背景
在高并发的系统中,通常不会打印除参数校验失败或捕获异常之外的日志,防止对接口的性能产生影响。
那对于请求不符合预期的情况,我们如何快速找到是哪块逻辑影响的至关重要。
Pfinder提供的链路监控,更多的是性能层面的监控,无法满足我们上述的诉求。
下面我将通过自定义通用上下文,添加日志埋点,解决上述存在的问题。
通用上下文 CommonContext
作用
创建通用上下文的作用,是为了跟踪一个请求的生命周期,然后根据请求的特殊标识,决定是否记录关键日志,然后返回给调用方,以识别具体执行了什么逻辑,以便快速排查问题。
包含
一个通用上下文,除了要包含记录日志的字段,也可以存储一些通用参数,计算中间结果等等。
示例
@Slf4j
@Data
public class CommonContext {
// 日志
private StringBuffer logSb = new StringBuffer();
// 日志开关
private boolean isDebug;
// 通用参数
private boolean compare = false;
// 中间结果
private Set<Integer> targetSet = new HashSet<>();
public void clearContext() {
targetSet = Collections.emptySet();
compare = false;
}
public void debug(String message) {
if (!isDebug || StringUtils.isEmpty(message)) {
return;
}
logSb.append(message).append("\t\n");
}
public void debug(String format, Object... argArray) {
if (!isDebug) {
return;
}
String[] msgArray = new String[argArray.length];
for (int i = 0; i < argArray.length; i++) {
msgArray[i] = JSON.toJSONString(argArray[i]);
}
FormattingTuple ft = MessageFormatter.arrayFormat(format, msgArray);
logSb.append(ft.getMessage()).append("\t\n");
}
public void debugEnd() {
if (!isDebug) {
return;
}
String msg = logSb.toString();
log.info(msg);
}
}
使用
简单是使用如下:
@Override
public Response method(Request request) {
if (checkParam(request)) {
log.error("request param error:{}", JSON.toJSONString(request));
return Response.failed(ResponseCode.PARAM_INVALID);
}
CallerInfo info = Profiler.registerInfo(Ump.getUmpKey(xxxx), false, true);
ParamVO paramVO = request.getParam();
try {
CommonContext context = new CommonContext();
context.setDebug(Constants.SPECIAL_UUID.equals(request.getUuid()));
Long userId = paramVO.getUserId();
context.setCompare(paramVO.getCompare());
context.debug("输入参数:{}", paramVO);
List result = userAppService.match(context, paramVO);
context.debug("输出结果:{}", result);
context.clearContext();
Response response = Response.success(result);
context.debugEnd(response);
return response;
} catch (Exception e) {
log.error("method error", e);
Profiler.functionError(info);
return Response.failed(ResponseCode.ERROR);
} finally {
Profiler.registerInfoEnd(info);
}
}
说明:
-
当识别到指定的
uuid,我们开启了上下文日志开关 -
对于单个入参的情况,
context.clearContext();不执行也可以,但是对于批量接口,在遍历处理的时候,需要在每个循环体内执行context.clearContext();,防止一些中间结果对后需循环的影响。 -
在关键的地方,我们可以通过
context.debug()记录日志,然后设置到Response#message随响应返回,进而快速识别问题。
存在的问题
在记录日志的时候,我打印了如下日志:
context.debug("activityList:{}", activityList.stream()
.map(ActivityInfo::toString)
.collect(Collectors.joining("######")));
单从代码来看,好像没什么问题。
来看接口性能,如下:
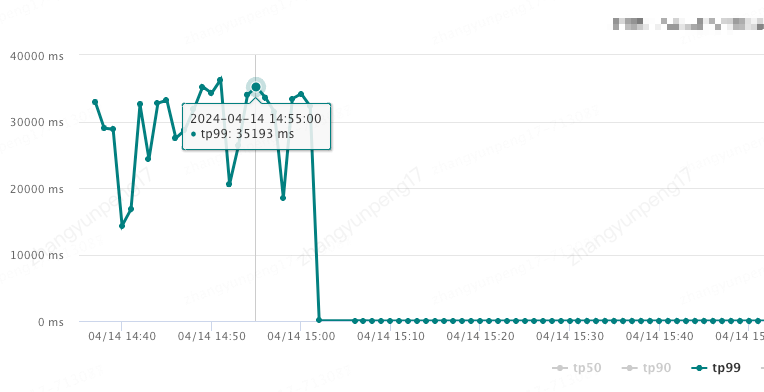
tp99达到恐怖的35s!
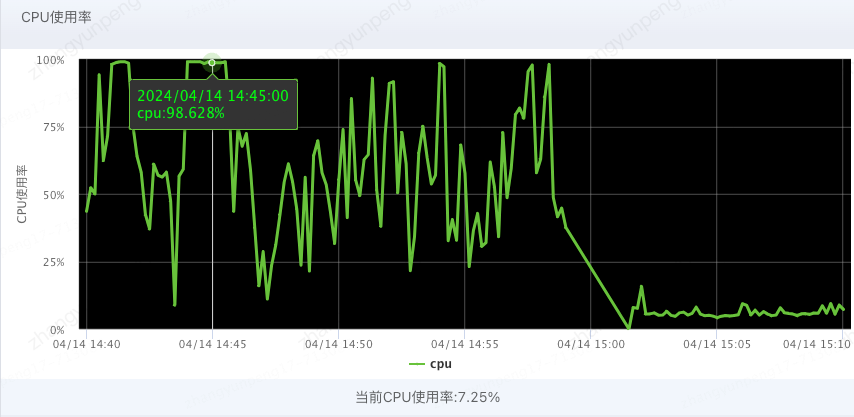
CPU使用率居高不下!
通过分析,发现查询到的 activityList 个数较多,且单个对象较大,在执行上述日志打印逻辑的时候,消耗了较多的CPU资源,进而影响了接口性能。
注释该段代码,tp99降低至15ms左右。
但实际上,我还是存在打印该列表的诉求。
升级
上述问题的根本原因是:不论我是否开启日志打印,日志中的计算逻辑总会执行。
那有什么办法,只在开关开启的情况下,打印该日志呢?
借鉴log4j,使用lamba表达式延迟打印
Log4j存在如下API:
org.apache.logging.log4j.Logger#info(java.lang.String, org.apache.logging.log4j.util.Supplier<?>...)
手动控制是否打印详情信息
将打印列表的诉求拆分如下:
-
对于特大的列表,不打印
-
对于较小的列表,打印
升级后的CommonContext
package org.example;
import com.alibaba.fastjson.JSON;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang.StringUtils;
import org.slf4j.helpers.FormattingTuple;
import org.slf4j.helpers.MessageFormatter;
import java.util.Collections;
import java.util.HashSet;
import java.util.Set;
import java.util.function.Supplier;
@Slf4j
@Data
public class CommonContext {
// 日志
private StringBuffer logSb = new StringBuffer();
// 日志开关
private boolean isDebug;
// 日志开关是否记录详细日志
private boolean isDebugDetail;
// 通用参数
private boolean compare = false;
// 中间结果
private Set<Integer> targetSet = new HashSet<>();
public void clearContext() {
targetSet = Collections.emptySet();
compare = false;
}
public void setDebugDetail(boolean debugDetail) {
if (debugDetail) {
isDebug = true;
}
isDebugDetail = debugDetail;
}
public void debug(String message) {
if (!isDebug || StringUtils.isEmpty(message)) {
return;
}
logSb.append(message).append("\t\n");
}
public void debug(String format, Object... argArray) {
if (!isDebug) {
return;
}
String[] msgArray = new String[argArray.length];
for (int i = 0; i < argArray.length; i++) {
msgArray[i] = JSON.toJSONString(argArray[i]);
}
FormattingTuple ft = MessageFormatter.arrayFormat(format, msgArray);
logSb.append(ft.getMessage()).append("\t\n");
}
public void debug(String message, Supplier<?>... paramSuppliers) {
if (!isDebug) {
return;
}
commonDebug(message, paramSuppliers);
}
public void debugDetail(String message, Supplier<?>... paramSuppliers) {
if (!isDebugDetail) {
return;
}
commonDebug(message, paramSuppliers);
}
private void commonDebug(String message, Supplier<?>... paramSuppliers) {
String[] msgArray = new String[paramSuppliers.length];
for (int i = 0; i < paramSuppliers.length; i++) {
msgArray[i] = JSON.toJSONString(paramSuppliers[i].get());
}
FormattingTuple ft = MessageFormatter.arrayFormat(message, msgArray);
logSb.append(ft.getMessage()).append("\t\n");
}
public void debugEnd() {
if (!isDebug) {
return;
}
String msg = logSb.toString();
log.info(msg);
}
}
说明:
-
这里引入的
Supplier是java.util包的,更通用。 -
保留了对于简单的参数,不使用lambda的方式。
-
lambda的延迟计算已验证,可放心使用。
升级后使用
CommonContext context = new CommonContext();
context.setDebug(Constants.SPECIAL_UUID.equals(request.getUuid()));
context.setDebugDetail(Constants.SPECIAL_UUID2.equals(request.getUuid()));
需要注意: setDebugDetail() 需要在 setDebug后执行,否则isDebug标识会被覆盖。
context.debugDetail("activityList:{}", () -> activityList.stream()
.map(ActivityInfo::toString)
.collect(Collectors.joining("######")));
将所有有计算逻辑的日志升级为 lamba表达式,下面来看升级前后接口性能变化:
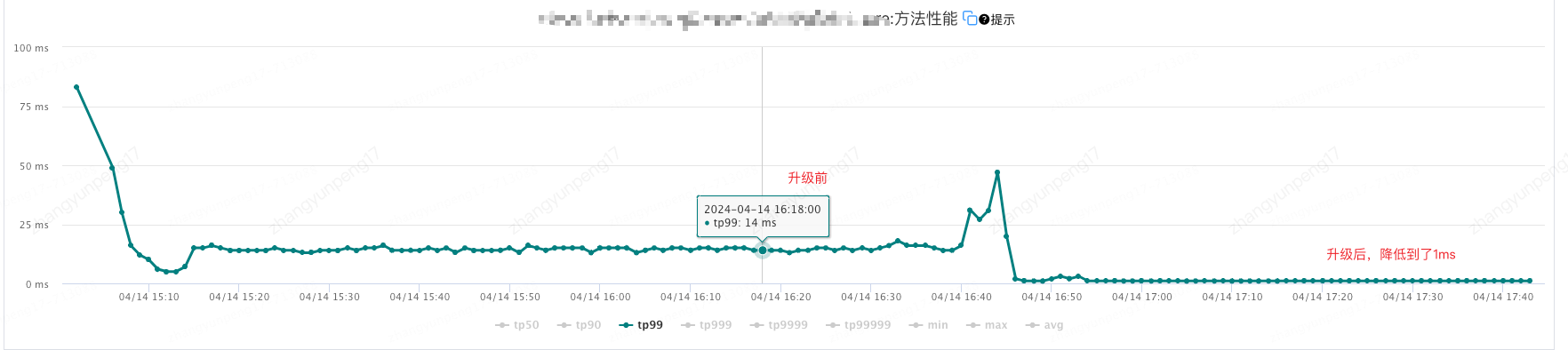
以上。
作者:京东零售 张云鹏
来源:京东云开发者社区
标签:String,自定义,message,void,context,埋点,public,日志 From: https://www.cnblogs.com/Jcloud/p/18203466