文件操作
-
文件的概念
就是操作系统暴露给用户操作硬盘的快捷方式 双击一个文件 其实是从硬盘将数据加载到内存 ctrl+s 保存文件 其实是将内存中的数据刷到硬盘保存 -
代码打开文件的两种方式
方式1:
f = open(文件路径,读写模式,encoding='utf8') f.close()方式2:
with open('a.txt', 'r', encoding='utf8') as f1: with子代码块winth上下文管理号处在于子代码运行结束自动调用close方法关闭资源
open方法的第一个参数是文件路径 并且撬棍跟一些字母的组合会产生特殊的含义导致路径查找混乱 为了解决该问题可以在字符串的路径前面加字母r D:\a\n\t r'D:\a\n\t' 以后涉及到路径的编写 推荐加上r with支持一次性打开多个文件 with open() as f1,open() as f2,open() as f3: 子代码文件读写模式
'r': 只读模式只能读不能写
'r+':可读可写,该文件必须已存在,文件指着在最前方
'rb':表示以二进制方式读取文件,该文件必须以存在
'w':只写,打开即默认创建一个新文件,如果文件已存在,则覆盖写(即文件内原始数据会被新写的数据清空覆盖)
'w+':写读,打开创建新文件并写入数据,如果文件已存在,则覆盖写。
'wb':表示以二进制写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,则覆盖写。
'a':追加写,若打开的是已有文件则直接对已有文件操作,若打开文件不存在则创建文件,只能执行写(追加后面),不能读
'a+':追加读写,打开文件方式与写入方式和'a'一样,都是可以读。需注意的是你刚用'a+'打开一个文件,一般不能直接读取,因为此时光标已经是文件末尾,除非你把光标移动到初始位置或任意非末尾的位置
文件操作模式
-
文本模式
1.文本模式本质就是我们日常书写的文件,只能容纳字符串不能容纳视频音频等其他格式文件 简写:r 全拼:rt (读取文件) 简写:w 全拼:wt (书写文件) 简写:a 全拼:at (追加书写文件) 2.注意事项 2.1文件,模式只能操作文本文件 2.2在书写时必须要话encoding后面跟上字符的编码格式 2.3读取的时候也只能读取字符串格式
-
-
二进制模式
1.二进制模式其实就是只有计算机能够听懂的语言,将我们人类能够看懂的语言编译成机器能听懂的语言,在通讯时我们将自己的语言发送通过计算机编译成二进制模式,从另一个接收端基站模拟出你发送的数据信号这样接受端就可以收到你所发送的东西。 全拼:rb (读取文件) 全拼:wb (书写文件) 全拼:ab (追加书写文件) 2.注意事项 2.1在标注二进制模式时必须全拼否则不识别或自动识别为文本模式 2.2能够操纵所有的文本格式 2.3不需要编辑encoding就可以直接编写因为会直接转成二进制 2.4他的存储单位是以bytes来存储
文件诸多方法
1.read()
一次性读取文件内容 并且光标停留在文件末尾 简写读取则没有内容
2.for循环
一行行读取文件内容 避免内存溢出现象的产生
3.readline()
一次只读一行内容
4.readlines()
一次性读取文件内容 会按照行数组织成列表的一个个数据值
5.readable()
判断文件是否具备读数据的能力
6.weint()
写入数据
7.weiteable()
判断文件是否具备写数据的能力
8.writelines()
接收一个列表 一次性列表中所有的数据值写入
9.flush()
将内存中文件数据立刻刷到硬盘 等价ctrl + s
文件内光标的移动
with open(r'a.txt', 'rb') as f:
print(f.read())
f.seek(0,0)
print(f.read())
f.seek(0,0)
print(f.read())
print(f.read(2)).decode('utf8'))
f.seek(-1, 2)
print(f.tell()) 返回光标距离文件开头产生的字节数
seek(offset, whence)
offset是位移量 以字节为单位
whence是模式 0 1 2
0是基于文件开头
文本和二进制模式都可以使用
1是基于当前位置
只有二进制模式可以使用
2是基于文件末尾
只有二进制模式可以使用
print(f.read(3).decode('utf8'))
文件内光标移动
-
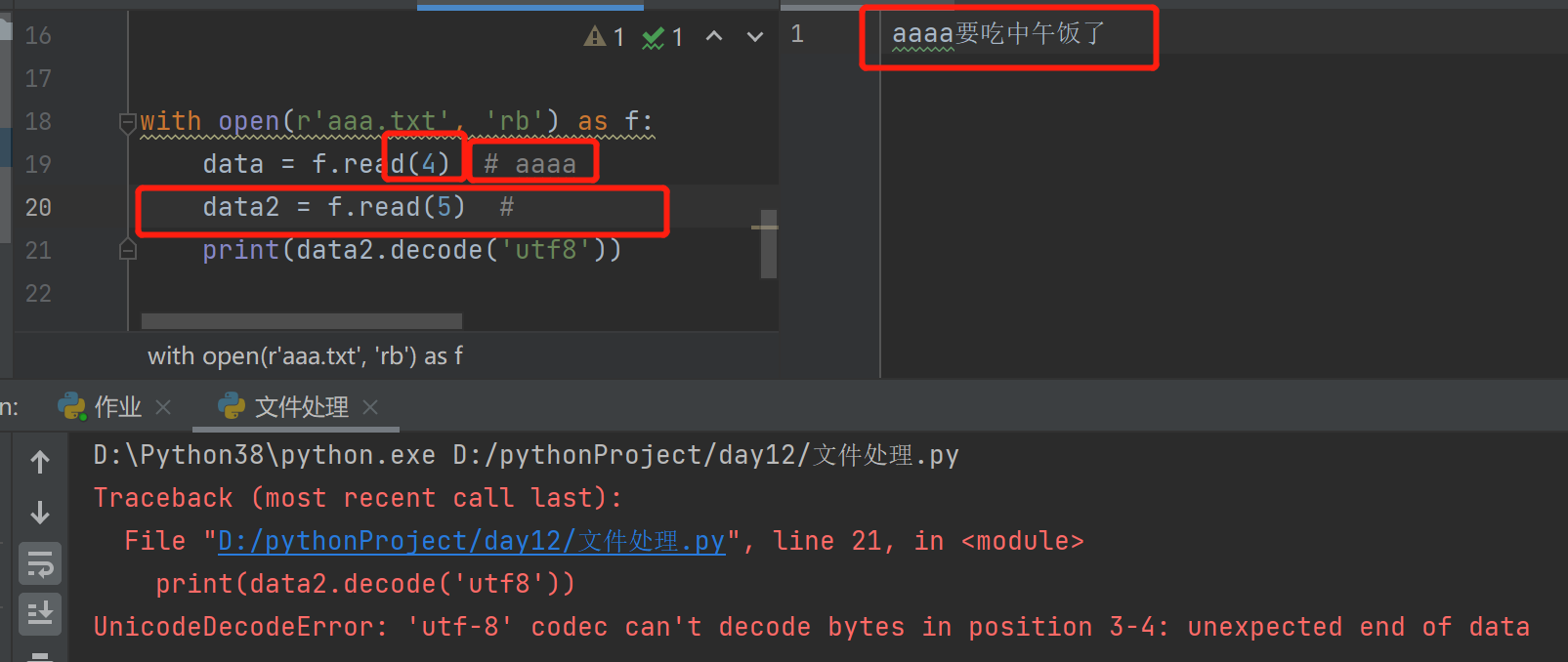
文件内光标的移动是以bytes为单位移动的,t模式下的read()是以字符移动的

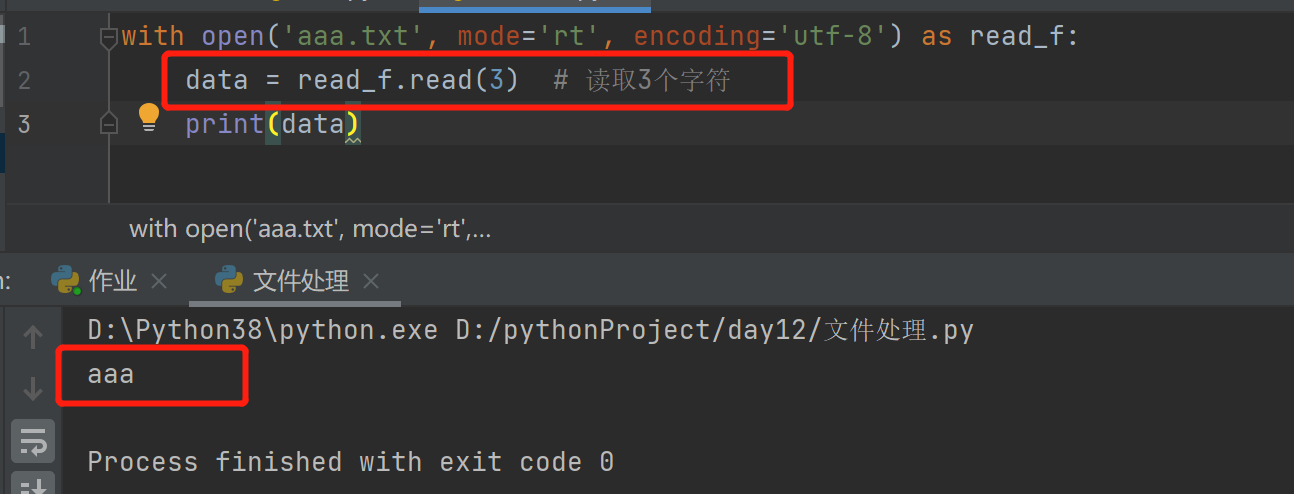

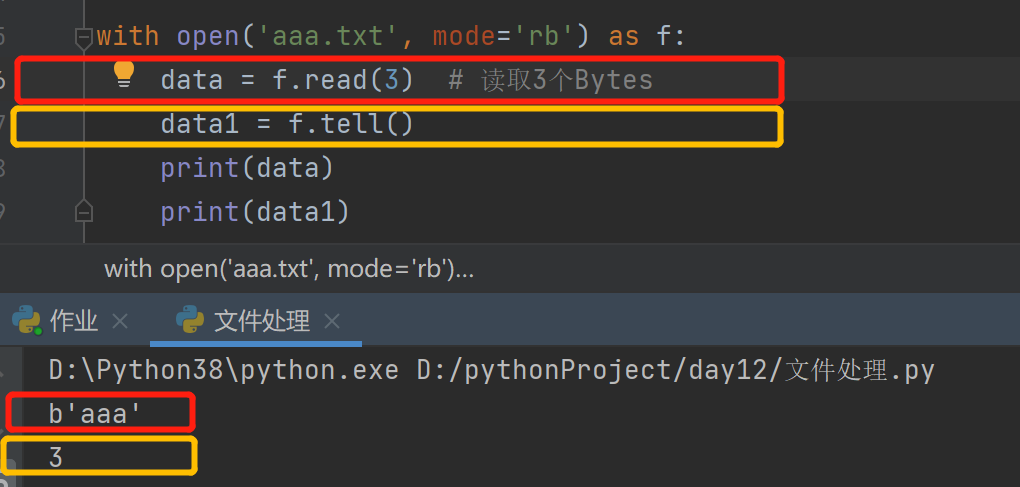
-
文件内指针的移动不一定都是有读写操作被动的出发,可以通过移动的方法对其指定的移动.seek(offset(光标移动的字节数,whence(模式控制))


计算机硬盘修改数据的原理
硬盘写数据可以看成是在硬盘上刻字 一旦需要修改中间内容 则需要重新刻字
因为刻过的字不可能从中间再分开
硬盘删除数据的原理
表示中间删除而是改变状态 等待后续数据的覆盖才会被真正删除
文件内容修改




函数的基本概念
函数也叫功能,它是对数据与代码的封装,实现了代码的复用。
当我们在pycharm中写代码时,假如先写了一个功能的代码,我们可以右键进行运行;如果我们又写了一个功能代码,点击运行时,两个功能代码都会运行,这时就可以把各个功能的代码块进行封装起来,写成函数。下次想用哪个功能就调哪个函数。
函数的语法结构
-
def
是定义函数的关键字
-
函数名
与变量名的命名一致,尽量做到见名知意
-
括号
在定义函数的时候函数名后面必须跟括号
-
参数
定义函数括号内可以写参数(个数不固定)也可以不写参数
用于接收外界传递给函数体代码 -
函数注释
类似于说明书 用于接受函数的主题功能和具体用法
-
函数体代码
整个函数最核心的区域(逻辑代码)
-
return
控制函数的返回值
调用函数之后返回值如何理解 使用函数之后也没有相应的反馈函数的定义与调用
1.定义函数的代码必须要在调用函数的代码之前先运行即可
func() def func() print('我是一个函数')
2.定义函数使用def关键字
调用函数使用函数名加括号(可能需要添加额外的参数)
3.函数在定义阶段只检测函数体代码语法 不执行函数体代码
只有在调用阶段才会真正的执行函数体代码
def func(): fcvhjfjhfyku cghfuyfkuy uyfruykrf

4.函数名到底是什么东西
函数名绑定的是一块内存地址 里面存放了函数体代码
要想运行改代码 就需要调用函数>>>:函数名加括号
5.函数名加括号执行优先级最高(定义阶段除外)
def func()
print('函数名')
func

函数的分类
-
内置函数
解释器提前帮你定义好的函数 用户可以直接调用 len()
内置函数可以直接调用
但是数据类型的内置方法(函数)必须使用数据2类型点的方式才可以调用
相当于是数据类型独有的一些内置方法
-
自定义函数
1.空函数
函数体代码使用pass顶替暂时没有任何功能
主要用于前期的项目搭建 提示主要功能

2.无参函数
函数定义阶段括号内没有填写参数,无参函数直接函数名加括号调用
def func()
print('无参函数')
func()

3.有参函数
函数定义阶段括号内填写参数,有参函数调用需要函数名加括号并且给数据值
def func(a, b):
print('无参函数')
func(1, 2)

函数的返回值
返回值接受调用函数之后产生的结果 可有可无 获取函数返回值的方法是固定的
变量名=函数() 有则获取 没有则默认接收None
1.函数体代码没有return关键字:默认返回None
def func()
print('from func')
res = func()
print(res)

2.函数体代码有return关键字:后面不写 也返回None
def func()
print('from func')
return
res = func()
print(res)

3.函数体代码有return关键字:return后面写什么就返回什么(如果数据数据值则直接返回 如果是变量则需要找到对应的数据值返回)
def func()
print('from func')
return 123
res = func()
print(res)

def func()
print('from func')
name = 'zhang'
return name
res = func()
print(res)

4.函数体代码有return关键字:并且后面写了多个数据值(名字)逗号隔开:默认情况下会自动组织成元组返回
def func()
return 1, 2, 3, 4
res = func()
print(res)

def func()
return [1, 2, 3, 4]
res = func()
print(res)

def funs()
return [1, 2, 3],{'name':'zhang'},123
res = funs()
print(res)

5.函数体代码遇到return关键字会立刻结束函数体代码的运行
def func():
print('我在上面')
return 123
print('我在下面')
func()q

函数的参数
参数有两大类
1.形式参数:函数在定义阶段括号内填写的参数简称为'形参'

2.实际参数:函数在调用阶段括号内填写的参数简称为'实参'

形参与实参关系
形参相当于是变量名
实参相当于是数据值
在函数调用阶段形参临时与实参进行绑定 函数雨运行结束立刻解除
动态绑定 动态解除

位置参数
位置形参:指的是定义函数时括号定义的参数,即变量名
在定义函数时,按照从左到右的顺序依次定义的参数,称为位置形参
特性:位置形参必须被传值,多一个不行少一个也不行
位置实参:指的是在调用函数时括号内传入的值,即变量名
在调用函数时,按照从左往右的顺序依次传入的值,称为位置实参
特点:与形参一一对应,顺序乱了,实参赋值也会乱

'''在调用函数时,实参的值会传给形参,这就是一个变量的赋值操作'''
默认形参和关键字实参
-
默认参数(形参):在定义函数时,就可以被赋值的参数,称为默认形参
- 在定义阶段已经被赋值,意味着在调用阶段就可以不用传值
- 默认参数必须跟在位置形参的后面,否则就会报错
- 默认参数的值只在定义阶段被赋值一次就固定死了,定义之后改变没有影响
- 默认参数的值应该设置成不可变类型
(1)、在定义阶段已经被赋值,意味着在调用阶段就可以不用传值
def foo(x,y,z=3):
print(x,y,z)
foo(1,2)
#返回值
1 2 3
(2)、默认形参跟在位置形参的前面,报错
ef foo(y=1,x):
pass
#报错
SyntaxError: non-default argument follows default argument
(3)、默认参数的值只在定义阶段被赋值一次就固定死了,定义之后改变没有影响
m=10
def func(x,y=m):
print(x)
print(y)
m=1111111
func(1)
#返回值
1
10
(4)、默认参数的值应该设置成不可变类型
#这种方式列表的值每次都会发生不可预料的变化,不建议这么做
def func(name,hobby,l=[]):
l.append(hobby)
print(name,l)
func('egon','read')
func('alex','play')
#返回值
egon ['read']
alex ['read', 'play']
#正确姿势
def func(name,hobby,l=None):
if l is None:
l=[]
l.append(hobby)
print(name,l)
func('egon','read')
func('alex','play')
#返回值
egon ['read']
alex ['play']
- 关键字实参:在调用函数时,按照key=value的形式定义的实参,称为关键字实参
特点:可以完全打乱顺序,但仍然能指名道姓的为指定的参数传值
def foo(x,y,z):
print(x,y,z)
foo(x=1,y=2,z=3)
#返回值
1 2 3
可变长参数
可变长参数:指的是在调用函数时,传入的参数个数可以不固定
调用函数时,传值的方式无非两种,一种是位置实参,另一种是关键字实参,因此形参也必须得有两种解决方法,以此来分别接收溢出来的位置实参(*)与关键字实参(**)
形参之*
形参中的会溢出来的位置实参全部接收,然后存储元组的形式,然后把元组赋值给后的参数。需要注意的是:*后的参数名约定俗称成为args。
def sum_self(*args):
res = 0
for num in args:
res += num
return res
res = sum_self(1, 2, 3, 4)
print(res)
10
形参之**
形参中的会将溢出的关键字形参全部接收,然后存储字典的形式,然后把字典赋值给后的参数。需要注意的是:**后的参数名约定俗称为kwargs。
def func(**kwargw):
print(kwargw)
func(a=5)
{'a': 5}
实参之*
实参中的*,会将后产生的值循环取出,打散成位置实参。以后但凡碰到实参中带 *的,它就是位置实参,应该马上打散成位置实参去看。
def func(x, y, z, *args):
print(x, y, z, args)
func(1, *(1, 2), 3, 4)
1 1 2 (3, 4)
1
2
3
4
5
6
实参之**
实参中的**,会将后参数的值循环取出,打散成关键字实参。以后但凡碰到实参中带 * *的,它就是关键字实参,应该马上打散成关键字实参去看。
def func(x, y, z, **kwargs):
print(x, y, z, kwargs)
func(1, 3, 4, **{'a': 1, 'b': 2})
1 3 4 {'a': 1, 'b': 2}
名称空间
名称空间就是用来存储变量名与数据值绑定关系的地方(我们也可以简单的理解为就是存储变量名的地方)
| 名称空间 | 存放名字 | 存货周期 |
|---|---|---|
| 内置名称空间 | 存放的是python解释器内置的名字 | python解释器启动后产生,关闭后回收 |
| 全局名称空间 | 不是函数内定义,也不是内置的,剩下的都是全局名称空间的名字 | 执行python文件时产生,python文件运行完成后回收 |
| 局部名称空间 | 在调用函数时,运行函数体代码的过程中生产的函数内的名字 | 在调用函数时生产,在函数用完毕后回收 |
名字查找顺序
涉及到名字查找,要搞清楚自己在哪个空间
-
当我们在局部名称空间中的时候
局部名称空间 >>> 全局名称空间 >>> 内置名称空间
-
当我们在全局名称空间中的时候
全局名称空间 >>> 内置名称空间

global与nonlocal
一、global
总之一句话,作用域是全局的,就是会修改这个变量对应地址的值。
global语句是一个声明,它适用于整个当前代码块。这意味着列出的标识符将被解释为全局变量。尽管自由变量可以能指的是全局变量而不被声明为全局变量。
global语句中列出的名称不得用于该全局语句之前的文本代码块中。
global语句中列出的名称不能定义为形式参数,也不能在for循环控制目标、class定义、函数定义、impot语句或变量注释中定义。
1、global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字。
gcount = 0
def global_test():
gcount+=1
print (gcount)
global_test()
以上代码会报错:第一行定义了全局变量,在内部函数中又对外部函数进行了引用并修改,那么python会认为它是一个局部变量,有因为内部函数没有对其gcount进行定义和赋值,所以报错。
2、如果局部要对全局变量修改,则在局部声明该全局变量
gcount = 0
def global_test():
global gcount
gcount+=1
print (gcount)
global_test()
以上输出为:1
3、如果局部不声明全局变量,并且不修改全局变量,则可以正常使用
gcount = 0
def global_test():
print (gcount)
global_test()
二、nonlocal
只在闭包里面生效,作用域就是闭包里面的,外函数和内函数都影响,但是闭包外面不影响。
nonlocal语句使列出的标识符引用除global变量外最近的封闭范围中的以前绑定的变量。这很重要,因为绑定的默认行为是首先搜索本地名称空间。该语句允许封装的代码将变量重新绑定到除全局(模块)作用域之外的本地作用域之外。
nonlocal 语句中列出的名称与 global 语句中列出的名称不同,它们必须引用封闭范围中已经存在的绑定(无法明确确定应在其中创建新绑定的范围)。
1、 nonlocal声明的变量不是局部变量,也不是全局变量,而是外部嵌套函数内的变量
def make_counter():
count = 0
def counter():
nonlocal count
count += 1
return count
return counter
def make_counter_test():
mc = make_counter()
print(mc())
print(mc())
print(mc())
make_counter_test()
以上输出为:
1
2
3
三、混合使用
def scope_test():
def do_local():
spam = "local spam" #此函数定义了另外的一个spam字符串变量,并且生命周期只在此函数内。此处的spam和外层的spam是两个变量,如果写出spam = spam + “local spam” 会报错
def do_nonlocal():
nonlocal spam #使用外层的spam变量
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("After local assignmane:", spam)
do_nonlocal()
print("After nonlocal assignment:",spam)
do_global()
print("After global assignment:",spam)
scope_test()
print("In global scope:",spam)
以上输出为:
After local assignmane: test spam
After nonlocal assignment: nonlocal spam
After global assignment: nonlocal spam
In global scope: global spam
函数名的多种用法
1.函数可以当作值被赋予变量
def func():
bu = (1,2,3,'abc',{'name':'ligen'})
print (bu)
a = func
a()
2.函数名可以当作函数的参数
def func(*args):
dict1 = {'name':args[0],'age':args[1],'box':args[2]}
for key in dict1:
print (key)
print ('*'*20)
for value in dict1.values():
print (value)
print ('*' * 20)
for kv in dict1.items():
print (kv)
# func('ligen', 24, 'blue')
def func2(f):
f
func2(func('ligen', 24, 'blue'))
3.函数可以当作元素放在容器中
def func1():
print ('1')
def func2():
list1 = [func1,func1,func1]
for i in list1:
i()
func2()
4.函数名可以当作函数的返回值
def func():
def foo():
print(222)
return foo
a = func()
a()
闭包函数
定义在函数内部的函数 并且用到了外部函数名称空间中的名字
1.定义在函数内容
2.用到外部函数名称空间中的名字
给函数传参的方式有俩种,分别为用形参和闭包
1. 形参
def index(a):
print('from index', a)
2. 闭包
def outer(name):
def inner():
print(name)
return inner
x = outer('XWenXiang') # x = outer() = inner
x() # x() = inner()
(1) 代码执行后首先在第一行定义函数 outer() 并定义形参 name
(2) 第二步调用函数 outer() 并传入实参 XWenXiang
(3) 第三步执行函数 outer() 函数体代码,定义函数 inner() ,返回值 inner,inner也就是函数
inner的内存地址
(4) 第四步将函数 outer() 返回值赋值给 x 。
(5) 第五步调用函数 x() 因为此时 x 等价与 inner 的内存地址。
装饰器
1.什么是装饰器
器指的是工具,可以定义成函数
装饰指的是为其他事物添加额外的东西点缀
合到一起的解释:
装饰器指的定义一个函数,该函数是用来为其他函数添加额外的功能
就是拓展原来函数功能的一种函数
2.为何要用装饰器
开放封闭原则
开放:指的是对拓展功能是开放的
封闭:指的是对修改源代码是封闭的
装饰器就是在不修改被装饰器对象源代码以及调用方式的前提下为被装饰对象添加新功能
3.如何用
# 需求:在不修改index函数的源代码以及调用方式的前提下为其添加统计运行时间的功能
def index(x, y):
time.sleep(3)
print('index %s %s' % (x, y))
index(111, 222)
# index(y=111,x=222)
# index(111,y=222)
# 解决方案一:失败
# 问题:没有修改被装饰对象的调用方式,但是修改了其源代码
import time
def index(x, y):
start = time.time()
time.sleep(3)
print('index %s %s' % (x, y))
stop = time.time()
print(stop - start)
index(111, 222)
# 解决方案二:失败
# 问题:没有修改被装饰对象的调用方式,也没有修改了其源代码,并且加上了新功能
# 但是代码冗余
import time
def index(x, y):
time.sleep(3)
print('index %s %s' % (x, y))
start = time.time()
index(111, 222)
stop = time.time()
print(stop - start)
# 解决方案三:失败
# # 问题:解决了方案二代码冗余问题,但带来一个新问题即函数的调用方式改变了
import time
def index(x, y):
time.sleep(3)
print('index %s %s' % (x, y))
def wrapper():
start = time.time()
index(111, 222)
stop = time.time()
print(stop - start)
wrapper()
# 方案三的优化一:将index的参数写活了
import time
def index(x, y, z):
time.sleep(3)
print('index %s %s %s' % (x, y, z))
def wrapper(*args, **kwargs):
start = time.time()
index(*args, **kwargs) # index(3333,z=5555,y=44444)
stop = time.time()
print(stop - start)
wrapper(3333, 4444, 5555)
wrapper(3333, z=5555, y=44444)
# 方案三的优化二:在优化一的基础上把被装饰对象写活了,原来只能装饰index
import time
def index(x,y,z):
time.sleep(3)
print('index %s %s %s' %(x,y,z))
def home(name):
time.sleep(2)
print('welcome %s to home page' %name)
def outter(func):
# func = index的内存地址
def wrapper(*args,**kwargs):
start=time.time()
func(*args,**kwargs) # index的内存地址()
stop=time.time()
print(stop - start)
return wrapper
index=outter(index) # index=wrapper的内存地址
home=outter(home) # home=wrapper的内存地址
home('egon')
# home(name='egon')
# 方案三的优化三:将wrapper做的跟被装饰对象一模一样,以假乱真
import time
def index(x,y,z):
time.sleep(3)
print('index %s %s %s' %(x,y,z))
def home(name):
time.sleep(2)
print('welcome %s to home page' %name)
def outter(func):
def wrapper(*args,**kwargs):
start=time.time()
res=func(*args,**kwargs)
stop=time.time()
print(stop - start)
return res
return wrapper
# # 偷梁换柱:home这个名字指向的wrapper函数的内存地址
home=outter(home)
res=home('egon') # res=wrapper('egon')
print('返回值--》',res)
装饰器模板
def outer(func):
def inner(*args, **kwargs):
res = func(*args, **kwargs)
return res
return inner
装饰器语法糖
在用装饰器之前还要写上 index = calculate_time(index) 这样一行代码,显然是很不方便的。这时候可以用 @calculate_time 替换 index = calculate_time(index)
import time #导入时间模块
def calculate_time(f):
def inner():
start_time = time.time()
f()
end_time = time.time()
print(end_time - start_time)
return inner
@calculate_time # 等价于index = calculate_time(index) 这行赋值的代码
def index():
time.sleep(2.2) #时间休眠2.2秒
index() #2.2051877975463867

算法二分法
二分算法图

什么是算法?
算法是高效解决问题的办法。
需求:有一个按照从小到大顺序排列的数字列表,查找某一个数字
# 定义一个无序的列表
nums = [3,4,5,67,8,9,124,1541,56,23637,7,37,321,21,61,515,1]
nums.sort() # 给列表排序
print(nums)
# 运行结果:[1,3,4,5,7,8,9,21,37,56,61,67,124,321,515,1541,23637]
nums = [-2,3,4,6,13,23,56,74,251,562,7437]
find_num = 13
# 方案一:整体遍历效率太低
for num in nums:
if num == find_num:
print("find it")
break
# for循环的弊端:效率低,得看运气。
# 使用二分法:从中间开始找,伪代码
def binary_search(find_num,列表):
mid_val=找列表中间的值
if find_num > mid_val:
# 应该在列表的右半部分查找
# (1) 新列表 = 列表切片右半部分
# (2) 重复本身的代码(列表)
elif find_num < mid_val:
# 应该在列表的左半部分
# (3)新列表 = 列表切左半部分
# (4)重复本身的代码(列表)
else: # find_num= mid_val
# 找到了
print('find it')
# 使用交互式程序获取应该列表的索引取值
nums = [1,2,3,4,5] # 定义一个含有奇数个的列表
len(nums) // 2 # 获取这个列表的中间索引值
3 # 这个列表的中间索引值是3
# 优化:二分法+递归解决需求
nunms = [-2,3,4,6,13,23,56,74,251,562,7437]
find_num = 15
def binary search(find num,1):
# 查看调用列表的次数
print(1)
# 针对列表索引值超范围:IndexError:list indx out of range
if len(1) == 0:
print("找的值不存在!!")
return
mid_index = len(1) // 2 # 获取列表中间的索引
if find_num > 1[mid_index]:
1 = 1[mid_index + 1:] # 列表切片,从中间索引加1处到列表最后。
binary_search(find_num,1)
elif find_num < 1[mid_index]:
1 = 1[:mid_index] # 列表切片,从列表到中间索引处。
binary_search(find_num,1)
else:
print('find it')
binary_search(find_num,nums)
# 优化:二分法+递归解决需求
nums = [-2,3,4,6,13,23,56,74,251,562,7437]
find_num = 15
def binary_search(find_num,l):
# 查看调用列表的次数
print(l)
# 针对列表索引值超出范围:IndexError: list index out of range
if len(l) == 0:
print("找的值不存在!!")
return
mid_index = len(l) // 2 # 获取列表中间值的索引
if find_num > l[mid_index]:
l = l[mid_index + 1:] # 列表切片,从中间索引加1处到列表最后。
binary_search(find_num,l)
elif find_num < l[mid_index]:
l = l[:mid_index] # 列表切片,从列表头到中间索引处。
binary_search(find_num,l)
else:
print('find it')
binary_search(find_num,nums)
# 第二次优化递归实现二分法:加入返回值
nums = [-3,4,7,10,13,21,43,77,89]
# find_num = 3
def binary_search(find_num,l):
print(l)
if len(l) == 0:
print("该值不存在!!!")
return False
mid_index = len(l) // 2
if find_num > l[mid_index]:
l = l[mid_index:1]
return binary_search(find_num,l)
elif find_num < l[mid_index]:
l = l[:mid_index]
return binary_search(find_num,l)
else:
print('find it')
return True
res = binary_search(7,nums)
print(res)
"""运行结果;没有return返回None
[-3, 4, 7, 10, 13, 21, 43, 77, 89]
[-3, 4, 7, 10]
find it
None
"""
# 获取结果的返回值:运行返回值是None?为啥?这要追溯到函数运行时的运行结果,没有return返回None
"""加入return后运行结果:
[-3, 4, 7, 10, 13, 21, 43, 77, 89]
[-3, 4, 7, 10]
find it
True
"""
三元表达式
三元表达式是一种python对于控制流程语句进行简写的形式。
res = 条件成立时返回的值 if 条件 else 条件不成立时返回的值
def max2(x,y):
if x > y:
return
else:
return y
res = max2(1,2)
各种生成式/表达式/推导式
name_list = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
# 给列表中所有人名的后面加上_NB的后缀
# for循环
new_list = []
for name in name_list:
data = f'{name}_NB'
new_list.append(data)
print(new_list)
# 列表生成式
# 先看for循环 每次for循环之后再看for关键字前面的操作
new_list = [name + "_NB" for name in name_list]
print(new_list)
# 复杂情况
new_list = [name + "_NB" for name in name_list if name == 'jason']
print(new_list)
new_list = ['大佬' if name == 'jason' else '小赤佬' for name in name_list if name != 'jack']
print(new_list)
# 字典生成式
s1 = 'hello world'
for i,j in enumerate(s1,start=100):
print(i,j)
d1 = {i: j for i, j in enumerate('hello')}
print(d1)
# 集合生成式
res = {i for i in 'hello'}
print(res)
# 元组生成式>>>:没有元组生成式 下列的结果是生成器(后面讲)
res = (i+'SB' for i in 'hello')
print(res)
for i in res:
print(i)
匿名函数
没有名字的函数 需要使用关键字lambda
语法结构
lambda 形参:返回值
使用场景
lambda a,b:a+b
匿名函数一般不单独使用 需要配合其他函数一起用
常见内置函数
1.map() 映射
l1 = [1, 2, 3, 4, 5]
def func(a):
return a + 1
res = map(lambda x:x+1, l1)
print(list(res))
2.max()\min()
l1 = [11, 22, 33, 44]
res = max(l1)
d1 = {
'zj': 100,
'jason': 8888,
'berk': 99999999,
'oscar': 1
}
def func(a):
return d1.get(a)
res = max(d1, key=lambda k: d1.get(k))
res = max(d1, key=func)
print(res)
3.reduce
reduce 传多个值 返回一个值
from functools import reduce
l1 = [11, 22, 33, 44, 55, 66, 77, 88]
res = reduce(lambda a, b: a * b, l1)
print(res)
'''好奇执行流程可以使用debug模式简单看看'''
重要内置函数
zip
将多个可迭代对象组合起来,然后可以用列表一次性将结果存入列表、元组或者字典

for循环可以把元素以此取出

fliter

特别需要注意到一点是在python2.7版本中filter()返回列表,而在python3.x版本中filter()返回迭代器对象,我们可以使用内置函数list()手动将filter迭代器对象转换为列表
常见内置函数
1.print(abs(-1)) #求绝对值
2.print(all([1,0,3]))# 判断列表所有值是否为真
print(any([1,0,3]))#判断列表有一个值为真则返回true
3.print(bin(1))#十进制数字转换成二进制
4.print(hex(1))#十进制数字转换成十六进制
5.print(chr(67))#返回十进制的ascii码值
6.print(ord('c'))#返回ascii码的十进制数字
7.print(bool(0))#判断布尔值
8.bytes() #转换成bytes类型
s1 = '您好'
print(s1.encode('utf8'))
print(bytes(s1,'utf8'))
9.callable() #判断名字是否可以加括号调用
name = 'jason'
def index():
print('from index')
print(callable(name)) #False
print(callable(index)) # True
10.print(dir('hello')) # 返回括号内对象能够调用的名字
11.divmod() #元组 第一个数据为整除数,第二个是余数
res = divmod(100,2)
print(res) # (50,0)
res = divmod(100,3)
print(res)
"""
总数据 每页展示的数据 总页码
100 10 10
99 10 10
101 10 11
"""
page_num, more = divmod(9999,20)
print(divmod(99,10)) # (9,9)
if more:
page_num += 1
print('总页码为:',page_num) #总页 码为: 500
12.enumerate() # 枚举
13.ebal() exec() # 能够识别字符串中的python并执行
s1 = 'print("哈哈哈")'
eval(s1)
exec(s1)
s2 = 'for i in
range(100):print(i)'
eval(s2) # 只能识别简单的python代码 具有逻辑性的都不行
exec(s2) # 可以识别具有一定逻辑性的 python代码
14.hash() # 哈希加密
print(hash('jaosn'))
15.id() #内存地址
16.input() # 获取用户输入
17.max() # 求最大值
18.min() # 求最小值
19.map() # 会根据提供的函数对指定序列做 映射
20.pow(a,b) # 幂指数(次方)
21.range() # 生成数据
22.round() # 四舍五入
23.sum() # 求和
24.zip() #函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表,如果各个迭代器的元素个数不一致,则返回列表长度最短的对象相同
可迭代对象
1.可迭代对象
对象内置有__iter__方法的都称为可迭代对象
"""
1.内置方法 通过点的方式能够调用的方法
2.__iter__ 双下iter方法
"""
2.可迭代对象的范围
不是可迭代对象
int float bool 函数对象
是可迭代对象
str list dict tuple set 文件对象
3.可迭代的含义
"""
迭代:更新换代(每次更新都必须依赖上一 次的结果)
"""
可迭代在python中可以理解为是否支持for循环
迭代器对象
1.迭代器对象
是由可迭代对象调用__iter__方法产生的
迭代器对象判断的本质是看是否内置有__iter__和__next__
2.迭代器对象的作用
提供了一种不依赖于索引取值的方式
正因为有迭代器的存在 我们的字典 集合才能够被for循环
3.迭代器对象实操
s1 = 'hello' # 可迭代对象
res = s1.__iter__() # 迭代器对象
print(res.__next__()) # 迭代取值 for循环的本质
一旦__next__取不到值 会直接报错
4.注意事项
可迭代对象调用__iter__会成为迭代器对象 迭代器对象如果还调用__iter__不会有任何变化 还是迭代器对象本身
for循环的本质
for 变量名 in 可迭代对象:
循环体代码
"""
1.先将in后面的数据调用__iter__转变成迭代器对象
2.依次让迭代器对象调用__next__取值
3.一旦__next__取不到值报错 for循环会自动捕获并处理
"""
异常捕获/处理
1.异常
异常就是代码运行报错 行业俗语叫bug
代码运行中一旦遇到异常会直接结束整个程序的运行 我们在编写代码的过程中药尽可能避免
2.异常分类
语法错误
不允许出现 一旦出现立刻改正 否则提桶跑路
逻辑错误
允许出现的 因为它一眼发现不了 代码运行之后才可能会出现
3.异常结构
错误位置
错误类型
错误详情