源地址:
背景
随着 ChatGPT、GPT4、PaLM2、文心一言各种大模型的爆火,我们在惊讶大模型能力的同时,也在不断的问自己一个问题,为什么 Decode-only 的 ChatGPT 拥有智能?
GPT 其实就是基于 Transformer 的 Decode-only,本质是就是 Next Token Prediction,为啥如此简单的结构,训练出来的大语言模型能够具备智能。
目前规模够大的 LLM 模型,在训练基座模型的时候,都采用 Next Token Prediction 任务。Next Token Prediction 如此简单的操作,就是通过语言中前面的单词,来产生下一个单词,很明显这样学到的不就是单词之间的表层统计关系吗?怎么就产生了智能?实在令人费解。
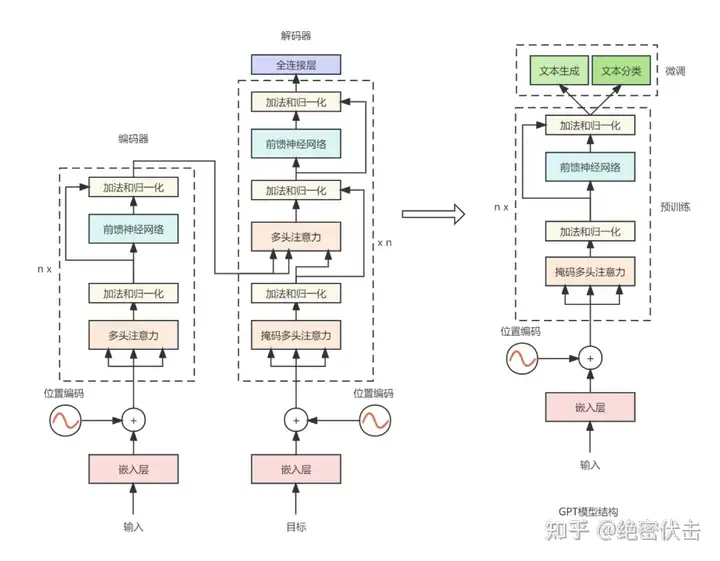
GPT模型
2月28日,OpenAI 的核心研发人员 Jack Rae 在参加 Stanford MLSys Seminar 的访谈时进行了一个名为 Compression for AGI 的主题分享,其核心观点为:AGI 基础模型的目标是实现对有效信息最大限度的无损压缩。并同时给出了为什么这个目标是合理的逻辑分析,以及 OpenAI 是如何在这个目标下开展工作的行动原则。

来源:Stanford MLSys Seminar
主讲人:Jack Rae(OpenAI)
视频链接:
背景:Jack Rae 是 OpenAI 的团队负责人,主要研究大型语言模型和远程记忆。此前,他在 DeepMind 工作了 8 年,领导大型语言模型 (LLM) 研究组。
在分享中,Jack Rae 给出了两个核心观点:
压缩即智能
LLM = Compression (GPT 的 Next Token Prediction 本质上是对训练数据的无损压缩)
通过论证压缩即智能,GPT 的训练过程是对数据的无损压缩,从而证明了 GPT 拥有智能。
Jack Rae 在 Stanford ML Seminar上的分享,听完之后感觉醍醐灌顶,通过压缩理论去论证为什么 GPT 拥有智能,是一个很独特的观点。
接下来就具体介绍下 Jack Rae 是如何论证的。
1. 压缩即智能
在介绍为什么压缩是一种实现通用人工智能(Artificial general intelligence, AGI)的方法之前,我们先介绍下什么是通用人工智能。
1.1 直观理解AGI
1980年,John Searle提出了一个著名的思想实验《中文房间》。实验过程可以表述如下:
将一个对中文毫无了解,只会说英语的人关在一个只有一个小窗的封闭房间里。房间里有一本记录着中英文翻译的手册。房间里还有足够的稿纸、铅笔。同时,写着中文的纸片通过小窗 口被送入房间中。房间中的人可以使用他的书来翻译这些文字并用中文回复。 虽然他完全不会中文,但通过这个过程,房间里的人可以让任何房间外的人以 为他会说流利的中文。

这样一个庞大的手册显然代表着非常低的智能水平,因为一旦遇到手册中没有的词汇,这个人就无法应对了。
如果我们能够从大量的数据中提取出一些语法和规则,那么手册可能会变得更加精简,但是系统的智能水平将会更高(泛化能力更强)。
手册越厚,智能越弱;手册越薄,智能越强。就好像公司雇一个人好像能力越强的人,你需要解释得越少,能力越弱,你需要解释得越多。
上面的例子比较值观的解释了为什么压缩即智能。
1.2 如何实现无损压缩
假设 Alice 需要把一个(可能无限长)的数据集 �={�1,�2,...,��,...} 从遥远的半人马座星系传输回地球上的 Bob,我们假设:
- �� 表示一个 token ,词表大小 �=256 , ��∈{0,1,…,255}
- Alice 和 Bob 都有足够的计算资源
- 假设现在已经传输了 �1:�, Alice 会将下一个 ��+1 编码为 ��+1 后传给 Bob
- Alice 希望 最小化传输的数据量 S ,以 number of bits 比特数量来衡量
-

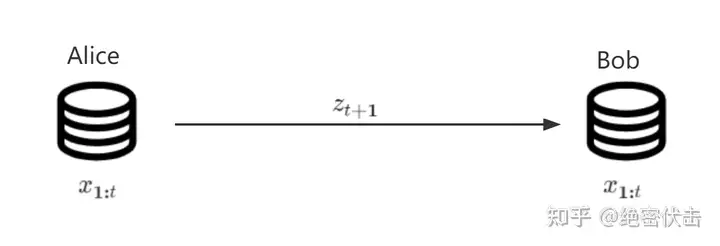
baseline 传输方法
由于 ��+1 的可能性有 �=256 种,所以 ��+1 可以表示为一个 8 bit 的整数(即一个 byte)。
例如当 ��+1=7 时, ��+1=00000111 表示 ��+1。
这时需要传输的位数 |��+1|=log�=log256=8。
其实,Alice 还要将上面的方法写成代码 �0,在一开始传输给 Bob。
这样传输一个大小为 � 的数据集 ��={�1,�2,...,��} 的代价 �0 为
�0=#����=|�0|+∑�=1�|��|=|�0|+�log�baseline 方法的概率解释

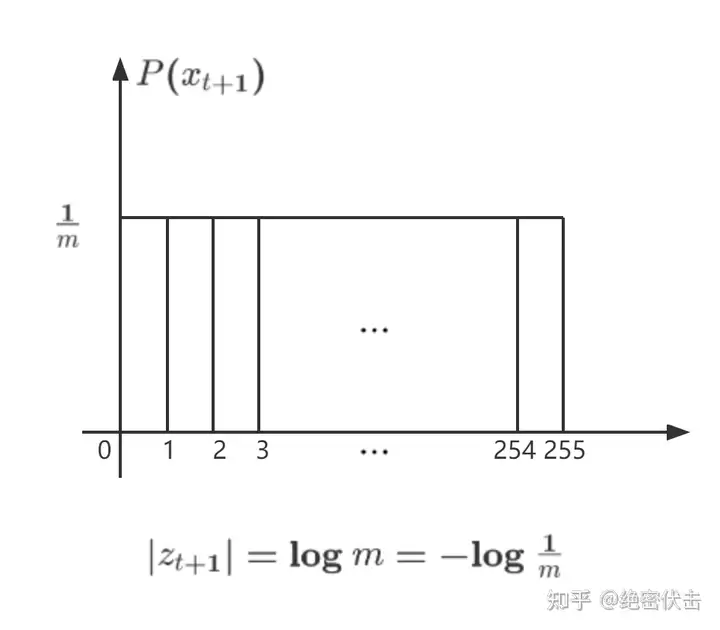
baseline 方法对于��+1的分布没有先验知识,故�(��+1)=1�是一个离散均匀分布。此时信息内容(Information content)为:
�=−log�(��+1)=−log1�=log�=|��+1|
故此时 |��+1| 也可以看作是 �(��+1) 的信息内容。

备注:


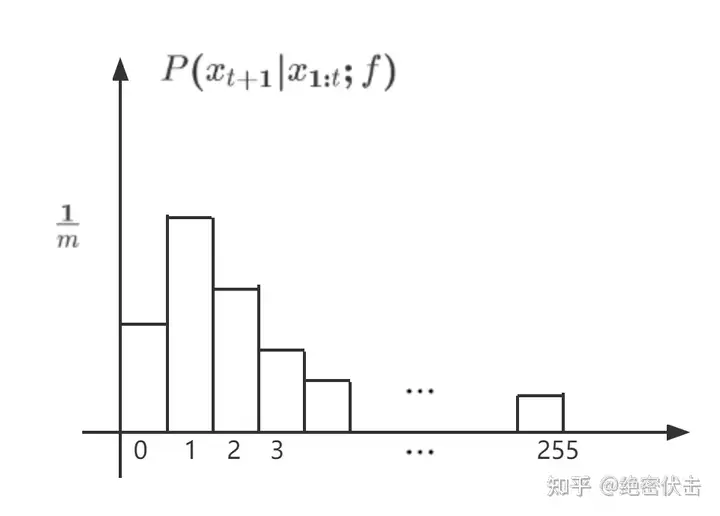

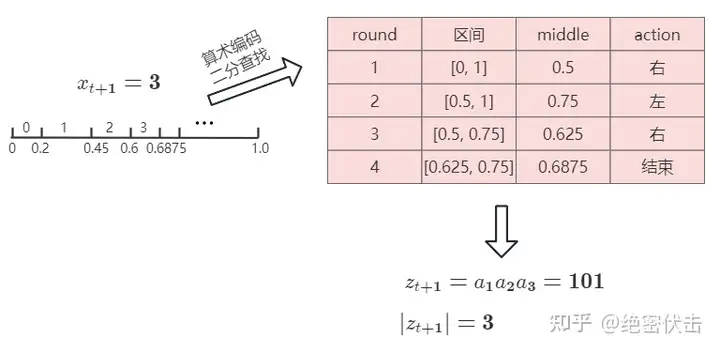

2. GPT 是对数据的无损压缩

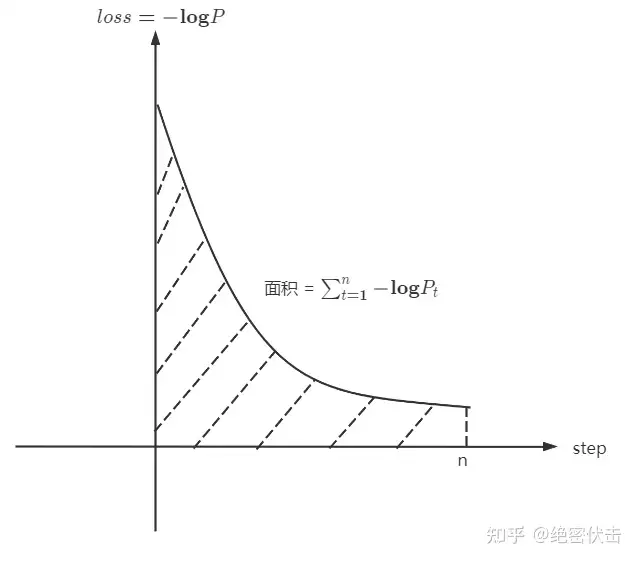



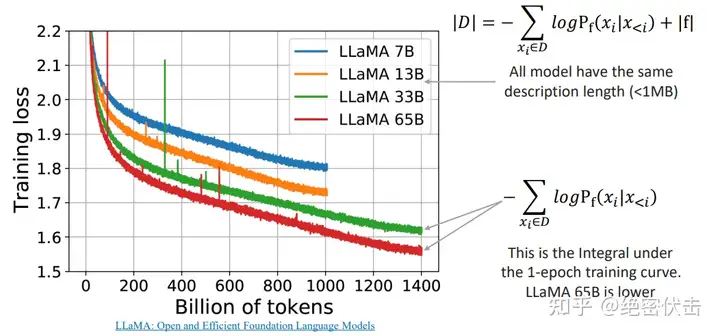
那么根据上面的结论,图中 LLaMA 65B 的 loss 面积最小,因此压缩率最高,模型效果往往也越好。
下面讨论下压缩率的变化。

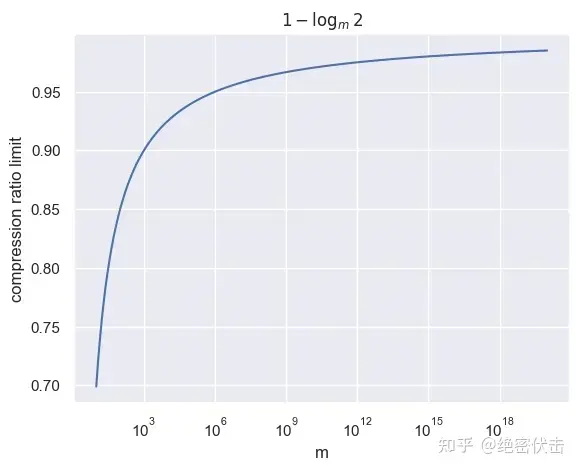
Next Token Prediction 虽然看似简单,但是却可以用压缩理论完美的解释,这也是为什么 OpenAI 坚持 Next Token Prediction 的原因。同时,压缩理论也印证了,为什么 BERT 的 “预测中间词” 从最终应用效果上比不上 GPT 系列始终坚持的“预测下一个词”。
3. Jack Rae:Compression for AGI
有了前面的基础,我们再来回顾 Jack Rae 的演讲内容,接下来理解起来就容易得多。
摘要:在本次演讲中,我们讨论了基础模型如何开始验证 70 多年前形成的假设:更好地压缩源数据的统计模型最终会从中学习更多基础和通用功能。我们首先介绍压缩的一些基础知识,然后描述跨越数千亿个参数的更大的语言模型实际上是最先进的无损压缩器。我们讨论了在实现最佳压缩的过程中可能会出现的一些新兴功能和持续限制。
演讲主题
- 深入思考基础模型的训练目标
- 思考我们正在做什么,为什么这样做是有道理的,局限性是什么
要点
- 找到解决感知问题的最小描述长度
- 生成模型是无损压缩器
- 大语言模型是 SOTA 的无损文本压缩器
- 现有压缩方法的局限性
- 局限性
目录
- 最小描述长度
- 用大语言模型进行无损压缩
- 具体实现
- 局限性和总结
3.1 最小描述长度(Minimum Description Length, MDL)
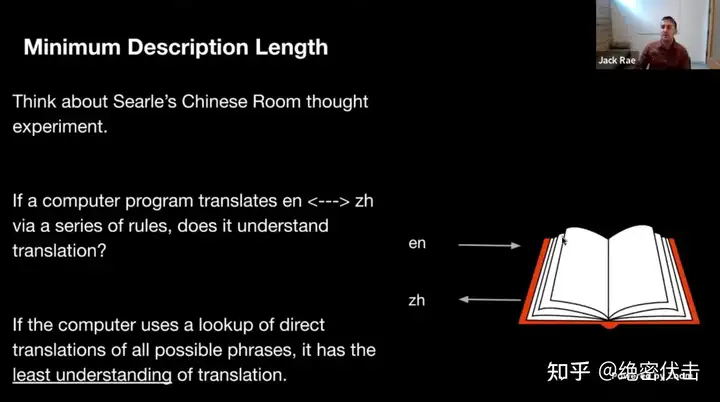
想象一个电脑软件需要把英文翻译成中文,如果它是通过查找字典把所有可能的词组翻译成中文,那么我们可以认为它对翻译任务有着最差的理解,因为任何出现在字典之外的词组它都无法翻译。但如果将字典提炼为较小的规则集(例如一些语法或基本的词汇),那它将会有更好的理解能力,因此我们可以根据规则集的压缩程度对其进行评分。实际上,如果我们可以把它压缩到最小描述长度,那么我们可以说它对翻译任务有着最好的理解。
对于给定的数据集 D,我们可以使用使用生成模型 f 对其进行压缩(在第2节我们已经介绍过如何推导出压缩公式),如下所示:
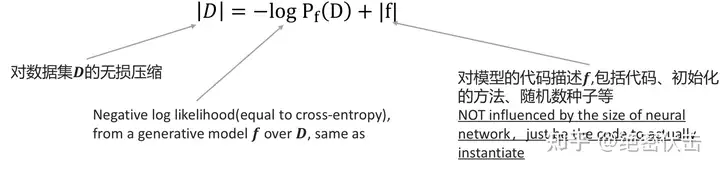
目前我们通常使用的基础模型是生成模型,我们可以使用生成器模型以非常精确的数学格式来表征数据集的无损压缩,因此我们可以尝试使用生成模型来找到最小描述长度。
图中 | D | 表示数据集 D 的无损压缩,无损压缩的大小可以表示为对 D 评估的生成模型的负对数似然加上估计函数的最小描述长度。
3.2 用大语言模型进行无损压缩
对于数据集 D,可以使用 LLM f 的 next-token 预测损失加上 f 的描述长度(~100KB)。
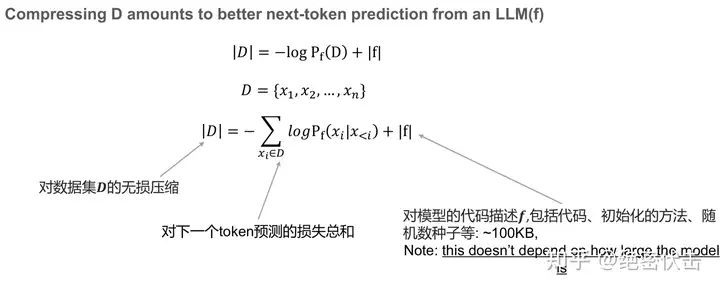
上面的公式在前面第2节已经介绍过。
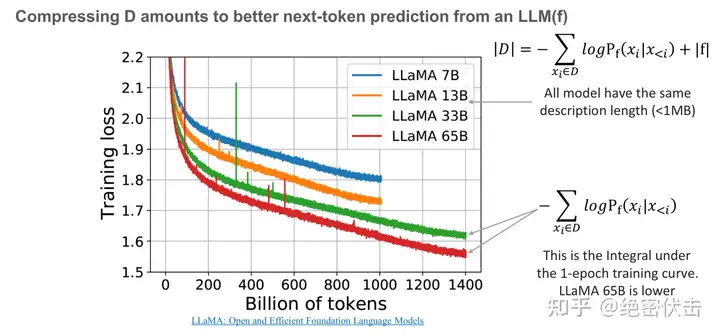
上图中是 LLaMA 模型的一些训练曲线,绿线和红线表示的两个模型只在数据集上训练了 1 个 epoch,因此可以把训练损失视为 |D| 中的 next-token 预测损失。同时我们也可以粗略地估计模型的描述长度(~1MB)。即便模型的参数量不同,但 LLaMA 33B 和 LLaMA 65B 两个模型有着相同的数据描述长度(用于训练的代码相同)。但 65B 模型显然有着更低的训练损失,把两项相加,可以看出 65B 实际上是更好的压缩器。
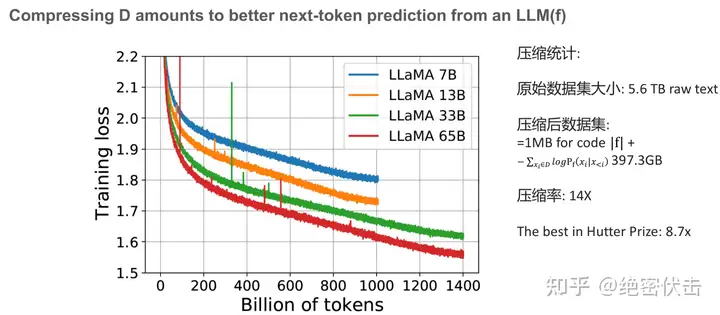
上图是一些更具体的数据,用于初始化和训练模型的代码约为 1MB,粗略地计算负对数似然大约是 400GB,而用于训练的原始数据是 5.6TB 的文本,因此该模型的压缩率为 14 倍。而 Hutter Prize 上最好的文本压缩器能实现 8.7 倍的压缩。实际上我们正在创建更强大的模型,为我们的训练数据提供更低的无损压缩率,即便中间模型本身可能非常大。
3.3 具体如何实现
关于 GPT 这样的大模型是如何实现压缩机制的,在前面第2节已经具体介绍过,这里就不再重复介绍。
3.4 局限性和总结

在分享的最后,Jack Rae介绍了大模型这种压缩方式的局限性。
1. 对所有的一切都进行压缩非常不现实
- 比如,像素级的图像建模开销非常大,对视频进行像素级别的建模简直是疯掉了
- 一个限制是,可能需要首先确定想要保留和建模的信息片段,然后找到一种方法来过滤掉我们不需要的无关计算和信息片段。这可以帮助我们在无损压缩之前减少正在处理的数据子集
2. 非常多在现实中的数据可能是无法直接观测到的
- 不能指望通过压缩所有可观测到的数据实现AGI
- 以围棋游戏AlphaZeroa为例子,观察有限数量的人类游戏不足以实现真实的突破。相反,需要其Agent自行进行对弈并收集数据中间的数据。

总结Jack Rae 在最后的总结中给出了以下几个观点:
- 最有用的压缩方法是通过scale实现。But Scale isn’t all you need。
- 还有这很多的算法上的进步等待着去发现 (如图像视频的压缩) 。
- 压缩是很好的评价大语言模型LLM能力的指标。
- 压缩是一种实现AGI的方法,但可能不唯一。
总结
Jack Rae 的这次分享向我们揭示了 GPT 为什么拥有智能,通过数据压缩理论给出了量化大模型能力的指标,感觉收获满满。如果大家想具体了解,还是建议去看看原视频。另外北京大学也做过一次 Compression For AGI 为主题的分享,感兴趣的也可以去下载下来看看。
Jack Rae 分享视频:https://www.youtube.com/watch?v=dO4TPJkeaaU
北京大学分享:【Compression For AGI:压缩即智慧,大语言模型LLM是最好的无损压缩器-哔哩哔哩】 https://b23.tv/RwEARtr
最后我们用一张长图,来回顾 AGI 的发展历史。

参考
张俊林:世界的参数倒影:为何GPT通过Next Token Prediction可以产生智能
Compression for AGI(大语言模型进行无损压缩) - 实时互动网 (nxrte.com)
智慧信息的压缩:模型智能的涌现之道_经济学人 - 前瞻网 (qianzhan.com)
智慧信息的压缩:模型智能的涌现之道 - 文心AIGC (7otech.com)
压缩下一个 token 通向超过人类的智能 - 知乎 (zhihu.com)
为什么说 GPT 是无损压缩 | K.I.S.S (bigeagle.me)
标签:Rae,压缩,无损压缩,智能,Jack,ChatGPT,模型 From: https://www.cnblogs.com/lsgsanxiao/p/18159871