1. 网络爬虫的类型
现在我们已经基本了解了网络爬虫的组成,那么网络爬虫具体有哪些类型呢?
网络爬虫按照实现的技术和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型。在实际的网络爬虫中,通常是这几类爬虫的组合体。
1.1 通用网络爬虫
首先我们为大家介绍通用网络爬虫(General Purpose Web Crawler)。通用网络爬虫又叫作全网爬虫,顾名思义,通用网络爬虫爬取的目标资源在全互联网中。
通用网络爬虫所爬取的目标数据是巨大的,并且爬行的范围也是非常大的,正是由于其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是非常高的。这种网络爬虫主要应用于大型搜索引擎中,有非常高的应用价值。
通用网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等构成。通用网络爬虫在爬行的时候会采取一定的爬行策略,主要有深度优先爬行策略和广度优先爬行策略。
1.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网络爬虫,顾名思义,聚焦网络爬虫是按照预先定义好的主题有选择地进行网页爬取的一种爬虫,聚焦网络爬虫不像通用网络爬虫一样将目标资源定位在全互联网中,而是将爬取的目标网页定位在与主题相关的页面中,此时,可以大大节省爬虫爬取时所需的带宽资源和服务器资源。
聚焦网络爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价出链接的重要性,然后根据链接和内容的重要性,可以确定哪些页面优先访问。
聚焦网络爬虫的爬行策略主要有4种,即基于内容评价的爬行策略、基于链接评价的爬行策略、基于增强学习的爬行策略和基于语境图的爬行策略。关于聚焦网络爬虫具体的爬行策略,我们将在下文中进行详细分析。

1.3 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。
增量式更新指的是在更新的时候只更新改变的地方,而未改变的地方则不更新,所以增量式网络爬虫,在爬取网页的时候,只爬取内容发生变化的网页或者新产生的网页,对于未发生内容变化的网页,则不会爬取。
增量式网络爬虫在一定程度上能够保证所爬取的页面,尽可能是新页面。
1.4 深层网络爬虫
深层网络爬虫(Deep Web Crawler),可以爬取互联网中的深层页面,在此我们首先需要了解深层页面的概念。
在互联网中,网页按存在方式分类,可以分为表层页面和深层页面。所谓的表层页面,指的是不需要提交表单,使用静态的链接就能够到达的静态页面;而深层页面则隐藏在表单后面,不能通过静态链接直接获取,是需要提交一定的关键词之后才能够获取得到的页面。
在互联网中,深层页面的数量往往比表层页面的数量要多很多,故而,我们需要想办法爬取深层页面。
爬取深层页面,需要想办法自动填写好对应表单,所以,深层网络爬虫最重要的部分即为表单填写部分。
深层网络爬虫主要由URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部分构成。
深层网络爬虫表单的填写有两种类型:
- 第一种是基于领域知识的表单填写,简单来说就是建立一个填写表单的关键词库,在需要填写的时候,根据语义分析选择对应的关键词进行填写;
- 第二种是基于网页结构分析的表单填写,简单来说,这种填写方式一般是领域知识有限的情况下使用,这种方式会根据网页结构进行分析,并自动地进行表单填写。
以上,为大家介绍了网络爬虫中常见的几种类型,希望读者能够对网络爬虫的分类有一个基本的了解。
2. 爬虫扩展——聚焦爬虫
由于聚焦爬虫可以按对应的主题有目的地进行爬取,并且可以节省大量的服务器资源和带宽资源,具有很强的实用性,所以在此,我们将对聚焦爬虫进行详细讲解。图1-2所示为聚焦爬虫运行的流程,熟悉该流程后,我们可以更清晰地知道聚焦爬虫的工作原理和过程。
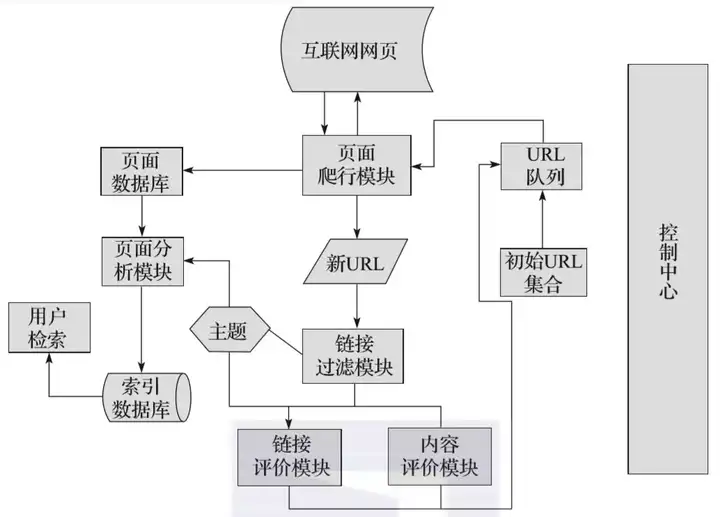
▲图2-2 聚焦爬虫运行的流程
首先,聚焦爬虫拥有一个控制中心,该控制中心负责对整个爬虫系统进行管理和监控,主要包括控制用户交互、初始化爬行器、确定主题、协调各模块之间的工作、控制爬行过程等方面。
然后,将初始的URL集合传递给URL队列,页面爬行模块会从URL队列中读取第一批URL列表,然后根据这些URL地址从互联网中进行相应的页面爬取。
爬取后,将爬取到的内容传到页面数据库中存储,同时,在爬行过程中,会爬取到一些新的URL,此时,需要根据我们所定的主题使用链接过滤模块过滤掉无关链接,再将剩下来的URL链接根据主题使用链接评价模块或内容评价模块进行优先级的排序。完成后,将新的URL地址传递到URL队列中,供页面爬行模块使用。
另一方面,将页面爬取并存放到页面数据库后,需要根据主题使用页面分析模块对爬取到的页面进行页面分析处理,并根据处理结果建立索引数据库,用户检索对应信息时,可以从索引数据库中进行相应的检索,并得到对应的结果。
这就是聚焦爬虫的主要工作流程,了解聚焦爬虫的主要工作流程有助于我们编写聚焦爬虫,使编写的思路更加清晰。
02 网络爬虫技能总览
在上文中,我们已经初步认识了网络爬虫,那么网络爬虫具体能做些什么呢?用网络爬虫又能做哪些有趣的事呢?在本章中我们将为大家具体讲解。
标签:4.10,URL,爬行,网络,爬虫,聚焦,页面 From: https://www.cnblogs.com/binglinll/p/18255064