Image Segmentation Using Text and Image Prompts论文阅读笔记
摘要
对于传统的分割方法,训练好后如果需要纳入新的类别,带来的成本是很高的。因此作者提出了一个系统,可以在测试时根据任意的提示生成图像分割,一个提示可以是一个文本或一个图像,这样也就为zero-shot,one-shot等任务创建了一个统一的模型。本文以 CLIP 模型为骨干,使用基于Transformer的解码器进行扩展,以实现密集预测。
要注意这个方法的输出是每个像素属于提示类别的概率,如果设置一个阈值的话得到的就是一个二值图因此用的损失是torch.nn.functional.binary_cross_entropy_with_logits。
方法
Decoder Architecture
基于Transformer的decoder具有类似UNet的skip connection接到encoder上。Decoder通过在其Transformer最后一层token上应用线性投影生成二进制的分割结果。为了利用visual prompt或者text prompt,对于decoder的输入还需要借助FiLM通过条件向量进行优化。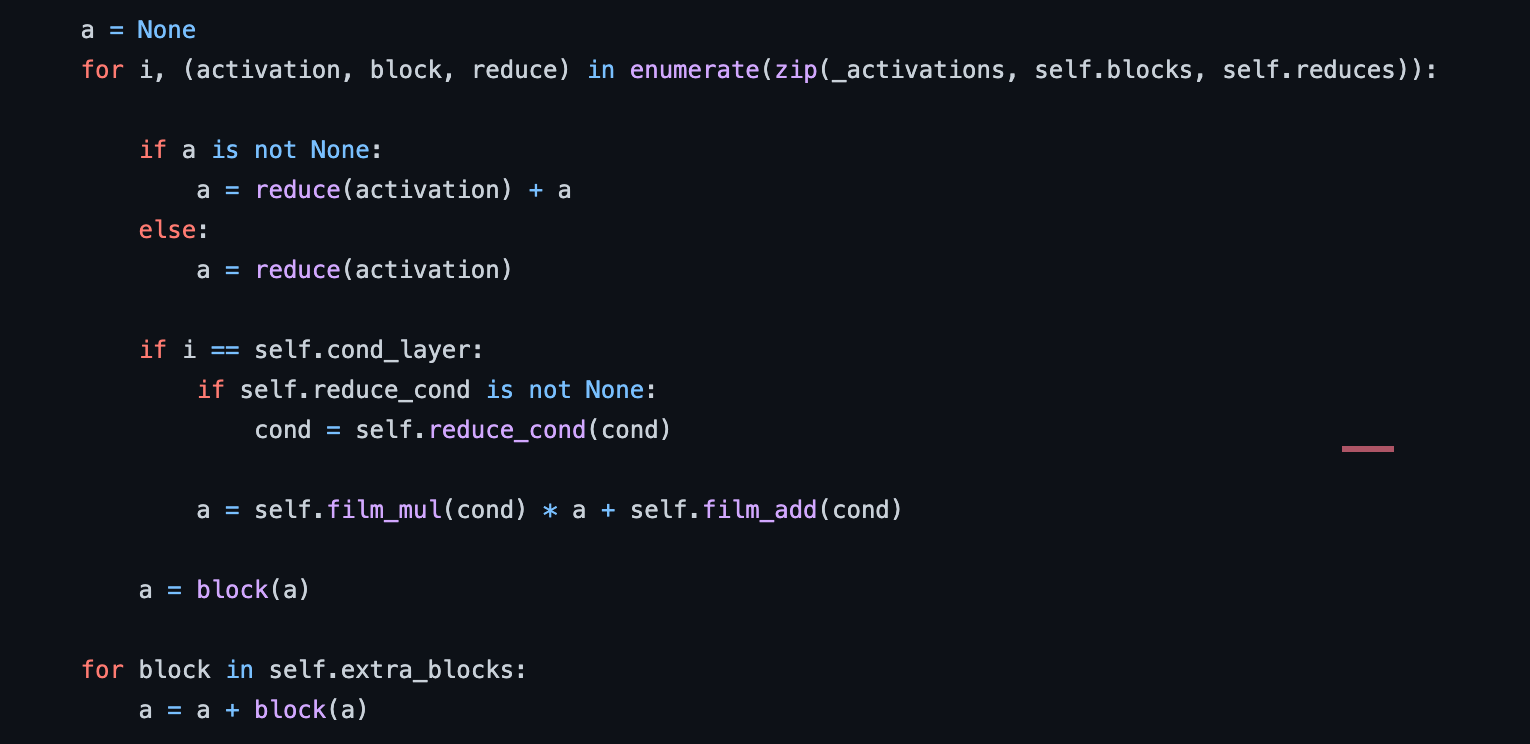
这里做的实际上就是\(y=mx+b\)的变换(https://staging.distill.pub/2018/feature-wise-transformations/)。
其中film_mul:
film_add是和film_mul一样的fc层。
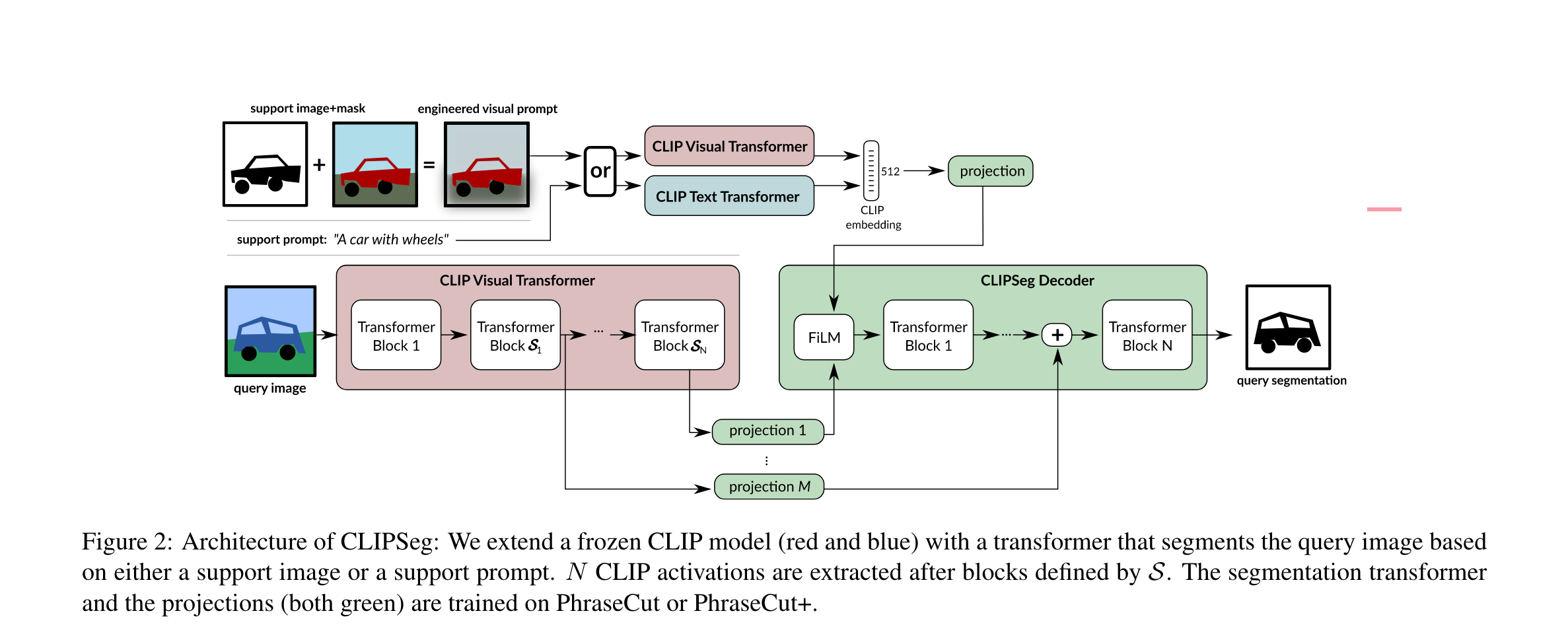
如图所示,有两种方法得到这个条件向量,第一种和CLIP一样,利用text-transformer对文本提示进行编码;第二种是使用CLIP的visual transformer对engineered visual prompt进行编码。这里的engineered visual prompt就是用mask去提取出对应类别的像素,将其他像素掩蔽。同时文章提出的方法通过对positional embedding插值,从而允许任意大小的图片输入。
Image-Text Interpolation
模型从上文提到的条件向量获取到的信息是“要分割的是什么”。这个条件向量可以从文本也可以从图像得到。因为CLIP中图像和文本的embedding space大小是相同的,可以通过插值的方式实现。这里没有太懂论文说的是什么意思,文章给出了公式\(x_i=as_i+(1-a)x_i\),但这是插值吗?这又怎么控制张量大小?
PhraseCut + Visual prompts (PC+)
文章使用的是PhraseCut数据集,包含三十四万个短语以及对应的图片分割,但并没有相应的视觉支持样本。因此作者对数据集进行了扩充,添加了视觉支持样本和负样本。为了为prompt p 添加视觉支持图像,作者从共享prompt p 的所有样本Sp的集合中随机抽取。作者还将负样本加入数据集,即没有对象与prompt匹配的样本。为此,样本的短语被替换为概率为\(q_{neg}\)的不同短语。短语使用一组固定前缀随机扩充。在考虑到对象位置的情况下,作者在图像上应用随机裁剪,确保对象至少部分可见。在本文的其余部分,将此扩展数据集称为 PhraseCut+(缩写为 PC+)。
Visual Prompting Engineering
CLIP Based Masking
这里作者主要是说模型内部结合图像和mask(ViT中使用Masked Pooling)需要更复杂的策略。限制与CLS的交互带来的提升比较小,而限制所有交互则会明显掉点。

Visual Prompt Engineering
可以将图像与mask结合得到新的图像,然后送入Visual Transformer进行处理,这和NLP中的Prompting很类似。作者对比了不同的方式,如下:

方式包括:降低背景亮度,对背景进行高斯滤波,裁剪等以及这些方式的组合。这里的概率计算方式是,首先将类别名送入CLIP的text encoder,然后与这些embedding后的visual prompt计算相似度并进行softmax。
实验
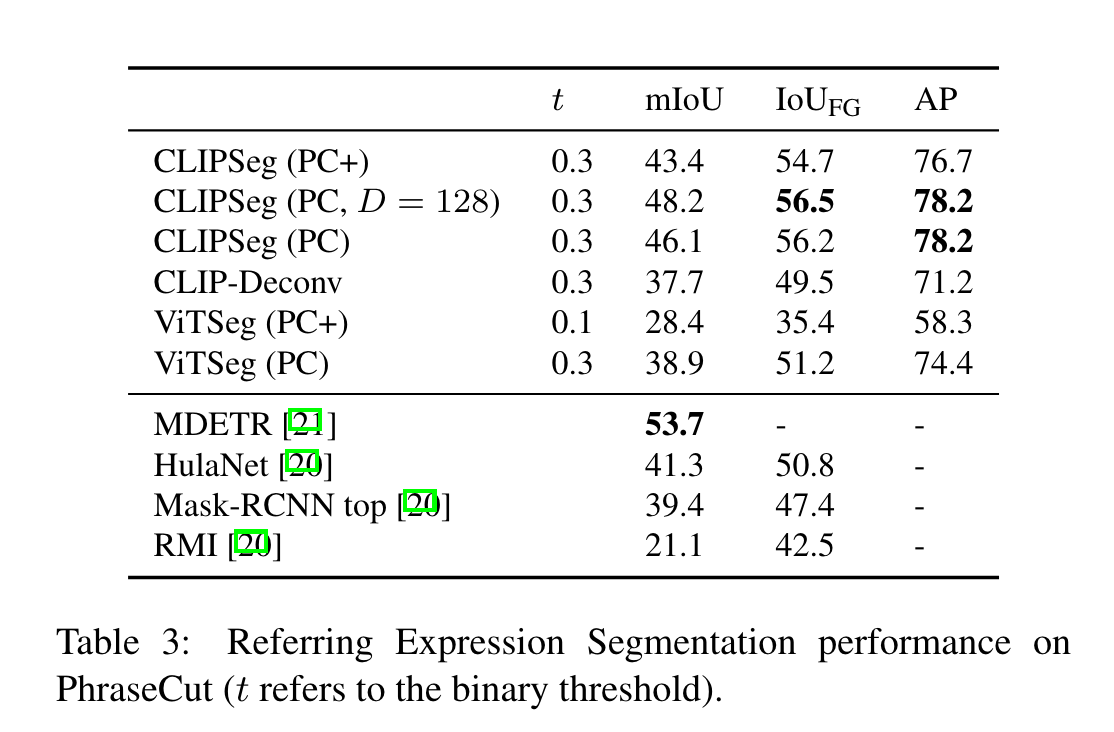
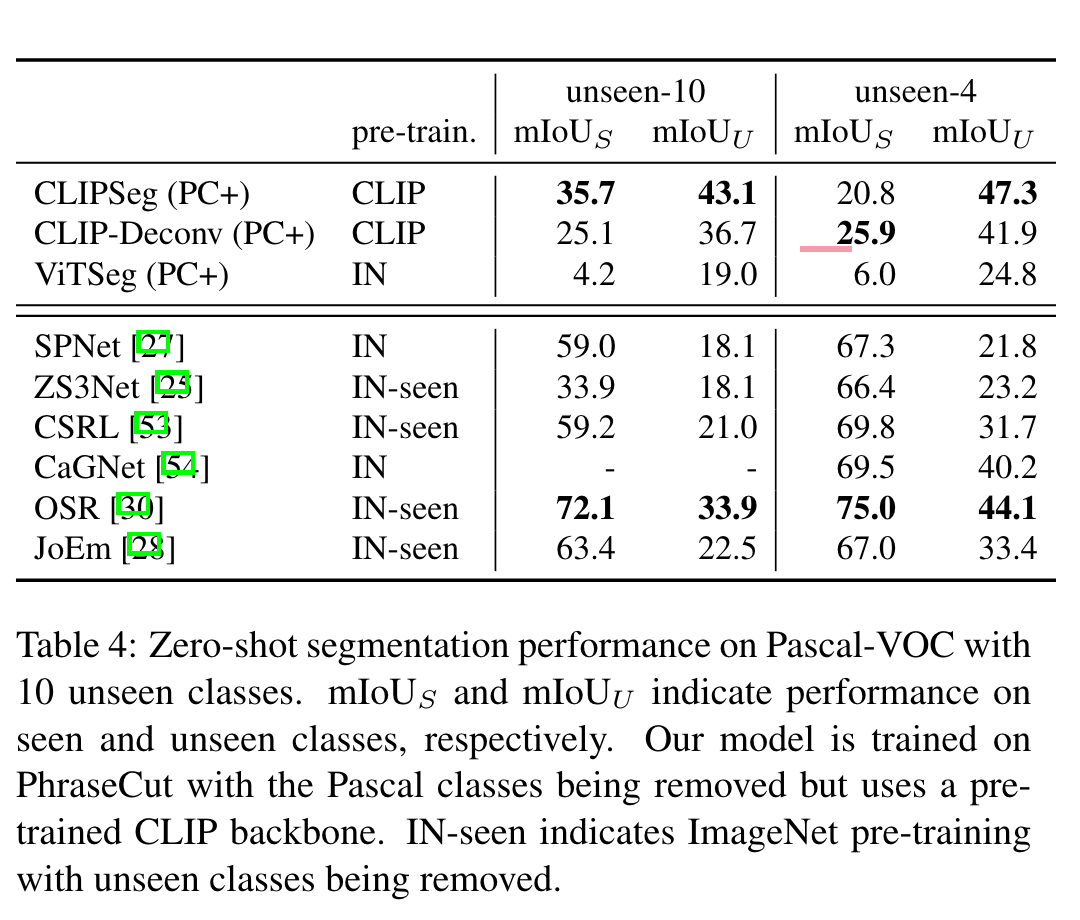
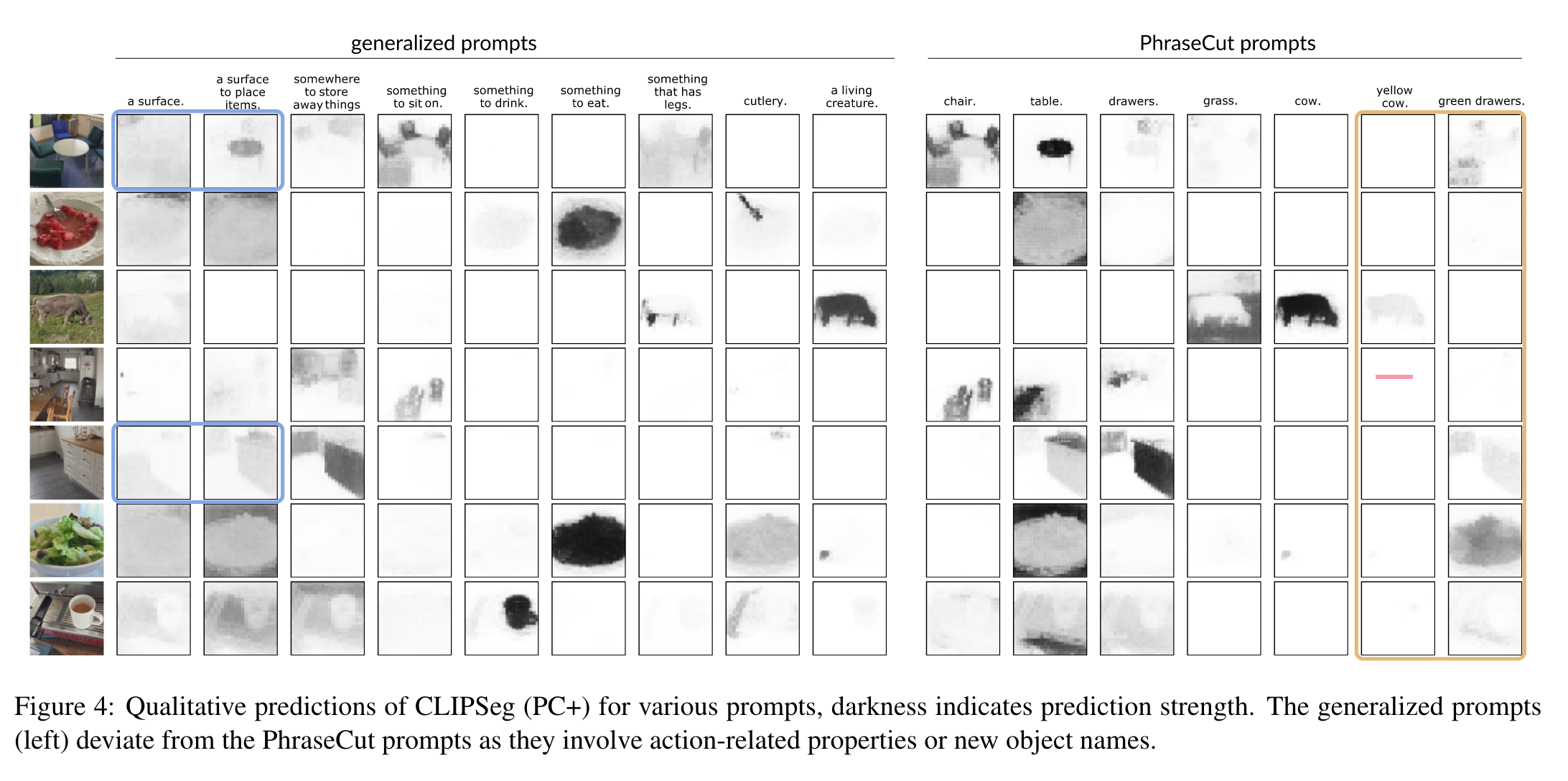
上面的图是使用不同prompt预测结果的可视化。左边是更加广义的prompt,右边是来自PhraseCut数据集的提示。
参考:https://zhuanlan.zhihu.com/p/538329106
标签:Segmentation,prompt,CLIP,Text,Image,样本,visual,图像 From: https://www.cnblogs.com/lipoicyclic/p/16805708.html