1. 前言
前文实现“代码可视化”需要了解的前置知识-编译器前端介绍了编译器前端知识并附带了小练习,本文将继续介绍编译器中端相关的知识,还是概念+练习的学习方式。中间代码是用来进行程序分析和实现代码可视化的关键数据,了解其生成和优化方式能更好的帮助我们理解程序的执行逻辑,希望大家阅读本文后有所收获。
2. 编译器(Compiler)
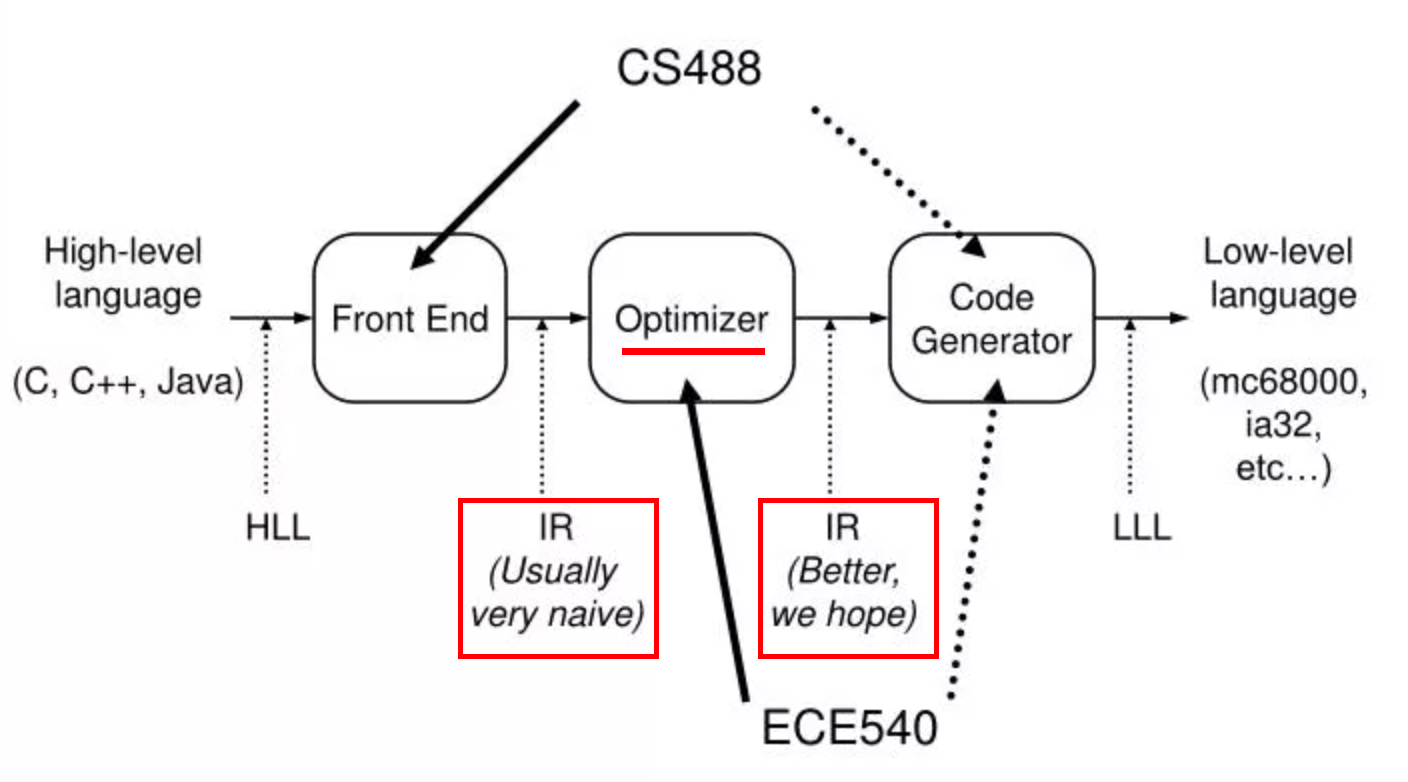
中端部分主要包含的功能有“生成中间代码”和“中间代码优化”。
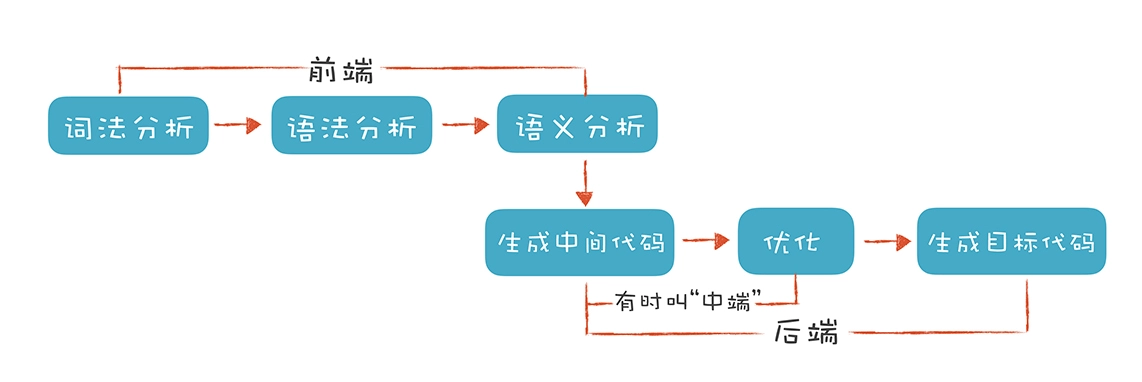
2.1 编译器工作步骤
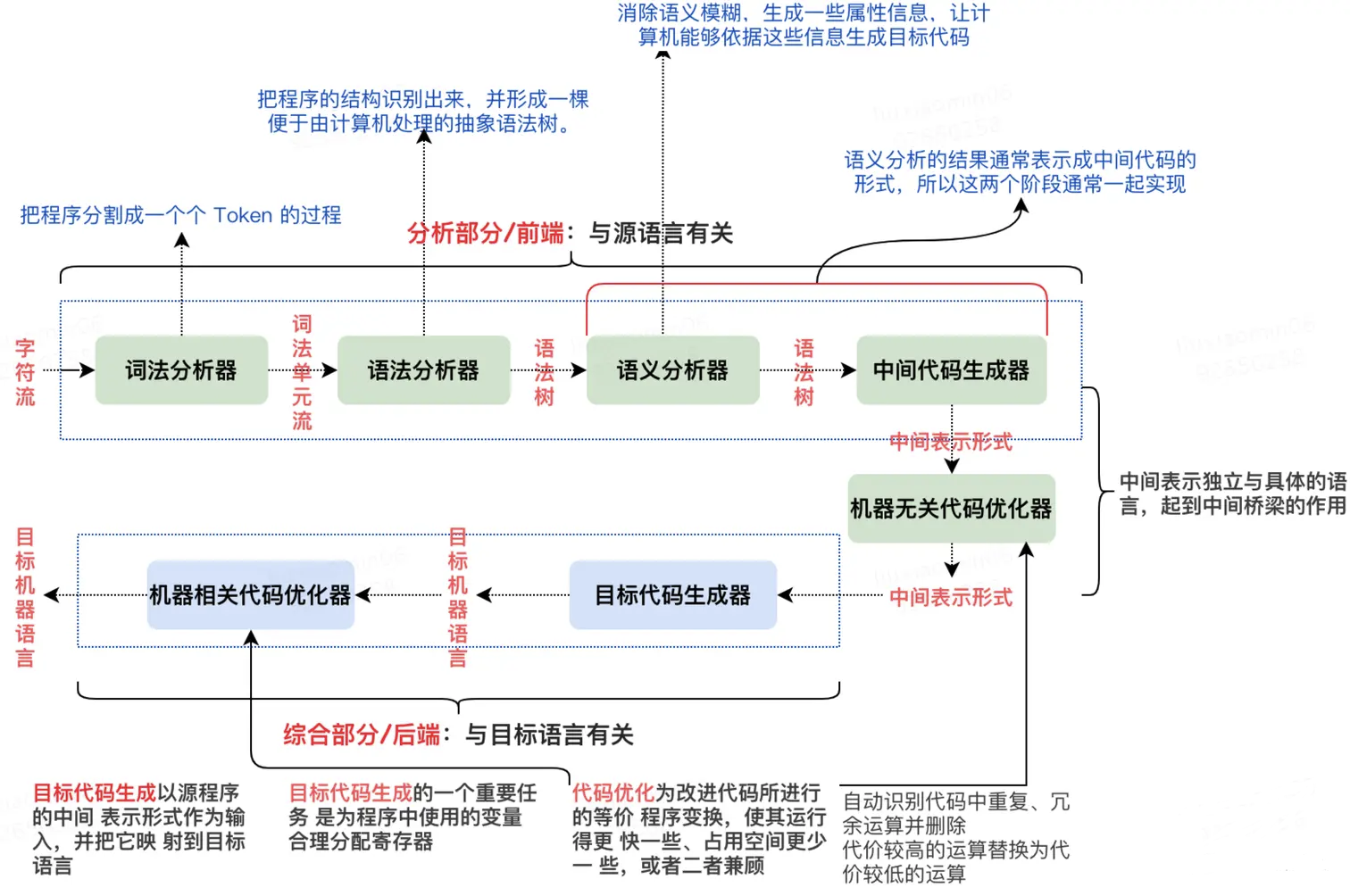
2.2 编译器中端
2.2.1 中间代码生成
2.2.1.1 为什么需要中间代码?
编译器很难通过一次处理就得到最优的目标代码,实际的编译器大多组织为一连串的处理趟,每一趟处理的结果又作为下一趟的输入持续的运行。随着编译器不断推导有关被编译代码的知识,它必须将这些信息从一趟传递到另一趟。因此,这些能推导出有关程序全部事实的信息需要一种表示方式,称之为中间代码或中间表示(intermediate representation),简称IR。
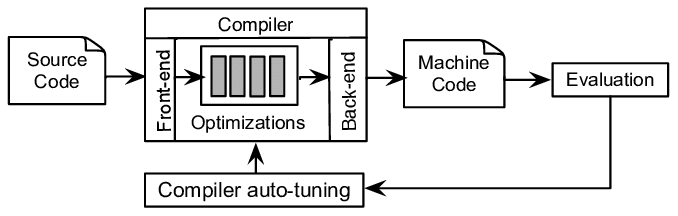
广义角度可以将源码到目标代码之间的表达形式都称之为中间代码。其目的是为了解耦编译器前端和后端部分,作为高级语言和目标机器语言之间的桥梁,不依赖于特定的源语言或目标机器使得一些代码优化动作能够复用。与高级语言相比,IR 丢弃了大部分高级语言的语法特征和语义特征,比如循环语句、if 语句、作用域、面向对象等等,它更像高层次的汇编语言;而相比真正的汇编语言,它又不会有那么多琐碎的、与具体硬件相关的细节。
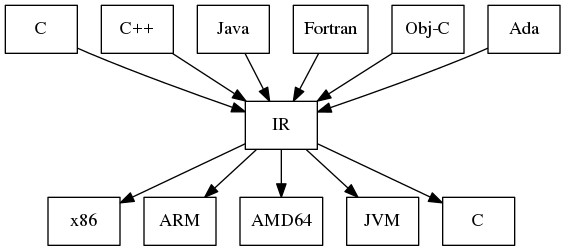
如果源语言语法结构较为简单,编译器可能会用唯一的IR,但如果源语言语法结构比较复杂,则在转换为目标语言的过程中可能会使用了一系列的IR,并通过转换进行大量的优化操作。
由于不同语言编译器中IR差异较大,本文后续内容对于概念部分只做点到即止的阐述,有兴趣的同学可以自行查阅资料,增加了LLVM的中间代码实操用来加深理解。LLVM 是一个开源的编译器基础设施项目,主要聚焦于编译器的后端功能(代码生成、代码优化、JIT……),其在业界被广泛应用,很多语言都是基于它实现的,更多信息可以查看官网。
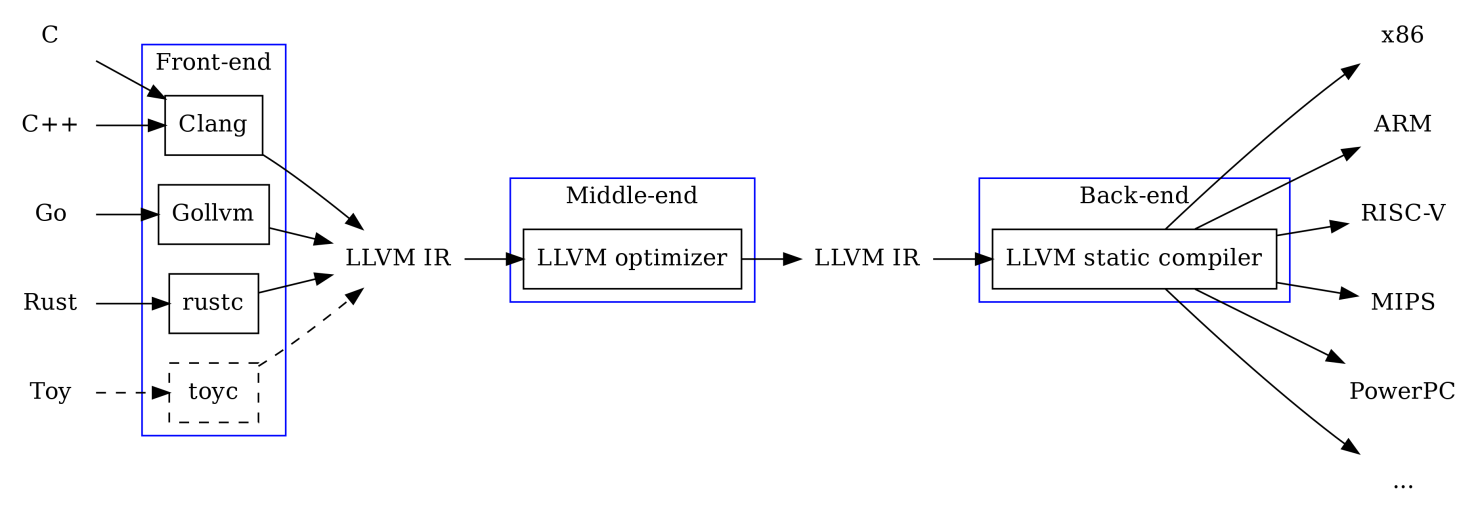
2.2.1.2 中间代码分类
按照与源代码接近程度可以分为:
•高级IR:更接近源代码,保留了更多的源代码层面的信息,如数据类型、控制结构等。通常用于编译器前端的语义分析和初步优化阶段。例如:AST等; •中级IR:开始脱离源代码的具体语法,引入更多与机器无关的优化。通常用于进行编译器的主要优化,如循环优化、常量传播、死代码消除等。例如:TAC等; •低级IR:接近目标机器代码,更多地反映了目标平台的具体特性,如寄存器、指令集等。用于编译器后端的优化,特别是那些与目标机器密切相关的优化,如寄存器分配、指令选择和调度。根据其结构和表现形式可以分为:
•图IR: 将编译器生成的信息保存在图中,通过图结构来表示程序的各种属性。图IR非常适合表示并分析程序的复杂结构,如循环、分支等。例如:AST、CFG和DFG等; •线性IR: 以线性的方式表示程序,通常是一系列的指令或语句。不像图IR那样直观地表示控制流或数据流,但对于某些分析和转换来说更简单、直接,常用于编译器的早期阶段,进行简化的分析和转换。例如:TAC、SSA等; •混合IR: 结合了图IR和线性IR的特点,尝试兼顾两者的优势。一种常见的混合表示为使用线性IR来表示无循环代码的块,使用图来表示这些块之间的控制流。混合IR旨在提供足够的灵活性来支持各种编译阶段的需要,从而使编译器能够有效地执行复杂的优化和分析。了解了基本的分类,下面介绍几种常见的中间表示方式,并针对表达式A进行不同形式的呈现:
// 表达式A
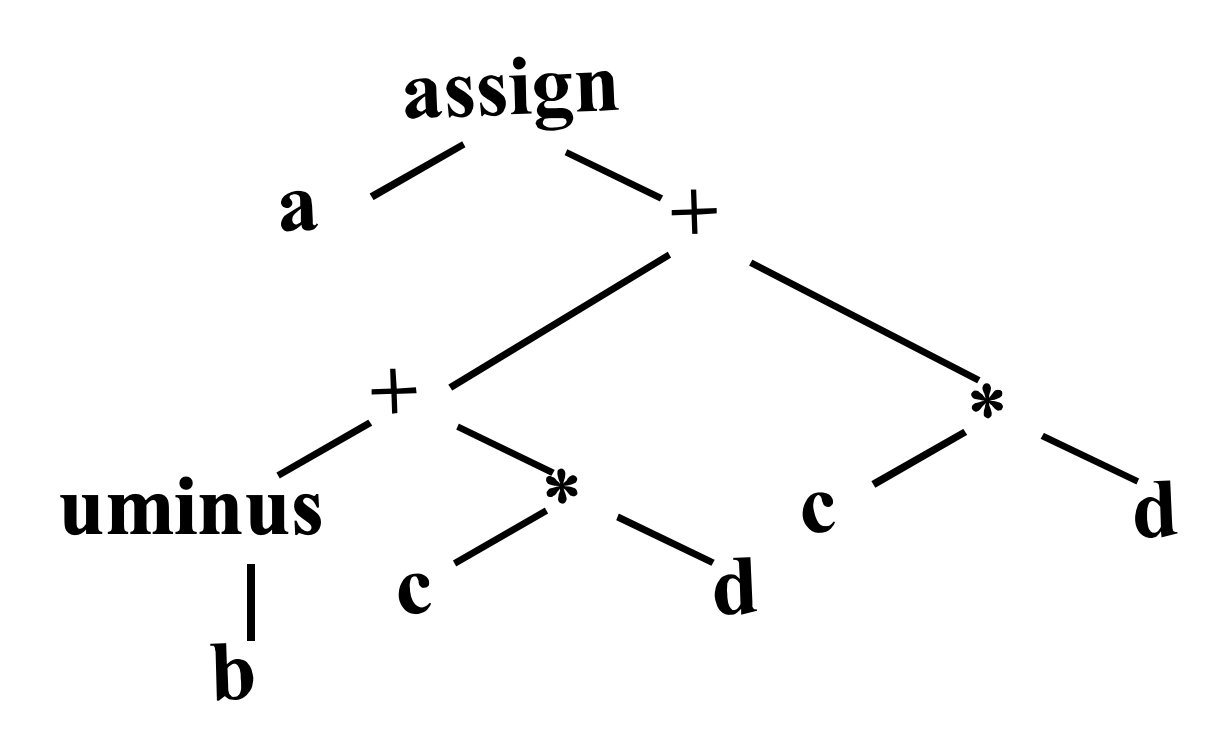
a=(-b+c*d)+c*d① 抽象语法树(Abstract Syntax Tree, AST)
通过编译器前端生成的抽象语法树也算是高级IR和图IR,它保留了源代码的语法结构,如表达式、语句、函数定义等。这里就不再赘述生成过程,如果忘记了相关知识可以再复习一下前文。表达式A对应的AST为:
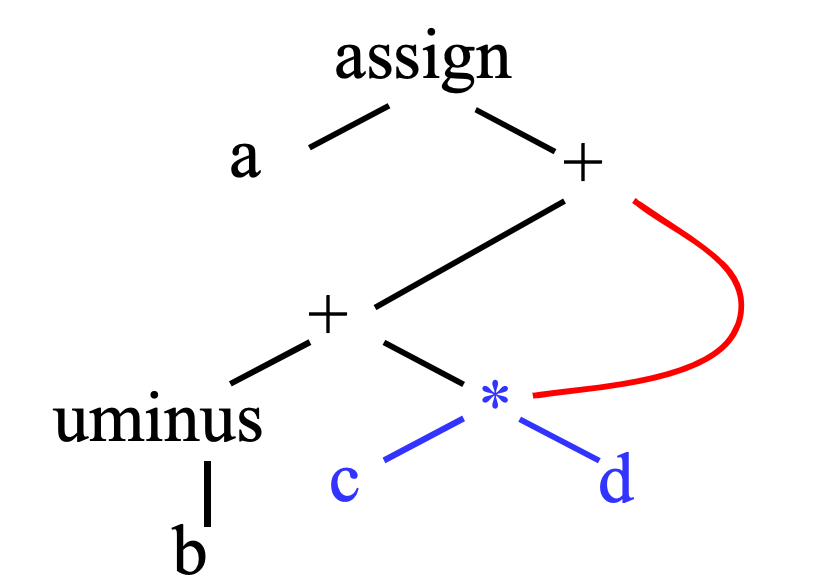
② 有向无环图(Directed Acyclic Graph,DAG)
有向无环图是在树结构的基础上,消除了冗余的子树。其结点可以有多个父结点,相同子树可以被重用,可以理解为是一种具有共享机制的AST。表达式A对应的DAG为:
③ 三地址代码(Three-Address Code, TAC)
三地址代码是中级IR和线性IR,它是一种接近于汇编语言但又保持了高级语言特征的代码形式。这种形式的IR特别适合于执行和表示各种编译时优化。在三地址代码中,每条指令通常涉及到两个操作数(y、z)和一个结果(x),指令的一般形式可以是:
x = y op z
其中,op 是一个二元运算符,y 和 z 是操作数,可以是常量、变量或者临时变量,x 是存放结果的变量或临时变量。三地址代码也支持一元运算符,这种情况下指令的形式为:
x = op y
常用的三地址代码有:
| 指令形式 | 备注 | |
|---|---|---|
| 赋值指令 | x = y op z x = op y | op为运算符 |
| 复制指令 | x = y | |
| 条件跳转 | if x relop y goto n | relop为关系运算符 |
| 非条件跳转 | goto n | 跳转到地址n的指令 |
| 参数传递 | param x | 将x设置为参数 |
| 过程调用 | call p,n | p为过程的名字,n为过程的参数的个数 |
| 过程返回 | return x | |
| 数组引用 | x=y[i] | i为数组的偏移地址,而不是下标 |
| 数组赋值 | x[i]=y | |
| 地址及指针操作 | x=&y、x=*y*x=y |
表达式A对应的TAC为(可以通过遍历AST生成TAC):
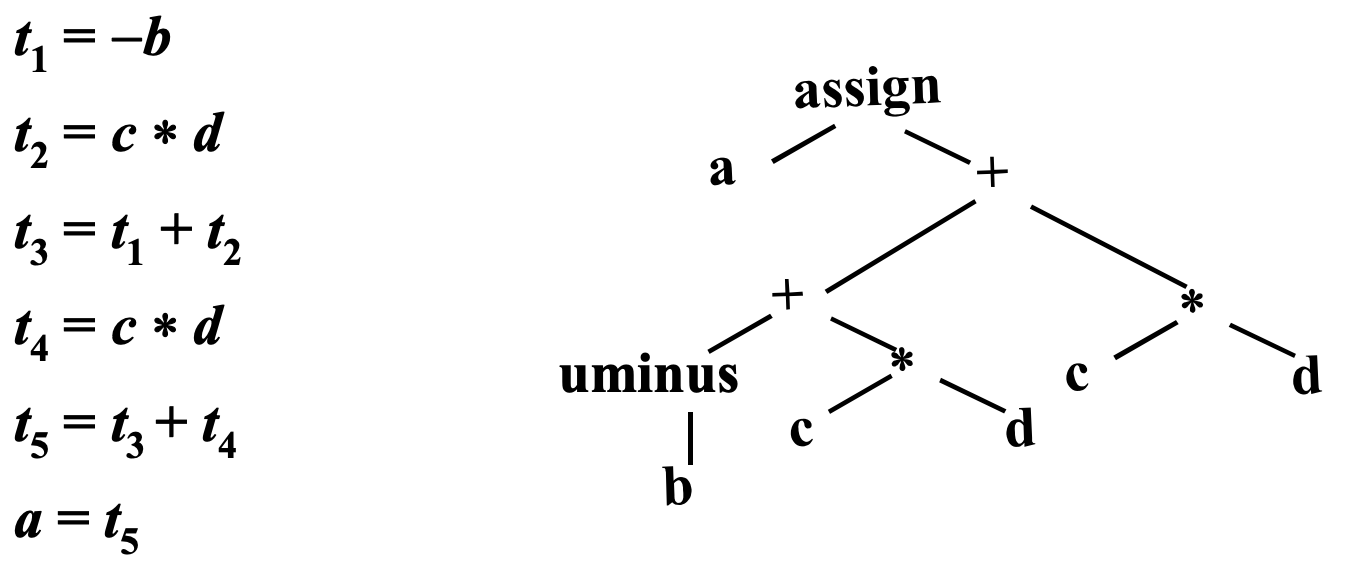
④ 静态单赋值形式(Static Single Assignment, SSA)
静态单赋值形式也是一种线性IR,它和三地址代码的主要区别在所有赋值指令都是对不同名字的变量的赋值。每个变量很确定地只会被定义一次,然后可以多次使用。这种特点使得基于SSA更容易做数据流分析,而数据流分析又是很多代码优化技术的基础,所以几乎所有语言的编译器、解释器或虚拟机中都使用了SSA。下图展示了两种表示方式的区别:

另外,表达式A生成的TAC和SSA是一样的,大家不妨验证一下是否符合SSA的特性
标签:LLVM,int,代码,IR,编译器,可视化,优化,中端 From: https://www.cnblogs.com/Jcloud/p/18203471