本篇篇幅较长,请做好心理准备!
共三章节:
1.深搜入门(一维方向 数字选数类)
2.深搜入门(二维方向 迷宫类)
3.深搜进阶(迷宫类问题--最少步数和输出路径)
第一章:深搜入门(一维方向 数字选数类)
前置知识:函数、递归
为了保证学习效果,请保证已经掌握前置知识之后,再来学习本章节!
深度优先搜索
基础入门:了解什么是深搜、理解深搜原理
选数类问题:如何选数,理解一维方向的深搜
迷宫类问题:求最少步数、输出第一条路径、输出所有路径等问题,理解二维方向深搜
回溯和剪枝:优化时间
什么是深搜
深度优先搜索(Depth First Search,简称DFS)与广度优先搜索(Breath First Search,简称BFS)是图论中两种非常重要的算法,也是进行更高的算法阶段学习的最后一道门槛。
搜索算法频繁出现在算法竞赛题中, 尤其是深度优先搜索,在竞赛中,它是用来进行保底拿分的神器!
深度优先搜索属于图算法的一种。其过程是: 对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次 。
简单来说就是: 一路走到头,不撞墙不回头 。
搜索案例
遍历如下图所示的图,图中部分结点之间有路径连接。遍历规则为:深度优先,右手路径优先,不能重复遍历。请问遍历的结果是什么?(假设从A点出发)
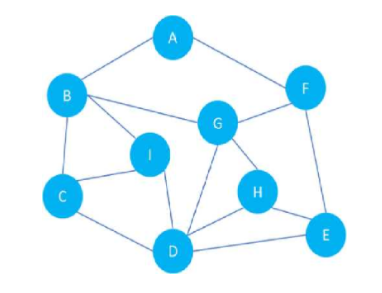
遍历结果:ABCDEFGHI。
假设从A点出发,遍历规则为:深度优先, 左手路径优先 ,不能重复遍历。请问遍历的结果是什么?(自行思考)
我相信很多同学看完上面的内容对深度优先搜索还不是很熟悉。下面我们通过几个例子带同学们更深入的了解什么是深度优先搜索。
案例1:扑克牌游戏(数字类深搜模板题)
假如有编号为1、2、3的3张扑克牌和编号为1、2、3的3个盒子。现在需要将这3张扑克牌分别放到3个盒子里面,并且每个盒子有且只能放一张扑克牌。那么一共有多少种不同的放法呢?
聪明的拓拓觉得这个题目很简答,于是他决定试一试。拓拓手拿 3张扑克牌,首先走到了1号盒子面前。此时拓拓心里想∶我是先放1号扑克牌,还是先放2号扑克牌,还是先放3号扑克牌呢?很显然这三种情况都需要去尝试,拓拓说那我们约定一个顺序吧∶每次到一个盒子面前时,都先放1号,再放2号,最后放3号扑克牌。说完拓拓走到了1号盒子前,将 1号扑克牌放到第1个盒子中。
放好之后拓拓往后走一步,来到了2号盒子面前。本来按照之前约定的规则,每到一个新的盒子面前,要按照1号、2号、3号扑克牌的顺序来放。但是现在拓拓手中只剩下2号和3号扑克牌了,于是拓拓将2号扑克牌放入了2号盒子中。放好之后拓拓再往后走一步,来到了3号盒子面前。
现在拓拓已经来到了3号盒子面前,按照之前约定的顺序,还是应该按照1号、2号、3号扑克牌的顺序来放,但是拓拓手中只有3号扑克牌了,于是只能往 3号盒子里面放3号扑克牌。放好后,拓拓再往后走一步,来到了4号盒子面前。咦!没有第4个盒子,其实我们并不需要第 4个盒子,因为手中的扑克牌已经放完了。我们发现当拓拓走到第4个盒子的时候,已经完成了一种排列,这个排列就是前面3个盒子中的扑克牌号码,即"123"。
是不是游戏到此就结束了呢?肯定没有!产生了一种排列之后拓拓需要立即返回。现在拓拓需要退一步重新回到 3 号盒子面前。好!现在拓拓已经回到了3号盒子面前,需要取回之前放在3号盒子中的扑克牌,再去尝试看看还能否放别的扑克牌,从而产生一个新的排列。
于是拓拓取回了3号扑克牌。当拓拓再想往3号盒子放别的扑克牌的时候,却发现手中仍然只有3号扑克牌,没有别的选择。于是拓拓不得不再往回退一步,回到2 号盒子面前。拓拓回到2号盒子后,收回了2号扑克牌。现在拓拓手里面有两张扑克牌了,分别是2号和3号扑克牌。按照之前约定的顺序,现在需要往2号盒子中放3号扑克牌(上一次放的是2号扑克牌)。放好之后拓拓又向后走一步,再次来到了3号盒子面前。拓拓再次来到3号盒子后,将手中仅剩的2号扑克牌放入了3号盒子。又来到4号盒子面前。当然了,这里并没有4号盒子。此时又产生了一个新的排列“132”。
接下来按照刚才的步骤去模拟,便会依次生成所有排列∶"213""231""312"和"321"。
说了半天,这么复杂的过程如何用程序实现呢?我们现在来解决最基本的问题∶如何往小盒子中放扑克牌。每一个小盒子都可能放1号、2号或者3号扑克牌,这需要一一去尝试,这里一个 for循环就可以解决。
for(i=1;i< =n;i++)
{
a[step]=i; //将第i号扑克牌放入第step个盒子中
}
这里数组 a是用来表示小盒子的,变量 step 表示当前正处在第 step 个小盒子面前。 a[step]=i; 就是将第i号扑克牌放入到第step个盒子中。这里有一个问题那就是,如果一张扑克牌已经放到别的小盒子中了,那么此时就不能再放入同样的扑克牌到当前小盒子中,因为此时手中已经没有这张扑克牌了。因此还需要一个数组 book来标记哪些牌已经使用了。
for(i=1;i< =n;i++)
{
if(book[i]==0)
{
a[step]=i; //将第i号扑克牌放入第step个盒子中
book[i]=1; //将book[i]设为1,表示滴i号牌已经不在手中了
}
}
OK,现在已经处理完第 step个小盒子了,接下来需要往下走一步,继续处理第 step+1个小盒子。那么如何处理第 step+1个小盒子呢?处理方法其实和我们刚刚处理第 step个小盒子的方法是相同的。因此就很容易想到(如果这个词伤害了您,我表示深深的歉意^^)把刚才的处理第 step 个小盒子的代码封装为一个函数,我们为这个函数起个名字,就叫做dfs 吧,如下。
void dfs(int step) //step表示现在站在第几个盒子面前
{
for(i=1;i< =n;i++)
{
//判断扑克牌i是否还在手上
if(book[i]==0) //将book[i]等于0表示扑克牌仍然在手上
{
a[step]=i; //将第i号扑克牌放入第step个盒子中
book[i]=1; //将book[i]设为1,表示滴i号牌已经不在手中了
}
}
}
把这个过程写成函数后,刚才的问题就好办了。在处理完第 step个小盒子之后,紧接着处理第 step+1个小盒子,处理第step+1和小盒子的方法就是 dfs(step+1),请注意下面代码中第11行语句。
void dfs(int step) //step表示现在站在第几个盒子面前
{
for(i=1;i< =n;i++)
{
//判断扑克牌i是否还在手上
if(book[i]==0) //将book[i]等于0表示扑克牌仍然在手上
{
a[step]=i; //将第i号扑克牌放入第step个盒子中
book[i]=1; //将book[i]设为1,表示滴i号牌已经不在手中了
dfs(step+1); //这里通过函数的递归用来实现
book[i]=0; //这是非常重要的一步,一定要将刚才尝试的扑克牌收回,才能进行下一次尝试
}
}
}
上面代码中的book[i]=0;这条语句非常重要,这句话的作用是将小盒子中的扑克牌收回,因为在一次摆放尝试结束返回的时候,如果不把刚才放入小盒子中的扑克牌收回,那将无法再进行下一次摆放。还剩下一个问题,就是什么时候该输出一个满足要求的序列呢。其实当我们处理到第 n+1个小盒子的时候(即 step等于n+1),那么说明前n个盒子都已经放好扑克牌了,这里就将 1-n个小盒子中的扑克牌编号打印出来就可以了,如下。注意!打印完毕一定要立即 return,不然这个程序就会永无止境地运行下去了,想一想为什么吧。
完整的代码如下所示:
#include< bits/stdc++.h>
using namespace std;
int a[10],book[10],n;
void dfs(int step) //step表示现在站在第几个盒子面前
{
int i;
if(step==n+1) //如果站在第n+1个盒子面前,则表示前n个盒子已经放在扑克牌
{
//输出一种排列(1-n号盒子中的扑克牌编号)
for(i=1;i< =n;i++)
{
cout< < a[i]< < " ";
}
cout< < endl;
return; //返回之前一步(最近一次调用dfs函数的地方)
}
//此时站在第step个盒子前,应该放哪张牌呢?
//按照1、2、3...n的顺序一一尝试
for(i=1;i< =n;i++)
{
//判断扑克牌i是否还在手上
if(book[i]==0) //将book[i]等于0表示扑克牌仍然在手上
{
//开始尝试使用扑克牌i
a[step]=i; //将第i号扑克牌放入第step个盒子中
book[i]=1; //将book[i]设为1,表示滴i号牌已经不在手中了
//第step个盒子已经放好扑克牌,接下来需要走到下一个盒子面前
dfs(step+1); //这里通过函数的递归用来实现
book[i]=0; //这是非常重要的一步,一定要将刚才尝试的扑克牌收回,才能进行下一次尝试
}
}
}
int main()
{
cin>>n;
dfs(1); //首先站在1号盒子前面
return 0;
}
这个简单的例子,核心代码不超过20行,却饱含深度优先搜索(DepthFirst Search,DFS)的基本模型。理解深度优先搜索的关键在于解决当下该如何做。至于下一步如何做则与当下该如何做是一样的。比如我们这里写的dfs(step)函数的主要功能就是解决当你在第 step个盒子的时候你该怎么办。通常的方法就是把每一种可能都去尝试一遍(一般使用 for 循环来遍历)。当前这一步解决后便进入下一步dfs(step+1)。下一步的解决方法和当前这步的解决方法是完全一样的。下面的代码就是深度优先搜索的基本模型。
void dfs(int step)
{
判断边界
尝试每一种可能 for(i=1;i< =n;i++)
{
继续下一步 dfs(step+1);
}
返回
}
排列与组合概念
排列:
一般地,从n个不同元素中取出m(m≤n)个元素,按照一定的顺序排成一列,叫做从n个元素中取出m个元素的一个排列(permutation)。特别地,当m=n时,这个排列被称作全排列(all permutation)。
例如n=4,m=2,集合A={1,2,3,4},即从A里选2个数排成一排,方案如下:
1 2 1 3 1 4
2 1 2 3 2 4
3 1 3 2 3 4
4 1 4 2 4 3
总共有12种排法,有些排列里数字是相同的,只不过顺序不一样。
组合:
是一个数学名词。一般地,从n个不同的元素中,任取m(m≤n)个元素为一组,叫作从n个不同元素中取出m个元素的一个组合。我们把有关求组合的个数的问题叫作组合问题。
例如n=4,m=2,集合A={1,2,3,4},即从A里选2个数进行,方案如下:
1 2 1 3 1 4
2 3 2 4
3 4
总共有6种组合,数字相同,顺序不一样的排列是一种组合,比如排列 1 2 和 2 1 是一种组合。
数字类搜索经典例题讲解:
例题1:全排列问题 P2696 全排列问题 - TopsCoding
输出自然数 1∼n 所有不重复的排列,即 n 的全排列,要求所产生的任一数字序列中不允许出现重复数字。
输入格式:一行,一个整数 n。
输出格式:输出由 1∼n 组成的所有不重复的数字序列。每行一个序列,行内数字之间用空格隔开。
样例输入:
3
样例输出:
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
数据范围:
对于 100% 的测试数据满足:1≤n≤9。
解题思路:看到这个题目,如果你还有一丝丝的疑惑就表示你对上面的第一个案例还没有弄明白,所谓的全排列的问题跟案例一扑克牌游戏其实是完全一样的题目。如果你直接把案例一的代码递交上去,会发现是可以直接ac的。
完整的代码如下:
#include< bits/stdc++.h>
using namespace std;
int a[10],book[10],n;
void dfs(int step) //step表示现在站在第几个盒子面前
{
int i;
if(step==n+1) //如果站在第n+1个盒子面前,则表示前n个盒子已经放在扑克牌
{
//输出一种排列(1-n号盒子中的扑克牌编号)
for(i=1;i< =n;i++)
{
cout< < a[i]< < " ";
}
cout< < endl;
return; //返回之前一步(最近一次调用dfs函数的地方)
}
//此时站在第step个盒子前,应该放哪张牌呢?
//按照1、2、3...n的顺序一一尝试
for(i=1;i< =n;i++)
{
//判断扑克牌i是否还在手上
if(book[i]==0) //将book[i]等于0表示扑克牌仍然在手上
{
//开始尝试使用扑克牌i
a[step]=i; //将第i号扑克牌放入第step个盒子中
book[i]=1; //将book[i]设为1,表示滴i号牌已经不在手中了
//第step个盒子已经放好扑克牌,接下来需要走到下一个盒子面前
dfs(step+1); //这里通过函数的递归用来实现
book[i]=0; //这是非常重要的一步,一定要将刚才尝试的扑克牌收回,才能进行下一次尝试
}
}
}
int main()
{
cin>>n;
dfs(1); //首先站在1号盒子前面
return 0;
}
例题2:集合元素排列 P1332 集合元素排列 - TopsCoding
设有 n个整数的集合 {1,2,…,n} ,从中取出任意 r 个数进行升序排列( r<=n ),试列出所有的排列。
输入格式
一行,包含两个整数 n和 r ,用空格隔开。( 0 < n <= 15, 0 ≤ r ≤ n )。
输出格式
所有符合条件的排列,每组排列一行,每行的每个数占 3 字符宽度,右对齐。
样例输入
3 2
样例输出:
1 2
1 3
2 3
解题思路:见解析
法一、
这里可以借助排列的思想,先确定第1个位置放的数,再确定第2个位置的数,...,最后确定第r个位置放的数,再递归下一步到达搜索出口。
令变量k表示当前选中的数所放的位置。k=1,2,3,...,r。
我们在考虑第k个位置放的数的情况时可以这样想,想放第k个数,那么第k-1的位置的数a[k-1],你肯定是已经确定好的,那么对于第k个位置来说,需要放的数从a[k-1]+1开始选择即可,一直到n,这里会出现,如果第k个数选择的过于靠后,那么从k+1到r这些位置选的数可能不够的情况,当然这些情况,在递归循环里会剔除不满足r个数的情况,无需担心。
//dfs中第k个数的选择范围只能是[a[k-1]+1,n]。
/*例如n=7,r=4;
1 2 3 4 5 6 7
第一个位置的数选择范围为[1,7];真实的是1-4
第二个位置的数选择范围为[2,7];真实的是2-5
第三个位置的数选择范围为[3,7];真实的是3-6
。。。
第k个位置的数选择范围为[a[k-1]+1,n];真实的是n-r+k,规律很简单可以推到
第k个位置的数的左值一定是从第k-1个数+1开始的
所以搜索里的循环是 for(int i=a[k-1]+1;i<=n;i++)
*/
#include<bits/stdc++.h>
using namespace std;
bool b[20];
int n,r,a[20];
void dfs(int k)
{
if(k==r+1)//到达递归出口
{
for(int i=1;i<=r;i++)cout<<setw(3)<<a[i];
cout<<endl;
return ;
}
for(int i=a[k-1]+1;i<=n;i++)//第k个数的范围只能是[a[k-1]+1,n]
{
if(b[i]==0)//数i没有被选中过
{
a[k]=i;//i加进来作为第k个选中的数
b[i]=1;//标记
dfs(k+1);//搜索下一层
b[i]=0;//取消标记
}
}
}
int main()
{
cin>>n>>r;
dfs(1);//确定的第1个位置的数
return 0;
}
法二、搜索剪枝
根据已知条件过滤不符合的搜索路径,保留符合要求的路径,每一层递归函数都进行剪枝操作,最终到达递归出口的结果就是符合问题的解
换句话说就是在进行搜索下一层前,要加相关的条件语句,作为剪枝的依据。
具体代码如下:
/*
搜索剪枝
只要确定b[i]==0 && i > a[k-1]即可
*/
#include<bits/stdc++.h>
using namespace std;
bool b[20];
int n,r,a[20];
void dfs(int k)
{
if(k==r+1)//到达递归出口
{
for(int i=1;i<=r;i++)cout<<setw(3)<<a[i];
cout<<endl;
return ;
}
for(int i=1;i<=n;i++)//
{
if(b[i]==0 && i>a[k-1])//数i没有被选中过且比第k-1个数大
{//i>a[k-1]就是剪枝的具体表现。对于小于等于a[k-1]的数就不需要层层递归下去了,都是无效的
a[k]=i;//i加进来作为第k个选中的数
b[i]=1;//标记
dfs(k+1);//搜索下一层
b[i]=0;//取消标记
}
}
}
int main()
{
cin>>n>>r;
dfs(1);//确定的第1个位置的数
return 0;
}
法三:
dfs函数可以添加两个参数
void dfs(int x,int k)//x表示当前层搜索的数的起始值,k表示要确定的数是第几个数,表示位置
{
}
#include <bits/stdc++.h>
using namespace std;
int flag[101];
int n, r;
void dfs(int x, int k)
{
// 边界返回条件:当前节点的处理
if(k == r)
{
for(int i = 1; i <= n; i++)
if(flag[i])
cout << setw(3) << i;
cout << endl;
return;
}
// 继续找下一个数
for(int i = x+1; i <= n; i++)
{
flag[i] = 1; // 选择 i
dfs(i, k+1);//下一个数的选择范围是从i开始,而不是x+1开始,保证数据有序
flag[i] = 0; // 取消选择
}
}
int main()
{
cin >> n >> r;
dfs(0, 0);
return 0;
}
例题3:选数 P1356 选数 - TopsCoding
已知 n 个整数 x1,x2,…,xn,以及一个整数 k(k<n)。从 n 个整数中任选 k个整数相加,可分别得到一系列的和。例如当 n=4,k=3,4 个整数分别为 3,7,12,19 时,可得全部的组合与它们的和为:
3+7+12=22 3+7+19=29 7+12+19=38 3+12+19=34。
现在,要求你计算出和为素数的方案共有多少种。
例如上例,只有一种的和为素数:3+7+19=29。
输入格式
键盘输入,格式为:
n,k(1≤n≤20,k<n)
x1,x2,...,xn(1≤xi≤5000000)
输出格式
一个整数(满足条件的种数)。
样例输入
4 3
3 7 12 19
样例输出
1
解题思路:见解析
#include< bits/stdc++.h>
using namespace std;
int a[25],f[25],s[25],m,n,s1=0,s2=0;
int prime(int x) //判断素数的函数
{
if(x< 2)
{
return 0;
}
for(int i=2;i< =sqrt(x);i++)
{
if(x%i==0)
{
return 0;
}
}
return 1;
}
void dfs(int t,int c)
{
s1=0;
if(t==n+1) //搜索结束条件
{
for(int i=1;i< t;i++) //求和
{
s1+=s[i];
}
if(prime(s1)==1) //如果和为素数
{
s2++;
}
return;
}
for(int i=c+1;i< =m;i++) //升序去重
{
if(f[i]==0) //跟上题完全一样
{
s[t]=a[i];
f[i]=1;
dfs(t+1,i);
f[i]=0;
}
}
}
int main()
{
//freopen(".in","r",stdin);
//freopen(".out","w",stdout);
cin>>m>>n;
for(int i=1;i< =m;i++)
{
cin>>a[i];
}
dfs(1,0); //1表示第几个数,0表示起始的值
cout< < s2;
return 0;
}
例题4:有重复元素的排列问题 P1363 有重复元素的排列问题 - TopsCoding
设 R={ r1, r2 , ..., rn} 是要进行排列的 n个元素。其中元素 r1, r2 , ..., rn 可能相同。试设计一个算法,列出 R的所有不同排列。
输入格式
第 11 行是元素个数 n,1≤n≤500。第二行是待排列的 n个元素(仅包含小写字母)。
输出格式
先输出 n个元素的所有不同排列,按字典序输出,最后一行输出排列总数。
样例输入
4
aacc
样例输出
aacc
acac
acca
caac
caca
ccaa
6
解题思路,见解析
#include < bits/stdc++.h>
using namespace std;
int n;
string s;
bool f[1000]={0};
char a[1000]={0};
int d=0;
void dfs(int cnt){
if(cnt>=n){
for(int i=0;i< n;i++)cout< < a[i];
cout< < endl;
d++;
return ;
}
char c='#'; //注意这里c的用法,为了去重,试试不加c会怎样
for(int i=0;i< s.size();i++){
if(f[i]==0&&c!=s[i]){
f[i]=1;
a[cnt]=s[i];
c=s[i];
dfs(cnt+1);
f[i]=0;
}
}
}
int main()
{
cin>>n;
cin>>s;
sort(s.begin(),s.end());
dfs(0);
cout< < d;
return 0;
}
例题5:素数环 P1348 素数环 I - TopsCoding
如图所示为一个由 n个圆圈构成的圆环。将自然数 1,2,...,n放入圆圈内,并且要求任意两个相邻的圆圈内的数字之和为素数。请问给你圆圈数,你能给出放置自然数的所有正确方案吗?
注意:圆圈中的数字一定是从1开始的,并且连续不重复。
输入格式:n(1< =n< =17)。
输出格式:把1放在第一位置,按照字典顺序不重复的输出所有解(顺时针,逆时针算不同的两种),相邻两数之间严格用一个整数隔开,每一行的末尾不能有多余的空格。 如果没有答案请输出"no answer"。
样例输入:
8
样例输出:
1 2 3 8 5 6 7 4
1 2 5 8 3 4 7 6
1 4 7 6 5 8 3 2
1 6 7 4 3 8 5 2
解题思路:仔细分析本道题,其实会发现跟全排列的题目有相似的地方,同样是n个不同的数字,只是本道题目里面的数字需要满足任意两个相邻的圆圈内的数字之和为素数。根据题意,把1放在第一位置,因此第一位一定是1,所以我们可以从第2个数开始搜索,同时把1标记为用过use[1]=1;。接下来我们开始写dfs()函数,用cur表示当前搜索到第几个数,如果当前这个数大于n,则搜索结束,搜索结束就可以输出一种可能性,这里需要特别注意的是还需要判断一下最后一个数跟第一个数字1的和是不是也是素数,这一点特别容易忽视。接下来开始写循环语句,从第2个数循环到第n个数,限制条件很简单,包括两个,一个是这个点没有用过即use[i]0;另一个是这个点跟上一个点之和为素数,即prime(i+a[cur-1])1(你也可以用素数筛来判断素数)。如果i满足限制条件就可以把i存在a[cur]里面,同时把i标记为1,即use[i]=1;这个数搞定了,紧接着,我们就可以开始搜索下一个数了,下一个数完全跟上一个数的搜索方法一样,因此可以直接调用dfs()函数,即dfs(cur+1);接下来就是最重要的一步,将i再标记成0。
完整代码如下所示:
#include< bits/stdc++.h>
using namespace std;
int a[20],f[20];
int n, ans=0;
int prime(int x)
{
if(x< 2) return 0;
for(int i=2;i< =sqrt(x);i++)
{
if(x%i==0) return 0;
}
return 1;
}
void dfs(int cur) //cur表示当前是第几个数
{
if(cur>n) //如果大于n,即n个数都输入环中,结束
{
if(prime(a[1]+a[n])==1) //结束的时候,还需要判断第n个数跟第一个数之和是不是素数
{
ans++;
for(int i=1;i< =n;i++)
{
cout< < a[i]< < " ";
}
cout< < endl; //如果成立,则输出这种排法
return;
}
}
for(int i=2;i< =n;i++) //从第2个数开始搜索
{
if(f[i]==0&′(i+a[cur-1])==1) //这个点没有搜过并且这个点跟上个点加起来是素数
{
a[cur]=i; //i保存在当前位置
f[i]=1; //这个数字搜过了,标记为1
dfs(cur+1); //开始搜下一个数
f[i]=0; //回溯,这个点又标记为0
}
}
}
int main()
{
cin>>n;
a[1]=1;
f[1]=1; //1一开始就被搜了,容易忽视
dfs(2); //从2开始搜索
if(ans==0) cout< < "no answer";
return 0;
}
例题6:特殊的质数肋骨 P2982 [USACO 1.5.3] Superprime Rib 特殊的质数肋骨 - TopsCoding
农民约翰的母牛总是产生最好的肋骨。你能通过农民约翰和美国农业部标记在每根肋骨上的数字认出它们。
农民约翰确定他卖给买方的是真正的质数肋骨,是因为从右边开始切下肋骨,每次还剩下的肋骨上的数字都组成一个质数。
举例来说:7 3 3 1 全部肋骨上的数字 7331 是质数;三根肋骨 733是质数;二根肋骨 73 是质数;当然,最后一根肋骨 7 也是质数。7331 被叫做长度 4 的特殊质数。
写一个程序对给定的肋骨的数目 n,求出所有的特殊质数。1不是质数。
输入格式
一行一个正整数 n。
输出格式
按顺序输出长度为 n 的特殊质数,每行一个。
样例输入
4
样例输出
2333
2339
2393
2399
2939
3119
3137
3733
3739
3793
3797
5939
7193
7331
7333
7393
数据范围
- 对于 100%的数据,1≤n≤8。
解题思路,见解析
#include< bits/stdc++.h>
using namespace std;
int n;
int prime(int x)
{
if(x< 2)
{
return 0;
}
for(int i=2;i< =sqrt(x);i++)
{
if(x%i==0)
{
return 0;
}
}
return 1;
}
void dfs(int k,int s)
{
if(k==n+1) //搜索结束条件
{
cout< < s< < endl;
s=0; //清零
return;
}
for(int i=1;i< =9;i++) //为什么不是从0开始?
{
if(prime(s*10+i)==1) //不对合成新的数字
{
dfs(k+1,s*10+i); //递归,搜索下一个
}
}
}
int main()
{
//freopen(".in","r",stdin);
//freopen(".out","w",stdout);
cin>>n;
dfs(1,0); //1表示第一个数,0表示开始
return 0;
}
例题7:自然数拆分问题 P2578 自然数的拆分问题 - TopsCoding
给你一个大于 1 的自然数 n,总可以拆分成若干个小于 n的自然数之和。
输入格式
待拆分的自然数 n(n≤10)
输出格式
若干个数的加法式子
样例
输入#1
7
输出#1
1+1+1+1+1+1+1
1+1+1+1+1+2
1+1+1+1+3
1+1+1+2+2
1+1+1+4
1+1+2+3
1+1+5
1+2+2+2
1+2+4
1+3+3
1+6
2+2+3
2+5
3+4
解题思路,见解析
#include< bits/stdc++.h>
using namespace std;
int a[50],n;
void sc(int c) //输出函数
{
cout< < a[1];
for(int i=2;i< c;i++)
{
cout< < "+"< < a[i];
}
cout< < endl;
}
void dfs(int sum,int cur)
{
if(sum==n) //如果和等于输入的数字,则拆分成功
{
sc(cur);
return ;
}
for(int i=a[cur-1];i< n;i++) //去重,想想为什么?
{
if(sum+i< =n) //剪枝,想想为什么?
{
a[cur]=i; //把这个数字存起来
dfs(sum+i,cur+1); //递归搜索下一个位置
}
}
}
int main()
{
//freopen(".in","r",stdin);
//freopen(".out","w",stdout);
cin>>n;
a[0]=1; //0不能参与拆分
dfs(0,1); //0表示一开始和为0,1表示第一位置
return 0;
}
例题8:回文拆分 P1495 回文拆分 - TopsCoding
对一个正整数 K,求出 K 的所有拆分,并统计输出其中回文数列的个数。所谓回文数列是指该数列中的所有数字,从左向右或从右向左看都相同。
例如,K=4 时,有如下的拆分:
4=1+1+1+1
=1+1+2
=1+2+1
=2+1+1
=2+2
=1+3
=3+1
回文数列共有 3 个:1+1+1+1,1+2+1,2+2。
输入格式
一行个正整数 K,1≤ K ≤26。
输出格式
一行一个正整数,所有拆分形成的回文数列个数。
样例输入
4
样例输出
3
解题思路,见解析
#include< bits/stdc++.h>
using namespace std;
int a[30];
int n, cnt;
bool check(int n)
{
for (int i = 1; i < = n; i++)
{
if (a[i] != a[n - i + 1])
return 0;
}
return 1;
}
void dfs(int step, int s)
{
if (s > n) return ;
if (s == n)
{
if (check(step - 1)) cnt++;
return ;
}
for (int i = 1; i < = n-s; i++)
{
a[step] = i;
dfs(step + 1, s + i);
}
}
int main()
{
cin >> n;
dfs(1, 0);
cout< < cnt-1;
}
第二章:深搜入门(二维方向 迷宫类)
不撞南墙不回头-深度优先搜索
广度优先搜索BFS是每次将当前状态能够一步拓展出的所有状态,全部拓展出来依次存入队列。而深度优先搜索是将当前状态按照一定的规则顺序,先拓展一步得到一个新状态,再对这个这个新状态递归拓展下去。如果无法拓展,则退回一步到上一步的状态,再按照原先设定的规则顺序重新寻找一个状态拓展。如此搜索,直到找到目标状态,或者遍历完所有的状态。
深度优先搜索
深度优先搜索(Depth First Search,DFS),简称 深搜 ,其状态“退后一步”的顺序符合“后进先出”的特点,所以采用“栈”存储状态。深搜的空间复杂度较小,因为它只存储了初始状态到当前状态的一条搜索路径。但是,深搜找到的第一个解不一定是最优解,要找最优解必须搜索整棵“搜索树”。所以,深搜适用于要求所有解方案的题目。
相信通过上面的描述,同学们还是对深度优先搜索一头雾水。下面我们结合一个例子,和大家一起探索下什么是深度优先搜索。深度优先搜索可以这样想,一个人迷路了,遇到很多分叉路口,他只有一个人,并且想走出去,所以他只能一个个路线的去尝试, 一条道路走到黑,发现到头了,然后再退回去走刚才这条路的其他分叉路口,最后发现这条路的所有分叉路口走完了,选择另外一条路继续以上操作,直到所有的路都走过了。
而广度优先并不是这样,一个人迷路了,但是他有特异技能(就好比火影里面鸣人的影分身一样), 他遇到分叉路口,不是选一个走,而是分身多个人每个路口都去试试 ,比如有A、B、C三个分叉路口,A路走一步,紧接着B路也走一步,然后C路也赶紧走一步,步伐整齐统一,直到所有的路走过了。
深度优先搜索的步骤
深度优先搜索的步骤分为 1.递归下去 2.回溯上来。顾名思义,深度优先,则是以深度为准则,先一条路走到底,直到达到目标,这里称之为递归下去。否则既没有达到目标又无路可走了,那么则退回到上一步的状态,走其他路,这便是回溯上来。下面结合具体例子来理解。如图所示,在一个迷宫中,黑色块代表玩家所在位置,红色块代表终点,问是否有一条到终点的路径。
我们用深度优先搜索的方法去解这道题,由图可知,我们可以走上下左右四个方向,我们规定按照 左下右上 的方向顺序走(逆时针方向),即如果左边可以走,我们先走左边。然后递归下去,没达到终点,我们再回溯上来,等又回溯到这个位置时,左边已经走过了,那么我们就走下边,按照这样的顺序与方向走。并且我们把走过的路标记一下代表走过,不能再走。所以我们从黑色起点首先向左走,然后发现还可以向左走,最后我们到达图示位置。
已经连续向左走到左上角的位置了,这时发现左边不能走了,这时我们就考虑往下走,发现也不能走,同理,上边也不能走, 右边已经走过了也不能走,这时候无路可走了 ,代表这条路是死路不能帮我们解决问题, 所以现在要回溯上去,回溯到上一个位置。
在这个位置我们由上可知走左边是死路不行,上下是墙壁不能走,而右边又是走过的路,已经被标记过了,不能走。所以只能再度回溯到上一个位置寻找别的出路。
最终我们回溯到最初的位置,同理,左边证明是死路不必走了,上和右是墙壁, 所以我们走下边 。然后递归下去
到了这个格子,因为按照左下右上的顺序,我们走左边,递归下去
一直递归下去到最左边的格子,然后左边行不通,走下边,一直往下走,正好可以找到目标位置。
广度优先搜索较之深度优先搜索之不同在于,深度优先搜索旨在不管有多少条岔路, 先一条路走到底,不成功就返回上一个路口然后就选择下一条岔路 ,而广度优先搜索旨在面临一个路口时,把所有的岔路口都记下来,然后选择其中一个进入,然后将它的分路情况记录下来,然后再返回来进入另外一个岔路,并重复这样的操作,用图形来表示则是这样的,例子同上。
从黑色起点出发,记录所有的岔路口,并标记为走一步可以到达的。然后选择其中一个方向走进去,我们走黑点方块上面的那个,然后将这个路口可走的方向记录下来并标记为2,意味走两步可以到达的地方。
接下来,我们回到黑色方块右手边的1方块上,并将它能走的方向也记录下来,同样标记为2,因为也是走两步便可到达的地方
这样走一步以及走两步可以到达的地方都搜索完毕了,下面同理,我们可以迅速把三步的格子给标记出来
再之后是四步,五步。
我们便成功寻找到了路径,并且把所有可行的路径都求出来了。
广度优先搜索和深度优先搜索的比较
在广度优先搜索中,可以看出是逐步求解的,反复的进入与退出,将当前的所有可行解都记录下来,然后逐个去查看。 在DFS中我们说关键点是递归以及回溯,在BFS中,关键点则是状态的选取和标记。
对于这两个搜索方法,其实我们是可以轻松的看出来,他们有许多差异与许多相同点的。
1.数据结构上的运用
DFS用递归的形式,用到了 栈 结构,先进后出。
BFS选取状态用 队列 的形式,先进先出。
2.复杂度
DFS的复杂度与BFS的复杂度大体一致,不同之处在于遍历的方式与对于问题的解决出发点不同,DFS适合目标明确,而BFS适合大范围的寻找。
3.思想
思想上来说这两种方法都是穷竭列举所有的情况。
入门例题
T1:扫地机器人(题号:3855)
本题需要掌握下列内容:
1、理解赋值的顺序,任意给定一个n×m的矩阵,能够写出赋值的结果;
2、理解递归的过程,任意给定一个n×m的矩阵,能够画出递归的过程;
3、理解程序编写的过程,和实现的原理;
4、理解函数递归调用的过程;
5、理解迷宫类递归的几种不同写法;
解题思路:
本题要求为矩阵每个点赋值,可以定义函数,来为矩阵赋值,比如:定义函数fun(int x,int y,int k),含义是为点 \((x,y)\) 赋值为 \(k\) 。
调用函数时,首先为点\((1,1)\)赋值为\(1\),也就是\(fun(1,1,1)\)。既然函数能够为点\((1,1)\)赋值,也就能为点\((1,2)\)赋值,以此类推,是典型的递归思想。
要注意,每次递归,所赋的值\(k\)要\(+1\)。
输入输出代码
#include <bits/stdc++.h>
using namespace std;
int n,m;
int a[20][20];
//为二维数组赋值
//为点(x,y)赋值为k
void fun(int x,int y,int k)
{
//关键代码,待完成
}
int main(){
//n行m列
cin>>n>>m;
//递归函数,逐个递归赋值
fun(1,1,1);
//输出
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
cout<<setw( 3 )<<a[i][j];
}
cout<<endl;
}
}
注意理解以下四种解法的不同之处,并逐渐熟练掌握和理解。
解法一
关键思路 :从出发点开始,探测每个点,标记数字,标记结束后,分别递归四个方向, 如果探测的点满足要求 ,则访问该点!
//为点(x,y)赋值为k
void fun(int x,int y,int k)
{
//赋值
a[x][y] = k;
//递归的条件:不能出边界,且不能访问已经赋值的点
//优先向右,其次向下,再次向左,再次向上
//向右尝试
if(y+1<=m && a[x][y+1]==0) fun(x,y+1,k+1);
//向下尝试
if(x+1<=n && a[x+1][y]==0) fun(x+1,y,k+1);
//向左尝试
if(y-1>=1 && a[x][y-1]==0) fun(x,y-1,k+1);
//向上尝试
if(x-1>=1 && a[x-1][y]==0) fun(x-1,y,k+1);
}
解法二
关键思路 :从出发点开始,探测每个点,标记数字,标记结束后,分别递归四个方向, 不管探测点是否可行,直接递归访问,在递归一进来的地方判断递归点是否可访问 !
//为x,y点赋值为k
void fun(int x,int y,int k)
{
//由于每次递归前没有检验递归的点是有效点
//因此可能xy是无效的(出了边界的点,或者已经赋值的点)
if(x >= 1 && x <= n && y >= 1 && y <= m && a[x][y] == 0){
a[x][y] = k;//赋值
//优先向右,其次向下,再次向左,再次向上
//向右尝试
fun(x,y+1,k+1);
//向下尝试
fun(x+1,y,k+1);
//向左尝试
fun(x,y-1,k+1);
//向上尝试
fun(x-1,y,k+1);
}
}
解法三
关键思路 :使用方向数组,循环递归访问四个方向!在递归前判断准备探测点的正确性。
//定义方向数组,存储×和y变化的值
int dx[4] = { 0,1,0,-1 };
int dy[4] = { 1,0,-1,0 };
//为点(x,y)赋值为k
void fun(int x, int y, int k) {
a[x][y] = k;//赋值
//优先向右,其次向下,再次向左,再次向上
//通过循环方向值变化的数组,将x和y变化的值逐个加到x和y上
int tx, ty; //表示将要访问的点
for (int i = 0; i < 4; i++) {
tx = x + dx[i];
ty = y + dy[i];
//在递归前判断准备探测点的正确性。
if (tx >= 1 && tx <= n && ty >= 1 && ty <= m && a[tx][ty] == 0) {
//只有点正确了,才进行递归
fun(tx, ty, k + 1);
}
}
}
解法四
关键思路 :使用方向数组,循环递归访问四个方向!不管点是否正确,直接递归,在递归进来的地方判断点是否正确。
//定义方向数组,存储×和y变化的值
int dx[4] = { 0,1,0,-1 };
int dy[4] = { 1,0,-1,0 };
//为点(x,y)赋值为k
void fun(int x, int y, int k) {
//由于每次递归前没有检验递归的点是有效点,因此可能xy是无效的(出了边界的点,或者已经赋值的点)
//所以,我们上来就判断点是否正确。
if (x >= 1 && x <= n && y >= 1 && y <= m && a[x][y] == 0) {
a[x][y] = k;//赋值
//优先向右,其次向下,再次向左,再次向上
//通过循环方向值变化的数组,将x和y变化的值逐个加到x和y上
int tx, ty; //表示将要访问的点
for (int i = 0; i < 4; i++) {
tx = x + dx[i];
ty = y + dy[i];
//直接递归,不管点是否正确,我们在下一次调用函数的最开始判断
fun(tx, ty, k + 1);
}
}
}
例题精讲
T1:迷宫出口(题号:3868)
【思路】从出发点开始,探测所有可探测的点,看是否有目标点,如果有,就表示可达,否则表示不可达!
【关键代码】
#include <bits/stdc++.h>
using namespace std;
//存放迷宫
int a[109][109];
//方向数组
int dx[4] = {0,1,0,-1};
int dy[4] = {1,0,-1,0};
int n, sx, sy, ex, ey;//sx,sy表示起始点,ex,ey表示终止点
bool f = false;//初始认为走不到终点
void dfs(int x, int y){
a[x][y] = 1;//将走过的点标记为1,防止死循环
int tx, ty;//表示将要探寻的点
for(int i = 0; i < 4; i++){
tx = x + dx[i];
ty = y + dy[i];
//新的点可以访问,并且没有越界
if(tx>=1&&tx<=n&&ty>=1&&ty<=n&&a[tx][ty]==0&&f==false){
if(tx==ex&&ty==ey){
f = true;
}else{
dfs(tx, ty);
}
}
}
}
int main()
{
cin >> n;
//读入迷宫
for(int i = 1;i <= n; i++){
for(int j = 1; j <= n; j++){
cin >> a[i][j];
}
}
//读入起始点和终止点
cin >> sx >> sy >> ex >> ey;
//如果起始点和终止点不可到达则不需要递归
if(a[sx][sy]==1 || a[ex][ey] == 1){
cout << "NO";
}
else
{
dfs(sx, sy);
if(f == true)
cout << "YES";
else
cout << "NO";
}
}
T2:数池塘(四方向)(题号:3870)
【思路】从属于池塘的点开始,探测所有属于池塘的点,看是否有池塘点,如果有,可以把池塘标记为.,直到这次搜索搜不到新的点。
【关键代码】
#include<bits/stdc++.h>
using namespace std;
int n,m;
char a[150][150];
void dfs(int x,int y){
//标记为已访问
a[x][y]='.';
//搜索四个方向能访问点
if(a[x-1][y]=='W') dfs(x-1,y);
if(a[x][y-1]=='W') dfs(x,y-1);
if(a[x+1][y]=='W') dfs(x+1,y);
if(a[x][y+1]=='W') dfs(x,y+1);
}
int main(){
//输入,并存储迷宫
cin>>n>>m;
int i,j,c=0;
for(i=1;i<=n;i++){
for(j=1;j<=m;j++){
cin>>a[i][j];
}
}
//每个点都访问一遍,若属于池塘,计数+1,并递归访问与该池塘相邻的所有池塘
for(i=1;i<=n;i++){
for(j=1;j<=m;j++){
if(a[i][j]=='W'){
c++;
dfs(i,j);
}
}
}
//最终输出
cout<<c;
}
作业
http://www.topscoding.com/p/3875, 数池塘(八方向)
http://www.topscoding.com/p/1203, 细胞
http://www.topscoding.com/p/3925, 奶牛和草丛
第三章:深搜进阶(迷宫类问题--最少步数和输出路径)
深搜--迷宫类问题--最少步数和输出路径
最少步数问题
【例题】:走出迷宫的最少步数(题号:3871)
【分析】
1、首先我们需要创建一个数组\(a\)用来存储迷宫,再创建一个\(dis\)数组,存放走到每个点的步数。
2、按照右下左上的行进方式,回溯到\((1,3)\)点,还有下面的走法。
3、在\((2,3)\)点往右走不了之后,我们还可以往左走。得到新的路径。
4、回溯到\((1,2)\)点的时候,还有更短的路径,更新这条路径。
5、继续回溯,到\((1,1)\)点的时候,还有更短的路径,更新这条路径。得到最终的路径。
【关键思路】:
如果走到某个点\((x,y)\)需要的步数,比\(dis\)数组中记录的最少步数还少,则走该点。
【初始状态】:
\(dis\)数组的初始值设置为INT_MAX。
【递归函数设计】:
\(dfs(x,y,k)\)表示到达点\((x,y)\)需要的最少步数为\(k\)。在递归时,要\(dfs(tx,ty,k+1)\)。
【总体思路】:
1、准备一个整数数组,记录从出发点到每个点至少需要多少步,初始化为INT_MAX;
2、从出发点开始探测,顺时针探测,如果该点可达,且到该点的步数更少,则替换\(dis\)数组的步数;
3、最终\(dis\)数组记录了到每个点至少需要多少步,\(a[n][m]\)就是最终结果。
递归的重点是防止死循环!!!
写代码如有bug,则可以通过在递归中输出关键信息,来检查bug
【参考代码】:
#include <bits/stdc++.h>
using namespace std;
int m, n;
char a[50][50];//存放迷宫
int dis[50][50];//存储步数
int dx[4] = {0,1,0,-1};//x方向数组
int dy[4] = {1,0,-1,0};//y方向数组
//检查一个点是否走出了地图
bool check(int x, int y){
return x>=1 && x<=n && y>=1 && y<=m;
}
//递归探索迷宫,求走到每个点最少需要多少步
void dfs(int x, int y, int dep){
dis[x][y] = dep;
for(int i = 0; i < 4; i++){
int tx = x + dx[i];
int ty = y + dy[i];
//如果点(tx,ty)可以探索(在地图内,且可以走,且步数更少)
if(check(tx, ty) && a[tx][ty]=='.' && dep+1<dis[tx][ty]){
dfs(tx, ty, dep+1);
}
}
}
int main()
{
cin >> n >> m;//n行m列
for(int i = 1; i <= n; i++){
for(int j = 1; j <= m; j++){
cin >> a[i][j];
dis[i][j] = INT_MAX;//最少步数初始化为INT_MAX
}
}
dfs(1, 1, 1);//调用深搜函数
cout << dis[n][m];//输出最终答案
}
第一条路径问题
解救小拓(图形类深搜模板题)
有一天,小拓一个人去玩迷宫。但是方向感很不好的小拓很快就迷路了。小哼得知后便立即去解救无助的小拓。小哼当然是有备而来,已经弄清楚了迷宫的地图,现在小哼要以最快的速度去解救小拓。问题就此开始了……
迷宫由n行m列的单元格组成(n和m都小于等于50),每个单元格要么是空地,要么是障碍物。你的任务是帮助小哼找到一条从迷宫的起点通往小拓所在位置的最短路径。注意障碍物是不能走的,当然小哼也不能走到迷宫之外。
首先我们可以用一个二维数组来存储这个迷宫,刚开始的时候,小哼处于迷宫的入口处(1,1),小拓在(p,q)。其实,就是找从(1,1)到(p,q)的最短路径。如果你是小哼,你该怎么办呢?小哼最开始在(1,1),他只能往右走或者往下走,但是小哼是应该往右走呢还是往下走呢。此时要是能有两个小哼就好了,一个向右走,另外一个向下走。但是现在只有一个小哼,所以只能一个一个地去尝试。我们可以先让小哼往右边走,直到走不通的时候再回到这里,再去尝试另外一个方向。我们这里规定一个顺序,按照顺时针的方向来尝试(即按照右、下、左、上的顺序去尝试)。
我们先来看看小哼一步之内可以达到的点有哪些?只有(1,2)和(2,1)。根据刚才的策略,我们先往右边走,小哼来到了(1,2)这个点。来到(1,2)之后小哼又能到达哪些新的点呢?只有(2,2)这个点。因为(1,3)是障碍物无法达到,(1,1)是刚才来的路径中已经走过的点,也不能走,所以只能到(2,2)这个点。但是小拓并不在(2,2)这个点上,所以小哼还得继续往下走,直至无路可走或者找到小拓为止。请注意!此处并不是一找到小拓就结束了。因为刚才只尝试了一条路,而这条路并不一定是最短的。刚才很多地方在选择方向的时候都有多种选择,因此我们需要返回到这些地方继续尝试往别的方向走,直到把所有可能都尝试一遍,最后输出最短的一条路径。例如下图就是一种可行的搜索路径。
现在我们尝试用深度优先搜索来实现这个方法。先来看 dfs()函数如何写。dfs()函数的功能是解决当前应该怎么办。而小哼处在某个点的时候需要处理的是∶先检查小哼是否已经到达小拓的位置,如果没有到达则找出下一步可以走的地方。为了解决这个问题,此处 dfs()函数只需要3个参数,分别是当前这个点的x坐标、y坐标以及当前已经走过的步数 step。 dfs()函数定义如下。
void dfs(int x,int y,int step)
{
return ;
}
是否已经到达小拓的位置这一点很好实现,只需要判断当前的坐标和小拓的坐标是否相等就可以了,如果相等则表明已经到达小拓的位置,如下。
void dfs(int x,int y,int step)
{
//判断是否到达小拓的位置
if(x==p && y==q)
{
//更新最小值
if(step< min)
{
min=step;
}
return ; //请注意这里返回很重要
}
return ;
}
如果没有到达小拓的位置,则找出下一步可以走的地方。因为有四个方向可以走,根据我们之前的约定,按照顺时针的方向来尝试(即按照右、下、左、上的顺序尝试)。这里为了编程方便,我定义了一个方向数组 next,如下。
int next[4][2]={{0,1}, //向右走
{1,0}, //向下走
{0,-1}, //向左走
{-1,0}}; //向上走
通过这个方向数组,使用循环就很容易获得下一步的坐标。这里将下一步的横坐标用 tx存储,纵坐标用 ty 存储。
for(k=0;k< =3;k++)
{
//计算的下一个点坐标
tx=x+next[k][0];
ty=y+next[k][1];
}
接下来我们就要对下一个点(x,ty)进行一些判断。包括是否越界,是否为障碍物,以及这个点是否已经在路径中(即避免重复访问一个点)。需要用book[tx][ty]来记录格子(tx,ty)是否已经在路径中。如果这个点符合所有的要求,就对这个点进行下一步的扩展,即 dfs(tx,ty,step+1),注意这里是 step+1,因为一旦你从这个点开始继续往下尝试,就意味着你的步数已经增加了1。
完整的代码实现如下:
#include< bits/stdc++.h>
using namespace std;
int n,m,p,q,mmin=999999;
int a[51][51],book[51][51];
void dfs(int x,int y,int step)
{
int dx[4]={0,1,0,-1};
int dy[4]={1,0,-1,0};
//四个方向,方向顺序不能错
int tx,ty;
//判断是否到达小拓的位置
if(x==p && y==q)
{
//更新最小值
if(step< mmin)
{
mmin=step;
}
return ; //请注意这里返回很重要
}
//枚举四种走法
for(int i=0;i< =3;i++)
{
//计算的下一个点坐标
tx=x+dx[i];
ty=y+dy[i];
//判断该点是否为障碍物或者已经在路径中
if(a[tx][ty]==0&&book[tx][ty]==0&&tx>=1&&tx< =n&&ty>=1&&ty< =m)
{
book[tx][ty]=1; //标记这个点已经走过
dfs(tx,ty,step+1); //开始尝试下一个点
book[tx][ty]=0; //尝试结束后,取消这个点的标记
}
}
return ;
}
int main()
{
int i,j,startx,starty;
cin>>n>>m;
for(i=1;i< =n;i++)
{
for(j=1;j< =m;j++)
{
cin>>a[i][j]; //读入迷宫
}
}
cin>>startx>>starty>>p>>q; //读入开始和结束坐标
//从起点开始搜索
book[startx][starty]=1; //标记该点已经在路径中,反正后面重复走
//第一个参数是起点的x的坐标,第二个参数是起点的y坐标,第三个参数是初始步数为0
dfs(startx,starty,0);
//输出最短步数
cout< < mmin;
return 0;
}
可以输入以下数据进行验证。第一行有两个数n和m。n表示迷宫的行,m表示迷宫的列。接下来的n行m列为迷宫,0表示空地,1表示障碍物。最后一行 4个数,前两个数为迷宫入口的x和y坐标。后两个为小拓的x和y坐标。运行结果是7。
5 4
0 0 1 0
0 0 0 0
0 0 1 0
0 1 0 0
0 0 0 1
1 1 4 3
【例题】:迷宫的第一条出路(题号:3872)
【分析】
1、首先我们需要创建一个数组\(a\)用来存储迷宫,再创建一个\(rec\)的二维数组(其他的数据存储方式也可以,只要能记录点的坐标即可),存放走的第一条路径。
2、之后我们每走到一个点,就记录到\(rec\)数组中去。
3、按照左、上、右、下的原则走到每一个点,同时在\(rec\)数组中记录每个点。
4、在上面图片的情况下,我们走到了死胡同。那么就必须要回溯了。注意:回溯的时候,\(rec\)数组中还记录着我们错误的路径。那么我们怎么来保证递归回溯到上一层的时候,\(rec\)数组也往回退一层呢?
5、我们回到\((1,1)\)点之后,还可以向下走。如果我们递归的同时记录了在哪一层,是不是就非常方便了!
6、继续搜索,一直搜到终点。那么\(rec\)数组中记录的就是路径啦!
【关键思路】:
创建rec数组,存放路径 。可以继续走的时候,存放下一个点放到rec数组中。当 不能往下走 的时候, 递归回到上一层,rec数组的记录的位置上移一层 。这样,就可以覆盖掉错误的路径。当我们走到终点时,就结束。
【递归函数设计】:
我们可以 用递归函数中的参数k记录到达rec的哪一层 。\(dfs(x,y,k)\)表示向路径数组\(rec\)中第\(k\)行的位置,记录一个坐标\((x,y)\)。在递归下一层时,和之前一样,要\(dfs(tx,ty,k+1)\),存放下一个点。
【参考代码】:
#include <bits/stdc++.h>
using namespace std;
int n;
char a[30][30];//存放迷宫
int rec[410][2];//路径数组,存放迷宫的第一条正确路径
//方向数组:左、上、右、下
int dx[4] = {0,-1,0,1};
int dy[4] = {-1,0,1,0};
bool f = false;//标记搜索结束
//打印第一条路径
void display(int k){
for(int i = 1; i <= k; i++){
cout<<"("<<rec[i][0]<<","<<rec[i][1]<<")";
if(i != k) cout << "->";
}
}
//向路径数组rec中k的位置,记录一个坐标(x,y)
void dfs(int x, int y, int k){
//记录坐标
rec[k][0] = x, rec[k][1] = y;
//标记当前点为'1',防止死循环
a[x][y] = '1';
//如果走到终点,打印路径,并结束搜索
if(x == n && y == n){
f = true;//用f标记结束深搜
display(k);
}
//由点(x,y)探索新的点
for(int i = 0; i < 4; i++){
int tx = x + dx[i];
int ty = y + dy[i];
//如果点(tx,ty)可以探索(在地图内,且可以走)
if(a[tx][ty]=='0' && f == false){
dfs(tx, ty, k+1);//向rec数组的k+1行记录坐标(tx,ty)
}
}
}
int main()
{
cin >> n;//n行m列
for(int i = 1; i <= n; i++){
for(int j = 1; j <= n; j++){
cin >> a[i][j];
}
}
dfs(1, 1, 1);//调用深搜函数
return 0;
}
【思考一下】:
为什么程序的第\(38\)行if(a[tx][ty]=='0' && f == false),这里不需要判断边界呢?
所有路径问题
例题:卒的遍历(题号:3873)
【分析】
1、和上一题一样,我们创建\(a\)数组用来存放迷宫,创建\(rec\)数组存放路径。
2、由于本题只能往下和往右,所以我们每走一个点,就记录一个点的坐标到\(rec\)数组中。
3、先下,后右。我们继续扩展新的点。
4、往下走到底之后不能往下走了,只能往右走。到达终点之后,\(rec\)数组存放的就是我们的第一条路径,就可以输出了。
5、从\((3,3)\)回溯,到\((3,2)\)不能走,到\((3,1)\)也不行,回到了\((2,1)\)。
6、在\((2,1)\),我们还可以往右走。所以往右,继续往\(rec\)数组中存放新的坐标,覆盖掉之前的坐标。
7、注意了,我们在\((2,2)\)点还是优先往下的哦!这样我们得到了一个新的路径,输出这个新的路径!
8、继续回溯。
9、回溯到(2,2)点的时候,还能向右走。所以又得到了一个路径。
10、此时我们从\((1,1)\)点往下走的所有路径都遍历完了,同学们试试从\((1,1)\)点往下还有没有其他的路径呢?
11、往下走的找完了,我们接下来按照要求,从\((1,1)\)点往右找。注意了,我们 到达新的点之后还是遵循先下、后右的原则 。
12、最终,我们得到了一条新的路径!
【思考一下】:
这里还有没找过的路径吗?
【关键思路】:
创建rec数组,存放路径。可以继续走的时候,存放下一个点放到\(rec\)数组中。当不能往下走的时候,递归回到上一层,\(rec\)数组的记录的位置上移一层。 当我们走到终点时,就递归回到上一层,继续寻找下一条路径 。
同时应该注意到,我们还要输出当前是第几条路径,我们 创建一个全局变量\(cnt\)存储当前是第几条路径 即可。
【递归函数设计】:
我们可以继续 用递归函数中的参数\(k\)记录到达\(rec\)的哪一层 。\(dfs(x,y,k)\)表示向路径数组\(rec\)中\(k\)的位置,记录一个坐标\((x,y)\)。在递归时,和之前一样,要\(dfs(tx,ty,k+1)\),存放下一个点。
【参考代码】:
#include <bits/stdc++.h>
using namespace std;
int n, m;
int rec[20][2];//路径数组
int cnt;//路径个数
//输出路径函数
void display(int k){
cnt++;//当前是第cnt个路径
cout << cnt << ":";
for(int i = 1; i < k; i++){
cout << "(" << rec[i][0] << "," << rec[i][1] << ")->";
}
cout << "(" << rec[k][0] << "," << rec[k][1] << ")" << endl;
}
//向路径数组rec中记录点(x,y)
void dfs(int x, int y, int k){
//记录点(x,y)
rec[k][0] = x;
rec[k][1] = y;
//如果遇到终点,则输出路径
if(x == n && y == m){
display(k);
return;
}
if(x + 1 <= n) dfs(x+1, y, k+1); //向下搜索
if(y + 1 <= m) dfs(x, y+1, k+1); //向右搜索
}
int main(){
cin >> n >> m;//n行m列
dfs(1,1,1);
}
未完待续。
标签:Search,递归,扑克牌,int,Depth,dfs,step,搜索,DFS From: https://www.cnblogs.com/Yzc-wm/p/18158673