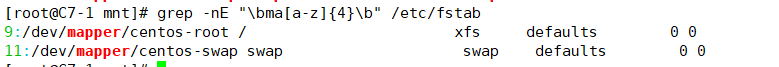正则表达式
目录一、正则表达式的概述
1、概念
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
2、作用
通常用于判断语句中,用来检查某一字符串是否满足某一格式
• 正则表达式是由普通字符与元字符组成
• 普通字符包括大小写字母、数字、标点符号及一些其他符号
• 元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
3、可达到的目的
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”)
- 可以通过正则表达式,从字符串中获取我们想要的特定部分
二、基础正则
1、字符匹配元字符
| 元字符 | 意义 |
|---|---|
| . | 匹配任意单个字符 |
| [] | 匹配指定范围内的任意单个字符,如:[0-9]匹配到的就是0至9中的任意一个数字 |
| [^] | 匹配指定范围外的任意单个字符,如:[ ^35]匹配到的就是除了含3和5的其他数字 |
| [:alnum:] | 字母和数字,即[0-9a-Za-z] |
| [:alpha:] | 代表任何英文大小写字符,即[a-Za-z] |
| [:lower:] | 小写字母,示例:[[:lower:]],相当于[a-z] |
| [:upper:] | 大写字母,[[:upper:]]相当于[A-Z] |
| [:blank:] | 空白字符(空格和制表符) |
| [:space:] | 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广 |
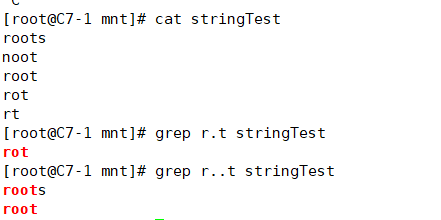
1.2、实例
1.2.1 . ( 匹配任意单个字符)
1.2.2 [] (匹配指定范围内的任意单个字符)

1.2.3 [^]匹配指定范围外的任意单个字符

2、表示次数的元字符
| 元字符 | 功能 |
|---|---|
| * | 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配 |
| .* | 任意长度的任意字符,不包括0次 |
| ? | 匹配其前面的字符出现0次或1次,即:可有可无 |
| + | 匹配其前面的字符出现最少1次,即:肯定有且大于等于1次 |
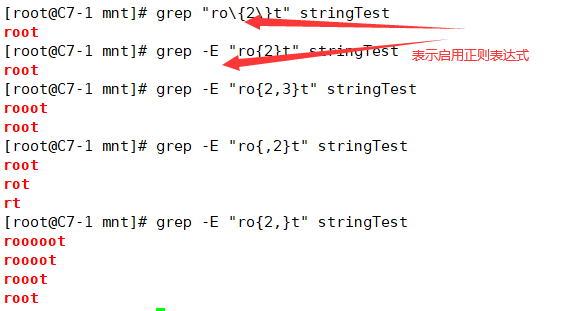
| 匹配前面的字符n次 | |
| 匹配前面的字符至少m次,至多n次 | |
| 匹配前面的字符至多n次,<=n | |
| 匹配前面的字符至少n次 |
2.1 实例
2.1.1 *

2.1.2 .*

2.1.3 ?

2.1.4 +

2.1.5 {}
3、表示位置锚定
| 元字符 | 功能 |
|---|---|
| ^ | 行首锚定,用于模式的最左侧 |
| $ | 行尾锚定,用于模式的最右侧 |
| ^PATTERN$ | 用于模式匹配整行(^root$表示单独一行只有root) |
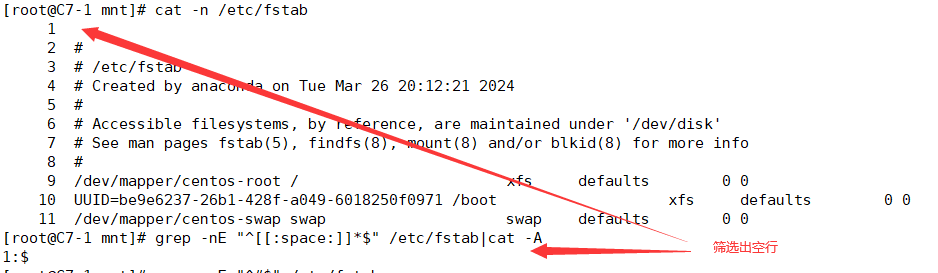
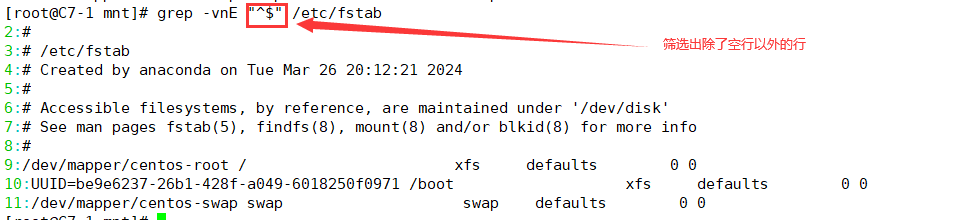
| ^$ | 空行,不包含空格行 |
| [1]*$ | 空白行 |
| \b,< | 词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部 |
| \b,> | 词尾锚定,用于单词模式的右侧 |
3.1实例
3.1.1 [2]*$
3.1.2 和PATTERN$
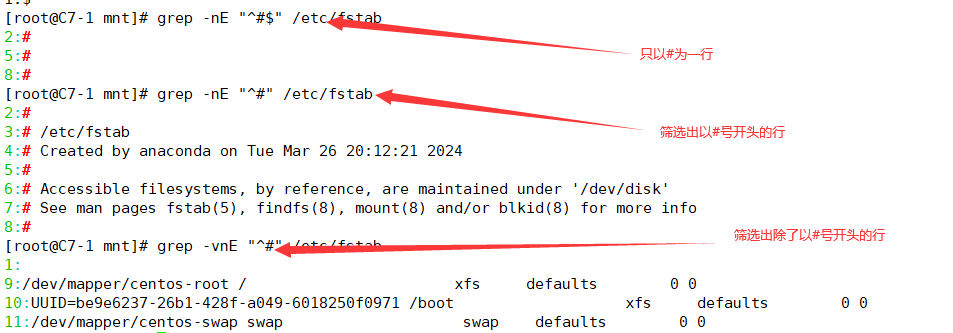
3.1.3 ^$
3.1.4 /b/b