Kubernetes部署安全认证ELK集群
一. 概述
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
1、工作流程图
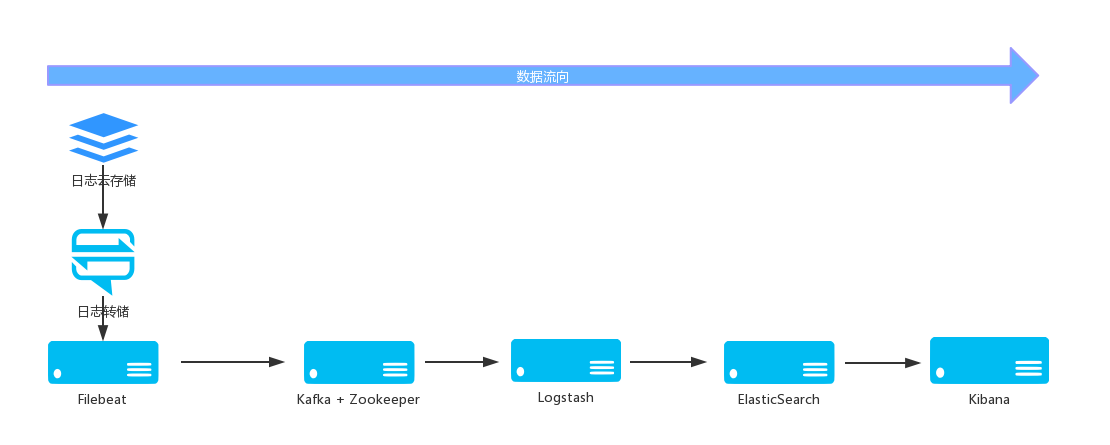
2、组件关系图
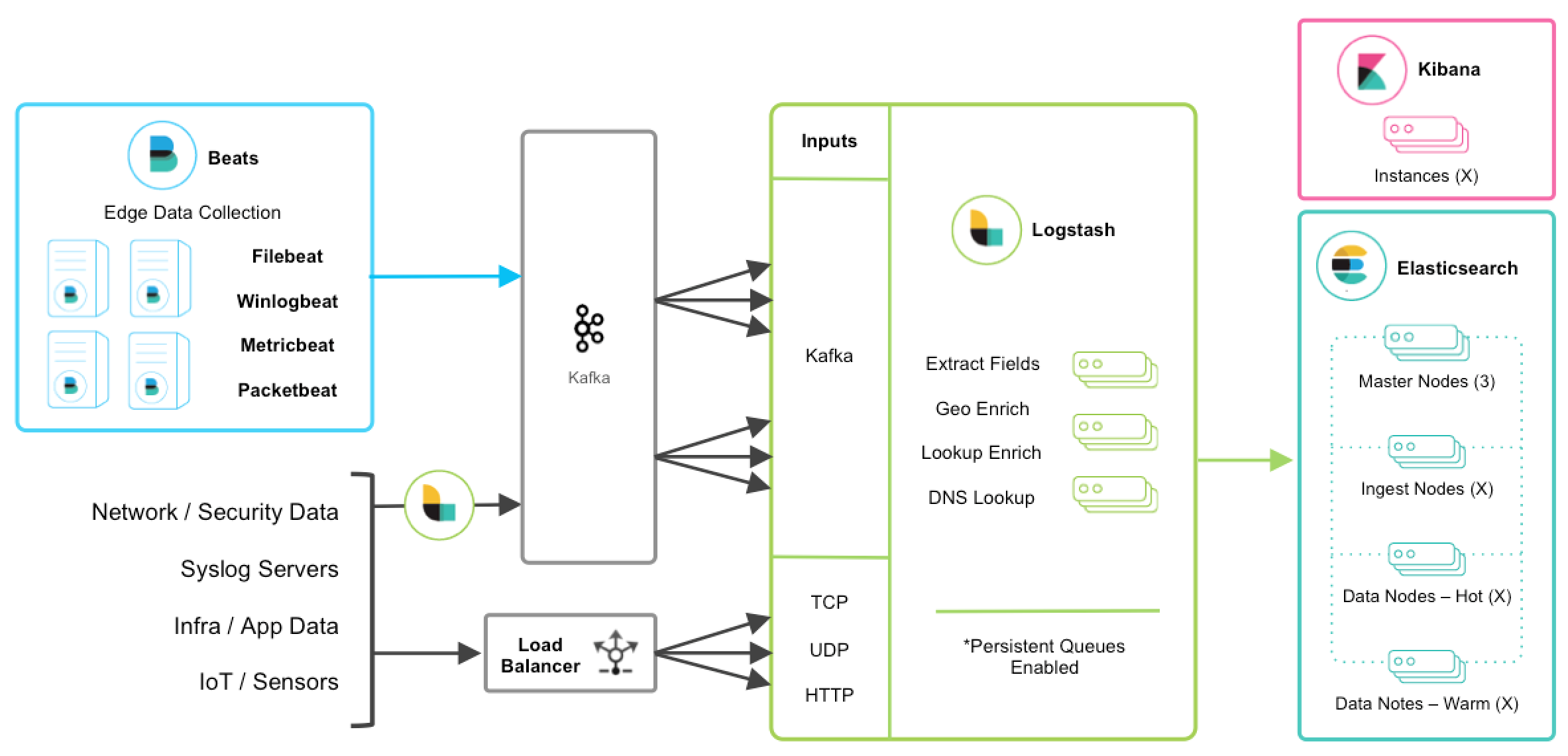
3、组件介绍
1、Elasticsearch 存储
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
ElasticSearch 节点类型与作用
Elasticsearch 节点类型和配置在集群的设计和性能优化中起着关键作用。以下是一些常见的 Elasticsearch 节点类型以及它们的配置示例:
- 主节点 (Master Nodes):
作用:主节点用于管理集群状态、索引创建和分片分配。它们不负责数据存储或搜索查询。
配置示例:
node.master: true
node.data: false
- 数据节点 (Data Nodes):
作用:数据节点存储索引数据并执行搜索查询。
配置示例:
node.master: false
node.data: true
- 协调节点 (Coordinator Nodes):
作用:协调节点用于接收客户端请求,并将其路由到数据节点。
配置示例:
node.master: false
node.data: false
- 仲裁节点 (Arbitrator Nodes):
作用:仲裁节点不存储数据,但可以参与主节点选举。
配置示例:
node.master: true
node.data: false
- Ingest 节点:
作用:Ingest 节点用于文档的预处理和转换。
配置示例:
node.master: false
node.data: false
node.ingest: true
- Machine Learning 节点:
作用:Machine Learning 节点用于运行 Elasticsearch 的机器学习任务。
配置示例:
node.ml: true
- Transform 节点:
作用:Transform 节点用于执行数据转换操作,将结果存储在新的索引中。
配置示例:
node.transform: true
- Remote 节点:
作用:Remote 节点用于转发请求到远程 Elasticsearch 集群。
配置示例:
node.remote_cluster_client: true
- Hot-Warm-Cold 节点:
作用:Hot 节点用于接收实时数据,Warm 节点用于冷热数据分离,Cold 节点用于长期存储。
配置示例:
node.attr.hot: true
node.attr.warm: true
node.attr.cold: true
请注意,上述示例是典型的节点类型和配置示例。在实际的集群配置中,可以根据需求和性能要求进行更详细的调整。配置文件通常是
Elasticsearch的elasticsearch.yml,你可以在每个节点上的该文件中设置节点类型和其他相关配置。根据需要,你可以将不同的节点类型配置在不同的节点上,以构建具有适当角色的Elasticsearch集群。同时,还可以使用其他设置来调整内存、存储、网络和性能参数,以满足特定的用例需求。
2、Logstash 过滤
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
优点
- 可伸缩性
节拍应该在一组Logstash节点之间进行负载平衡。
建议至少使用两个Logstash节点以实现高可用性。
每个Logstash节点只部署一个Beats输入是很常见的,但每个Logstash节点也可以部署多个Beats输入,以便为不同的数据源公开独立的端点。
- 弹性
Logstash持久队列提供跨节点故障的保护。对于Logstash中的磁盘级弹性,确保磁盘冗余非常重要。对于内部部署,建议您配置RAID。在云或容器化环境中运行时,建议您使用具有反映数据SLA的复制策略的永久磁盘。
- 可过滤
对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段。
缺点
- Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
3、Kibana 展示
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
4、Filebeat 日志数据采集
filebeat是Beats中的一员,Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件。
目前Beats包含六种工具:
- Packetbeat:网络数据(收集网络流量数据)
- Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
- Filebeat:日志文件(收集文件数据)
- Winlogbeat:windows事件日志(收集Windows事件日志数据)
- Auditbeat:审计数据(收集审计日志)
- Heartbeat:运行时间监控(收集系统运行时的数据)
工作的流程图如下:
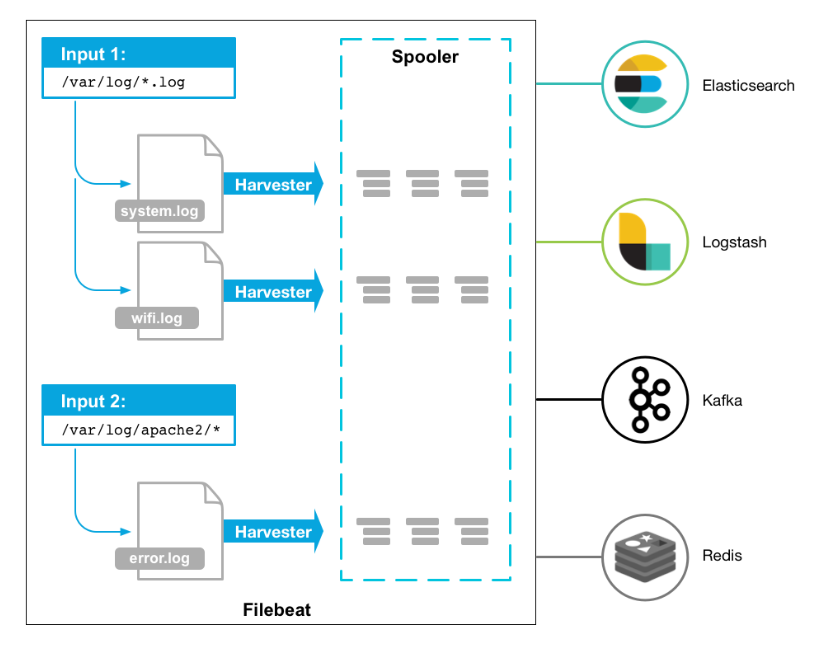
优点
- Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少。
缺点
- Filebeat 的应用范围十分有限,因此在某些场景下咱们会碰到问题。在 5.x 版本中,它还具有过滤的能力。
filebeat和logstash的关系
因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。不过作者只是一个人,加入http://elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。
5、Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它能帮助我们削峰。ELK也可以使用redis作为消息队列,但redis作为消息队列不是强项而且redis集群不如专业的消息发布系统kafka。
二、架构介绍
1、详细流程图
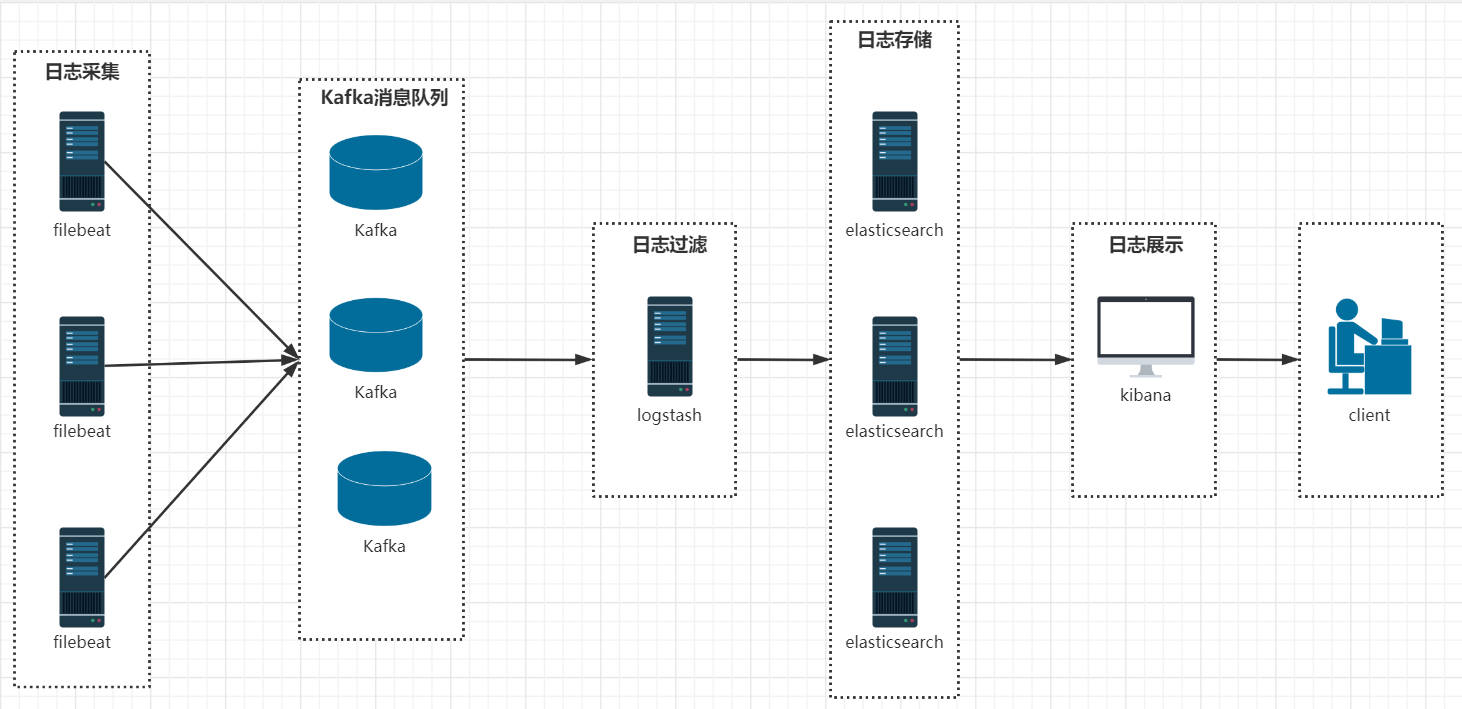
2、最简单的 ELK 架构
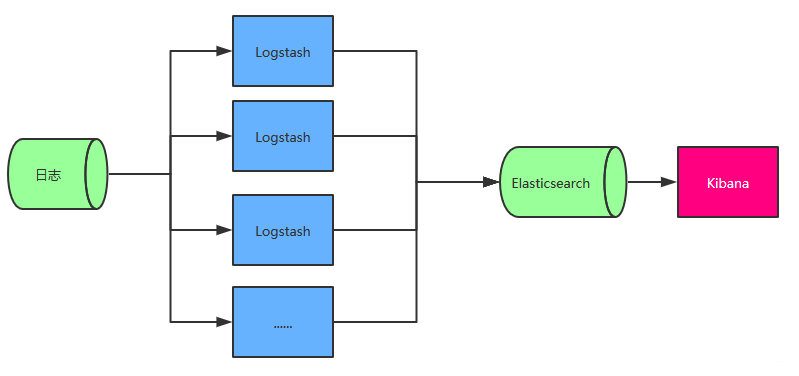
- Logstash 多个的原因是考虑到程序是分布式架构的情况,每台机器都需要部署一个 Logstash,如果确实是单服务器的情况部署一个 Logstash 即可。
- 此架构的优点是搭建简单,易于上手。缺点是Logstash消耗系统资源比较大,运行时占用CPU和内存资源较高。另外,由于没有消息队列缓存,可能存在数据丢失的风险,适合于数据量小的环境使用。
3、引入 Kafka 的典型 ELK 架构
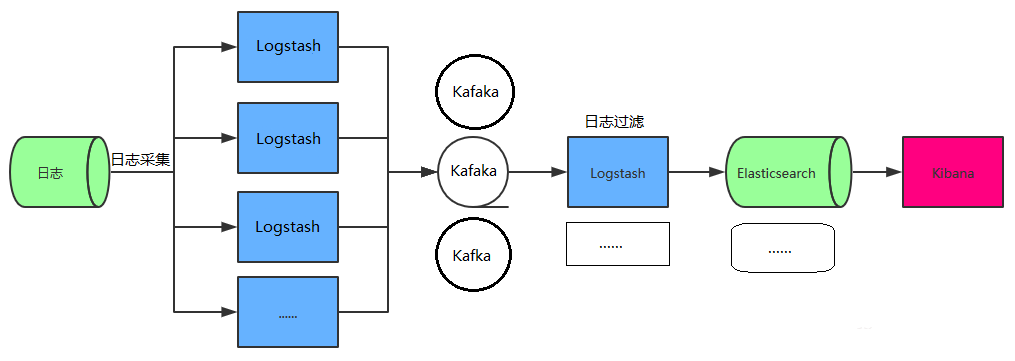
- 为保证日志传输数据的可靠性和稳定性,引入Kafka作为消息缓冲队列,位于各个节点上的Logstash Agent(一级Logstash,主要用来传输数据)先将数据传递给消息队列,接着,Logstash server(二级Logstash,主要用来拉取消息队列数据,过滤并分析数据)将格式化的数据传递给Elasticsearch进行存储。最后,由Kibana将日志和数据呈现给用户。由于引入了Kafka缓冲机制,即使远端Logstash server因故障停止运行,数据也不会丢失,可靠性得到了大大的提升。
- 该架构优点在于引入了消息队列机制,提升日志数据的可靠性,但依然存在Logstash占用系统资源过多的问题,在海量数据应用场景下,可能会出现性能瓶颈。
4、FileBeats + Kafka + ELK 集群架构

- 日志采集器Logstash其功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会消耗过多的系统资源,这将严重影响业务系统的性能,而filebeat就是一个完美的替代者,它基于Go语言没有任何依赖,配置文件简单,格式明了,同时filebeat比logstash更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上。这就是推荐使用filebeat,也是 ELK Stack 在 Agent 的第一选择。
- 此架构适合大型集群、海量数据的业务场景,它通过将前端Logstash Agent替换成filebeat,有效降低了收集日志对业务系统资源的消耗。同时,消息队列使用kafka集群架构,有效保障了收集数据的安全性和稳定性,而后端Logstash和Elasticsearch均采用集群模式搭建,从整体上提高了ELK系统的高效性、扩展性和吞吐量。我所在的项目组采用的就是这套架构,由于生产所需的配置较高,且涉及较多持久化操作,采用的都是性能高配的云主机搭建方式而非时下流行的容器搭建。
三、Kubernetes 部署Elasticsearch集群
1、部署基础架构
| IP | 角色 | 主机名 | pod |
|---|---|---|---|
| 192.168.1.3 | master | master1 | es-master,es-data,es-client,zookeeper,kafka,filebeat |
| 192.168.1.4 | master | master2 | es-master,es-data,es-client,zookeeper,kafka,filebeat |
| 192.168.1.5 | master | master3 | es-master,es-data,es-client,zookeeper,kafka,filebeat |
| 192.168.1.6 | node | node1 | es-data,filebeat |
| 192.168.1.7 | node | node2 | es-data,kibana,filebeat,logstash |
2、创建StorageClass和Namespace
1、创建NFS-StorageClass
[root@k8s-master ~]# mkdir -p /elk/{master,data,client,kibana,zookeeper,kafka}
[root@k8s-master ~]# mkdir elk && cd elk
[root@k8s-master elk]# cat <<EOF>>04-nfs-StorageClass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
namespace: dev
provisioner: provisioner-nfs-storage #这里的名称要和provisioner配置文件中的环境变量PROVISIONER_NAME保持一致
parameters:
archiveOnDelete: "false"
EOF
2、创建名称空间ns-elk
[root@k8s-master elk]# cat<<EOF>>00-ns.yaml
apiVersion: v1
kind: Namespace
metadata:
name: ns-elk
labels:
app: elasticsearch
EOF
3、创建elasticsearch集群证书
参考:https://github.com/elastic/helm-charts/blob/master/elasticsearch/examples/security/Makefile#L24-L35
[root@k8s-master elk]# docker run --name es-certutil -i -w /tmp elasticsearch:7.17.20 /bin/sh -c \
"elasticsearch-certutil ca --out /tmp/es-ca.p12 --pass '' && \
elasticsearch-certutil cert --name security-master --dns \
security-master --ca /tmp/es-ca.p12 --pass '' --ca-pass '' --out /tmp/elastic-certificates.p12"
[root@k8s-master elk]# docker cp es-certutil:/tmp/elastic-certificates.p12 ./
生成 ssl 认证要使用的 secret elastic-certificates:
[root@k8s-master elk]# kubectl -n ns-elk create secret generic elastic-certificates --from-file=./elastic-certificates.p12
4、部署ES集群
1、部署master节点
[root@k8s-master elk]# cat<<EOF>>01-es-master.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: ns-elk
name: elasticsearch-master
labels:
app: elasticsearch
role: master
spec:
serviceName: elasticsearch-master
replicas: 3
selector:
matchLabels:
app: elasticsearch
role: master
template:
metadata:
labels:
app: elasticsearch
role: master
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.17.20
command: ["bash", "-c", "ulimit -l unlimited && sysctl -w vm.max_map_count=262144 && chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/data && exec su elasticsearch docker-entrypoint.sh"]
ports:
- containerPort: 9200
name: http
- containerPort: 9300
name: transport
env:
#- name: discovery.seed_hosts
# value: "elasticsearch-master-0.elasticsearch-master,elasticsearch-master-1.elasticsearch-master,elasticsearch-master-2.elasticsearch-master"
- name: discovery.seed_hosts
value: "elasticsearch-master-0.elasticsearch-master,elasticsearch-master-1.elasticsearch-master,elasticsearch-master-2.elasticsearch-master,elasticsearch-data-0.elasticsearch-data,elasticsearch-data-1.elasticsearch-data,elasticsearch-data-2.elasticsearch-data,elasticsearch-data-3.elasticsearch-data,elasticsearch-data-4.elasticsearch-data,elasticsearch-client-0.elasticsearch-client,elasticsearch-client-1.elasticsearch-client,elasticsearch-client-2.elasticsearch-client"
- name: cluster.initial_master_nodes
value: "elasticsearch-master-0,elasticsearch-master-1,elasticsearch-master-2"
- name: ES_JAVA_OPTS
value: -Xms512m -Xmx512m
- name: node.master
value: "true"
- name: node.ingest
value: "false"
- name: node.data
value: "false"
- name: cluster.name
value: "elasticsearch"
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: xpack.security.enabled
value: "true"
- name: xpack.security.transport.ssl.enabled
value: "true"
- name: xpack.monitoring.collection.enabled
value: "true"
- name: xpack.security.transport.ssl.verification_mode
value: "certificate"
- name: xpack.security.transport.ssl.keystore.path
value: "/usr/share/elasticsearch/config/elastic-certificates.p12"
- name: xpack.security.transport.ssl.truststore.path
value: "/usr/share/elasticsearch/config/elastic-certificates.p12"
volumeMounts:
- mountPath: /usr/share/elasticsearch/data
name: pv-storage-elastic-master
- name: elastic-certificates
readOnly: true
mountPath: "/usr/share/elasticsearch/config/elastic-certificates.p12"
subPath: elastic-certificates.p12
- mountPath: /etc/localtime
name: localtime
securityContext:
privileged: true
volumes:
- name: elastic-certificates
secret:
secretName: elastic-certificates
- hostPath:
path: /etc/localtime
name: localtime
volumeClaimTemplates:
- metadata:
name: pv-storage-elastic-master
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 1Gi
EOF
2、部署Data节点
[root@k8s-master elk]# cat<<EOF>>02-es-data.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: ns-elk
name: elasticsearch-data
labels:
app: elasticsearch
role: data
spec:
serviceName: elasticsearch-data
replicas: 5
selector:
matchLabels:
app: elasticsearch
role: data
template:
metadata:
labels:
app: elasticsearch
role: data
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.17.20
command: ["bash", "-c", "ulimit -l unlimited && sysctl -w vm.max_map_count=262144 && chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/data && exec su elasticsearch docker-entrypoint.sh"]
ports:
- containerPort: 9200
name: http
- containerPort: 9300
name: transport
env:
#- name: discovery.seed_hosts
# value: "elasticsearch-data-0.elasticsearch-data,elasticsearch-data-1.elasticsearch-data,elasticsearch-data-2.elasticsearch-data,elasticsearch-data-3.elasticsearch-data,elasticsearch-data-4.elasticsearch-data"
- name: discovery.seed_hosts
value: "elasticsearch-master-0.elasticsearch-master,elasticsearch-master-1.elasticsearch-master,elasticsearch-master-2.elasticsearch-master,elasticsearch-data-0.elasticsearch-data,elasticsearch-data-1.elasticsearch-data,elasticsearch-data-2.elasticsearch-data,elasticsearch-data-3.elasticsearch-data,elasticsearch-data-4.elasticsearch-data,elasticsearch-client-0.elasticsearch-client,elasticsearch-client-1.elasticsearch-client,elasticsearch-client-2.elasticsearch-client"
- name: cluster.initial_master_nodes
value: "elasticsearch-master-0,elasticsearch-master-1,elasticsearch-master-2"
- name: ES_JAVA_OPTS
value: -Xms512m -Xmx512m
- name: node.master
value: "false"
- name: node.ingest
value: "false"
- name: node.data
value: "true"
- name: cluster.name
value: "elasticsearch"
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: xpack.security.enabled
value: "true"
- name: xpack.security.transport.ssl.enabled
value: "true"
- name: xpack.monitoring.collection.enabled
value: "true"
- name: xpack.security.transport.ssl.verification_mode
value: "certificate"
- name: xpack.security.transport.ssl.keystore.path
value: "/usr/share/elasticsearch/config/elastic-certificates.p12"
- name: xpack.security.transport.ssl.truststore.path
value: "/usr/share/elasticsearch/config/elastic-certificates.p12"
volumeMounts:
- mountPath: /usr/share/elasticsearch/data
name: pv-storage-elastic-data
- name: elastic-certificates
readOnly: true
mountPath: "/usr/share/elasticsearch/config/elastic-certificates.p12"
subPath: elastic-certificates.p12
- mountPath: /etc/localtime
name: localtime
securityContext:
privileged: true
volumes:
- name: elastic-certificates
secret:
secretName: elastic-certificates
- hostPath:
path: /etc/localtime
name: localtime
volumeClaimTemplates:
- metadata:
name: pv-storage-elastic-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 2Gi
EOF
3、部署Client节点
[root@k8s-master elk]# cat <<EOF>>elasticsearch-client.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: ns-elk
name: elasticsearch-client
labels:
app: elasticsearch
role: client
spec:
serviceName: elasticsearch-client
replicas: 3
selector:
matchLabels:
app: elasticsearch
role: client
template:
metadata:
labels:
app: elasticsearch
role: client
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.17.20
command: ["bash", "-c", "ulimit -l unlimited && sysctl -w vm.max_map_count=262144 && chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/data && exec su elasticsearch docker-entrypoint.sh"]
ports:
- containerPort: 9200
name: http
- containerPort: 9300
name: transport
env:
#- name: discovery.seed_hosts
# value: "elasticsearch-client-0.elasticsearch-client,elasticsearch-client-1.elasticsearch-client,elasticsearch-client-2.elasticsearch-client"
- name: discovery.seed_hosts
value: "elasticsearch-master-0.elasticsearch-master,elasticsearch-master-1.elasticsearch-master,elasticsearch-master-2.elasticsearch-master,elasticsearch-data-0.elasticsearch-data,elasticsearch-data-1.elasticsearch-data,elasticsearch-data-2.elasticsearch-data,elasticsearch-data-3.elasticsearch-data,elasticsearch-data-4.elasticsearch-data,elasticsearch-client-0.elasticsearch-client,elasticsearch-client-1.elasticsearch-client,elasticsearch-client-2.elasticsearch-client"
- name: cluster.initial_master_nodes
value: "elasticsearch-master-0,elasticsearch-master-1,elasticsearch-master-2"
- name: ES_JAVA_OPTS
value: -Xms512m -Xmx512m
- name: node.master
value: "false"
- name: node.ingest
value: "true"
- name: node.data
value: "false"
- name: cluster.name
value: "elasticsearch"
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: xpack.security.enabled
value: "true"
- name: xpack.security.transport.ssl.enabled
value: "true"
- name: xpack.monitoring.collection.enabled
value: "true"
- name: xpack.security.transport.ssl.verification_mode
value: "certificate"
- name: xpack.security.transport.ssl.keystore.path
value: "/usr/share/elasticsearch/config/elastic-certificates.p12"
- name: xpack.security.transport.ssl.truststore.path
value: "/usr/share/elasticsearch/config/elastic-certificates.p12"
volumeMounts:
- mountPath: /usr/share/elasticsearch/data
name: pv-storage-elastic-client
- name: elastic-certificates
readOnly: true
mountPath: "/usr/share/elasticsearch/config/elastic-certificates.p12"
subPath: elastic-certificates.p12
- mountPath: /etc/localtime
name: localtime
securityContext:
privileged: true
volumes:
- name: elastic-certificates
secret:
secretName: elastic-certificates
- hostPath:
path: /etc/localtime
name: localtime
volumeClaimTemplates:
- metadata:
name: pv-storage-elastic-client
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 1Gi
EOF
4、创建ES集群的Service
[root@k8s-master elk]# cat <<EOF>>04-es-service.yaml
apiVersion: v1
kind: Service
metadata:
namespace: ns-elk
name: elasticsearch-master
labels:
app: elasticsearch
role: master
spec:
selector:
app: elasticsearch
role: master
type: NodePort
ports:
- port: 9200
nodePort: 30001
targetPort: 9200
---
apiVersion: v1
kind: Service
metadata:
namespace: ns-elk
name: elasticsearch-data
labels:
app: elasticsearch
role: data
spec:
selector:
app: elasticsearch
role: data
type: NodePort
ports:
- port: 9200
nodePort: 30002
targetPort: 9200
---
apiVersion: v1
kind: Service
metadata:
namespace: ns-elk
name: elasticsearch-client
labels:
app: elasticsearch
role: client
spec:
selector:
app: elasticsearch
role: client
type: NodePort
ports:
- port: 9200
nodePort: 30003
targetPort: 9200
EOF
5、设置ES集群密码
[root@k8s-master elk]# kubectl -n ns-elk exec -it $(kubectl -n ns-elk get pods | grep elasticsearch-master | sed -n 1p | awk '{print $1}') -- bin/elasticsearch-setup-passwords auto -b
[root@master01 ns-elk]# kubectl exec -it -n ns-elk elasticsearch-master-0 -- /bin/sh
sh-5.0# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 16:32 ? 00:00:00 su elasticsearch docker-entrypoint.sh
elastic+ 9 1 33 16:32 ? 00:01:15 /usr/share/elasticsearch/jdk/bin/java -Xshare:auto -Des.net
elastic+ 216 9 0 16:33 ? 00:00:00 /usr/share/elasticsearch/modules/x-pack-ml/platform/linux-x
root 427 0 0 16:36 pts/0 00:00:00 /bin/sh
root 437 427 0 16:36 pts/0 00:00:00 ps -ef
sh-5.0# cd /usr/share/elasticsearch/
sh-5.0# ls
LICENSE.txt NOTICE.txt README.asciidoc bin config data jdk lib logs modules plugins
sh-5.0# cd bin/
sh-5.0# ls
elasticsearch elasticsearch-keystore elasticsearch-sql-cli
elasticsearch-certgen elasticsearch-migrate elasticsearch-sql-cli-7.17.20.jar
elasticsearch-certutil elasticsearch-node elasticsearch-syskeygen
elasticsearch-cli elasticsearch-plugin elasticsearch-users
elasticsearch-croneval elasticsearch-saml-metadata x-pack-env
elasticsearch-env elasticsearch-service-tokens x-pack-security-env
elasticsearch-env-from-file elasticsearch-setup-passwords x-pack-watcher-env
elasticsearch-geoip elasticsearch-shard
sh-5.0# elasticsearch-setup-passwords auto -b
Changed password for user apm_system
PASSWORD apm_system = mdxoGjVA76RDvX5d5DCC
Changed password for user kibana_system
PASSWORD kibana_system = VQKC8RLuziSVagRNv7cg
Changed password for user kibana
PASSWORD kibana = VQKC8RLuziSVagRNv7cg
Changed password for user logstash_system
PASSWORD logstash_system = EH1xXzbkD5g3ZhyqZUjP
Changed password for user beats_system
PASSWORD beats_system = UJzPnlmujU2eas0nJeC3
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = dvCwt1HNHfyCiVjtLr7s
Changed password for user elastic
PASSWORD elastic = lGTiRY1ZcChmlNpr5AFX
牢记上面的密码!!! elastic 的密码 lGTiRY1ZcChmlNpr5AFX 登录 kibana 要用这个用户和密码
四、Kubernetes部署Kibana
1、创建 kibana 连接 elasticsearch 的secret
- 使用elasticsearch生成的用户kibana的密码 VQKC8RLuziSVagRNv7cg(kibana 连接elasticsearch要用这个用户和密码)
[root@k8s-master elk]# kubectl -n ns-elk create secret generic elasticsearch-password --from-literal password=VQKC8RLuziSVagRNv7cg
2、部署kibana
[root@k8s-master elk]# cat <<EOF>>05-kibana.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: ns-elk
name: kibana-config
labels:
app: kibana
data:
kibana.yml: |-
server.host: 0.0.0.0
elasticsearch:
hosts: \${ELASTICSEARCH_HOSTS}
username: \${ELASTICSEARCH_USER}
password: \${ELASTICSEARCH_PASSWORD}
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: kibana
name: kibana
namespace: ns-elk
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
# nodeSelector:
# node: node2
containers:
- name: kibana
image: kibana:7.17.20
ports:
- containerPort: 5601
protocol: TCP
env:
- name: SERVER_PUBLICBASEURL
value: "http://0.0.0.0:5601"
- name: I18N.LOCALE
value: zh-CN
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch-client:9200"
- name: ELASTICSEARCH_USER
value: "kibana"
- name: ELASTICSEARCH_PASSWORD
valueFrom:
secretKeyRef:
name: elasticsearch-password
key: password
- name: xpack.encryptedSavedObjects.encryptionKey
value: "min-32-byte-long-strong-encryption-key"
volumeMounts:
- name: kibana-config
mountPath: /usr/share/kibana/config/kibana.yml
readOnly: true
subPath: kibana.yml
- mountPath: /etc/localtime
name: localtime
volumes:
- name: kibana-config
configMap:
name: kibana-config
- hostPath:
path: /etc/localtime
name: localtime
---
kind: Service
apiVersion: v1
metadata:
labels:
app: kibana
name: kibana-service
namespace: ns-elk
spec:
ports:
- port: 5601
targetPort: 5601
nodePort: 30004
type: NodePort
selector:
app: kibana
EOF
五、Kubernetes部署Kafka集群
1、Kafka 集群组件介绍
1、Kafka 简介
- Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,由 Scala 和 Java 编写。
- Kafka 是一个分布式、支持分区的的、多副本,基于 zookeeper 协调的分布式消息系统。它
- Kafka 最大特性是可以实时的处理大量数据以满足各种需求场景,比如基于 Hadoop 的批处理系统、低延时的实时系统、storm/Spark 流式处理引擎,web/nginx 日志,访问日志,消息服务等等。
2、Zookeeper 简介
- ZooKeeper 是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。
- ZooKeeper 通过其简单的架构和 API 解决了这个问题。
- ZooKeeper 允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
- Kafka 中主要利用 zookeeper 解决分布式一致性问题。
- Kafka 使用 Zookeeper 的分布式协调服务将生产者,消费者,消息储存结合在一起。同时借助 Zookeeper,Kafka 能够将生产者、消费者和 Broker 在内的所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现生产者的负载均衡。
3、Kafka Manager 简介
Kafka Manager 是目前最受欢迎的 Kafka 集群管理工具,最早由雅虎开源,用户可以在 Web 界面执行一些简单的集群管理操作。
支持以下功能:
- 管理 Kafka 集群
- 方便集群状态监控 (包括topics, consumers, offsets, brokers, replica distribution, partition distribution)
- 方便选择分区副本
- 配置分区任务,包括选择使用哪些 Brokers
- 可以对分区任务重分配
- 提供不同的选项来创建及删除 Topic
- Topic List 会指明哪些topic被删除
- 批量产生分区任务并且和多个topic和brokers关联
- 批量运行多个主题对应的多个分区
- 向已经存在的主题中添加分区
- 对已经存在的 Topic 修改配置
- 可以在 Broker Level 和 Topic Level 的度量中启用 JMX Polling 功能
- 可以过滤在 ZooKeeper 上没有 ids/owners/offsets/directories 的 consumer
此环境不建议线上使用!!!
kafka-manager 项目地址:https://github.com/yahoo/kafka-manager
2、Kafka 集群部署
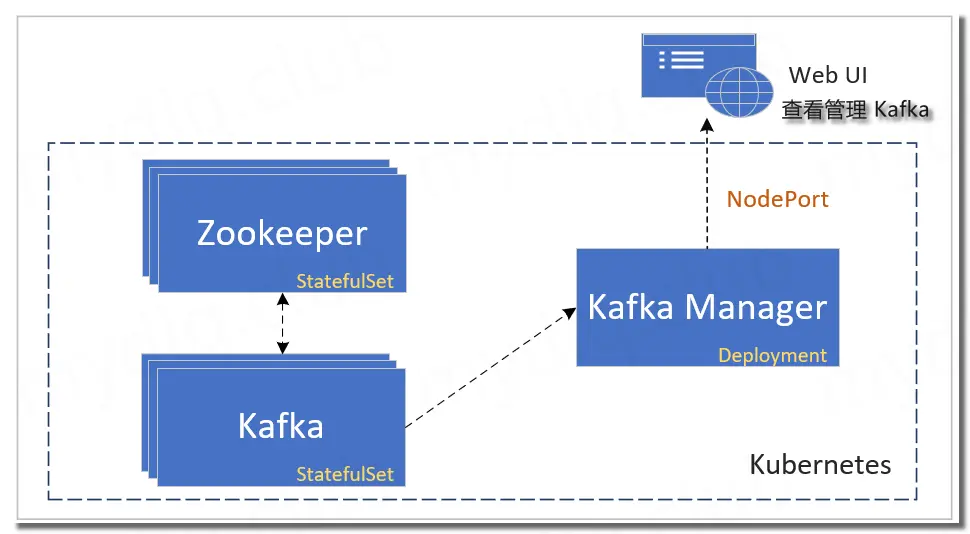
这个流程需要部署三个组件,分别为 Zookeeper、Kafka、Kafka Manager:
- Zookeeper: 首先部署 Zookeeper,方便后续部署 Kafka 节点注册到 Zookeeper,用 StatefulSet 方式部署三个节点。
- Kafka: 其次部署的是 Kafka,设置环境变量来指定 Zookeeper 地址,用 StatefulSet 方式部署。
- (Kafka Manager: 最后部署的是 Kafka Manager,用 Deployment 方式部署,然后打开 Web UI 界面来管理、监控 Kafka。
1、部署zookeeper集群
[root@k8s-master elk]# cat <<EOF>>06-zk.yaml
apiVersion: v1
kind: Service
metadata:
name: zookeeper
namespace: ns-elk
labels:
app: zookeeper
spec:
type: NodePort
ports:
- port: 2181
nodePort: 30005
targetPort: 2181
selector:
app: zookeeper
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zookeeper-pdb
namespace: ns-elk
spec:
selector:
matchLabels:
app: zookeeper
minAvailable: 2
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zookeeper
namespace: ns-elk
spec:
selector:
matchLabels:
app: zookeeper
serviceName: zookeeper
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: Parallel
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: zookeeper
spec:
containers:
- name: kubernetes-zookeeper
imagePullPolicy: IfNotPresent
image: "mirrorgooglecontainers/kubernetes-zookeeper:1.0-3.4.10"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: zookeeper
mountPath: /var/lib/zookeeper
securityContext:
runAsUser: 1000
fsGroup: 1000
volumeClaimTemplates:
- metadata:
name: zookeeper
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 1Gi
EOF
2、部署kafka集群
[root@k8s-master elk]# cat 07-kafka.yaml
apiVersion: v1
kind: Service
metadata:
name: kafka
namespace: ns-elk
labels:
app: kafka
spec:
type: NodePort
ports:
- port: 9092
nodePort: 30009
targetPort: 9092
selector:
app: kafka
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: kafka-pdb
namespace: ns-elk
spec:
selector:
matchLabels:
app: kafka
maxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
namespace: ns-elk
spec:
selector:
matchLabels:
app: kafka
serviceName: kafka
replicas: 3
template:
metadata:
labels:
app: kafka
spec:
terminationGracePeriodSeconds: 300
containers:
- name: k8s-kafka
imagePullPolicy: IfNotPresent
image: fastop/kafka:2.2.0
resources:
requests:
memory: "600Mi"
cpu: 500m
ports:
- containerPort: 9092
name: server
command:
- sh
- -c
- "exec kafka-server-start.sh /opt/kafka/config/server.properties --override broker.id=${HOSTNAME##*-} \
--override listeners=PLAINTEXT://:9092 \
--override zookeeper.connect=zookeeper.ns-elk.svc.cluster.local:2181 \
--override log.dir=/var/lib/kafka \
--override auto.create.topics.enable=true \
--override auto.leader.rebalance.enable=true \
--override background.threads=10 \
--override compression.type=producer \
--override delete.topic.enable=false \
--override leader.imbalance.check.interval.seconds=300 \
--override leader.imbalance.per.broker.percentage=10 \
--override log.flush.interval.messages=9223372036854775807 \
--override log.flush.offset.checkpoint.interval.ms=60000 \
--override log.flush.scheduler.interval.ms=9223372036854775807 \
--override log.retention.bytes=-1 \
--override log.retention.hours=168 \
--override log.roll.hours=168 \
--override log.roll.jitter.hours=0 \
--override log.segment.bytes=1073741824 \
--override log.segment.delete.delay.ms=60000 \
--override message.max.bytes=1000012 \
--override min.insync.replicas=1 \
--override num.io.threads=8 \
--override num.network.threads=3 \
--override num.recovery.threads.per.data.dir=1 \
--override num.replica.fetchers=1 \
--override offset.metadata.max.bytes=4096 \
--override offsets.commit.required.acks=-1 \
--override offsets.commit.timeout.ms=5000 \
--override offsets.load.buffer.size=5242880 \
--override offsets.retention.check.interval.ms=600000 \
--override offsets.retention.minutes=1440 \
--override offsets.topic.compression.codec=0 \
--override offsets.topic.num.partitions=50 \
--override offsets.topic.replication.factor=3 \
--override offsets.topic.segment.bytes=104857600 \
--override queued.max.requests=500 \
--override quota.consumer.default=9223372036854775807 \
--override quota.producer.default=9223372036854775807 \
--override replica.fetch.min.bytes=1 \
--override replica.fetch.wait.max.ms=500 \
--override replica.high.watermark.checkpoint.interval.ms=5000 \
--override replica.lag.time.max.ms=10000 \
--override replica.socket.receive.buffer.bytes=65536 \
--override replica.socket.timeout.ms=30000 \
--override request.timeout.ms=30000 \
--override socket.receive.buffer.bytes=102400 \
--override socket.request.max.bytes=104857600 \
--override socket.send.buffer.bytes=102400 \
--override unclean.leader.election.enable=true \
--override zookeeper.session.timeout.ms=6000 \
--override zookeeper.set.acl=false \
--override broker.id.generation.enable=true \
--override connections.max.idle.ms=600000 \
--override controlled.shutdown.enable=true \
--override controlled.shutdown.max.retries=3 \
--override controlled.shutdown.retry.backoff.ms=5000 \
--override controller.socket.timeout.ms=30000 \
--override default.replication.factor=1 \
--override fetch.purgatory.purge.interval.requests=1000 \
--override group.max.session.timeout.ms=300000 \
--override group.min.session.timeout.ms=6000 \
--override inter.broker.protocol.version=2.2.0 \
--override log.cleaner.backoff.ms=15000 \
--override log.cleaner.dedupe.buffer.size=134217728 \
--override log.cleaner.delete.retention.ms=86400000 \
--override log.cleaner.enable=true \
--override log.cleaner.io.buffer.load.factor=0.9 \
--override log.cleaner.io.buffer.size=524288 \
--override log.cleaner.io.max.bytes.per.second=1.7976931348623157E308 \
--override log.cleaner.min.cleanable.ratio=0.5 \
--override log.cleaner.min.compaction.lag.ms=0 \
--override log.cleaner.threads=1 \
--override log.cleanup.policy=delete \
--override log.index.interval.bytes=4096 \
--override log.index.size.max.bytes=10485760 \
--override log.message.timestamp.difference.max.ms=9223372036854775807 \
--override log.message.timestamp.type=CreateTime \
--override log.preallocate=false \
--override log.retention.check.interval.ms=300000 \
--override max.connections.per.ip=2147483647 \
--override num.partitions=4 \
--override producer.purgatory.purge.interval.requests=1000 \
--override replica.fetch.backoff.ms=1000 \
--override replica.fetch.max.bytes=1048576 \
--override replica.fetch.response.max.bytes=10485760 \
--override reserved.broker.max.id=1000 "
env:
- name: KAFKA_HEAP_OPTS
value : "-Xmx512M -Xms512M"
- name: KAFKA_OPTS
value: "-Dlogging.level=INFO"
volumeMounts:
- name: kafka
mountPath: /var/lib/kafka
readinessProbe:
tcpSocket:
port: 9092
timeoutSeconds: 1
initialDelaySeconds: 5
securityContext:
runAsUser: 1000
fsGroup: 1000
volumeClaimTemplates:
- metadata:
name: kafka
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 1Gi
3、测试验证zookeeper,kafka集群
1、通过zookeeper查看broker
[root@k8s-master elk]# kubectl exec -it zookeeper-1 -n ns-elk -- /bin/bash
zookeeper@zookeeper-1:/$ zkCli.sh
Connecting to localhost:2181
.....
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://kafka-0.kafka.ns-elk.svc.cluster.local:9093"],"jmx_port":-1,"host":"kafka-0.kafka.ns-elk.svc.cluster.local","timestamp":"1641887271398","port":9093,"version":4}
cZxid = 0x200000024
ctime = Tue Jan 11 07:47:51 UTC 2022
mZxid = 0x200000024
mtime = Tue Jan 11 07:47:51 UTC 2022
pZxid = 0x200000024
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x27e480b276e0001
dataLength = 246
numChildren = 0
[zk: localhost:2181(CONNECTED) 1] get /brokers/ids/1
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://kafka-1.kafka.ns-elk.svc.cluster.local:9093"],"jmx_port":-1,"host":"kafka-1.kafka.ns-elk.svc.cluster.local","timestamp":"1641887242316","port":9093,"version":4}
cZxid = 0x20000001e
ctime = Tue Jan 11 07:47:22 UTC 2022
mZxid = 0x20000001e
mtime = Tue Jan 11 07:47:22 UTC 2022
pZxid = 0x20000001e
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x27e480b276e0000
dataLength = 246
numChildren = 0
[zk: localhost:2181(CONNECTED) 2] get /brokers/ids/2
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://kafka-2.kafka.ns-elk.svc.cluster.local:9093"],"jmx_port":-1,"host":"kafka-2.kafka.ns-elk.svc.cluster.local","timestamp":"1641888604437","port":9093,"version":4}
cZxid = 0x20000002d
ctime = Tue Jan 11 08:10:04 UTC 2022
mZxid = 0x20000002d
mtime = Tue Jan 11 08:10:04 UTC 2022
pZxid = 0x20000002d
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x27e480b276e0002
dataLength = 246
numChildren = 0
2、kafka生产消费测试
1、创建topic
[root@k8s-master elk]# kubectl exec -it kafka-0 -n ns-elk -- /bin/sh
$ pwd
/
$ cd /opt/kafka/bin
$ ./kafka-topics.sh --create --topic test --zookeeper zookeeper.ns-elk.svc.cluster.local:2181 --partitions 3 --replication-factor 3
Created topic "test".
$ ./kafka-topics.sh --list --zookeeper zookeeper.ns-elk.svc.cluster.local:2181
test
2、生产者生产消息
$ ./kafka-console-producer.sh --topic test --broker-list kafka-0.kafka.ns-elk.svc.cluster.local:9092
111
./kafka-console-producer.sh --topic filebeat --broker-list kafka-0.kafka.ns-elk.svc.cluster.local:9092
3、消费者消费消息
- 另起一个终端消费消息
[root@k8s-master elk]# kubectl exec -it kafka-1 -n ns-elk -- /bin/sh
$ pwd
/
$ cd /opt/kafka/bin
$ ./kafka-console-consumer.sh --topic test --bootstrap-server kafka-0.kafka.ns-elk.svc.cluster.local:9092 --from-beginning
111
./kafka-console-consumer.sh --topic filebeat --bootstrap-server kafka-0.kafka.ns-elk.svc.cluster.local:9092 --from-beginning
- 消费正常的,kafka集群部署成功
4、Kubernetes 部署 Kafka Manager
1、创建 Kafka Manager 部署文件
[root@k8s-master01 elk]# cat <<EOF>>kafka-manager.yaml
apiVersion: v1
kind: Service
metadata:
name: kafka-manager
namespace: ns-elk
labels:
app: kafka-manager
spec:
type: NodePort
ports:
- name: kafka
port: 9000
targetPort: 9000
nodePort: 30900
selector:
app: kafka-manager
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-manager
namespace: ns-elk
labels:
app: kafka-manager
spec:
replicas: 1
selector:
matchLabels:
app: kafka-manager
template:
metadata:
labels:
app: kafka-manager
spec:
containers:
- name: kafka-manager
# image: zenko/kafka-manager:1.3.3.22
image: zenko/kafka-manager:2.0.0.2
imagePullPolicy: IfNotPresent
ports:
- name: kafka-manager
containerPort: 9000
protocol: TCP
env:
- name: ZK_HOSTS
value: "zookeeper:2181"
livenessProbe:
httpGet:
path: /api/health
port: kafka-manager
readinessProbe:
httpGet:
path: /api/health
port: kafka-manager
EOF
2、部署 Kafka Manager
kubectl apply -f kafka-manager.yaml
3、进入 Kafka Manager 管理 Kafka 集群
-
Kubernetes 集群地址为:192.168.0.197,并且在上面设置 Kafka-Manager 网络策略为 NodePort 方式,且设置端口为 30900,
-
输入地址:http://192.168.0.197:30900 访问 Kafka Manager。
-
进入后先配置 Kafka Manager,增加一个 Zookeeper 地址。
-
配置三个必填参数:
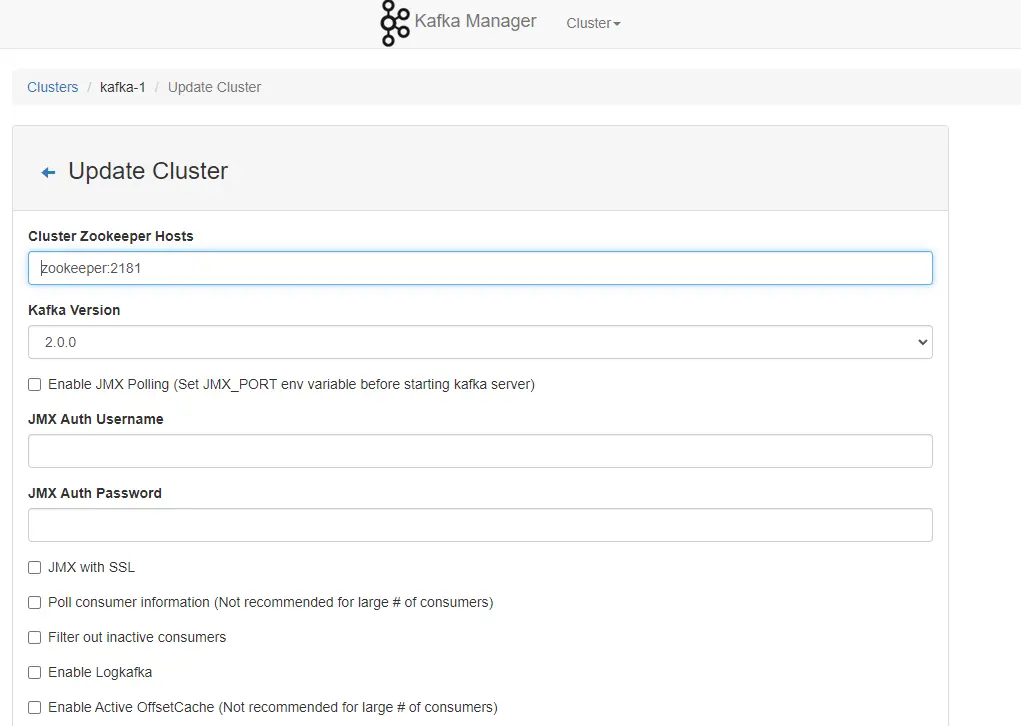
-
Cluster Name:自定义一个名称,任意输入即可。
-
Zookeeper Hosts:输入 Zookeeper 地址,这里设置为 Zookeeper 服务名+端口。
-
Kafka Version:选择 kafka 版本。
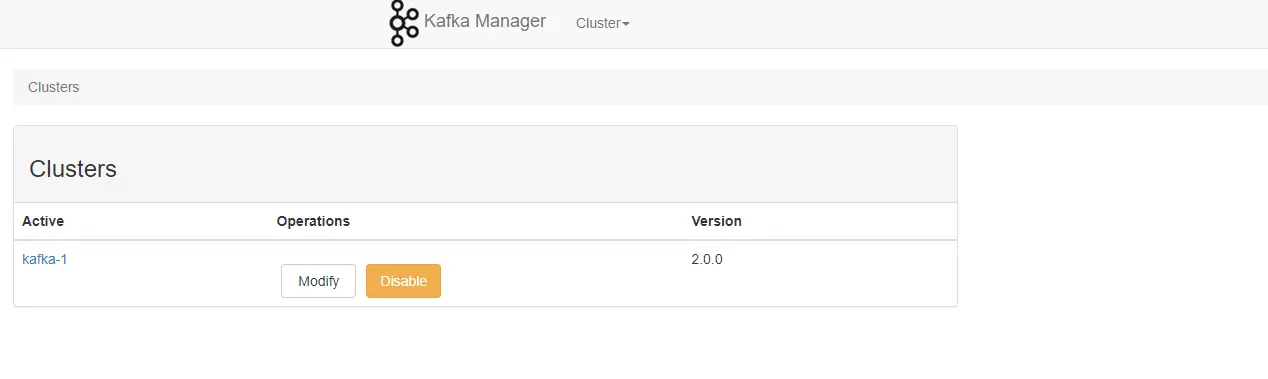
- Kafka Manager 部署成功,用于管理kafka
六、Kubernetes 部署 filebeat
- filebeat使用DemoSet,并且是自动发现日志模式
[root@k8s-master elk]# cat 08-filebeat.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: ns-elk
labels:
k8s-app: filebeat
data:
filebeat.yml: |
filebeat.inputs:
# - type: container
- type: log
paths:
- '/var/lib/docker/containers/*.log'
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/lib/docker/containers/"
processors:
- add_cloud_metadata:
- add_host_metadata:
output:
kafka:
enabled: true
hosts: ["kafka-0.kafka.ns-elk.svc.cluster.local:9092","kafka-1.kafka.ns-elk.svc.cluster.local:9092","kafka-2.kafka.ns-elk.svc.cluster.local:9092"]
topic: "filebeat"
max_message_bytes: 5242880
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: ns-elk
labels:
k8s-app: filebeat
spec:
selector:
matchLabels:
k8s-app: filebeat
template:
metadata:
labels:
k8s-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:7.17.20
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
resources:
limits:
memory: 500Mi
requests:
cpu: 300m
memory: 300Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
# readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/log/nginx
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: ns-elk
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat
namespace: ns-elk
subjects:
- kind: ServiceAccount
name: filebeat
namespace: ns-elk
roleRef:
kind: Role
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat-kubeadm-config
namespace: ns-elk
subjects:
- kind: ServiceAccount
name: filebeat
namespace: ns-elk
roleRef:
kind: Role
name: filebeat-kubeadm-config
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
- apiGroups: ["apps"]
resources:
- replicasets
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat
namespace: ns-elk
labels:
k8s-app: filebeat
rules:
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs: ["get", "create", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat-kubeadm-config
namespace: ns-elk
labels:
k8s-app: filebeat
rules:
- apiGroups: [""]
resources:
- configmaps
resourceNames:
- kubeadm-config
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: ns-elk
labels:
k8s-app: filebeat
七、Kubernetes 部署 Logstash
[root@k8s-master elk]# cat 09-logstash.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-configmap
namespace: ns-elk
data:
logstash.yml: |
http.host: "0.0.0.0"
path.config: /usr/share/logstash/pipeline
logstash.conf: |
input {
kafka {
bootstrap_servers => "kafka-0.kafka.ns-elk.svc.cluster.local:9092,kafka-1.kafka.ns-elk.svc.cluster.local:9092,kafka-2.kafka.ns-elk.svc.cluster.local:9092"
topics => ["filebeat"]
codec => "json"
}
}
filter {
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
hosts => ["elasticsearch-client:9200"]
user => "elastic"
password => "lGTiRY1ZcChmlNpr5AFX" # 注意这里的密码
index => "kubernetes-%{+YYYY.MM.dd}"
}
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash-deployment
namespace: ns-elk
spec:
selector:
matchLabels:
app: logstash
replicas: 1
template:
metadata:
labels:
app: logstash
spec:
# nodeSelector:
# node: node2
containers:
- name: logstash
image: docker.elastic.co/logstash/logstash:7.17.20
ports:
- containerPort: 5044
volumeMounts:
- name: config-volume
mountPath: /usr/share/logstash/config
- name: logstash-pipeline-volume
mountPath: /usr/share/logstash/pipeline
- mountPath: /etc/localtime
name: localtime
volumes:
- name: config-volume
configMap:
name: logstash-configmap
items:
- key: logstash.yml
path: logstash.yml
- name: logstash-pipeline-volume
configMap:
name: logstash-configmap
items:
- key: logstash.conf
path: logstash.conf
- hostPath:
path: /etc/localtime
name: localtime
---
kind: Service
apiVersion: v1
metadata:
name: logstash-service
namespace: ns-elk
spec:
selector:
app: logstash
type: NodePort
ports:
- protocol: TCP
port: 5044
targetPort: 5044
nodePort: 30007
- 所有组件创建完成后,可以使用kubectl logs -f po-name -n ns-elk来查看应用的日志,检查应用是否正常运行。
- 创建完成的资源清单:
[root@k8s-master elk]# kubectl get all -n ns-elk
NAME READY STATUS RESTARTS AGE
pod/cerebro-5f87f6d9b6-9f5c8 1/1 Running 0 10h
pod/elasticsearch-client-0 1/1 Running 0 14h
pod/elasticsearch-client-1 1/1 Running 0 13h
pod/elasticsearch-client-2 1/1 Running 0 49m
pod/elasticsearch-data-0 1/1 Running 0 62m
pod/elasticsearch-data-1 1/1 Running 0 62m
pod/elasticsearch-data-2 1/1 Running 0 10h
pod/elasticsearch-data-3 1/1 Running 0 11h
pod/elasticsearch-data-4 1/1 Running 0 50m
pod/elasticsearch-master-0 1/1 Running 0 13h
pod/elasticsearch-master-1 1/1 Running 0 14h
pod/elasticsearch-master-2 1/1 Running 0 19h
pod/filebeat-5h7kb 1/1 Running 0 13h
pod/filebeat-s9rg5 1/1 Running 0 13h
pod/kafka-0 1/1 Running 0 17h
pod/kafka-1 1/1 Running 0 17h
pod/kafka-2 1/1 Running 0 17h
pod/kafka-manager-656fffdb64-xh45v 1/1 Running 0 12h
pod/kibana-5bf5c59c95-dvd5r 1/1 Running 6 (18h ago) 18h
pod/logstash-deployment-5b5968f4bf-2k6hp 1/1 Running 0 13h
pod/nginx-web-4fb26 1/1 Running 0 16h
pod/nginx-web-fkkvb 1/1 Running 0 16h
pod/zookeeper-0 1/1 Running 1 (13h ago) 18h
pod/zookeeper-1 1/1 Running 1 (13h ago) 18h
pod/zookeeper-2 1/1 Running 2 (11h ago) 18h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/cerebro LoadBalancer 10.106.86.218 192.168.96.102 80:31887/TCP 10h
service/elasticsearch-client NodePort 10.103.13.70 <none> 9200:30003/TCP 19h
service/elasticsearch-data NodePort 10.104.240.76 <none> 9200:30002/TCP 19h
service/elasticsearch-master NodePort 10.109.219.148 <none> 9200:30010/TCP 19h
service/kafka NodePort 10.100.160.56 <none> 9092:30006/TCP 18h
service/kafka-manager NodePort 10.105.131.68 <none> 9000:30900/TCP 12h
service/kibana-service NodePort 10.104.192.64 <none> 5601:30004/TCP 18h
service/logstash-service NodePort 10.106.149.78 <none> 5044:30007/TCP 13h
service/nginx-web NodePort 10.102.236.53 <none> 80:30008/TCP 16h
service/zookeeper NodePort 10.100.37.255 <none> 2181:30005/TCP 18h
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/filebeat 2 2 2 2 2 <none> 13h
daemonset.apps/nginx-web 2 2 2 2 2 <none> 16h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/cerebro 1/1 1 1 10h
deployment.apps/kafka-manager 1/1 1 1 12h
deployment.apps/kibana 1/1 1 1 18h
deployment.apps/logstash-deployment 1/1 1 1 13h
NAME DESIRED CURRENT READY AGE
replicaset.apps/cerebro-57cbbf8865 0 0 0 10h
replicaset.apps/cerebro-5f87f6d9b6 1 1 1 10h
replicaset.apps/cerebro-6d88d86dfb 0 0 0 10h
replicaset.apps/cerebro-6df855d767 0 0 0 10h
replicaset.apps/kafka-manager-656fffdb64 1 1 1 12h
replicaset.apps/kibana-5bf4d7cc56 0 0 0 18h
replicaset.apps/kibana-5bf5c59c95 1 1 1 18h
replicaset.apps/kibana-6495b45b45 0 0 0 18h
replicaset.apps/logstash-deployment-5b5968f4bf 1 1 1 13h
replicaset.apps/logstash-deployment-8648844fd5 0 0 0 13h
NAME READY AGE
statefulset.apps/elasticsearch-client 3/3 19h
statefulset.apps/elasticsearch-data 5/5 19h
statefulset.apps/elasticsearch-master 3/3 19h
statefulset.apps/kafka 3/3 18h
statefulset.apps/zookeeper 3/3 18h
八、创建 Deployment 验证日志采集
1、创建 Deployment
[root@k8s-master hpa]# cat <<EOF>> nginx-web.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-web
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: nginx-logs
mountPath: /var/log/nginx
volumes:
- name: nginx-logs
hostPath:
path: /var/log/nginx
---
apiVersion: v1
kind: Service
metadata:
name: nginx-hpa-svc
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30008
selector:
app: nginx
EOF
2、做压力测试模拟产生日志
[root@master01 ~]# kubectl get svc -n ns-elk | grep nginx-web
nginx-web NodePort 10.102.236.53 <none> 80:30008/TCP 16h
[root@master01 ~]# ab -c 10 -n 100000 http://10.102.236.53/index.html # 不要压的太猛,会把es集群打夸
3、kibana 查看日志采集状态
所有的资源正常运行打开kibana页面,检查索引是否创建:
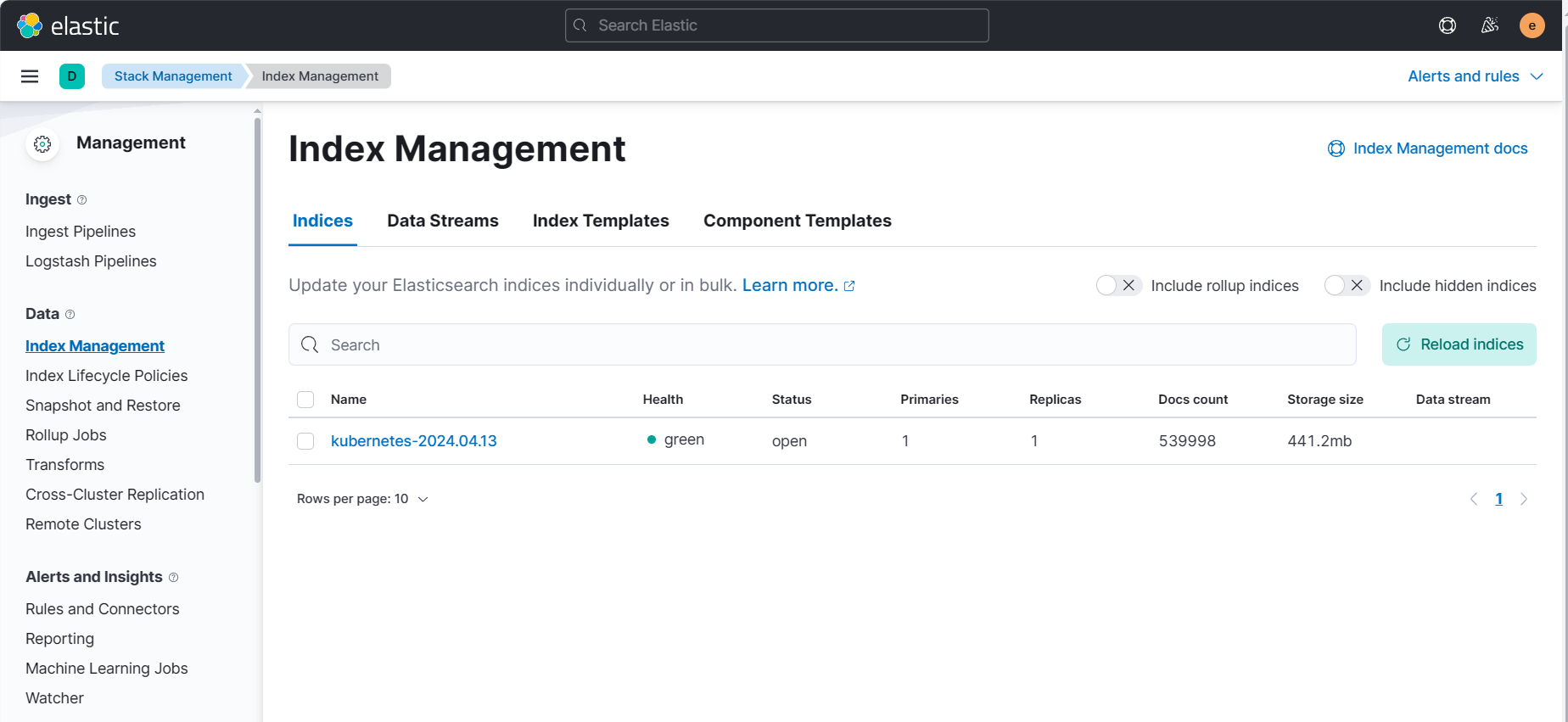
- 创建索引模式,看一下数据:
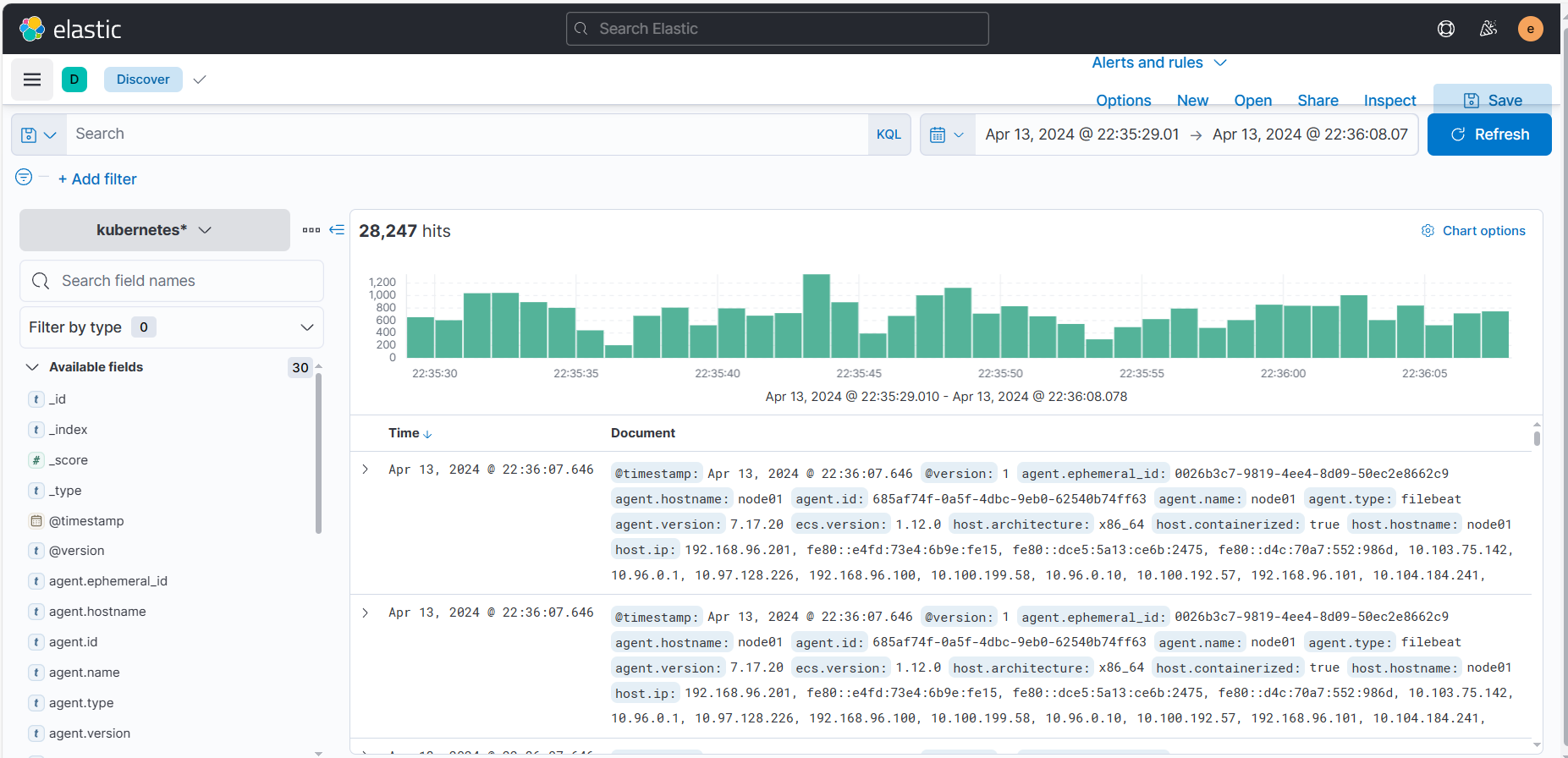
日志数据有了,整个集群基本搭建完成!
九、Elasticsearch 可视化集群工具 Cerebro
1、概述
Cerebro(又称Elasticsearch Cerebro)是一个用于可视化和管理 Elasticsearch 集群的开源工具。它提供了一个直观的用户界面,让您能够轻松地监控、管理和诊断您的Elasticsearch集群。以下是一些Cerebro的主要特点和如何使用它:
主要特点:
- 集群总览:
Cerebro提供了一个集群总览页面,显示有关您的Elasticsearch集群的基本信息,包括节点数量、分片数量、索引数量等。 - 节点和索引管理: 您可以通过
Cerebro轻松管理集群的节点和索引。您可以查看节点的详细信息,关闭或打开索引,执行索引操作,查看分片分配等。 - 搜索和查询:
Cerebro允许您执行搜索和查询操作,以便快速检查Elasticsearch索引的数据,而无需编写HTTP请求。 - 诊断工具: 工具栏提供了一些有用的诊断功能,例如查看集群健康、执行Ping操作、查看索引状态和查看慢查询等。
- 可视化: Cerebro提供了图形化的方式来查看分片和副本的分布情况,以及查看索引的可用性和状态。
如何使用 Cerebro:
以下是使用 Cerebro 来监控和管理 Elasticsearch 集群的一般步骤:
- **安装
Cerebro**: 首先,您需要下载和安装Cerebro。您可以从GitHub仓库或官方网站获取最新的Cerebro版本。 - 配置
Cerebro: 在安装Cerebro后,您需要配置它以连接到您的Elasticsearch集群。配置文件通常包含Elasticsearch集群的主机和端口等信息。 - 启动Cerebro: 启动Cerebro应用程序,它将运行在一个Web界面上,通常在本地的8080端口。您可以通过浏览器访问http://localhost:9000来打开Cerebro。
- 连接Elasticsearch: 在Cerebro的界面上,您将找到一个选项,可以配置Elasticsearch集群的连接信息。填写正确的主机和端口信息以连接到您的Elasticsearch集群。
- 开始使用: 一旦连接成功,您可以开始使用Cerebro来监控和管理您的Elasticsearch集群。您可以查看集群总览、节点和索引信息,执行搜索和查询,查看诊断信息等。
请注意,
Cerebro是一个社区维护的工具,因此您需要定期检查其最新版本以确保安全性和功能性。此外,如果您的Elasticsearch集群受到安全性的限制,确保采取必要的安全措施来保护Cerebro的访问。
2、Kubernetes 部署 Cerebro
- GitHub地址:https://github.com/lmenezes/cerebro.git
- cerebro 配置文件信息, Deployment、svc、ingress 信息
apiVersion: v1
kind: ConfigMap
metadata:
name: cerebro-application
namespace: ns-elk
data:
application.conf: |
es = {
gzip = true
}
auth = {
type: basic
settings {
username = "admin"
password = "123456"
}
}
hosts = [
{
host = "http://elasticsearch-client:9200"
name = "elasticsearch"
auth = {
username = "elastic"
password = "qV1ZwwTkFCz1qV38eZyN"
}
}
]
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: cerebro
name: cerebro
namespace: ns-elk
spec:
replicas: 1
selector:
matchLabels:
app: cerebro
template:
metadata:
labels:
app: cerebro
name: cerebro
spec:
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
containers:
- image: lmenezes/cerebro:0.8.4
imagePullPolicy: IfNotPresent
name: cerebro
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 300m
memory: 300Mi
volumeMounts:
- name: cerebro-conf
mountPath: /etc/cerebro
volumes:
- name: cerebro-conf
configMap:
name: cerebro-application
---
apiVersion: v1
kind: Service
metadata:
labels:
app: cerebro
name: cerebro
namespace: ns-elk
spec:
#type: ClusterIP
type: LoadBalancer
ports:
- port: 80
protocol: TCP
targetPort: 9000
selector:
app: cerebro
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: cerebro
namespace: ns-elk
spec:
rules:
- host: cerebro.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: cerebro
port:
number: 80
- 查看部署状态
[root@master01 ns-elk]# kubectl get all -n ns-elk | grep cerebro
pod/cerebro-5f87f6d9b6-9f5c8 1/1 Running 0 11m
service/cerebro LoadBalancer 10.106.86.218 192.168.96.102 80:31887/TCP 23m
deployment.apps/cerebro 1/1 1 1 23m
replicaset.apps/cerebro-5f87f6d9b6 1 1 1 11m
3、配置域名解析
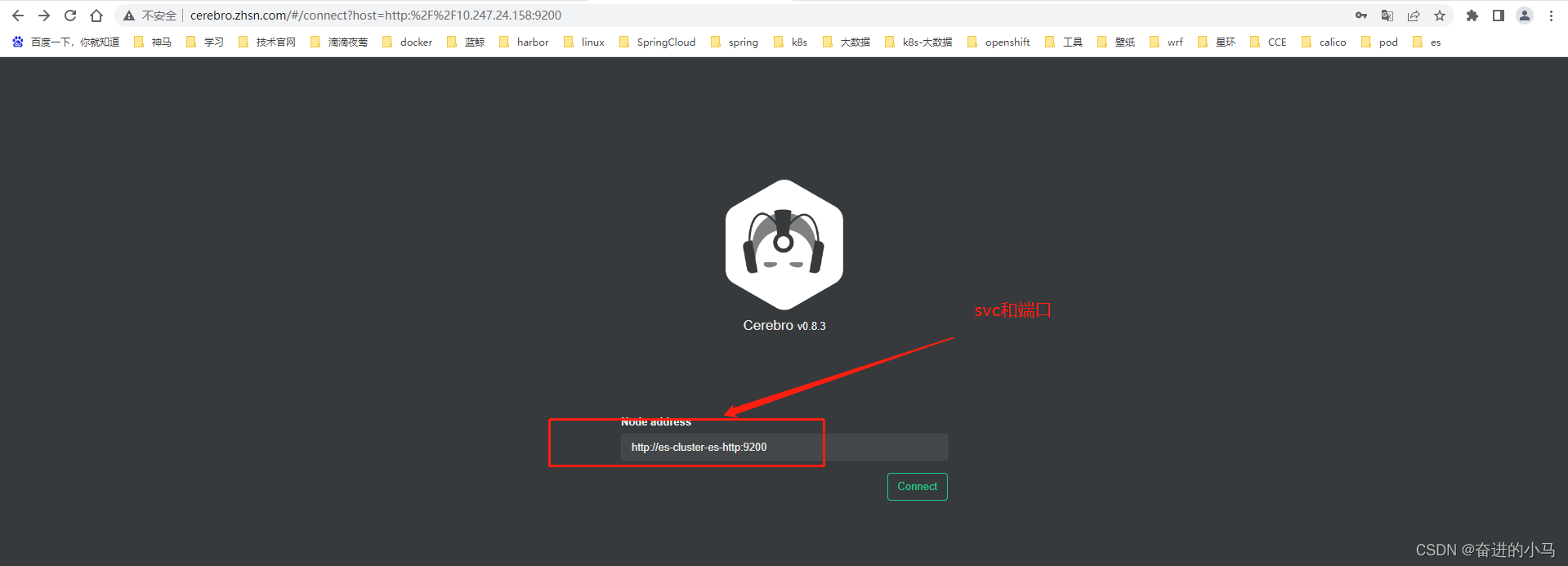
- 解析域名到 k8s 集群的 ingress
192.168.96.102 cerebro.example.com
4、登录查看
3、Cerebro 功能解析
1、总览信息
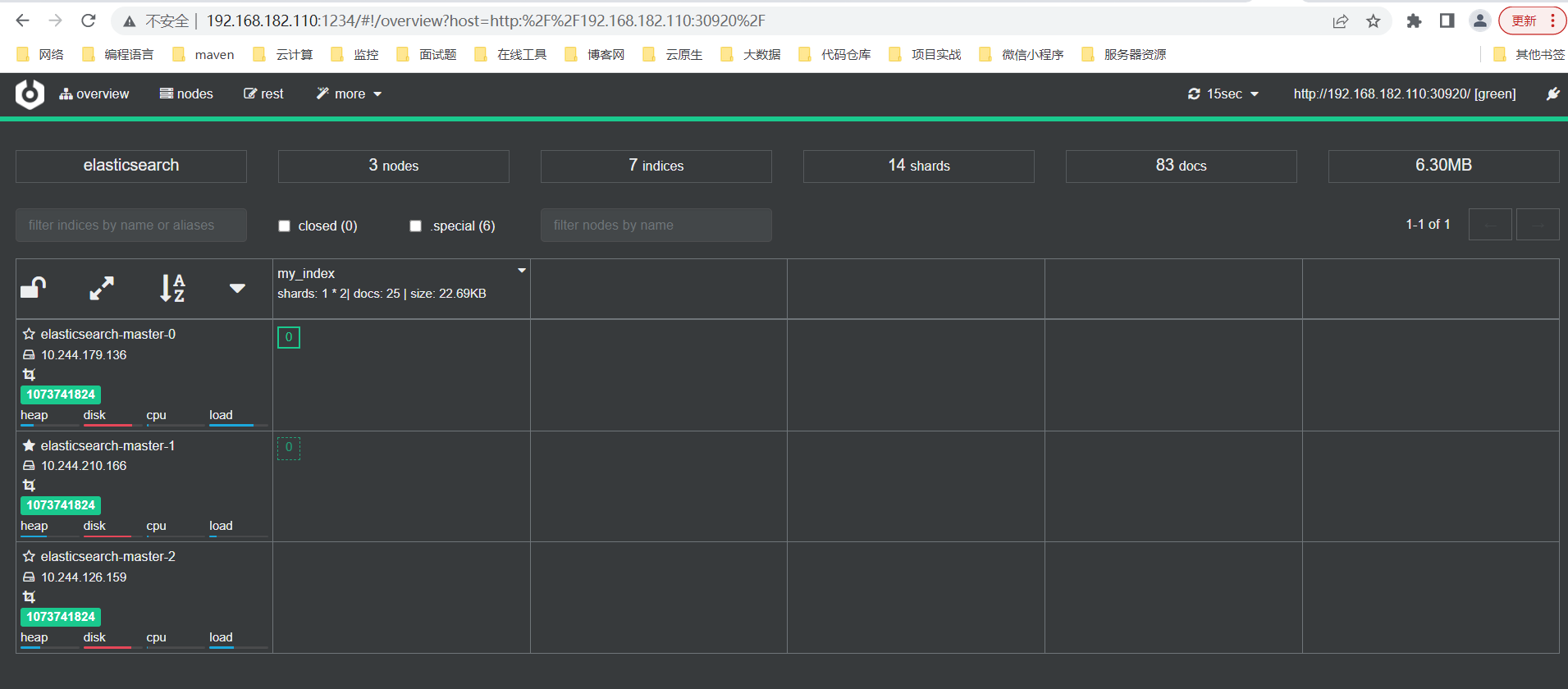
2、节点信息
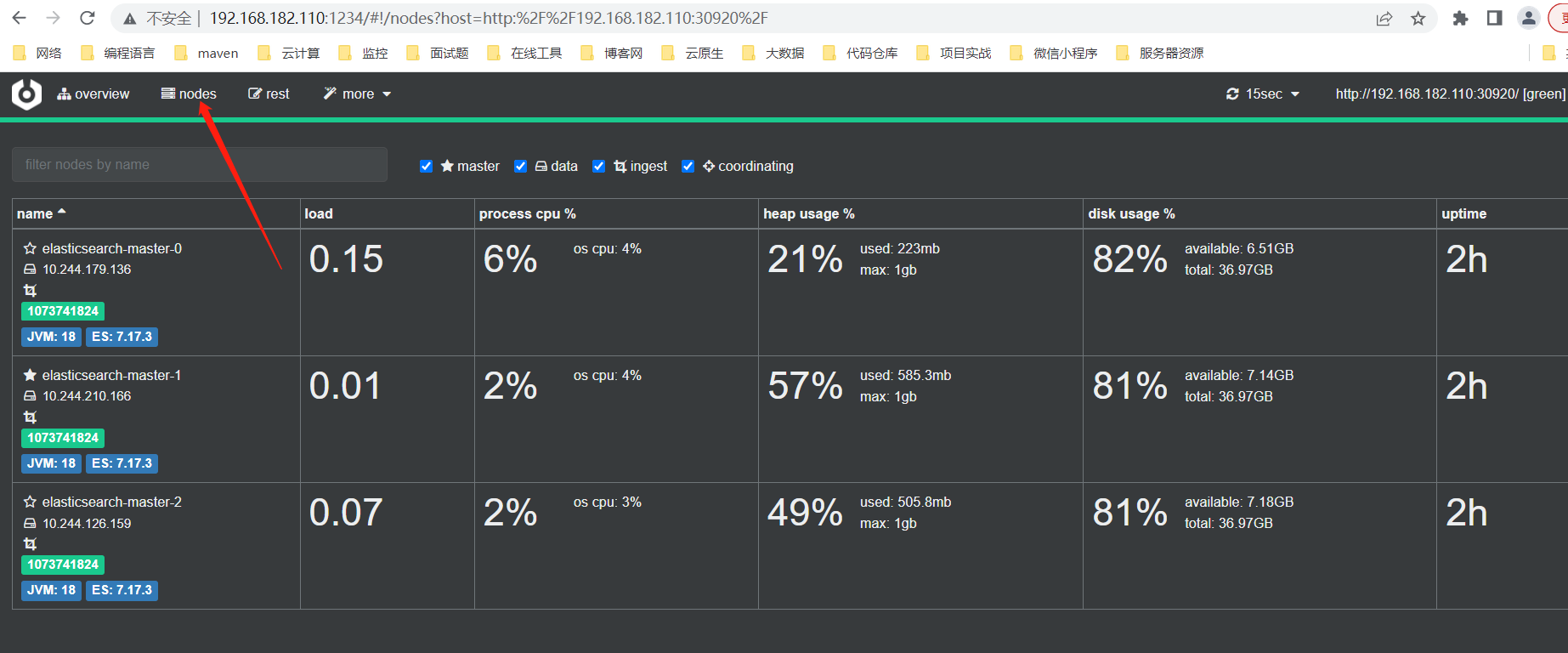
3、rest 接口请求
如下图所示,为 cerebro 的 rest 菜单界面。通过该界面可以直接向es发起 rest 请求,如 _search 请求等。
4、更多功能
-
如: 创建索引、集群设置、snapshot信息等
-
如下图所示,为
cerebro更多功能菜单。该菜单支持索引创建、集群设置、重命名、索引字段分析、es模板查看和修改、仓储查看和创建、快照查看等快捷功能。
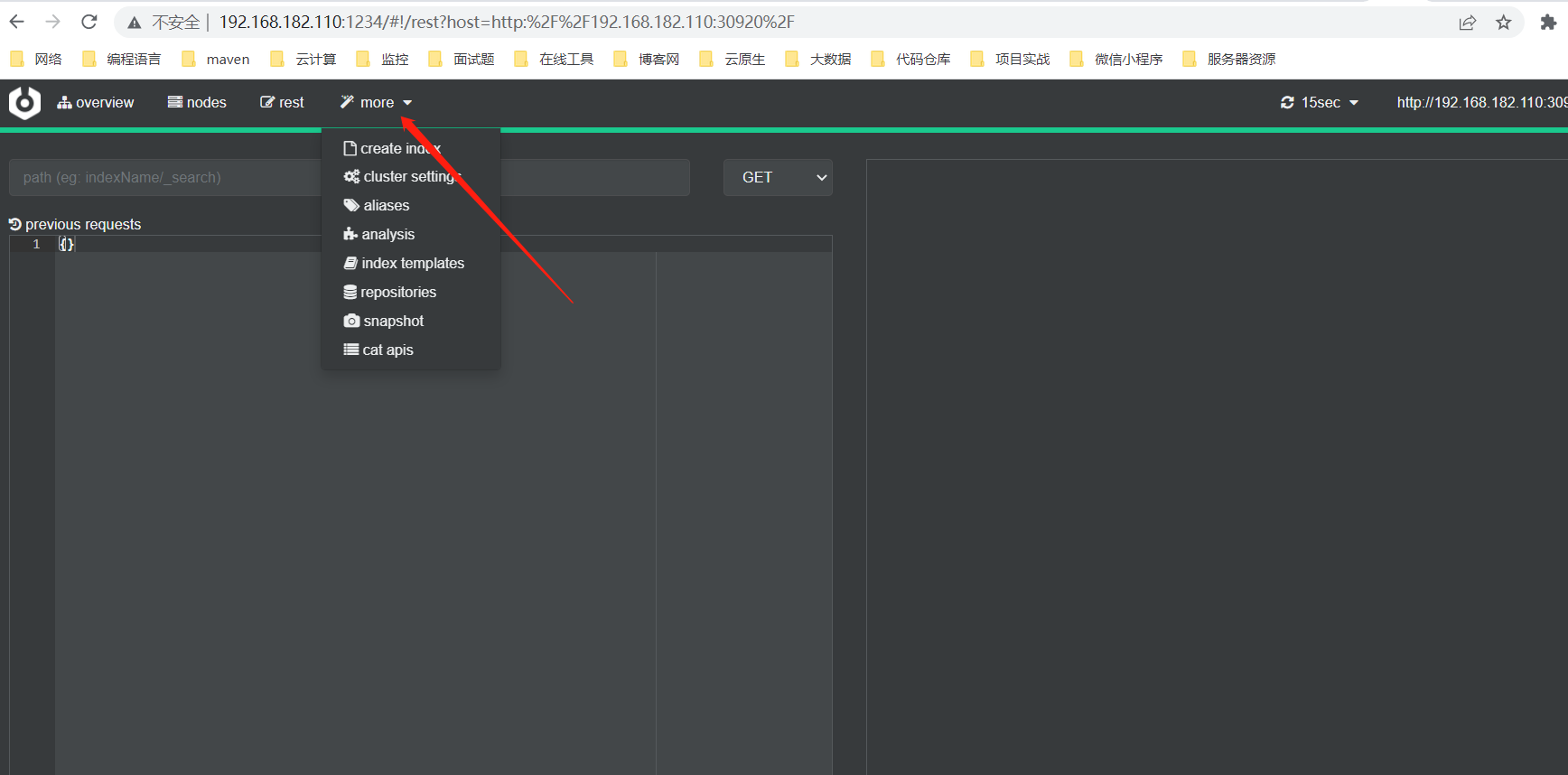
5、分片重新分配
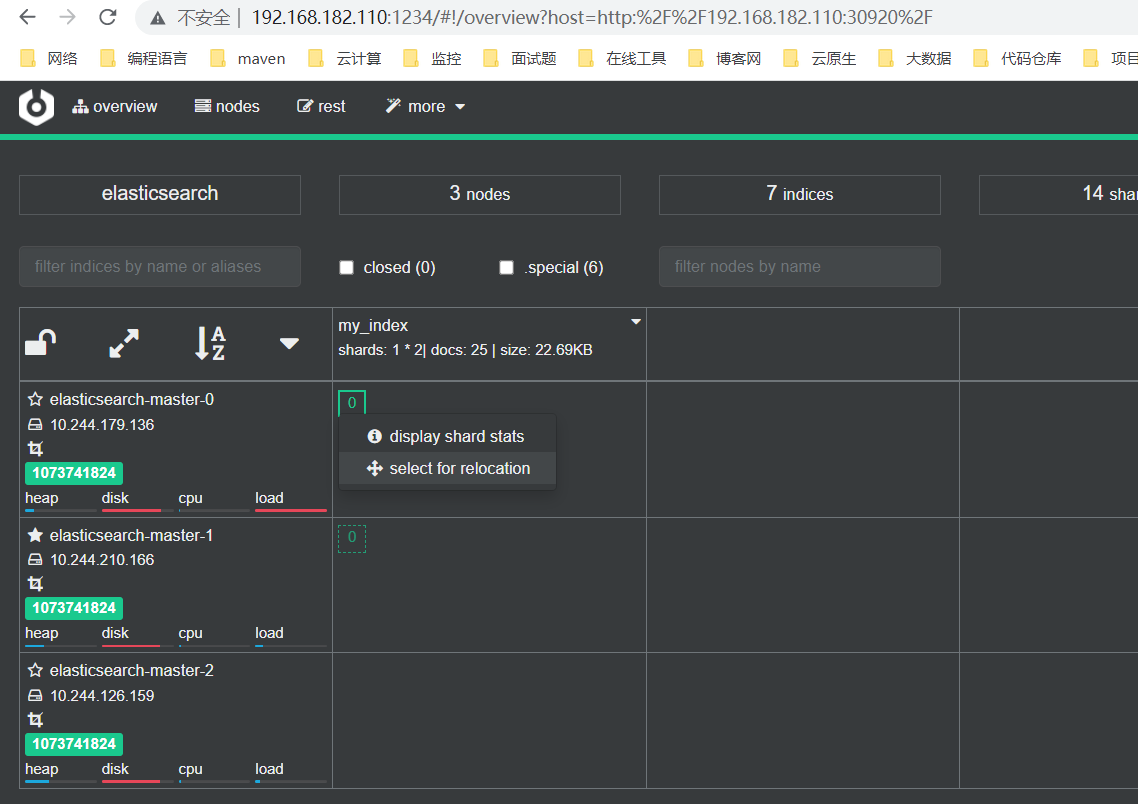
- 如果索引的分片分布不均匀,可以选中某个节点上的分片,重新分配
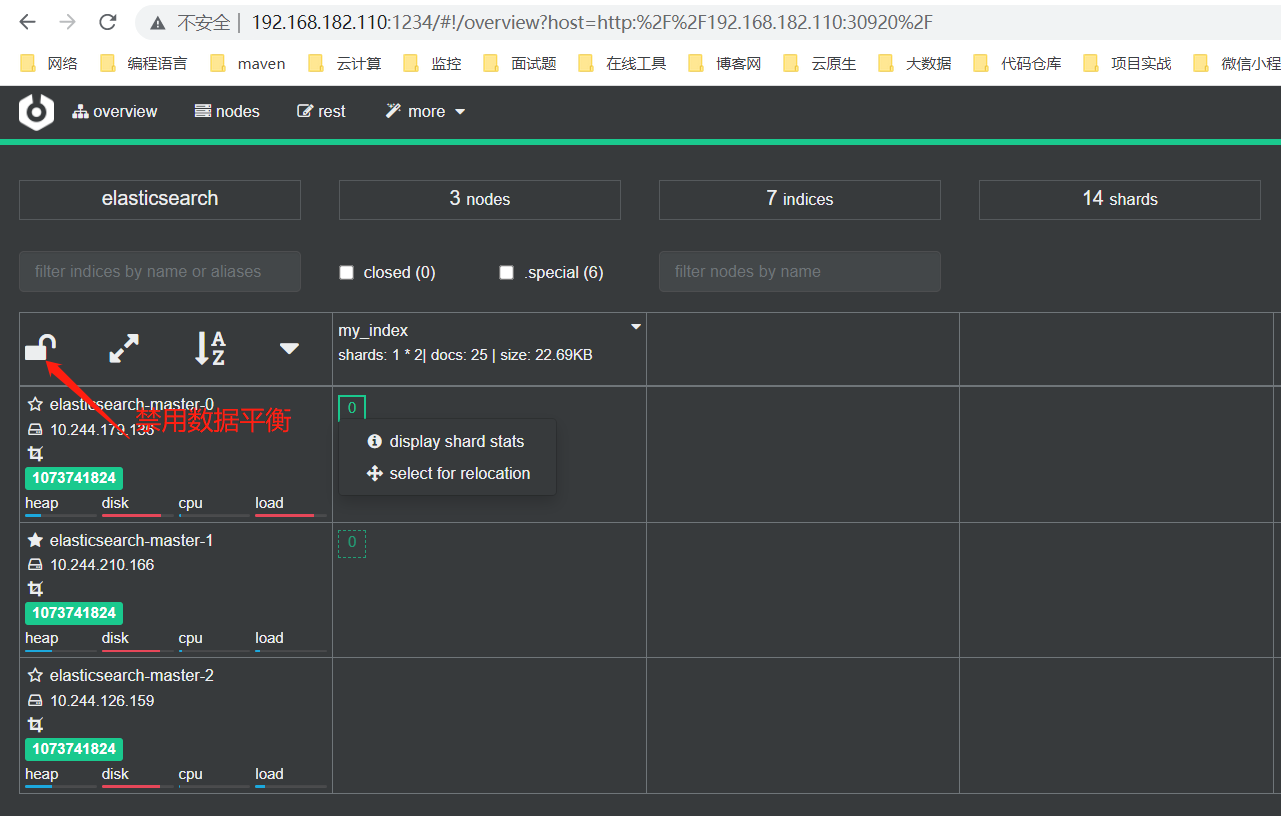
6、禁用数据平衡
4、Cerebro、Elasticsearch-Head和 Elasticsearch-SQL 工具对比
Cerebro、Elasticsearch-Head 和 Elasticsearch-SQL 是三种用于与 Elasticsearch 集群进行交互和管理的工具,但它们各自具有不同的功能和用途。以下是对这三种工具的简要比较:
1、Cerebro
- 用途: Cerebro 主要用于可视化和管理 Elasticsearch 集群。它提供了集群总览、节点管理、索引管理、搜索和查询等功能。
- 特点:
- 直观的用户界面,适用于监控和管理 Elasticsearch 集群。
- 提供了集群总览、索引和节点管理、搜索和查询、诊断工具等功能。
- 可以用于执行基本的 Elasticsearch 操作,如创建索引、执行搜索和查询、查看节点状态等。
- 支持数据可视化和图形化分片分布查看。
- 适用场景: Cerebro 适用于那些需要轻松监控和管理 Elasticsearch 集群的管理员和运维人员。它提供了对集群状态的实时监控以及对索引和节点的基本管理功能。
2、Elasticsearch-Head
- 用途:
Elasticsearch-Head主要用于可视化和管理 Elasticsearch 集群,类似于Cerebro。 - 特点:
- 提供了用于监控和管理
Elasticsearch集群的用户界面。 - 允许查看集群总览、索引和节点管理、执行搜索和查询、查看分片状态等。
- 支持数据可视化和图形化分片分布查看。
- 提供了一些插件和扩展功能,如请求和响应的查看器、RESTful API 调用等。
- 提供了用于监控和管理
- 适用场景:
Elasticsearch-Head适用于那些需要可视化监控Elasticsearch集群的管理员和运维人员。它提供了集群状态的实时查看和基本管理功能。
3、Elasticsearch-SQL
- 用途:
Elasticsearch-SQL是一个用于执行SQL查询的工具,它允许您使用类似于 SQL 的语法查询 Elasticsearch 集群。 - 特点:
- 支持
SQL查询,可以将Elasticsearch视为关系型数据库并执行查询操作。 - 允许执行复杂的查询、聚合和过滤操作。
- 可以在
Elasticsearch中使用标准 SQL 查询数据。 - 适用于那些熟悉 SQL 语法的用户,以便更轻松地与 Elasticsearch 进行交互。
- 支持
- 适用场景:
Elasticsearch-SQL适用于那些熟悉 SQL 查询语言的用户,他们可以使用 SQL 查询 Elasticsearch 集群中的数据,而无需编写复杂的 Elasticsearch 查询DSL。
总结:
Cerebro和Elasticsearch-Head都是用于可视化监控和管理Elasticsearch集群的工具,提供了用户界面、集群总览、节点管理、索引管理等功能。Elasticsearch-SQL是一个用于执行 SQL 查询的工具,允许用户使用 SQL 查询 Elasticsearch 集群中的数据。