hadoop3.2.3+flink1.13.0+hbase2.4.8集群搭建
hadoop3.2.3+flink1.13.0+hbase2.4.8集群搭建
1.准备 3台centos7 服务器
配置hosts(可能需要重启才生效)
/etc/hosts
192.168.10.209 master
192.168.10.155 slave1
192.168.10.234 slave2
- 1
- 2
- 3
- 4
- 5
- 6
免密登录
ssh-keygen -t rsa
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
- 1
- 2
- 3
- 4
关闭防火墙 :
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
- 1
- 2
yum install ntpdate -y
ntpdate ntp1.aliyun.com
- 1
- 2
卸载自带openjdk
rpm -qa|grep java
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.242.b08-1.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.251-2.6.21.1.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.251-2.6.21.1.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64
- 1
- 2
- 3
- 4
- 5
2.安装jdk
tar zxvf jdk-8u161-linux-x64.tar.gz -C /export/server/
- 1
配置java环境变量
vim /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_161
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib
source /etc/profile
- 1
- 2
- 3
- 4
- 5
3.安装zookeeper
tar zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /export/server/
- 1
配置zk环境变量
vim /etc/profile
export PATH=$PATH:/export/server/apache-zookeeper-3.8.0-bin/bin
source /etc/profile
- 1
- 2
- 3
复制配置文件
cd /export/server/apache-zookeeper-3.8.0-bin/conf
cp zoo_sample.cfg zoo.cfg
- 1
- 2
创建zk数据存储目录
mkdir -p /export/data/zookeeper-3.8.0
- 1
编辑zoo.cfg配置文件
vim zoo.cfg
dataDir=/export/data/zookeeper-3.8.0
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
- 1
- 2
- 3
- 4
- 5
添加myid配置
/export/data/zookeeper-3.8.0路径下创建一个文件,文件名为myid ,文件内容为1
echo 1 > /export/data/zookeeper-3.8.0/myid
- 1
安装包分发并修改myid的值
第一台机器上面执行以下两个命令
scp -r /export/server/apache-zookeeper-3.8.0-bin root@slave1:/export/server/
scp -r /export/server/apache-zookeeper-3.8.0-bin root@slave2:/export/server/
- 1
- 2
第二台机器上修改myid的值为2
直接在第二台机器任意路径执行以下命令
echo 2 > /export/data/zookeeper-3.8.0/myid
- 1
第三台机器上修改myid的值为3
直接在第三台机器任意路径执行以下命令
echo 3 > /export/data/zookeeper-3.8.0/myid
- 1
三台机器启动zookeeper服务
三台机器都要执行
/bin/zkServer.sh start
- 1
#查看启动状态
/bin/zkServer.sh status
- 1
4.安装hadoop
tar zxvf hadoop-3.2.3.tar.gz -C /export/server/
- 1
配置hadoop
cd /export/server/hadoop-3.2.3/etc/hadoop/ vim core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> <description>表示HDFS的基本路径</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-3.2.3</value> <description>Abase for other temporary directories.</description> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
vim hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9868</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/export/server/hadoop-3.2.3/share/hadoop/mapreduce/*, /export/server/hadoop-3.2.3/share/hadoop/mapreduce/lib/*</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
vim yarn-site.xml<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property><property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property><property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1600</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property><property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
vim workers
master
slave1
slave2
- 1
- 2
- 3
- 4
- 5
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.2.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
- 1
- 2
- 3
- 4
namenode 格式化
hdfs namenode -format
- 1
hadoop 集群启动命令
start-all.sh
stop-all.sh
- 1
- 2
5.安装hbase
tar -zxvf hbase-2.4.8-bin.tar.gz -C /export/server/
- 1
修改 conf 目录 hbase-env.sh 文件
vim hbase-env.sh
export JAVA_HOME=/export/server/jdk1.8.0_161
export HBASE_MANAGES_ZK=false
source /etc/profile
- 1
- 2
- 3
- 4
修改hbase-site.xml文件
vim hbase-site.xml
- 1
修改或者直接增加以下内容:
<configuration> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,slave1,slave2:2181</value> </property> <property> <name>hbase.rootdir</name> <value>hdfs://master:8020/hbase</value> </property> <property> <name>hbase.tmp.dir</name> <value>./tmp</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
修改 regionservers
vim regionservers
master
slave1
slave2
- 1
- 2
- 3
- 4
分发
scp -r /export/server/hbase-2.4.8/ root@slave1:/export/server/
scp -r /export/server/hbase-2.4.8/ root@slave2:/export/server/
- 1
- 2
修改环境变量
vim /etc/profile
export HBASE_HOME=/export/server/hbase-2.4.8/
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
- 1
- 2
- 3
- 4
分发
scp -r /etc/profile root@slave1:/etc/profile
scp -r /etc/profile root@slave2:/etc/profile
- 1
- 2
- 3
在slave1和slave2上执行
source /etc/profile
- 1
启动
start-hbase.sh
- 1
6.安装flink
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /export/server/
- 1
修改集群配置
进入 conf 目录下,修改 flink-conf.yaml 文件(使用rocksdb状态后端 开启HistoryServer 记录历史任务)
cd conf/ vim flink-conf.yaml #JobManager 节点地址. jobmanager.rpc.address: master# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
state.backend: rocksdb# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
state.checkpoints.dir: hdfs://master:8020/flink-checkpoints# Default target directory for savepoints, optional.
#
state.savepoints.dir: hdfs://master:8020/flink-savepoints# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
jobmanager.archive.fs.dir: hdfs://master:8020/flink/completed-jobs/# The address under which the web-based HistoryServer listens.
historyserver.web.address: 0.0.0.0# The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082# Comma separated list of directories to monitor for completed jobs.
historyserver.archive.fs.dir: hdfs://master:8020/flink/completed-jobs/# Interval in milliseconds for refreshing the monitored directories.
historyserver.archive.fs.refresh-interval: 10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点
vim workers
slave2
slave3
- 1
- 2
- 3
分发安装目录
scp -r ./flink-1.13.0 root@slave1:/export/server/
scp -r ./flink-1.13.0 root@slave2:/export/server/
- 1
- 2
yarn 模式
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
source /etc/profile
- 1
- 2
- 3
启动flink集群
bin/start-cluster.sh
- 1
7.查看各个集群的web网页
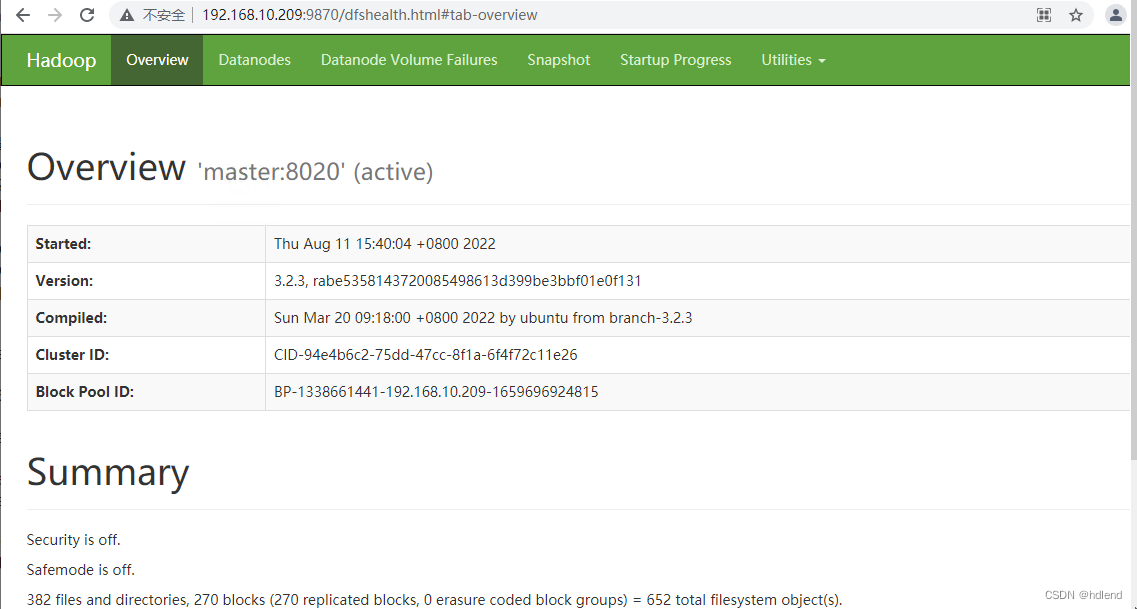
http://192.168.10.209:9870/
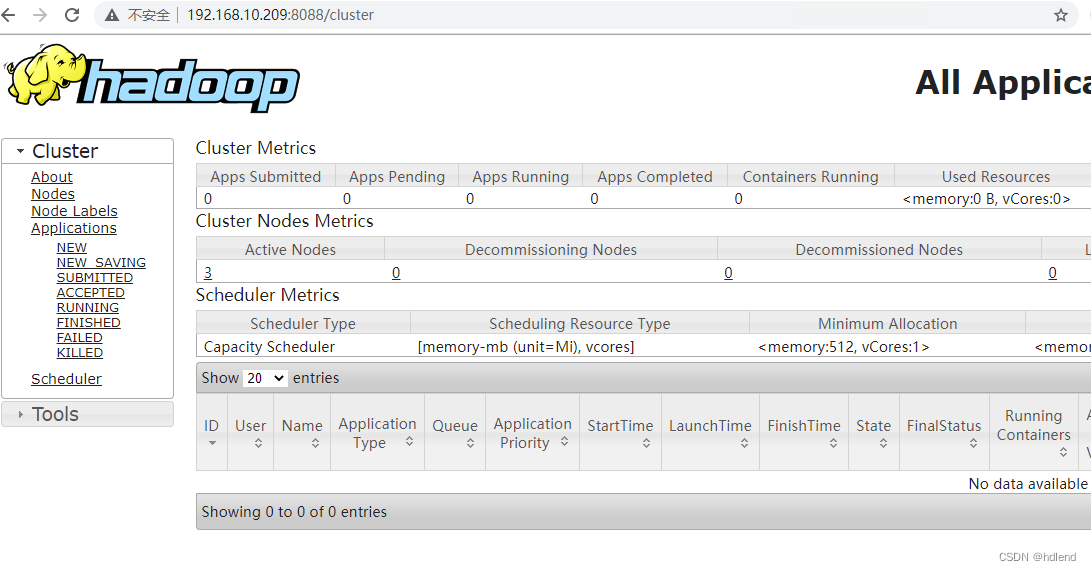
http://192.168.10.209:8088/
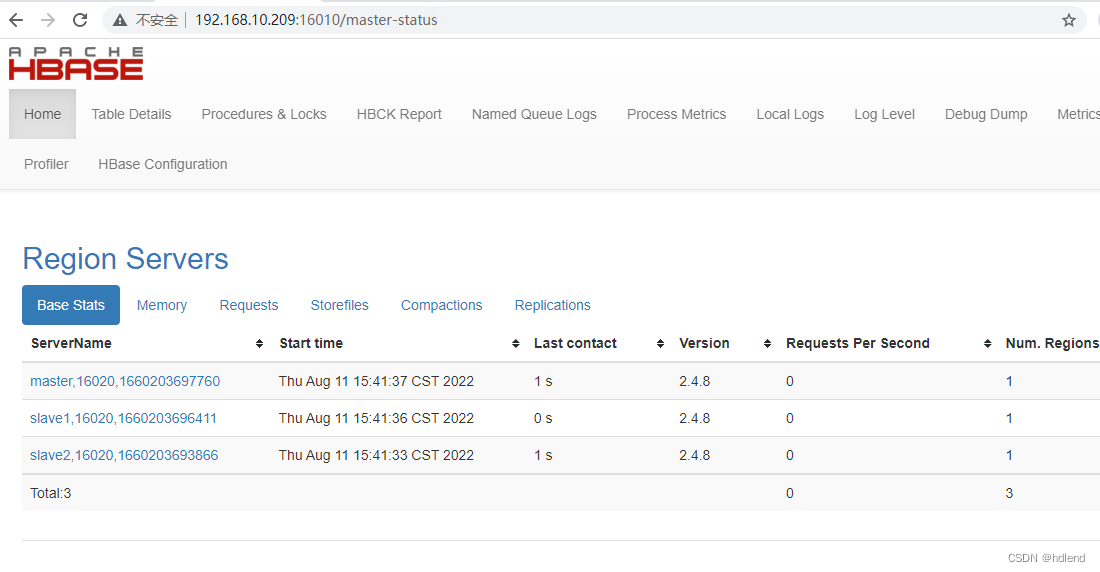
http://192.168.10.209:16010/
http://192.168.10.209:8081/
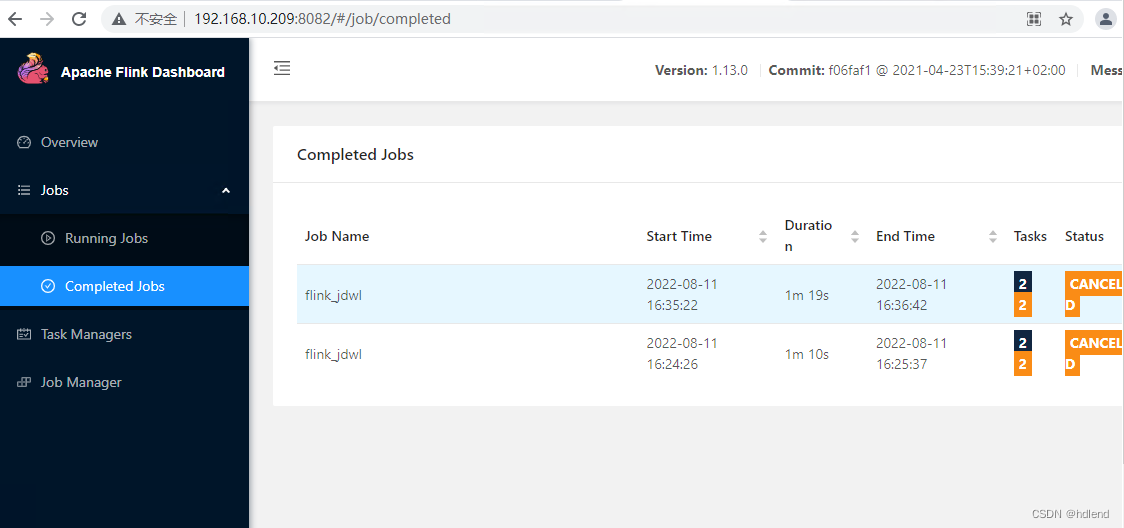
http://192.168.10.209:8082/