过去的一年,是大语言模型快速发展的一年。大模型强大的语言理解能力,逐渐让用户习惯了将各类文章丢给大模型,让它来帮忙总结提炼。从产品角度看,这是一次10倍体验的飞跃,意味着巨大的市场机会。也因此,市面上涌现出了大量的文档+大模型的应用。但大多数的开发者普遍都会遇到一个问题,那就是各种文档的效果都想做好,兼容起来太麻烦了,有没有更好的解决方案? 以PDF为例,通常大家会尝试选择开源工具,比如PyPDF2,但发现它们对中文的支持都不太好;有些对行业相对了解的开发者,可能会选择一些付费的OCR api,但往往结果都是按行输出,丢失了段落信息,更不用说对于表格,或者像论文这样的双栏版式的良好支持了。 行内人士都知道,LLM在训练时,通常会采用较多的论文或书籍等知识密度较高的语料。大家一般会采用Markdown格式作为训练语料,这种格式既简单,又能反映一些基本的排版,能很好地表征论文和书籍中的信息。那么很自然地想到,如果模型在做文档问答推理时,给到的内容也是Markdown格式的,效果会不会更好? 对于这个问题,合合信息的回答是肯定的。 合合信息实验结果表明:在同一批合同数据上,用Llama-7B模型,同样的Prompt做信息抽取,比较纯OCR和markdown格式输出的差异,结果发现,Markdown格式的抽取准确率要高于纯 OCR输出不少。 也因此,合合信息决定将智能文字处理领域十几年的积累都利用起来,为当前大模型浪潮下的开发者们,打造一款LLM友好的文档解析产品。 大模型问答应用需要一款怎样的PDF解析工具 经过调研发现,一款好用的PDF解析工具,至少要有3个特性:一是速度快、二是精度高、三是兼容性好。
- 速度快,是指解析一个文件的耗时要在秒级。尤其对于C端应用而言,如果用户上传一个300页的文档,结果要等上5分钟,这个体验一定是灾难性的。
- 精度高,是指对于各类版面元素都要有不错的识别效果。不管是公式、表格、还是相对复杂的排版,都能正确理解并准确还原。其中尤其以表格最为关键,如果表格的行列信息错位,会直接导致LLM在理解结论时出错。
- 兼容性好,是指对于繁杂的PDF编码格式都能正确识别,不会出现乱码、大量丢字等现象。
- 作为基础设施,稳定性是立身之本,尤其对于需要文档解析来提供线上服务的应用来说,如果底层基建不响应,精心设计的上层应用自然难以发挥应有的价值。
- 至于成本,对于要处理大量文件数据的业务而言,一点成本差异乘以巨大的文件数量,也可能导致最终成本难以接受。
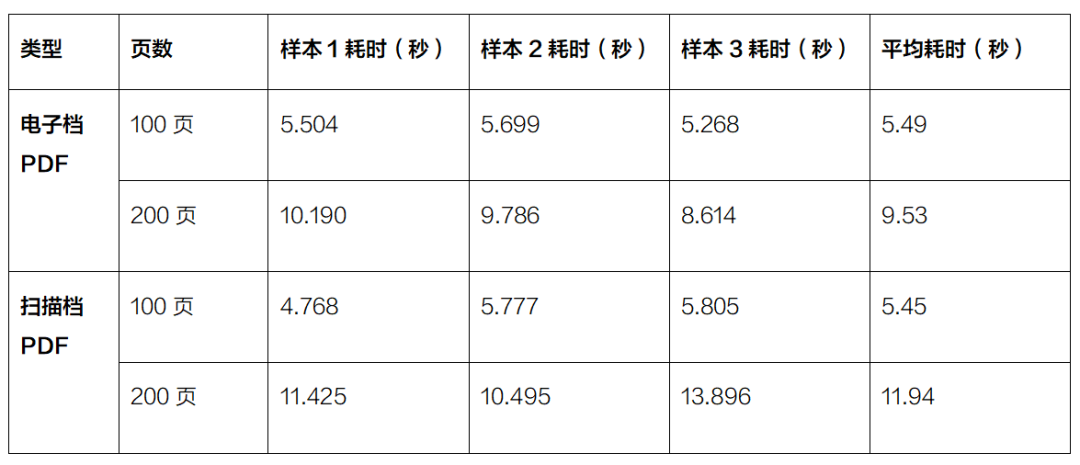 同时,团队也测试了不同尺寸的单张图片耗时:
同时,团队也测试了不同尺寸的单张图片耗时:
 目前产品还在针对速度做进一步的优化,内部最快的版本,100页的耗时P90小于2.5s,预计5月会上线。
2)精度与兼容性
为了直观展示使用合合信息解析能力后的效果,团队做了一次对比测试。
先用一批样本放到当前主流的几个大模型问答产品中,针对特定内容进行提问。然后挑选出各家产品均未能答对的样本,将其通过合合信息的接口输出为Markdown格式。由于目前仅有两家支持.md格式,因此团队手动将文件后缀改为.txt。然后将该.txt文件上传到各家产品中,再问和之前同样的问题,看回答情况是否有改善。
展示几张主要的结果:
首先是一个扫描件中的无线表格样本。某热门的大模型问答产品,在使用自带的解析时,找到的信息和表格内容不符;换用合合信息的解析结果之后,就能找对正确的数字了。
目前产品还在针对速度做进一步的优化,内部最快的版本,100页的耗时P90小于2.5s,预计5月会上线。
2)精度与兼容性
为了直观展示使用合合信息解析能力后的效果,团队做了一次对比测试。
先用一批样本放到当前主流的几个大模型问答产品中,针对特定内容进行提问。然后挑选出各家产品均未能答对的样本,将其通过合合信息的接口输出为Markdown格式。由于目前仅有两家支持.md格式,因此团队手动将文件后缀改为.txt。然后将该.txt文件上传到各家产品中,再问和之前同样的问题,看回答情况是否有改善。
展示几张主要的结果:
首先是一个扫描件中的无线表格样本。某热门的大模型问答产品,在使用自带的解析时,找到的信息和表格内容不符;换用合合信息的解析结果之后,就能找对正确的数字了。
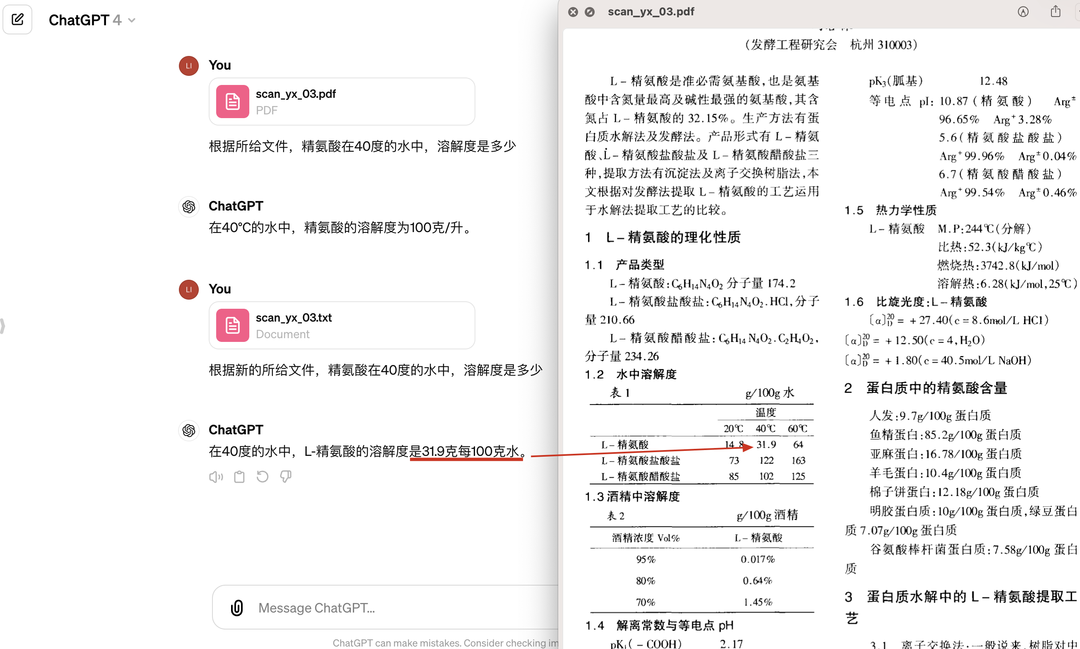 一张数百页的扫描版书籍,使用自带解析结果时,回答内容并不完全准确,换合合信息的解析结果后,就和原文信息完全能对上了。
一张数百页的扫描版书籍,使用自带解析结果时,回答内容并不完全准确,换合合信息的解析结果后,就和原文信息完全能对上了。
 最后是一张会乱码的电子版论文,打开并复制第一段前两行内容后,粘贴出来是乱码,如下:
最后是一张会乱码的电子版论文,打开并复制第一段前两行内容后,粘贴出来是乱码,如下:
|
? <=>?@ABCD $ "@A % KLMN?@OP QABCDRSTU?VWX89YZ[?@AB |
 如果尝试过基于开源PDF解析工具,或是开源OCR方案,搭建自己的PDF解析服务的开发者们,应该对文档处理的复杂程度有很深刻的体会。要么是公式精度不够高,输出的latex格式经常语法错误;要么是layout识别不好,需要拼接别的方案;再或者就是花大量的时间维护一套规则,去兼容奇怪的格式。
合合信息想做的,就是帮各位开发者们节省自己宝贵的生产力,和文档打交道这样的麻烦事,让我们来就好。开发者们的精力,如果用来构建自身产品的优势,往往会发挥更大的价值。
3)稳定性——低于万分之一的失败率
当前产品的公有云版本已正式上架,一个多月以来,经过多次迭代,目前的稳定性可以做到页面失败率小于万分之0.5。当然,这也不是终点,合合信息的产品团队期望将整体错误率降低到百万分之一以下,从而为开发者们提供足够可靠的产品。
4)成本——低至1分钱/页
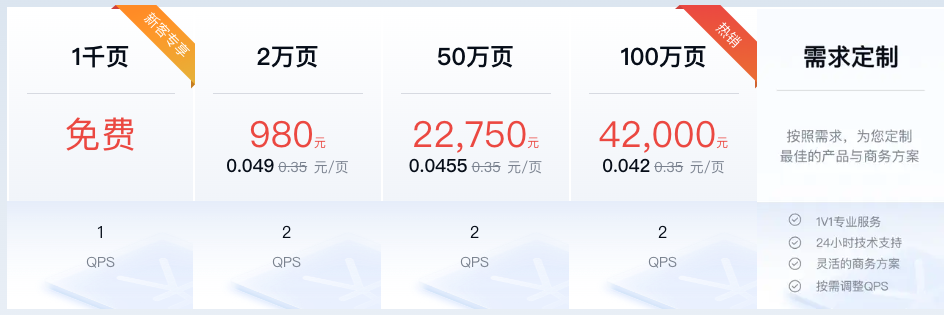
目前平台上提供3个套餐可选,如下图所示:
如果尝试过基于开源PDF解析工具,或是开源OCR方案,搭建自己的PDF解析服务的开发者们,应该对文档处理的复杂程度有很深刻的体会。要么是公式精度不够高,输出的latex格式经常语法错误;要么是layout识别不好,需要拼接别的方案;再或者就是花大量的时间维护一套规则,去兼容奇怪的格式。
合合信息想做的,就是帮各位开发者们节省自己宝贵的生产力,和文档打交道这样的麻烦事,让我们来就好。开发者们的精力,如果用来构建自身产品的优势,往往会发挥更大的价值。
3)稳定性——低于万分之一的失败率
当前产品的公有云版本已正式上架,一个多月以来,经过多次迭代,目前的稳定性可以做到页面失败率小于万分之0.5。当然,这也不是终点,合合信息的产品团队期望将整体错误率降低到百万分之一以下,从而为开发者们提供足够可靠的产品。
4)成本——低至1分钱/页
目前平台上提供3个套餐可选,如下图所示:
 如果觉得用量很大,也可以联系商务切换为后付费机制,每月180万页以上调用的,即可按1分钱/页计费。
5)One more thing
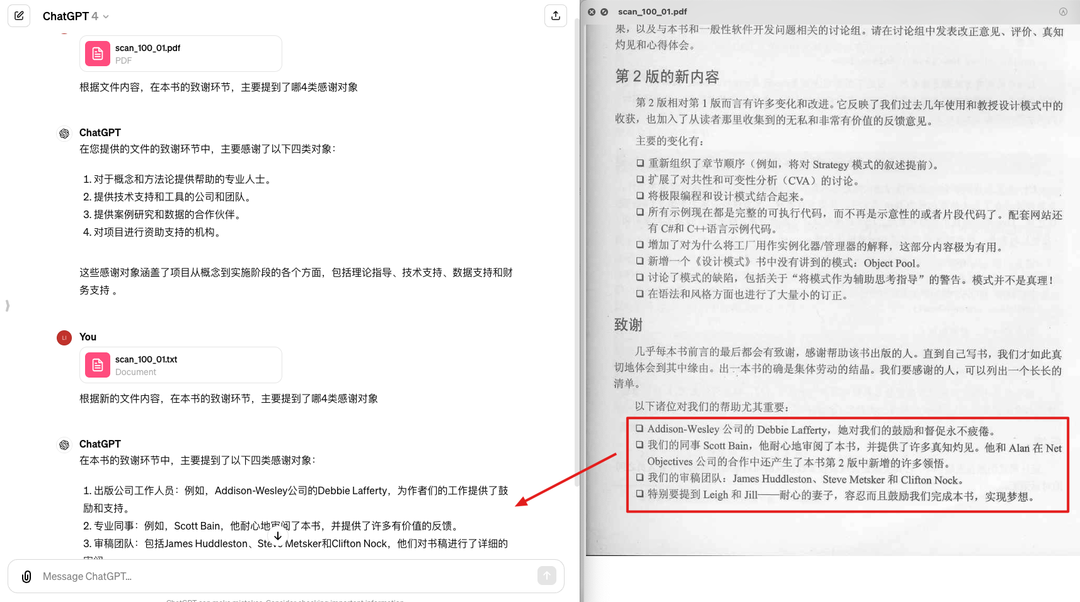
过去几个月里,合合信息在金融年报和研报场景下做了不少优化,尤其处理了各种年报中最难的无线表格和合并单元格等。这里向大家汇报一下成果。
首先是对于年报中的多行表头或多行单元格,合合信息的产品能够正确的划分结构,而多数识别引擎会错误折行,或是把第一行表头丢掉。
如果觉得用量很大,也可以联系商务切换为后付费机制,每月180万页以上调用的,即可按1分钱/页计费。
5)One more thing
过去几个月里,合合信息在金融年报和研报场景下做了不少优化,尤其处理了各种年报中最难的无线表格和合并单元格等。这里向大家汇报一下成果。
首先是对于年报中的多行表头或多行单元格,合合信息的产品能够正确的划分结构,而多数识别引擎会错误折行,或是把第一行表头丢掉。
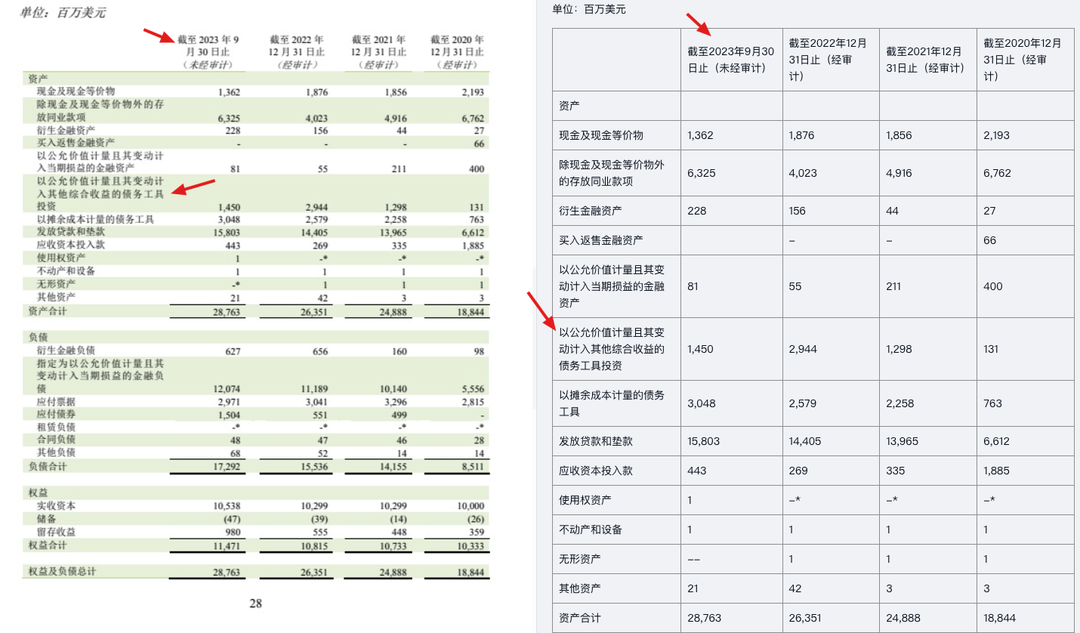 再来一个更复杂的Case,上表中,数据部分只有第一列是多行,干扰情况可能还好。下面这张样本中第二个框里,第一列和后面的数据列,都是多行,不少识别引擎就会将其拆分成多行表格,而实际上,这里应该只有一行。
再来一个更复杂的Case,上表中,数据部分只有第一列是多行,干扰情况可能还好。下面这张样本中第二个框里,第一列和后面的数据列,都是多行,不少识别引擎就会将其拆分成多行表格,而实际上,这里应该只有一行。
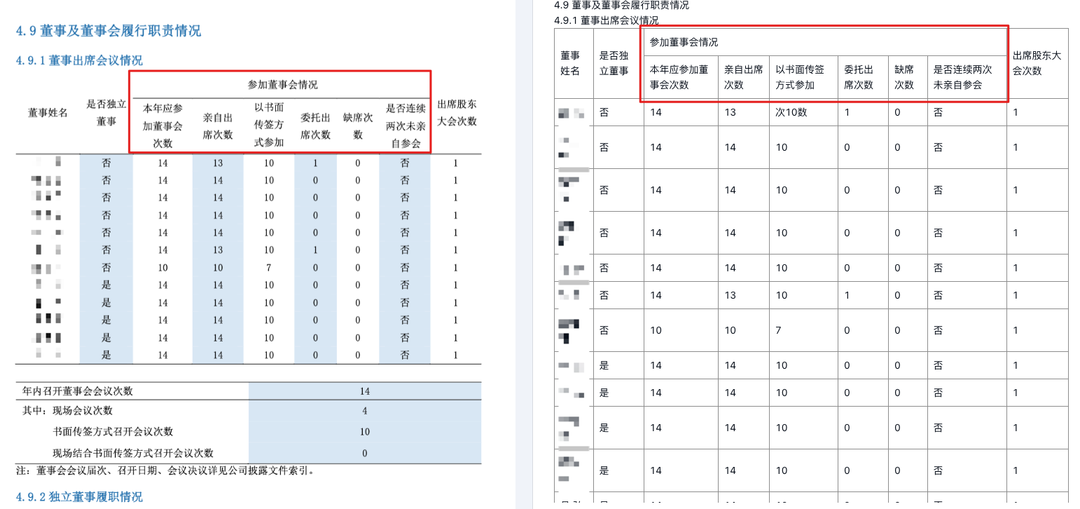 同时,从这个样本也可以看出,对于大多数合并单元格的样本,合合信息的文档解析能按照原始样式进行还原,而不是胡乱拆分。
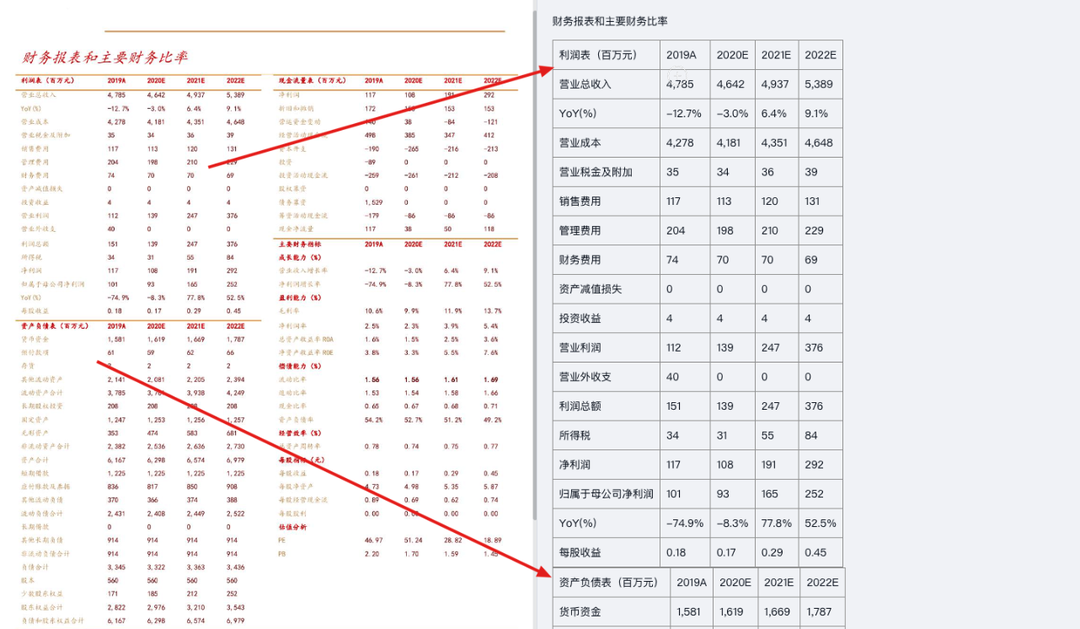
对于研报这种一页里紧密排了好几张表的样本,合合信息的文档解析也能按正确的顺序和归属,将数据分类对应,拆成独立的表输出。
同时,从这个样本也可以看出,对于大多数合并单元格的样本,合合信息的文档解析能按照原始样式进行还原,而不是胡乱拆分。
对于研报这种一页里紧密排了好几张表的样本,合合信息的文档解析也能按正确的顺序和归属,将数据分类对应,拆成独立的表输出。
 如何使用
合合信息文档解析产品已经上架TextIn平台,任何开发者都可以注册账号并开通使用。
https://www.textin.com/market/detail/pdf_to_markdown
如何使用
合合信息文档解析产品已经上架TextIn平台,任何开发者都可以注册账号并开通使用。
https://www.textin.com/market/detail/pdf_to_markdown
 访问链接,点击【免费体验】,即可在线试用,如下图所示:
访问链接,点击【免费体验】,即可在线试用,如下图所示:
 如果想试试用代码调用,也可以访问对应的接口文档内容:TextIn - API中心 - 通用文档解析。平台提供了一个Playground,帮开发者们预先调试接口。
如果想试试用代码调用,也可以访问对应的接口文档内容:TextIn - API中心 - 通用文档解析。平台提供了一个Playground,帮开发者们预先调试接口。
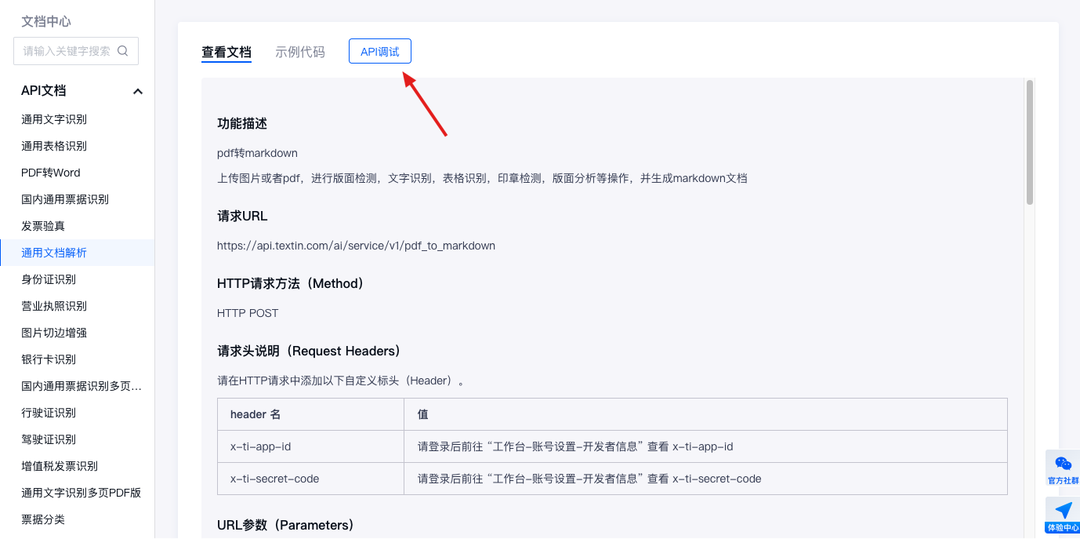 点击页面中【API调试】按钮,即可进入调试页面。
点击页面中【API调试】按钮,即可进入调试页面。
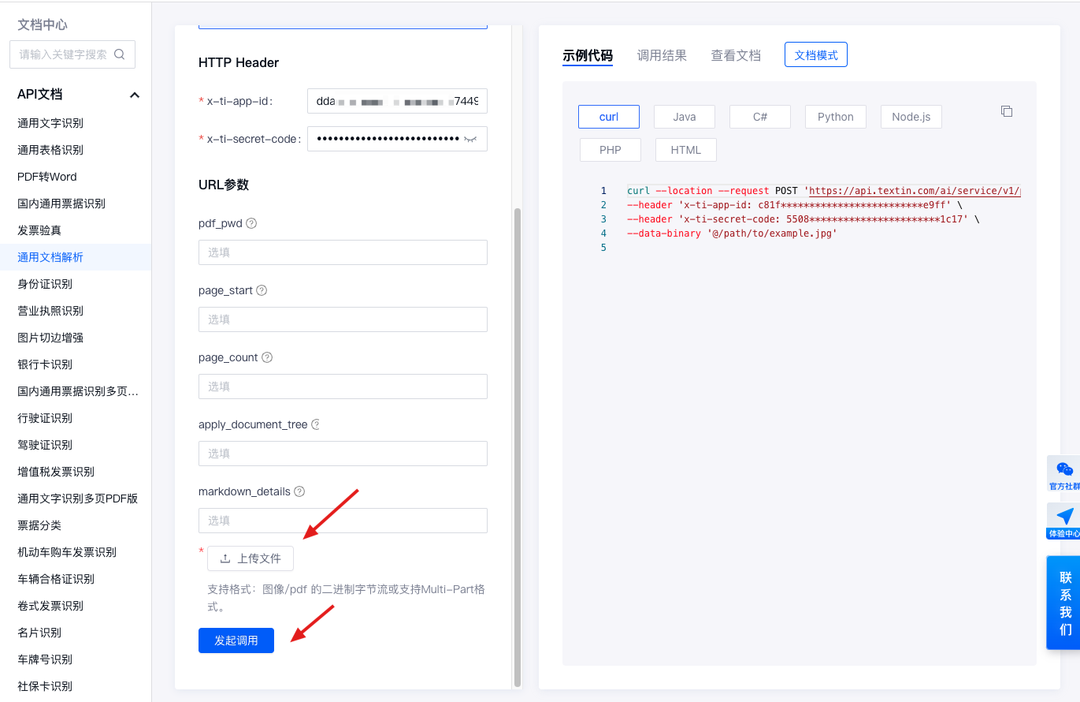 在这里,可以简单配置一些接口参数,发起调用后,右侧即会出现调用结果。
如果想用python调用,既可以参考平台上的通用示例代码,也可以关注公众号《合研社》,获取一些更全面的demo代码。
尾声
文档解析产品目前正处于内测阶段。正式产品通常有1000页的免费试用额度,在内测期间,平台给每位开发者提供每周7000页的额度福利,关注公众号《合研社》即可领取。欢迎大家提意见或建议。
同时,也欢迎更多从业者来与合合信息技术团队交流,多多讨论,多多碰撞。
标签:触达大,信息,合合,文档,开发者,PDF,解析,精准
From: https://www.cnblogs.com/intsig/p/18185883
在这里,可以简单配置一些接口参数,发起调用后,右侧即会出现调用结果。
如果想用python调用,既可以参考平台上的通用示例代码,也可以关注公众号《合研社》,获取一些更全面的demo代码。
尾声
文档解析产品目前正处于内测阶段。正式产品通常有1000页的免费试用额度,在内测期间,平台给每位开发者提供每周7000页的额度福利,关注公众号《合研社》即可领取。欢迎大家提意见或建议。
同时,也欢迎更多从业者来与合合信息技术团队交流,多多讨论,多多碰撞。
标签:触达大,信息,合合,文档,开发者,PDF,解析,精准
From: https://www.cnblogs.com/intsig/p/18185883