
image: mysql
# ports:
# - "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
volumes:
- qanything_mysql_data:/var/lib/mysql
(1)privileged: true
当在Docker容器中设置privileged: true时,容器将获得以下额外的权限:
-
访问所有设备:特权容器可以访问宿主机上的所有设备节点,例如/dev目录下的设备文件。
-
监听所有端口:非特权容器默认只能监听高于1024的端口,而特权容器可以监听所有端口。
-
挂载文件系统:特权容器可以挂载任何文件系统,包括/proc、/sys、/dev等,这些在非特权容器中通常是受限的。
-
操作网络栈:特权容器可以修改宿主机的网络栈,例如添加路由规则或修改网络接口。
-
拥有更多的系统调用:特权容器可以执行一些通常受限的系统调用。
(2)volumes
将名为qanything_mysql_data的数据卷挂载到容器内部的/var/lib/mysql目录。这种配置通常用在Docker容器中运行MySQL数据库时:
-
将MySQL的数据文件存储在数据卷中,而不是容器的临时文件系统中。
-
确保MySQL的数据在容器重启或删除后依然被保留。
-
允许在多个MySQL容器之间共享或迁移数据。
5.qanything服务
解析:
qanything_local:
container_name: qanything-container-local
image: freeren/qanything-win:v1.2.1
# runtime: nvidia
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: "all"
capabilities: ["gpu"]
command: sh -c 'if [ "${LLM_API}" = "local" ]; then /workspace/qanything_local/scripts/run_for_local_option.sh -c $LLM_API -i $DEVICE_ID -b $RUNTIME_BACKEND -m $MODEL_NAME -t $CONV_TEMPLATE -p $TP -r $GPU_MEM_UTILI; else /workspace/qanything_local/scripts/run_for_cloud_option.sh -c $LLM_API -i $DEVICE_ID -b $RUNTIME_BACKEND; fi; while true; do sleep 5; done'
privileged: true
shm_size: '8gb'
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/assets/custom_models:/model_repos/CustomLLM
- ${DOCKER_VOLUME_DIRECTORY:-.}/:/workspace/qanything_local/
ports:
- "5052:5052"
- "8777:8777"
environment:
- NCCL_LAUNCH_MODE=PARALLEL
- GPUID1=${GPUID1:-0}
- GPUID2=${GPUID2:-0}
- MODEL_SIZE=${MODEL_SIZE:-0B}
- USER_IP=${USER_IP:-localhost}
depends_on:
- "standalone"
- "mysql"
tty: true
stdin_open: true
(1)runtime: nvidia
在Docker容器的配置中,runtime: nvidia是用来指定容器应该使用NVIDIA GPU运行时的配置选项。这个选项通常与NVIDIA Docker(现在被集成到Docker 19.03及以上版本中)一起使用,它允许容器访问和利用宿主机上的NVIDIA GPU资源。
(2)shm_size: '8gb'
设置容器的共享内存(Shared Memory)的大小。共享内存是进程间通信(IPC)的一种方式,允许两个或多个进程共享一个给定的内存区域。
(3)tty: true
用于分配一个伪终端(pseudo-TTY)给容器。docker run -it my_image这个命令中:
-
-i 表示以交互式模式运行容器,保持标准输入(STDIN)打开,即使不附加到终端。
-
-t 就相当于在容器的创建命令中设置了 tty: true,它会分配一个TTY。
(4)stdin_open: true
用于控制容器的标准输入(STDIN)是否在容器启动时打开。在Docker中,可以通过在 docker run 命令中添加 -i 标志来设置 stdin_open: true。
(5)command
command: sh -c 'if [ "${LLM_API}" = "local" ]; then /workspace/qanything_local/scripts/run_for_local_option.sh -c $LLM_API -i $DEVICE_ID -b $RUNTIME_BACKEND -m $MODEL_NAME -t $CONV_TEMPLATE -p $TP -r $GPU_MEM_UTILI; else /workspace/qanything_local/scripts/run_for_cloud_option.sh -c $LLM_API -i $DEVICE_ID -b $RUNTIME_BACKEND; fi; while true; do sleep 5; done'
这段代码是Docker容器的command配置,它定义了容器启动时执行的命令。这个命令是一个复杂的shell脚本,用于根据环境变量LLM_API的值来决定执行哪个脚本。下面是对整个命令的解释:
-
command:这是Docker容器配置中用于指定容器启动时要运行的命令的字段。 -
sh -c:这表示使用sh(Shell)来执行后面的命令字符串。-c参数允许传递一个字符串作为Shell命令执行。 -
if [ "${LLM_API}" = "local" ]; then ...; else ...; fi:这是一个条件语句,用于检查环境变量LLM_API的值是否等于"local"。 -
如果
LLM_API等于"local",则执行then部分的命令。 -
如果不等于
"local",则执行else部分的命令。 -
.../run_for_local_option.sh -c $LLM_API -i $DEVICE_ID -b $RUNTIME_BACKEND -m $MODEL_NAME -t $CONV_TEMPLATE -p $TP -r $GPU_MEM_UTILI;:这是当LLM_API等于"local"时执行的脚本及其参数。该脚本可能用于配置和启动一个本地运行的LLM(大型语言模型)服务。参数传递了多个环境变量,这些变量可能用于配置服务。 -
.../run_for_cloud_option.sh -c $LLM_API -i $DEVICE_ID -b $RUNTIME_BACKEND;:这是当LLM_API不等于"local"时执行的脚本及其参数。该脚本可能用于配置和启动一个基于云的LLM服务。 -
while true; do sleep 5; done:这是一个无限循环,用于保持容器运行状态。sleep 5命令使容器在每次循环迭代中暂停5秒。这个循环确保容器不会因为执行完前面的命令而退出,从而保持容器的持续运行。
综上这个命令用于根据LLM_API的值来决定是运行本地模式的LLM服务还是云模式的LLM服务,并在执行完相应的启动脚本后,通过无限循环保持容器活跃。这种方式常用于确保容器作为一个长期运行的服务容器,即使在没有持续操作的情况下也保持运行状态。
(6)deploy
-
deploy: 这是Kubernetes部署(Deployment)配置的开始,它定义了如何部署和管理容器化的应用程序。
-
resources: 这是指定部署所需的计算资源的字段,如CPU、内存和设备。
-
reservations: 在resources内部,reservations用于定义资源的预留要求,以确保部署的Pods有足够资源运行。
-
devices: reservations下的devices字段用于定义需要预留的设备类型和数量。
-
driver: nvidia:这是一个设备定义,指定了设备驱动为nvidia。这告诉Kubernetes调度器,需要预留装有NVIDIA驱动的GPU设备。
-
count: "all":这指定了需要预留的NVIDIA GPU的数量。在这个例子中,"all"意味着应预留集群中所有可用的NVIDIA GPU设备。
-
capabilities: ["gpu"]:这是设备的能力列表,指定了设备应支持的功能。在这里,"gpu"表示设备应具备GPU计算能力。
6.数据卷
解析:
volumes:
qanything_mysql_data:
-
volumes: 这是Docker Compose 文件中定义数据卷的开始。
-
qanything_mysql_data: 这是数据卷的名称。在Docker Compose 文件中定义后,可以在 services 下的对应服务中通过 volumes 选项来引用它。
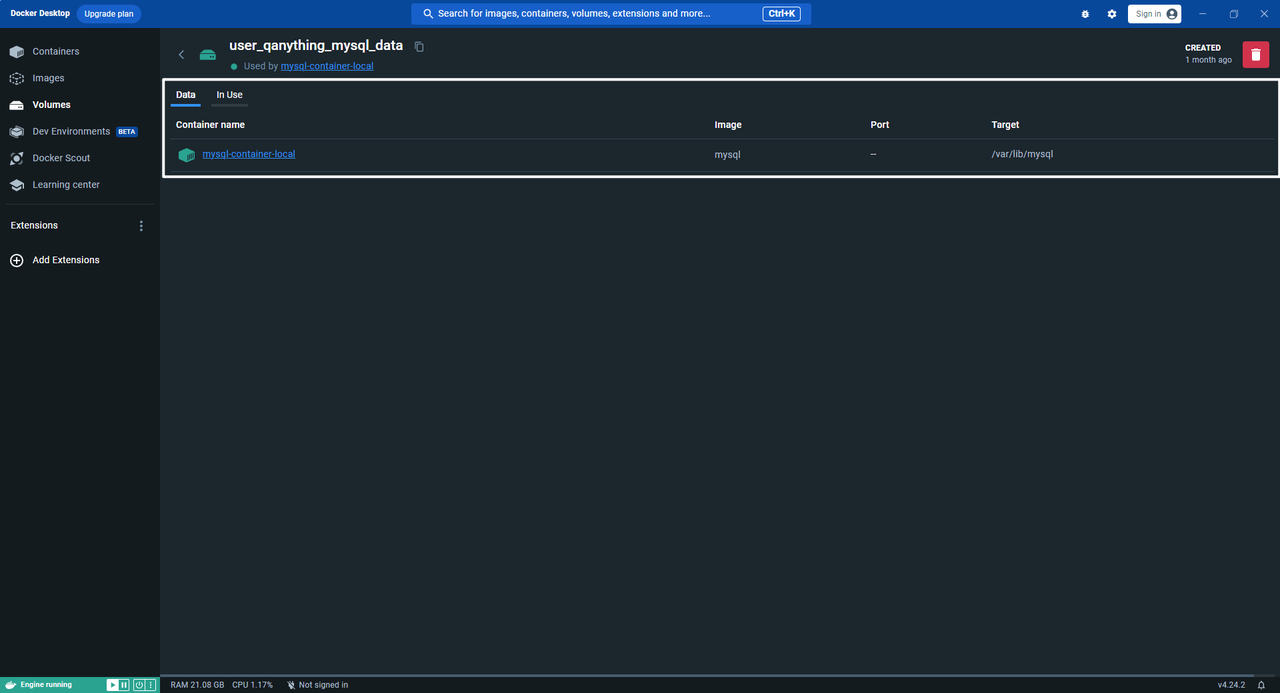
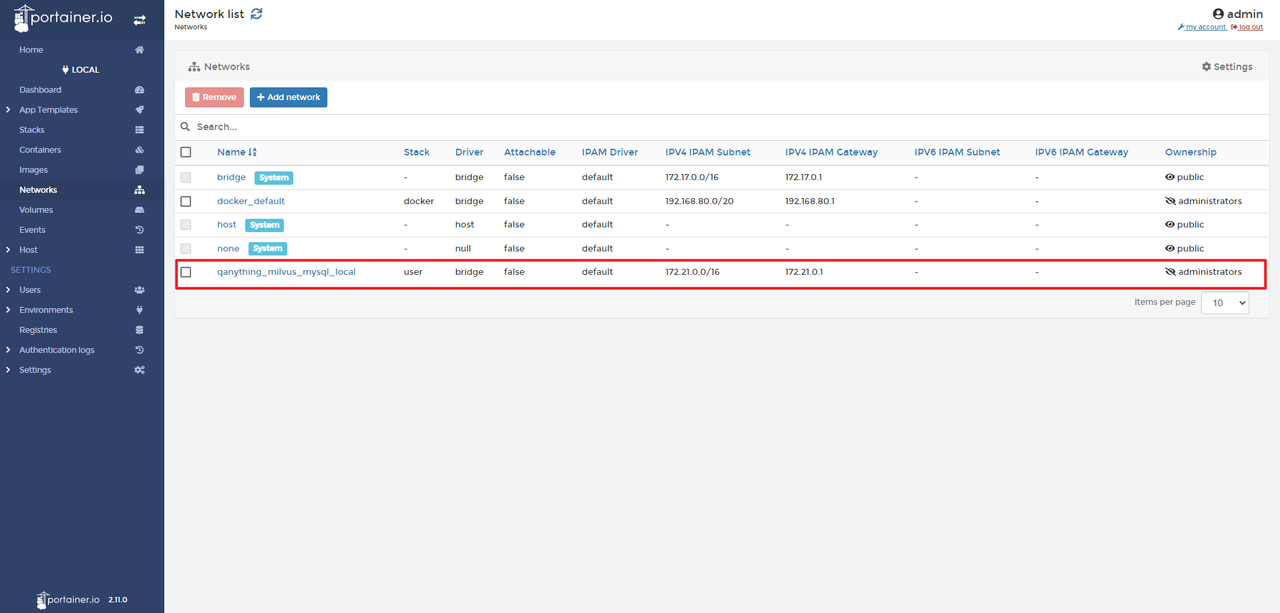
7.默认网络名字
解析:
networks:
default:
name: qanything_milvus_mysql_local
-
networks: 这是Docker Compose文件中定义网络的开始。
-
default: Docker Compose中的服务默认连接到一个名为default的网络。如果不指定服务连接到哪个网络,它将自动使用default网络。
-
name: qanything_milvus_mysql_local 这里为default网络指定了一个自定义名称。在Docker Compose中,网络名称是区分不同网络环境的重要标识。
四.run_for_local_option.sh脚本
1.检查FastChat的MD5
解析:这段shell脚本的功能是检查FastChat文件夹下所有文件的MD5校验和,并与预先保存的默认校验和进行比较。以下是对脚本功能的总结:
(1)获取默认的MD5校验和:脚本从/workspace/qanything_local/third_party/checksum.config文件中读取默认的MD5校验和,将其存储在变量default_checksum中。
(2)计算FastChat文件夹下所有文件的MD5校验和:使用find命令结合md5sum工具计算/workspace/qanything_local/third_party/FastChat目录下所有文件的MD5校验和。计算出的校验和列表通过sort排序,然后再计算这些校验和行的总的MD5校验和,最终结果存储在变量checksum中。
(3)输出校验和:脚本打印出计算得到的checksum和默认的default_checksum,以便于用户或开发者进行查看或调试。
(4)检查校验和是否一致:使用if语句比较default_checksum和checksum。如果两者不相等,意味着FastChat目录下的文件发生了变化。
(5)重新安装依赖:如果校验和不相等,脚本会进入/workspace/qanything_local/third_party/FastChat目录,并使用pip install -e .命令重新安装该目录下的所有Python依赖。这通常用于当源代码发生变化时,需要重新安装以反映这些变化。
(6)更新默认校验和:重新计算安装依赖后的MD5校验和,并将新计算出的校验和写入/workspace/qanything_local/third_party/checksum.config文件中,更新默认校验和。
2.检查vllm依赖是否安装
(1)使用pip list | grep vllm命令检查vllm依赖是否已经安装在Python环境中。
(2)如果没有找到vllm(即install_deps变量为空或者不包含vllm),则打印出"vllm deps not found"。
3.安装FastChat依赖并更新校验和
(1)如果vllm依赖未找到,脚本会进入FastChat目录,并使用pip install -e .命令安装当前目录下的Python包。
(2)然后重新计算该目录下所有文件的MD5校验和,并将新校验和写入checksum.config文件中。
4.创建模型仓库和日志目录
(1)使用mkdir -p命令创建所需的目录结构,包括模型仓库和日志目录。-p参数确保了即使父目录不存在,也能创建完整的路径。
5.设置符号链接
(1)脚本检查QAEnsemble_base和QAEnsemble_embed_rerank目录中是否已经存在名为base、rerank和embed的符号链接。
(2)如果这些符号链接不存在,脚本会在QAEnsemble_base和QAEnsemble_embed_rerank目录下创建它们,分别指向/model_repos/QAEnsemble/base、/model_repos/QAEnsemble/rerank和/model_repos/QAEnsemble/embed。
6.默认后端选择
默认后端为FasterTransformer,仅支持Nvidia RTX 30系列或40系列显卡。还可以选择vllm和hf后端。
7.根据GPU显存和模型尺寸提供建议
(1)检查显存大小:脚本首先检查环境变量GPU1_MEMORY_SIZE的值,这个值代表第一个GPU的显存大小(单位是MiB)。
(2)显存小于4GB:如果显存小于4GB,脚本会建议用户升级显卡,因为当前显存不足以部署项目,并退出程序。
(3)使用OpenAI API:如果显存大小为0B(表示使用在线的OpenAI API),脚本会打印出当前显存可以使用OpenAI API。
(4)显存小于8GB:如果显存在4GB到8GB之间,脚本推荐使用在线的OpenAI API,并且如果模型大小超过显存容量,脚本会提示用户重新选择模型大小,并退出。
(5)显存在8GB到10GB之间:对于8GB到10GB的显存,推荐部署1.8B的大模型,并包括使用OpenAI API。如果模型大小超过2B,脚本会提示用户显存不足,并退出。
(6)显存在10GB到16GB之间:对于10GB到16GB的显存,推荐部署3B及3B以下的模型,并包括使用OpenAI API。如果模型大小超过3B,脚本会提示用户显存不足,并退出。
(7)显存在16GB到22GB之间:对于16GB到22GB的显存,推荐部署小于等于7B的大模型。根据使用的后端(Qwen-7B-QAnything+FasterTransformer、Huggingface Transformers、VLLM),脚本会设置不同的tokens上限以避免显存溢出,并退出如果模型大小不兼容。
(8)显存在22GB到25GB之间:对于22GB到25GB的显存,推荐部署7B模型。如果模型大小超过7B,脚本会提示用户显存不足,并退出。
(9)显存大于25GB:对于大于25GB的显存,脚本不会设置tokens上限。
脚本中还包含了一些逻辑来处理不同后端(如default、hf、vllm)的特定情况,并根据这些后端和显存大小来设置OFFCUT_TOKEN环境变量,这个变量可能用于控制程序中的某些内存限制。
8.核心服务启动过程
大模型中转服务已就绪 (1/8)
rerank服务已就绪 (2/8)
OCR服务已就绪 (3/8)
qanything后端服务已就绪 (4/8)
Dependencies related to npm are obtained (5/8)
[npm run build] build successfully (6/8)
前端服务已就绪 (7/8)
Embedding和Rerank服务已准备就绪 (7.5/8)
LLM 服务已准备就绪,现在您可以使用qanything服务 (8/8)
说明:run_for_cloud_option.sh不再讲解。
五.启动的容器
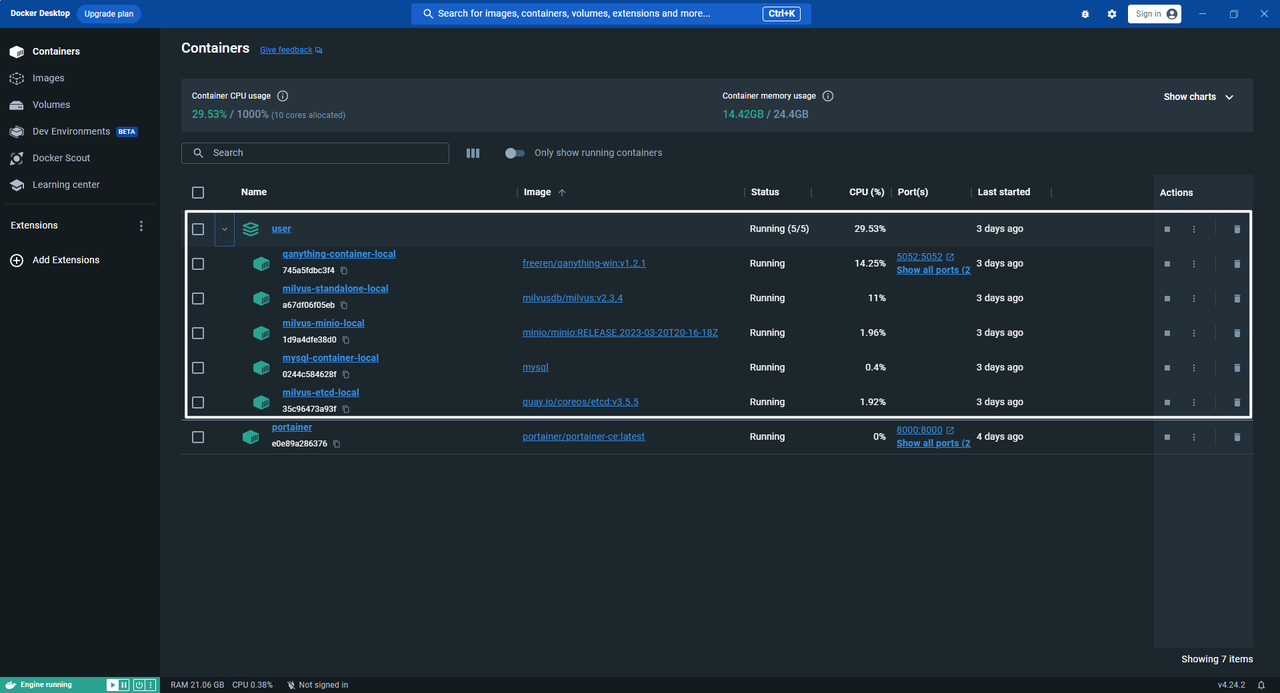
1.qanything-container-local
这个容器运行 QAnything 服务,这是一个基于深度学习的问答系统。它可以处理各种类型的文件和数据,并提供问答功能。这个容器依赖于 "standalone" 和 "mysql" 容器。
2.milvus-standalone-local
这个容器运行 Milvus 服务,Milvus 是一个开源的向量数据库,用于处理大规模的向量数据。它提供了高效的向量索引和查询功能。这个容器依赖于 "etcd" 和 "minio" 容器。
3.milvus-minio-local
这个容器运行 MinIO 服务,MinIO 是一个高性能的对象存储服务,用于存储和管理大量的非结构化数据,如图片、视频、日志文件等。
4.mysql-container-local
这个容器运行 MySQL 服务,MySQL 是一个关系型数据库管理系统,用于存储和管理结构化数据。
5.milvus-etcd-local
这个容器运行 etcd 服务,etcd 是一个分布式键值存储系统,用于共享配置和服务发现。
标签:容器,container,启动,qanything,QAnything,API,LLM,解析,local From: https://www.cnblogs.com/shengshengwang/p/18279020