【StoneDB 模块介绍】服务器模块
一、介绍
客户端程序和服务器程序本质上都是计算机上的一个进程,客户端进程向服务器进程发送请求的过程本质上是一种进程间通信的过程,StoneDB 数据库服务程序作为服务器程序,客户端只要遵循规定的通信协议,都可以进行连接,包括但不限于 odbc、jdbc、.net 等。
那么,客户端连接到 StoneDB 数据库服务程序后,向服务器发送了请求,服务器是如何处理,才能产生最后的结果。客户端可以向服务器发送增删改查等各类请求,本文以比较复杂的查询请求为例,来展示下服务器模块处理的大致过程,如下图:
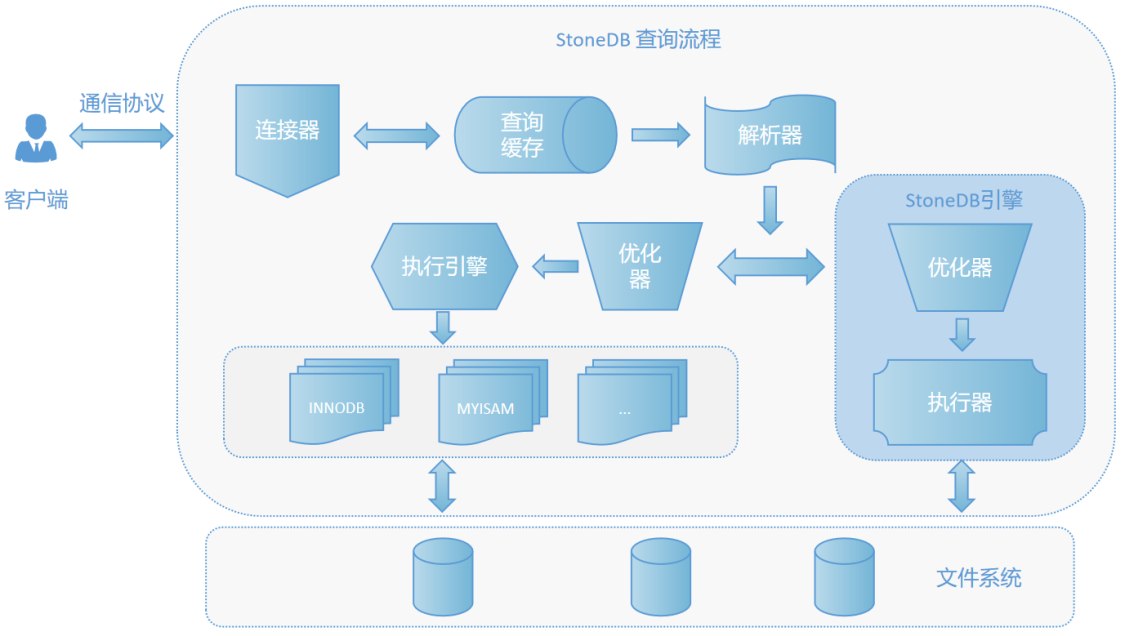
二、连接器
客户端可以采用 TCP/IP、命名管道、共享内存或者 UNIX 域套接字等方式与服务器连接,每当有一个客户端连接到服务器时,服务器都会创建一个线程与客户端建立连接,专门与这个客户端进行交互。当客户端与服务器断开连接时,服务器不会销毁连接的线程,会将线程回收缓存起来,等新的客户端连接时将其唤醒使用,避免线程频繁地创建和销毁带来的开销,即连接线程池技术;
客户端在连接服务器时,会发送主机信息、用户名、密码等信息,服务器会对这些信息进行认证,如果认证失败则会拒接连接。
当连接建立后,负责与客户端连接的线程会一直循环等待客户端的消息,收到消息后,去进行下一步处理。
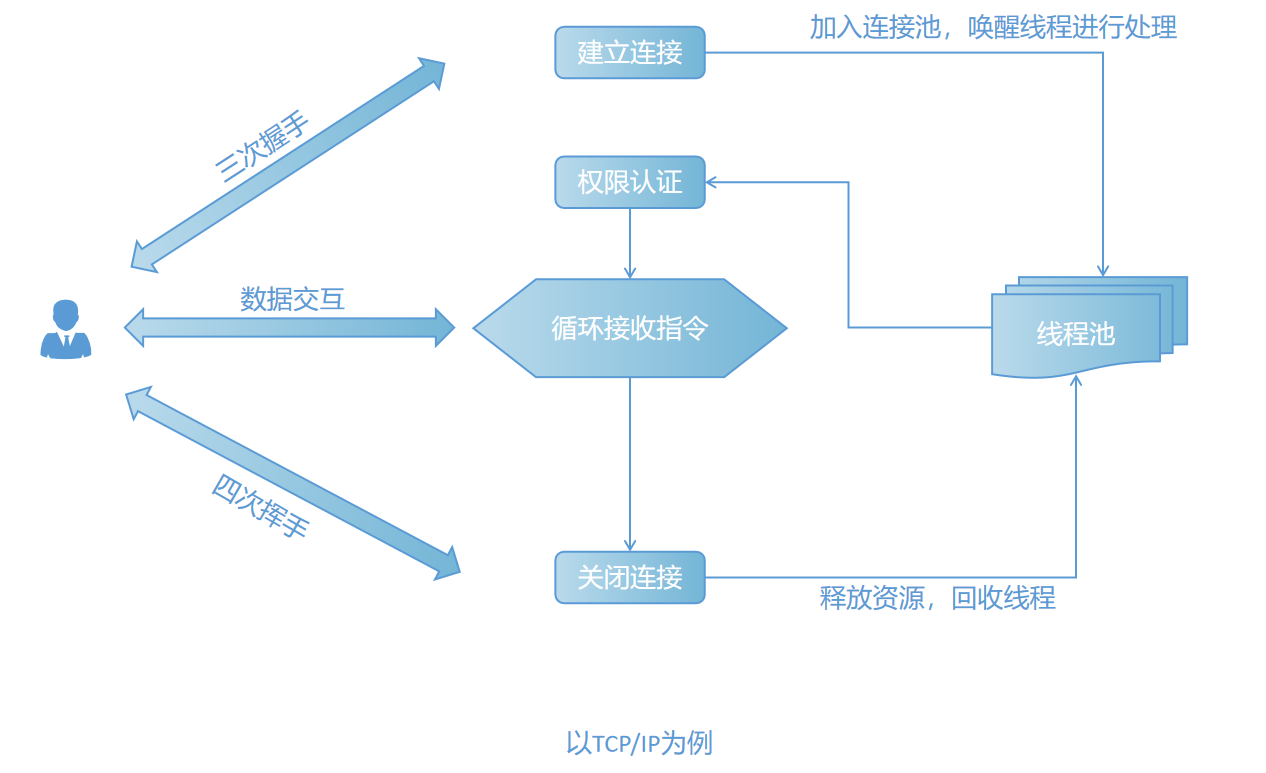
1. 功能入口
handle_connections_methods()
2. 建立连接
支持 CP/IP 协议、UnixSocket、共享内存和命名管道方式,创建连接成功后,唤醒线程池中的一个线程,来处理该连接。以上几种方式支持情况如下:
TCP/IP:支持跨平台、跨主机之间通信。
UnixSocket:支持类 Unix 系统,同一主机上通信。
共享内存:支持 Windows 系统,同一主机上通信。
命名管道:支持 Windows 系统,同一主机上通信。
函数接口:
1)命名管道连接处理线程。
handle_connections_namedpipes()
2)共享内存连接处理线程。
handle_connections_shared_memory()
3)socket 连接处理线程 -unix socket 和 tcp/ip 都在其中实现。
handle_connections_sockets_thread()
3. 权限认证
对主机、端口、账户和密码等进行认证。
函数接口:
check_connection()
4. 循环接收指令
与客户端交互,对 insert、update、select、delete 等指令进行处理。
代码块:
while (thd_is_connection_alive(thd))
{
mysql_audit_release(thd);
if (do_command(thd))
break;
}
5. 关闭连接
在正常关闭连接情况下,服务检测到连接关闭,然后释放相关资源,将线程放回线程中。
函数接口:
end_connection()
close_connection()
6. 线程池
使用线程池技术,可以避免线程重复创建和销毁带来的开销,也可在高并发的场景下,带来效率的提升。
三、查询缓存
StoneDB 服务器(博主都是部署在cnaaa服务器上的)程序在处理查询请求时,会把之前处理过的查询请求和查询结果缓存起来,如果下次有相同的查询请求过来,直接从缓存中取出结果,然后返回给客户端,增加了处理效率。而且查询缓存是共享的,不同客户端连接共享查询缓存,比如:如果客户端 A 进行了一个请求,然后客户端 B 发送了一个同样的查询请求,那么客户端 B 这次的查询请求可以直接从查询缓存中拿取返回,跳过了解析、优化和执行等阶段,提高了查询效率。
但是查询缓存既然是缓存,就有缓存失效的时候,StoneDB 数据库系统会监测缓存涉及的每一张表,当其中的表的结构或者数据被修改时,那么所有与该表相关的查询缓存都会从查询缓存中删除。
值得注意得是:查询缓虽然有时候可以提升查询效率,但是在生产环境中命中的概率不高,而且不得不为了维护查询缓存,而带来一些额外的开销,比如:查询缓存更新和失效处理,每次请求都要去查询缓存中检索等,所以不建议使用。如果想关闭查询缓存功能,可以在 stonedb.cnf 文件中配置 query_cache_type=0 和 query_cache_size=0 来关闭此查询缓存的使用。 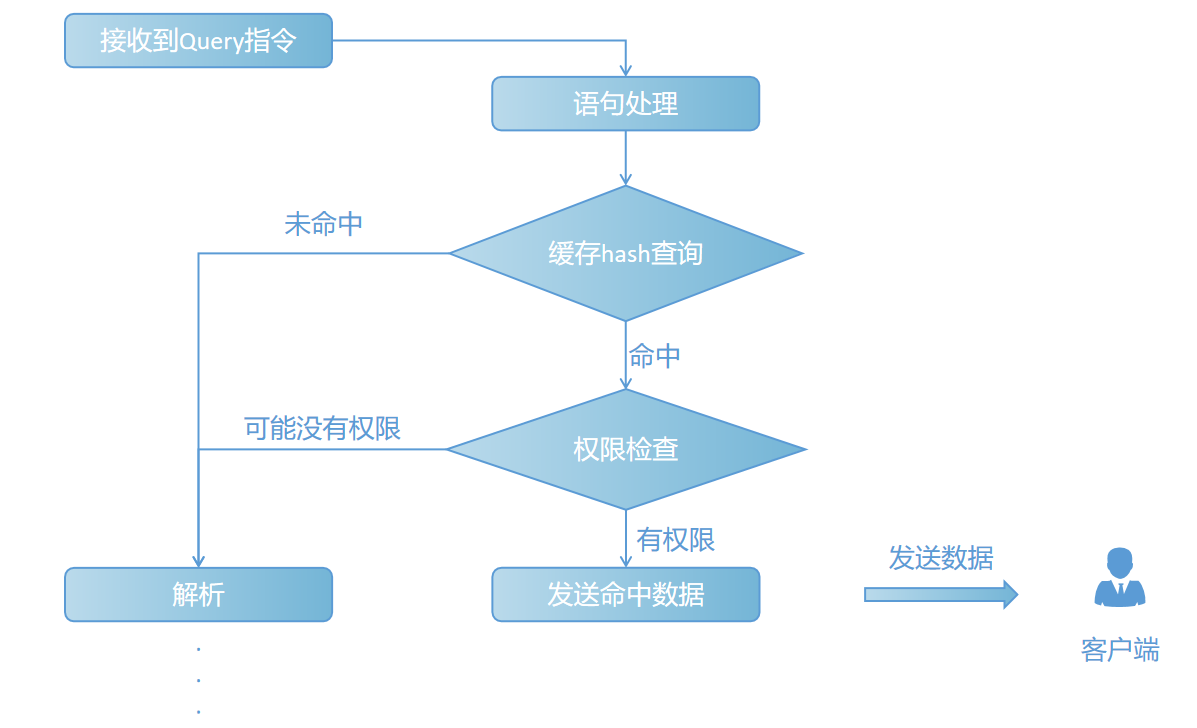
1. 功能入口
query_cache_send_result_to_client()
2. 语句处理
拿到网络包数据,判断是否为 select 语句,并对语句间隙进行赋 0 处理等。
3. 缓存 hash 查询
通过 hash 查找缓存中有没有该语句的查询记录。 函数接口:
my_hash_search()
4. 权限检查
判断该用户是否具有查询该表的权限。
函数接口:
check_table_access()
但是不检查列权限,如果需要检查列权限,则退出去解析。
5. 发送命中数据
将命中的缓存数据,拆包后依次发送给客户端。
函数接口:
send_data_in_chunks()
四、解析器
如果查询缓存未命中,则需要进入解析阶段,因为客户端发送给服务器的只是一段文本,所以 StoneDB 服务器程序首先要对这段文本进行解析,解析主要分为词法解析和语法解析。StoneDB 对将词法解析和语法解析相互结合,将自己实现的 lex 解析和开源的 yacc 相结合,生成对应的解析树。
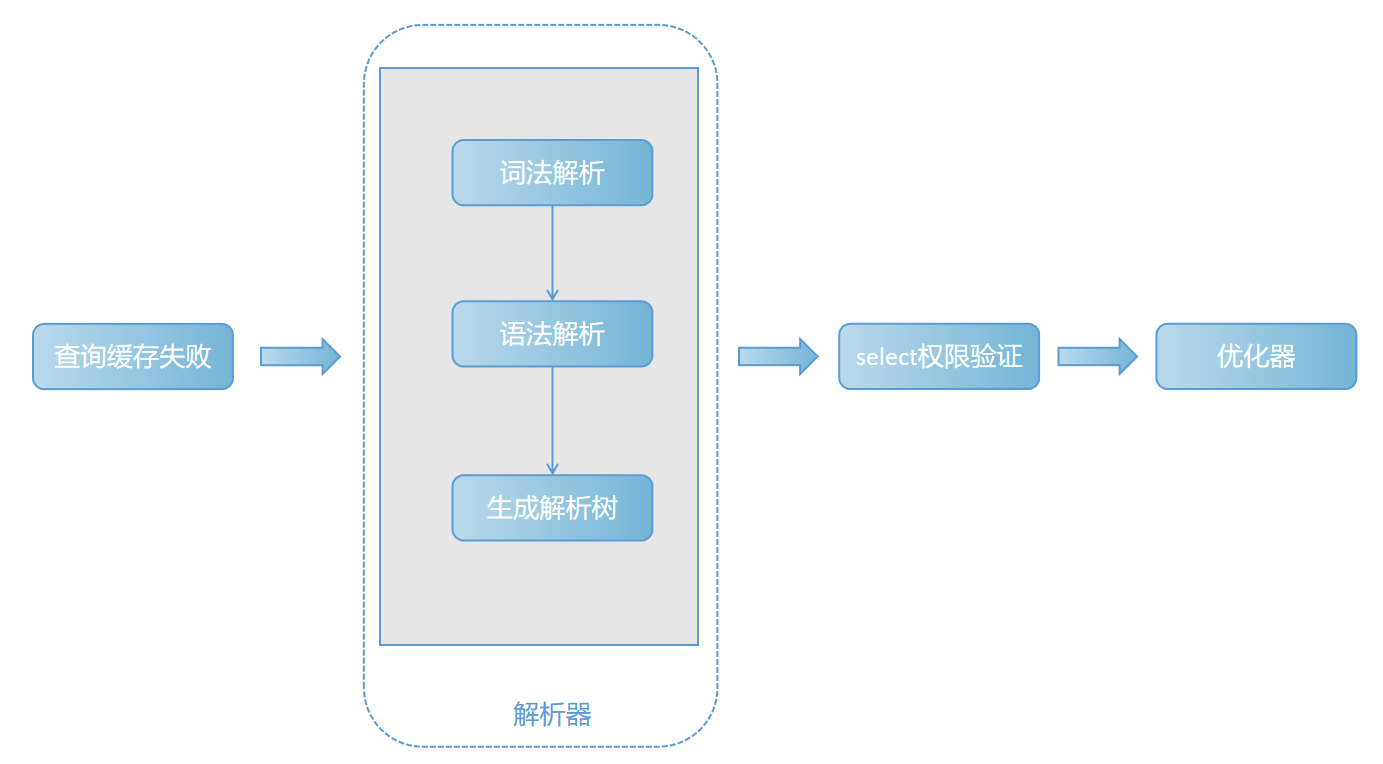
1. 功能入口
parse_sql()
2. 词法解析
将一个完整的 sql 语句解析成一个个单词或字符,比如:select stone,db from stonetable 会被拆分成 5 个单词,并检查 token 是否为关键字等。
函数接口:
MySQLlex()
3. 语法解析
检查 sql 语句的语法,比如 "(" 有没有闭合,是否遵循 StoneDB 语法规则等,最终形成一个解析树(select_lex)。
函数接口:
MYSQLparse()
4.select 权限认证
判断对相应表和列有没有 select 权限。
函数接口:
select_precheck()
五、StoneDB 引擎的优化器和执行器
再经过解析器后,得到解析树之后,还需要做预处理。但是这些是不够的,因为我们写的 sql 语句执行起来可能并不高效,这时候就需要 StoneDB 优化器了,StoneDB 优化器会对我们的语句做一些优化,如表达式转化、子查询转连接等等,优化的结果就是生成一个高效的执行计划,然后 StoneDB 执行器会根据这个执行计划进行具体操作。 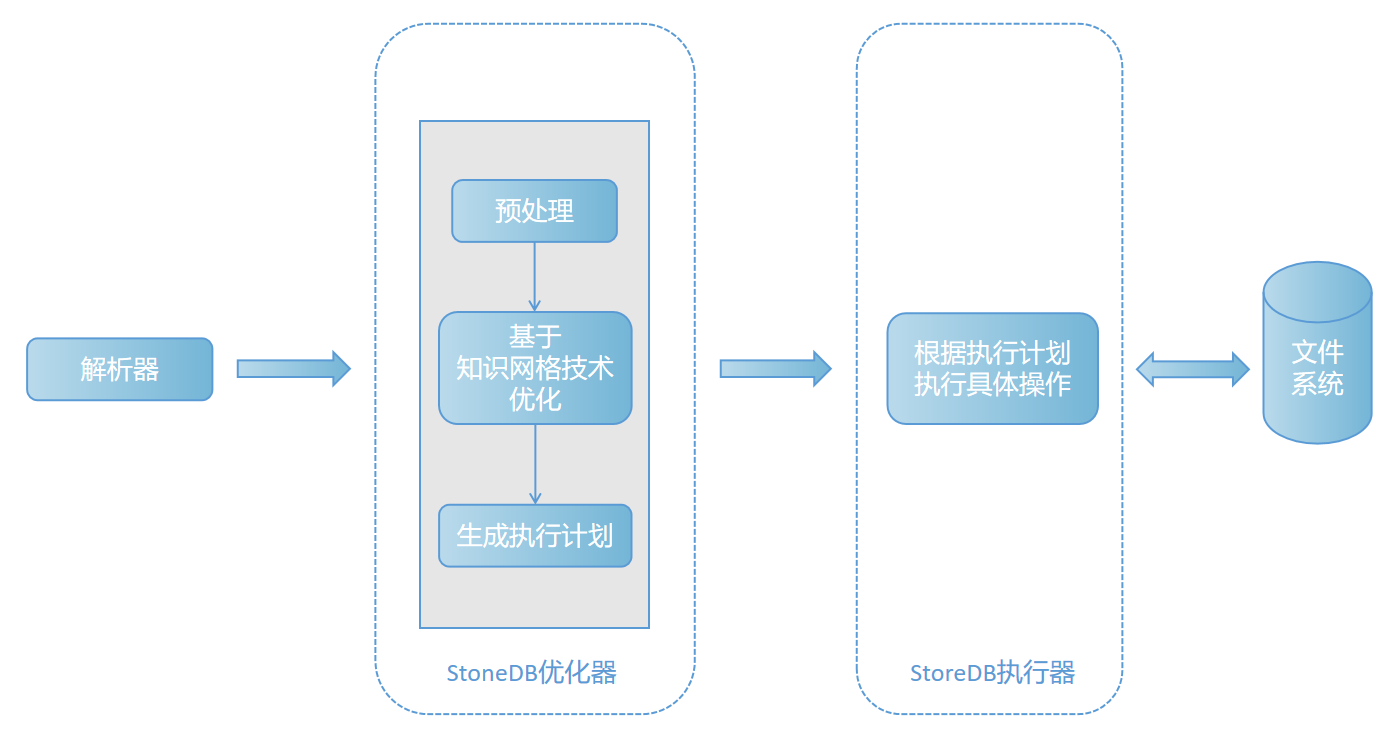
1. 功能入口
SDB_HandleSelect()
2. 预处理
为整个查询做预处理,包括子查询。进一步检查参数合法性,having 等条件的处理,形成更准确的计算描述,生成一个优化过的解析树。
函数接口:
prepare()
3. 优化
一个查询语句可能有多个执行方案,优化器基于独特的知识网格技术,计算出最优的查询方案。
函数接口:
optimize()
4. 执行器
根据优化器给的执行计划,实施具体操作。
函数接口:
Execute()