Motivation & Abs
Motivation:之前基于LLM的通用助手仅能处理文本。
数据:使用纯语言的GPT4生成多模态语言-图像指令数据。
模型:基于生成数据端到端训练的模型LLaVA,用于通用视觉语言理解。
指标:两个benchmark。
GPT-assisted Visual Instruction Data Generation
现有的多模态指令数据集往往很小,原因在于构建这样的数据集相当耗时,同时缺少较好的定义。因此作者考虑使用C ha t GPT/GPT4来构建相应的数据(基于现有的图像文本对)。
对于一张图像\(X_v\)以及与之关联的caption \(X_c\),我们可以很自然地构建一系列的问题\(X_q\),目的是指导助手描述图像内容。作者提示GPT-4以生成一系列的问题,因此一个简单的扩充图像文本对为指令跟随的方式是:
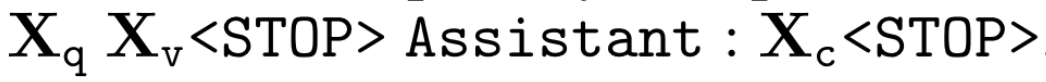
但这种简单的方式会导致指令以及回答的多样性 / 推理深度的缺失。为解决这个问题,作者使用ChatGPT / GPT4(仅利用其语言能力)作为一个强的教师模型生成包含视觉内容的指令跟随数据。为了将图像编码为视觉特征送入text-only GPT,作者使用了两种不同形式的表示:(1)Captions以及(2)Bounding boxes,这种表示可以使图像被编码为LLM能够识别的序列。作者使用了COCO的图像,同时生成了三种指令跟随数据:Conversation,Detailed description以及Complex reasonging。

Visual Instruction Tuning
Architecture
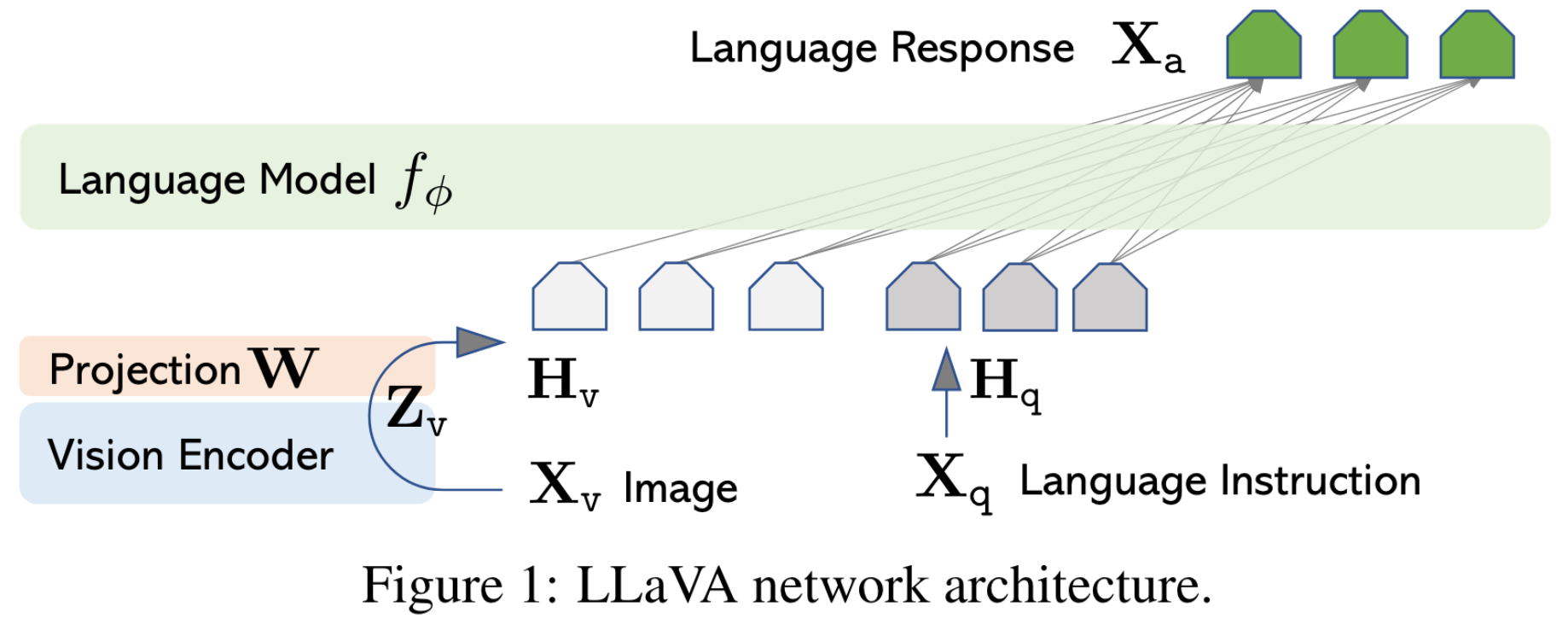
LLM使用的是Vicuna,视觉encoder使用的是CLIP的ViT-L/14, 通过一个简单的线性层将图像特征投影到word embedding space。
Training
对于每一个图像\(X_v\),作者生成多轮对话数据\(X_q^1,X_a^1...X_q^T,X_a^T\)。指令构建:
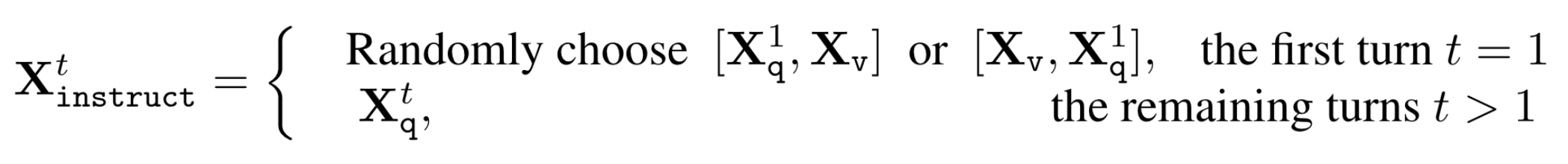
对于预测token使用instruction-tuning,优化目原始的自回归目标:
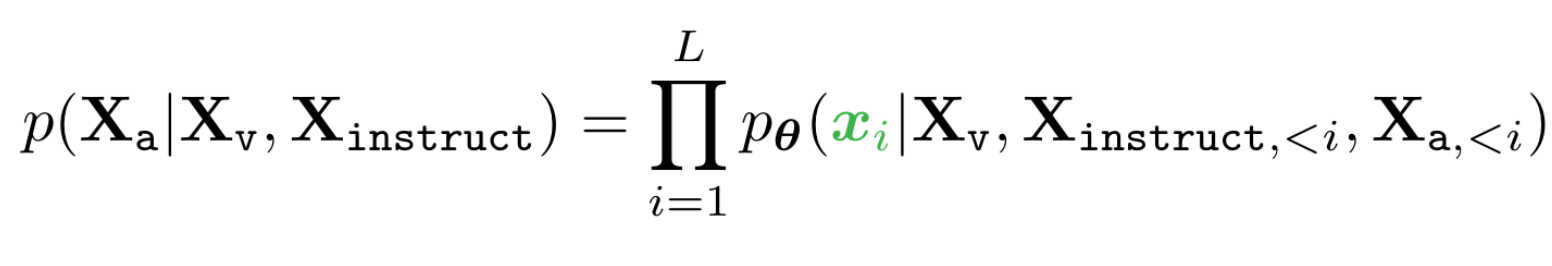
两阶段指令微调过程:
Stage 1: Pre-training for Feature Alignment. 在这一阶段只训练线性层,使用的数据为图像以及对应的original caption(GT)。每个训练样本可以被视为单轮对话。
Stage 2: Fine-tuning End-to-End. 第二阶段冻结视觉encoder,训练投影层和LLM。
实验
需要注意的是,定量实验中,作者使用GPT4评估生成的质量(helpfulness, relevance, accuracy, and level of detail of the responses)。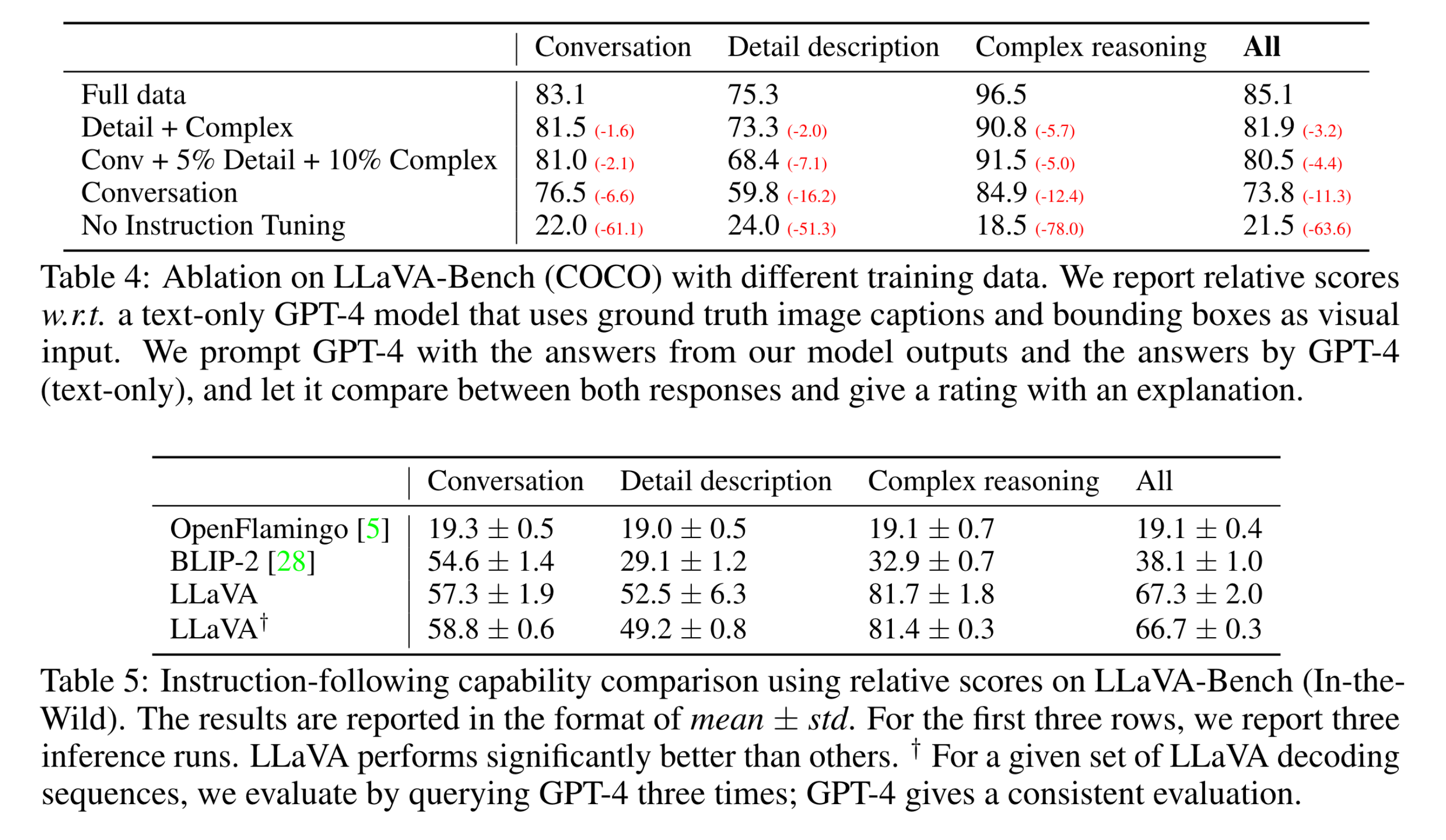
两个benchmark:
