前言 本文介绍了一些Transformers常用的加速策略。
本文转载自Deephub Imba
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
招聘高光谱图像、语义分割、diffusion等方向论文指导老师
Transformers 是一个强大的架构,但模型因其采用的自注意力机制,虽然能够有效地处理序列数据并捕获长距离依赖关系,但同时也容易导致在训练过程中出现OOM(Out of Memory,内存不足)或者达到GPU的运行时限制。
主要是因为
- 参数数量庞大:Transformer模型通常包含大量的参数,尤其是在模型层面进行扩展时(例如,增加层数或头数)。这些参数需要大量的内存来存储权重和梯度。
- 自注意力计算:自注意力机制需要对输入序列的每个元素与其他所有元素计算其相互关系,导致计算复杂度和内存需求随着输入长度的增加而显著增加。对于非常长的序列,这一点尤其突出。
- 激活和中间状态存储:在训练过程中,需要存储前向传播中的中间激活状态,以便于反向传播时使用。这增加了额外的内存负担。
为了解决这些问题,我们今天来总结以下一些常用的加速策略

固定长度填充

在处理文本数据时,由于文本序列的长度可能各不相同,但许多机器学习模型(尤其是基于Transformer的模型)需要输入数据具有固定的尺寸,因此需要对文本序列进行固定长度填充(padding)。
在使用Transformer模型时,填充部分不应影响到模型的学习。因此通常需要使用注意力掩码(attention mask)来指示模型在自注意力计算时忽略这些填充位置。通过这种固定长度填充和相应的处理方法,可以使得基于Transformer的模型能够有效地处理不同长度的序列数据。在实际应用中,这种方法是处理文本输入的常见策略。
def fixed_pad_sequences(sequences, max_length, padding_value=0):
padded_sequences = []
for sequence in sequences:
if len(sequence) >= max_length:
padded_sequence = sequence[:max_length] # Trim the sequence if it exceeds max_length
else:
padding = [padding_value] * (max_length - len(sequence)) # Calculate padding
padded_sequence = sequence + padding # Pad the sequence
padded_sequences.append(padded_sequence)
return padded_sequences这种方式会将所有的序列填充成一个长度,这样虽然长度相同了,但是因为序列的实际大小本来就不同,同一批次很可能出现有很多填充的情况,所以就出现了动态填充策略。
动态填充是在每个批处理中动态填充输入序列到最大长度。与固定长度填充不同,在固定长度填充中,所有序列都被填充以匹配整个数据集中最长序列的长度,动态填充根据该批中最长序列的长度单独填充每个批中的序列。

这样虽然每个批次的长度是不同的,但是批次内部的长度是相同的,可以加快处理速度。
def pad_sequences_dynamic(sequences, padding_value=0):
max_length = max(len(seq) for seq in sequences) # Find the maximum length in the sequences
padded_sequences = []
for sequence in sequences:
padding = [padding_value] * (max_length - len(sequence)) # Calculate padding
padded_sequence = sequence + padding # Pad the sequence
padded_sequences.append(padded_sequence)
return padded_sequences等长匹配
等长匹配是在训练或推理过程中将长度相近的序列分组成批处理的过程。等长匹配通过基于序列长度将数据集划分为桶,然后从这些桶中采样批次来实现的。

从上图可以看到,通过等长匹配的策略,减少了填充量,这样也可以加速计算
def uniform_length_batching(sequences, batch_size, padding_value=0):
# Sort sequences based on their lengths
sequences.sort(key=len)
# Divide sequences into buckets based on length
buckets = [sequences[i:i+batch_size] for i in range(0, len(sequences), batch_size)]
# Pad sequences within each bucket to the length of the longest sequence in the bucket
padded_batches = []
for bucket in buckets:
max_length = len(bucket[-1]) # Get the length of the longest sequence in the bucket
padded_bucket = []
for sequence in bucket:
padding = [padding_value] * (max_length - len(sequence)) # Calculate padding
padded_sequence = sequence + padding # Pad the sequence
padded_bucket.append(padded_sequence)
padded_batches.append(padded_bucket)
return padded_batches自动混合精度
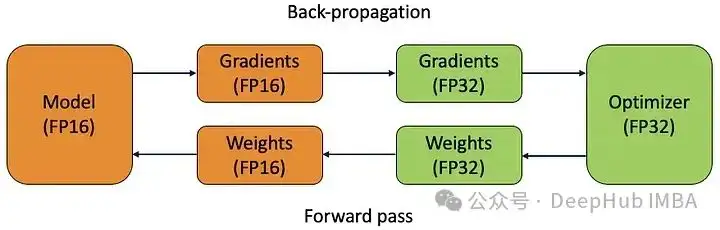
自动混合精度(AMP)是一种通过使用单精度(float32)和半精度(float16)算法的组合来加速深度学习模型训练的技术。它利用了现代gpu的功能,与float32相比,使用float16数据类型可以更快地执行计算,同时使用更少的内存。
import torch
from torch.cuda.amp import autocast, GradScaler
# Define your model
model = YourModel()
# Define optimizer and loss function
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = torch.nn.CrossEntropyLoss()
# Create a GradScaler object for gradient scaling
scaler = GradScaler()
# Inside the training loop
for inputs, targets in dataloader:
# Clear previous gradients
optimizer.zero_grad()
# Cast inputs and targets to the appropriate device
inputs, targets = inputs.to(device), targets.to(device)
# Enable autocasting for forward pass
with autocast():
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward pass
# Scale the loss value
scaler.scale(loss).backward()
# Update model parameters
scaler.step(optimizer)
# Update the scale for next iteration
scaler.update()AMP在训练过程中动态调整计算精度,允许模型在大多数计算中使用float16,同时自动将某些计算提升为float32,以防止下流或溢出等数值不稳定问题。
Fp16 vs Fp32
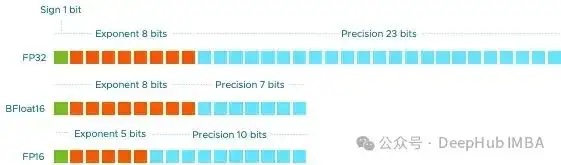
双精度(FP64)消耗64位。符号值为1位,指数值为11位,有效精度为52位。
单精度(FP32)消耗32位。符号值为1位,指数值为8位,有效精度为23位。
半精度(FP16)消耗16位。符号值为1位,指数值为5位,有效精度为10位。
所以Fp16可以提高内存节省,并可以大大提高模型训练的速度。考虑到Fp16的优势和它在模型使用方面的主导区域,它非常适合推理任务。但是fp16会产生数值精度的损失,导致计算或存储的值不准确,考虑到这些值的精度至关重要。
另外就是这种优化师针对于分类任务的,对于回归这种需要精确数值的任务Fp16的表现并不好。
总结
以上这些方法,可以在一定程度上缓解内存不足和计算资源的限制,但是对于大型的模型我们还是需要一个强大的GPU。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:padding,常用,Transformers,技巧,填充,sequence,padded,length,sequences From: https://www.cnblogs.com/wxkang/p/18196940