Mybatis-Plus 简介
Mybatis -Plus (简称MP) 是一个Mybatis的增强工具,在Mybatis的基础上只做增强不做改变,为简化开发,提高效率而生。
愿景:
我们的愿景是成为 MyBatis 最好的搭档,就像 魂斗罗 中的 1P、2P,基友搭配,效率翻倍。
{kind=link}

特性:
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
框架结构

配置
引入MybatisPlus的起步依赖:
MybatisPlus官方提供了starter,其中集成了Mybatis 和 MybatisPlus的所有功能,并且实现了自动装配效果。因此我们可以用MybatisPlus的starter代替Mybatis的starter。
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
在 application.yml 配置文件中添加数据库的相关配置
spring:
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://域名:端口/库名?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
username: 用户名
password: 密码
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射
map-underscore-to-camel-case: true
# 使用指定的日志实现,这里是输出到控制台
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
# 指定主键 ID 的生成策略为手动赋值,意味着你需要在插入数据时手动设置主键的值。其他常见的主键生成策略包括 AUTO(自动增长)、UUID(使用UUID作为主键)等。
id-type: ASSIGN_ID
常见注解
MP 通过扫描实体类,并基于反射获取实体类信息作为数据库表信息。
实体类有很多数据,哪些可以转为数据库表信息呢?
1.类名驼峰转下划线作为表名
2.名为id的字段作为主键
3.变量名驼峰转下划线作为表的字段名

默认约定大于配置。如果实体类信息不符合约定,需通过注解手动说明。
- @TableName: 指定表名字
比如实体类的表名不符合约定, 需使用TableName 指定表名

- @TableId:用来指定表中的主键字段信息

实体类的id 字段默认为是表的主键,如果表的主键名称不是id,需要@TableId指明。
IdType 常用的三种主键策略:
1.AUTO:数据库自增长 (数据库自动生成)
2.INPUT:通过set方法由程序员自行输入 (人操作生成)
3.ASSIGN_ID:分配ID,(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法)。 (MP 自动生成)
4.ASSIGN_UUID: 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) 。(MP自动生成)
实体类中如果没有指定IdType则按照 application.yml 配置文件的id-type生成主键。
- TableField:用来指定表中的普通字段信息
使用@TableFiled的常见场景:
1.成员变量名与数据库表字段名不一致
2.成员变量名以is开头,且是布尔值
对于is开头并且是布尔类型的成员变量,在通过反射机制会将is去掉,那么就起不到驼峰转下划线的效果,因此is开头的布尔类型成员变量需要用@TableField注解。
3.成员变量名与数据库关键字冲突,需用@TableField注解,且要将关键字写在反引号中
4.成员变量不是数据库字段
成员变量不是数据库字段,需用@TableField(exist=false)
- @TableLogic: 表字段逻辑处理注解(逻辑删除)
@TableLogic 对增删改查的影响:
实体类:

新增:不做限制。
查询(select): @TableLogic注解将会在select 语句的where 条件追加条件,过滤掉已删除的数据,且使用wrapper.entity生成的where条件会忽略改字段。
如 select id,name,sort from category where type =1 and is_deleted=0
更新(update):@TableLogic注解会在update 语句的where条件追加条件,防止更新到已删除的数据,且使用wrapper.entity生成的where条件会忽略改字段。
如 update user set name='Jack' where id=123 and is_deleted=0
删除(delete):@TableLogic 注解会将delete语句转变成update语句, 进行逻辑删除。
如 update user set is_deleted=1 where id=123;
核心功能
条件构造器
MP支持各种复杂的where条件,可以满足日常开发的所有需求。
BaseMapper 中除了id操作的方法外,还有一些是基于Wrapper参数的方法。

Wraper是个抽象类,下面有很多的子类。

AbstractWrapper抽象类定义了常用的方法,见下图:

AbstractWrapper能够满足复杂的where条件,那么子类QueryWrapper、UpdateWrapper在父类的基础上做了哪些拓展?
QueryWrapper 拓展查询,select语句指明了具体查询哪些字段, 如 select Id, username, sort from user where id=1。 AbstractWrapper 查询语句默认返回所有字段, select * from user where id=1.

案例:查询名字中带王的,性别=男性的员工Id,name,usename;
![]()

UpdateWrapper拓展更新,更新一般是update user set name=? where id=? ,但有些特殊场景,比如原来余额基础上减少200. ---> update user set balance= balance -200 where id in (1,2,3)。 setSql(boolean,String) 将set 部分允许以SQL语句形式传递进去。

案例:更新name为王武、李斯的积分,扣200
![]()

BaseMapper中除了新增外,删除、更新、删除都可以使用Wrapper。 除了Query/UpdateWrapper, 还有LambdaQueryWrapper、LambdaUpdateWrapper。后面两者和前者相比使用了Lambda语法。使用Query/UpdateWrapper时需指定表字段名,在开发规约中属于硬编码,LambdaQuery/UpdateWrapper可以解决硬编码问题。

条件构造器的用法总结:
- QueryWrapper 和LambdaQueryWrapper常用来构建select、delete、update的where条件部分
- UpdateWrapper 和 LambdaUpdatWrapper通常只有在set语句比较特殊才使用
- 尽量使用LambdaQueryWrapper和LambdaUpdatWrapper,避免硬编码
自定义SQL
MP提供了完善的条件构造器,为什么还要自定义SQL呢?
MP的Wrapper构建where条件很方便,但有些特殊场景需要在业务层拼接SQL,这违反了开发规范。如以下情况:

在这种场景下SQL语句中的where条件用wrapper构建,where条件外的其他部分自定义。
自定义SQL的三个步骤:
①基于Wrapper构建where条件
②在mapper方法参数中用@Param注解声明wrapper变量名称,必须是ew
③自定义SQL,并使用wrapper条件
引用条件构造器UpdateWrapper的案例:更新name为王武、李斯的积分,扣200

IService接口
IService接口和BaseMapper相比只多不少。BaseMapper是MP提供的一个基础映射器接口,它继承了Mybatis的Mapper接口,提供了CRUD操作的方法。通过继承BaseMapper,我们可以方便地实现数据库的增删改查操作,而无需编写SQL语句。ServiceImpl是MP提供的服务实现类,它实现了IService接口并提供了具体的方法实现。在ServiceImpl中,我们根据实际业务需求编写具体的实现逻辑,并调用BaseMapper中定义的数据库操作方法。通过ServiceImpl,我们可以将业务逻辑与数据库操作解耦,提高代码的可维护性和可扩展性。此外IService接口则提供了更高级的CRUD操作方法,如批量查询、批量删除和分页查询等等。
IService新增、修改、删除、查询接口如下:


BaseMapper的接口:

MP的Service接口使用流程是怎样的?
①自定义Service接口继承IService接口

②自定义Service实现类,实现自定义接口并继承ServiceImpl类

IService及ServiceImpl类底层就是调用BaseMapper,所以在自定义Service实现类时需指明Mapper和实体类。
IService 在根据业务的复杂程度,我们可以使用基本的CRUD接口,复杂的业务场景也可以自定义方法,也可以使用lambda构建复杂where条件,大批量数据可以使用批量接口。
IService 基础操作
如果没有复杂的业务逻辑,可以直接调用IService提供的CRUD接口操作。
@SpringBootTest
@RunWith(SpringRunner.class)
public class DishServiceTest {
@Autowired
DishServiceImpl dishService;
/**
* 删除菜品
*/
@Test
public void test_deleteDishById() {
Long id = 1772300032641380353L;
dishService.removeById(id);
}
/**
* 查询单个菜品
*/
@Test
public void test_getDishById() {
Long id = 1397854652581064706L;
Dish dish = dishService.getById(id);
System.out.println(JSON.toJSONString(dish));
}
/**
* 批量查询菜品
*/
@Test
public void test_queryDishBatch() {
List<Long> ids = Arrays.asList(1397854652581064706L, 1397853709101740034L, 1397853183287013378L, 1397860963880316929L);
List<Dish> list = dishService.listByIds(ids);
System.out.println("批量查询菜品" + JSON.toJSONString(list));
}
}
以上代码中均是调用IService基本的CRUD接口。
IService自定义方法
如果业务逻辑比较复杂,IService基本的CRUD接口满足不了业务要求时则需要在Service中自定义方法来实现。或者业务逻辑需要在mapper.xml中编写复杂的SQL才能处理,那么也需要在Service中自定义方法来调用mapperl满足需求。
需求:根据id修改用户余额,要求
1.在扣减余额时校验用户状态,用户是正常状态才做扣减;
2.扣减用户余额;
需求分析:1.根据Id查询到用户->判断用户是否存在、用户状态是否正常-> 存在&状态正常,扣减用户余额。
SQL: update tb_user set balance = balance - 扣减金额;
MP的Service、BaseMapper常规接口无法满足要求,那么需要在mapper中定义SQL:
public interface TbUserMapper
extends BaseMapper<TbUser> {
List<TbUser> queryUsers(String username, Integer status, Long minBalance, Long maxBalance);
//mapper中定义SQL有两种方式,第一种在xml编写SQL
void deductBalanceById(Long id, Long amount);
//mapper中定义SQL有两种方式,第二种使用注解
@Update("update tb_user set balance = balance - #{amount} where id = #{id}")
void deductBalance(@Param("id") Long id, @Param("amount") Long amount);
}
Service中自定义方法校验业务逻辑及调用mapper方法:
@Override
public void deductBalanceById(Long id, Long amount) {
TbUser tbUser = getById(id);
//检查用户状态是否正常
if (Objects.isNull(tbUser) || tbUser.getStatus() != 1) {
throw new RuntimeException("用户不存在或状态异常!");
}
//检查余额是否充足
if (tbUser.getBalance() < amount) {
throw new RuntimeException("用户余额不足!");
}
baseMapper.deductBalanceById(id, amount);
}
IService 的lambda用法
Lambda查询
需求:实现一个根据复杂条件查询的接口,查询条件如下:
1.username: 用户名,可以为空
2.status: 用户状态,可以为空
3.minBalance: 最小金额,可以为空
4.maxBalance: 最大金额,可以为空
上面的复杂查询按照mybatis的mapper.xml做法,SQL长这样
<mapper namespace="com.guosou.reggie.mapper.TbUserMapper">
<select id="queryUsers" resultType="com.guosou.reggie.entity.TbUser">
select * from tb_user
<where>
<if test="name !=null ">
AND username like #{name}
</if>
<if test="status !=null">
and `status` = #{status}
</if>
<if test="minBalance !=null and maxBalance!=null">
and balance between #{minBalance} and #{maxBalance}
</if>
</where>
</select>
</mapper>
public interface TbUserMapper extends BaseMapper<TbUser> {
List<TbUser> queryUsers(String username, Integer status, Long minBalance, Long maxBalance);
}
// Lambda查询
public class TbUserServiceImpl extends ServiceImpl<TbUserMapper, TbUser> implements ITbUserService { /** * 根据 用户名、状态、金额范围查询 * * @param username 用户名 * @param status 状态 * @param minBalance 最小金额 * @param maxBalance 最大金额 * @return User */ public List<TbUser> queryUsers(String username, Integer status, Long minBalance, Long maxBalance) { return lambdaQuery() .like(StringUtils.isNotEmpty(username), TbUser::getUsername, username) .eq(Objects.nonNull(status), TbUser::getStatus, status) .ge(Objects.nonNull(minBalance), TbUser::getBalance, minBalance) .le(Objects.nonNull(maxBalance), TbUser::getBalance, maxBalance) //.page() 查分页 //.count() 查条数 //.oneOpt() 查一条 .list(); }
Lambda更新
需求:根据id修改用户余额,要求
1.在扣减余额时校验用户状态,用户是正常状态才可扣减;
2.对用户余额做校验、如果扣减后余额为0,则将用户状态修改为冻结状态。
@Override
public void deductBalance(Long id, Long amount) {
TbUser tbUser = getById(id);
//检查用户状态是否正常
if (Objects.isNull(tbUser) || tbUser.getStatus() != 1) {
throw new RuntimeException("用户不存在或状态异常!");
}
//检查余额是否充足
if (tbUser.getBalance() < amount) {
throw new RuntimeException("用户余额不足!");
}
long balance = tbUser.getBalance() - amount;
lambdaUpdate()
.set(TbUser::getBalance, balance)
.set(balance == 0, TbUser::getStatus, 2)
.eq(TbUser::getId, id)
.update();
}
lambdaUpdate()要记得最后调用update()方法否则不执行的。
IService 批处理操作
需求:批量插入1000条用户数据,并作出对比。
1.普通for循环插入
2.IService的批量插入
1 package com.guosou.reggie.service;
2
3 import com.guosou.reggie.entity.TbUser;
4 import com.guosou.reggie.service.impl.TbUserServiceImpl;
5 import org.junit.Test;
6 import org.junit.runner.RunWith;
7 import org.springframework.beans.factory.annotation.Autowired;
8 import org.springframework.boot.test.context.SpringBootTest;
9 import org.springframework.test.context.junit4.SpringRunner;
10
11 import java.util.ArrayList;
12 import java.util.List;
13
14 @SpringBootTest
15 @RunWith(SpringRunner.class)
16 public class TbUserServiceTest {
17
18 @Autowired
19 TbUserServiceImpl tbUserService;
20
21 private TbUser buildUser(int i) {
22 TbUser user = new TbUser()
23 .setUsername("user_" + i)
24 .setPassword("123456")
25 .setPhone("12345678911")
26 .setStatus(2)
27 .setBalance(1000);
28 return user;
29 }
30
31 /**
32 * 普通for循环插入User
33 */
34 @Test
35 public void test_normalSaveBatch() {
36 long a = System.currentTimeMillis();
37 for (int i = 0; i < 1000; i++) {
38 tbUserService.save(buildUser(i));
39 }
40 long b = System.currentTimeMillis();
41 System.out.println("save 耗时:" + (b - a));
42 }
43
44 /**
45 * IService 批处理插入User
46 */
47 @Test
48 public void test_saveBatch() {
49 List<TbUser> list = new ArrayList<TbUser>(100);
50 Long a = System.currentTimeMillis();
51 for (int i = 0; i < 1000; i++) {
52 list.add(buildUser(i));
53 if (i % 100 == 0) {
54 tbUserService.saveBatch(list);
55 list.clear();
56 }
57 }
58 long b = System.currentTimeMillis();
59 System.out.println("saveBatch 耗时:" + (b - a));
60 }
61 }
普通for循环插入耗时:

IService的批量插入,JDBC参数rewriteBatchedStatements=false 耗时:

IService的批量插入,JDBC参数rewriteBatchedStatements=true 耗时:

批处理方案:
- 普通for循环逐条插入速度极差,不推荐
普通for循环差的原因有两点,一是每次请求只提交一条SQL语句,数据越多请求量也越多,比较耗时。其次是每条SQL也是逐条执行的,导致执行性也较差。
上面10万条数据,实际上提交10万条inert SQL语句,请求了10万次然后执行10万次。
- MP的批量新增,基于预编译的批处理,性能不错
MP默认情况下的批处理,比如一次性提交1000条,那就是把它编译成1000条SQL一次性提交这样可以减少网络请求,所以性能上有所提升。但由于还是一条SQL执行一条数据,其实它并不是真正的批处理只是批量提交,在mysql执行的时候还是逐条执行的,所以性能上没有达到最好。
- 配置JDBC参数,开启rewriteBatchedStatements=true,性能最好
如果MySQL数据库批处理性能想要达到最好,需要加一个参数rewriteBatchedStatements=true。一旦开启这个参数,mySQL驱动会帮助我们将一条一条的SQL重写成一个SQL批量新增的语句,那么性能上会有非常大的提升了。
开启rewriteBatchedStatements=true,一条一条的SQL重写为一个SQL:

拓展功能
代码生成器
MP的官网介绍了两种代码生成器:以下是两种的详细介绍(但都不太好用)。Idea中有款MybatisPlus的插件,推荐使用这款简洁干净的插件。
第一种:springboot 项目依赖 mybatis-plus-generator 3.5.1以上版本,需要编写代码来自动生成mapper、service、impl等。
大概的步骤如下:
①安装
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.1</version>
</dependency>
②编写application.yaml配置文件:mysql配置
spring:
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://域名:端口/库名?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
username: 用户名
password: 密码
③编写代码根据表名自动生成相应代码
FastAutoGenerator.create("url", "username", "password")
.globalConfig(builder -> {
builder.author("baomidou") // 设置作者
.enableSwagger() // 开启 swagger 模式
.fileOverride() // 覆盖已生成文件
.outputDir("D://"); // 指定输出目录
})
.dataSourceConfig(builder -> builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> {
int typeCode = metaInfo.getJdbcType().TYPE_CODE;
if (typeCode == Types.SMALLINT) {
// 自定义类型转换
return DbColumnType.INTEGER;
}
return typeRegistry.getColumnType(metaInfo);
}))
.packageConfig(builder -> {
builder.parent("com.baomidou.mybatisplus.samples.generator") // 设置父包名
.moduleName("system") // 设置父包模块名
.pathInfo(Collections.singletonMap(OutputFile.xml, "D://")); // 设置mapperXml生成路径
})
.strategyConfig(builder -> {
builder.addInclude("t_simple") // 设置需要生成的表名
.addTablePrefix("t_", "c_"); // 设置过滤表前缀
})
.templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker引擎模板,默认的是Velocity引擎模板
.execute();
第二种:通过mybatisx插件自动生成代码,主要包含自动生成数据库实体和XML配置文件、根据Mapper的接口名自动生成xml配置、Mapper接口和xml自动跳转功能。
xml跳转

生成代码(需先在 idea 配置 Database 配置数据源)

重置模板

生成新增(生成修改、查询和生成新增类似)

第三种:在Idea中安装MyBatisPlus插件自动生成代码
①安装插件

②连接数据库 --> 选择表 --> 指明包路径、主键策略等,生成entity、mapper、controller、service及impl

枚举处理器
实体类某些字段使用枚举时会比较方便,比如用户状态,使用枚举会让代码更易读。但entity类中的枚举类型变量与数据库中的字段如何转换呢?

解决步骤:
1.给枚举中与数据库对应value值添加@EnumValue注解

2.在配置文件中配置统一的枚举处理器,实现类型转换
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射
map-underscore-to-camel-case: true
# 使用指定的日志实现,这里是输出到控制台
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 指明枚举处理器
default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
DB静态工具
逻辑删除
JSON处理器
Java 的数据类型和JDBC 数据类型之间时如何转换的?我们先看下MySQL数据类型与Java 数据类型的映射:
|
MySQL数据类型 |
Java实体类数据类型 |
说明 |
|
int |
Integer |
不管signed 还是unsigned,java实体类属性类型都是Integer |
|
bigint |
Long |
不管bignit多少位,不管signed 还是unsigned,java 实体类类型都是Long |
|
bit |
byte[] |
|
|
tinyint |
byte |
|
|
smallint |
short |
|
|
char |
String |
不管char是gbk、utf-8等编码类型,java实体类型都是String |
|
varchar |
String |
|
|
longvarchar |
String |
|
|
date |
Date |
java.util.Date |
|
datetime |
Date |
java.util.Date |
|
timestamp |
Date |
java.util.Date |
|
time |
Date |
|
|
float |
Float |
|
|
decimal |
Long |
|
|
numeric |
Long |
|
|
double |
Double |
|
|
tinytext |
String |
|
|
year |
Date |
|
|
enum |
String |
MP提供了字段类型转换器用来转换JDBC数据类型和Java数据类型的转换。
如果Java变量是个对象如何映射到数据库呢?
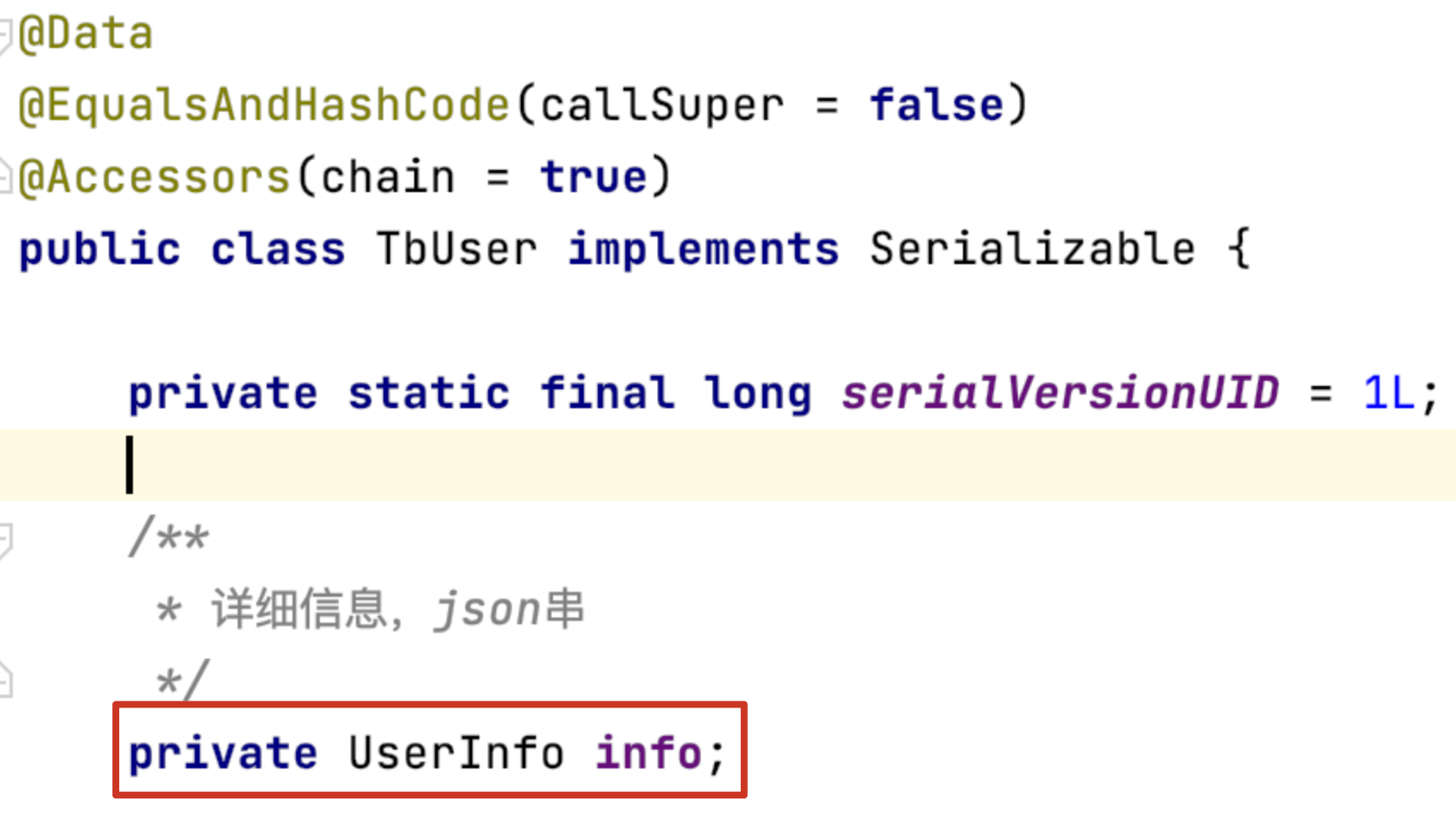
JSON处理器:
MP提供了三种JSON处理器:

三种处理器的区别实质上是处理Json的第三方不同。 GSON 是 Google 提供的Json解析函数库,FasJson是阿里巴巴的开源JSON解析库,JackJson 是 spring boot 官方内置得 json 解析库。为了不引进新的依赖,spring boot项目建议使用JacksonTypeHandler处理器。
步骤:
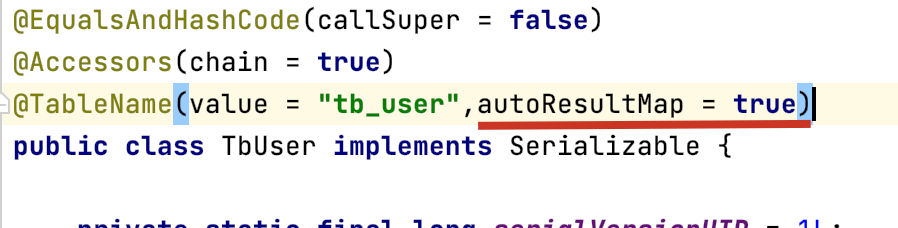
- 在需要转换成json的对象上添加@TableField注解

- 在类上指明autoResultMap=true
插件功能
分页插件基本用法
通用分页实体
通用分页实体与MP转换s
标签:IService,入门,自定义,Long,Plus,SQL,Mybatis,where,id From: https://www.cnblogs.com/sunsunhy/p/18143053