前言
本文总结库存领域建设库存预占能力时遇到的问题以及解决方案。感谢【金鹏】、【孙静】、【陈瑞】同学在本文撰写中提供的内容及帮助!
1、库存预占业务概述
消费者拍下商品订单后,库存系统先为该订单预留库存,这个预留库存的动作被称为库存预占。
在系统中,库存预占主要是对库存数据进行扣减操作。例:假如一个商品有5个可用库存,订单购买了1个此商品,库存系统需要把可用库存的数量由5扣减为4
库存预占属于物流核心流程。如果预占能力出问题,可能会导致商品无法正常售卖或者出现超卖。
2、库存预占能力建设面临的挑战及应对
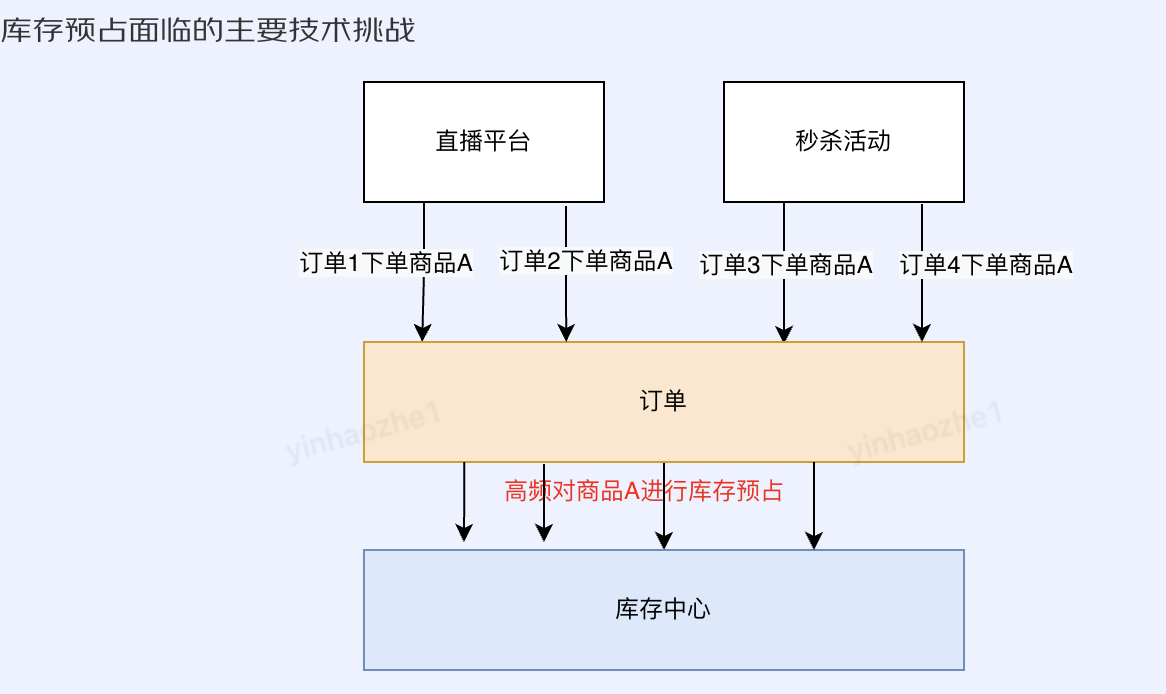
秒杀活动、直播促销等业务场景,往往会出现短时间内多个订单都去预占某一个或几个商品库存的情况。如何处理高并发场景中对热点商品进行库存扣减操作,是库存预占业务要面临的主要技术挑战
2.1 性能挑战
多个线程并发对同一个数据库商品数据做库存扣减时,数据库中会加锁来保障数据被正确操作。当商品数据足够【热】时,大量的锁等待会导致性能问题,见下图:
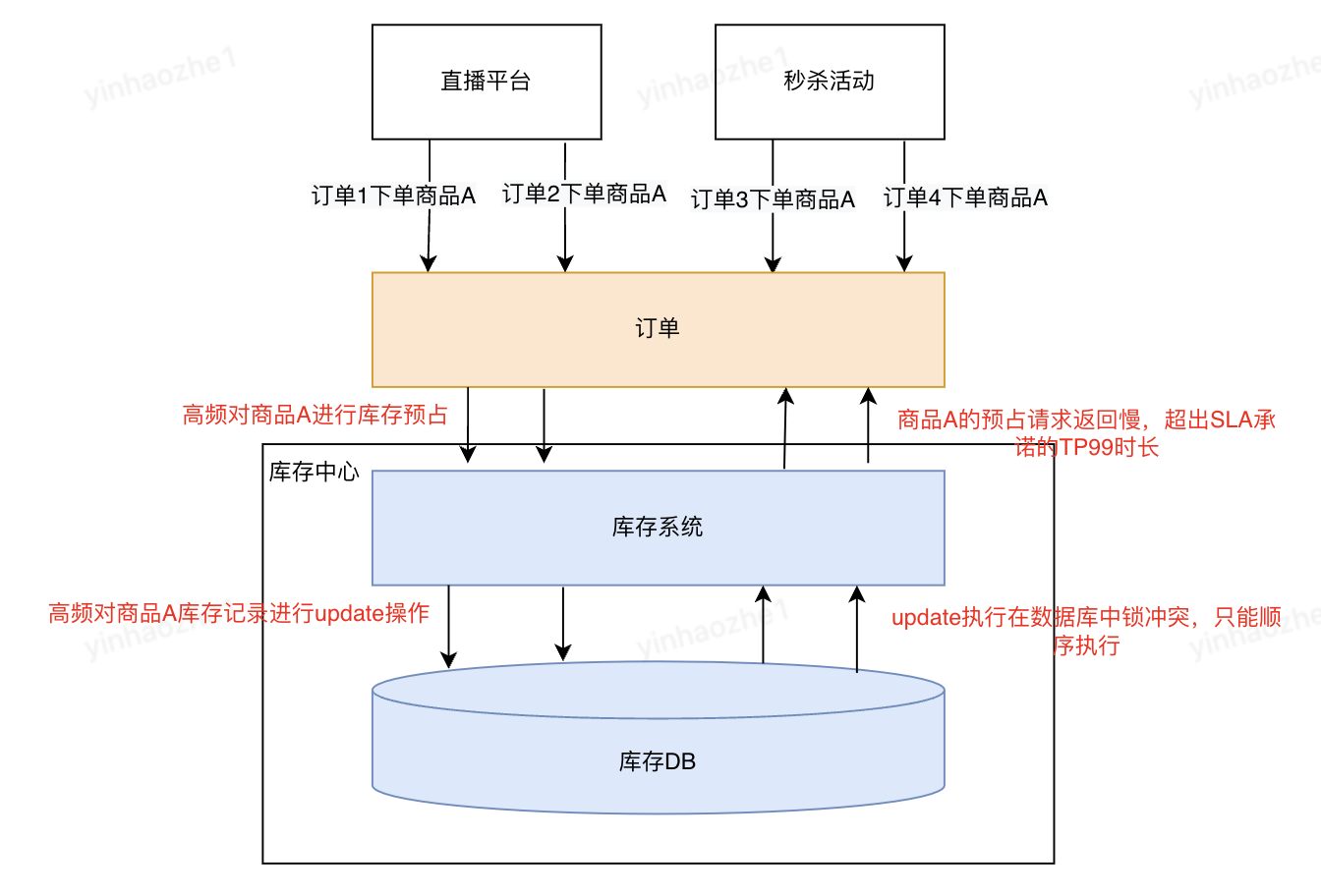
过往线上业务对固定商品的预占峰值在数百次/秒,而使用常规数据库预占方案,经压测数据验证,仅能支撑50次/秒。一旦发生热点商品高频预占,TP99就会飙升,如果高频预占时间较长,会给系统带来稳定性风险
2.1.1 解决方案调研
1、异步限流。让热点不那么热
在业务上允许的情况下,减缓预占操作速度,从而降低热点热度,缓解库存系统的性能压力。见下图:
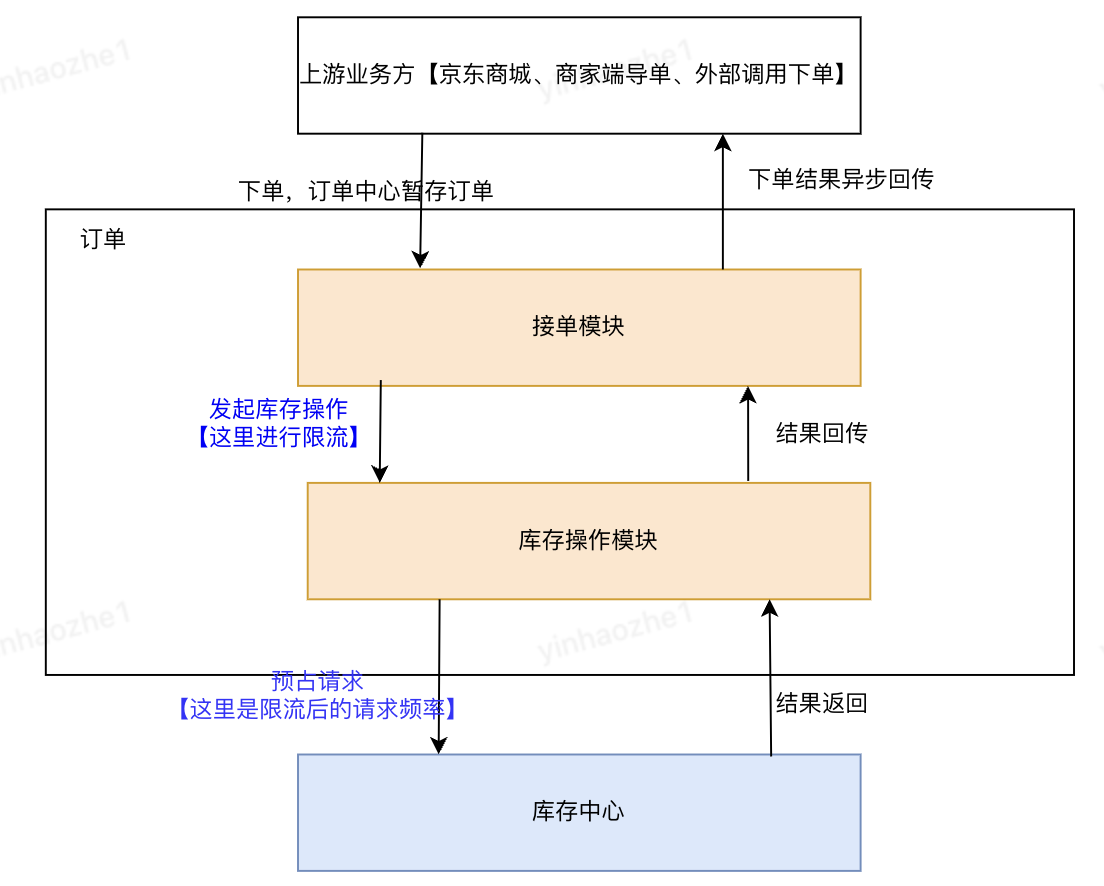
优点:逻辑简单,改造风险较小。从整个调用链路的角度去优化问题,而不是只优化瓶颈点
缺点:与下单方的交互机制需要支持异步机制,可能涉及流程改造;
2、商品库存横向拆分,提升数据库处理能力,降低并发请求时数据库锁的影响。将一个热点拆成多个不那么热的点
(1)商品入库时,将数量拆分为N份,放入N个表或者一个表的N行中
(2)预占时,根据预占单据号取余数,访问不同的数据源进行预占
假如单条记录支撑的性能是50单/秒,那么拆分成3份以后,支撑的性能就能提升到100+单/秒。见下图:
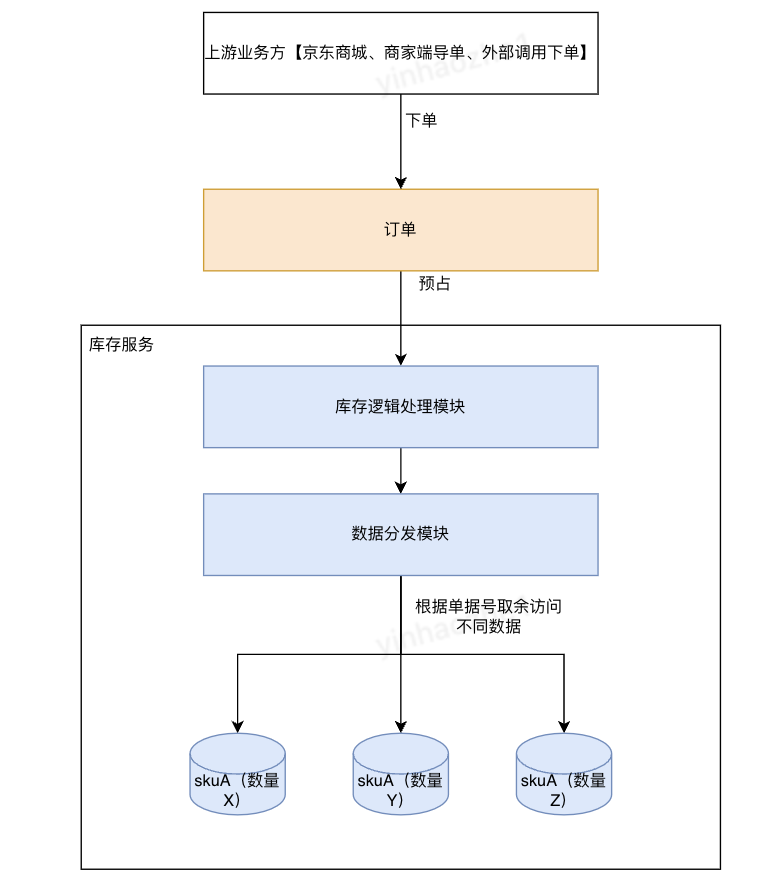
优点:上游无感知,改造可控制在库存领域
缺点:1、逻辑相对复杂,改造风险高
2、业务有损。存在有库存,但是预占不到的情况。例:(1)3个数据源都只有1个可用库存,但是订单上数量为2,预占不成功 (2)第一个数据源已经没有库存,其他数据源有库存,但是订单路由到了第一个数据源。可以使用其他子库重试、子库存加和后重试等方式解决此问题,但是逻辑复杂
3、使用缓存抗写流量。提升热点处理能力
热点商品预占的耗时主要集中在数据库操作上,使用处理速度更快的redis缓存来替代数据库来提供预占能力,见下图:
缓存的处理能力比DB高的多,经压测,可以支撑热点1200单/秒
优点:上游无感知,改造可控制在库存领域;
缺点:处理逻辑复杂。需要增加缓存处理逻辑;需要保障缓存-db的数据一致性
2.1.2 各方案对比及选型
| 是否能无损支持业务 | 实现成本 | |
| 异步限流 | 否,仅无损支持与下单方异步交互的场景 | 低 |
| 商品库存横向拆分 | 否,会出现有库存但无法预占的情况 | 中 |
| 缓存抗写流量 | 是 | 高 |
结合业务现状,当前存在部分KA商家体量大,改造风险高,但是这部分KA商家,订单已经与下单方是异步交互,所以这部分使用【异步限流】方案;其他商家统一使用【缓存抗写流量】的方案
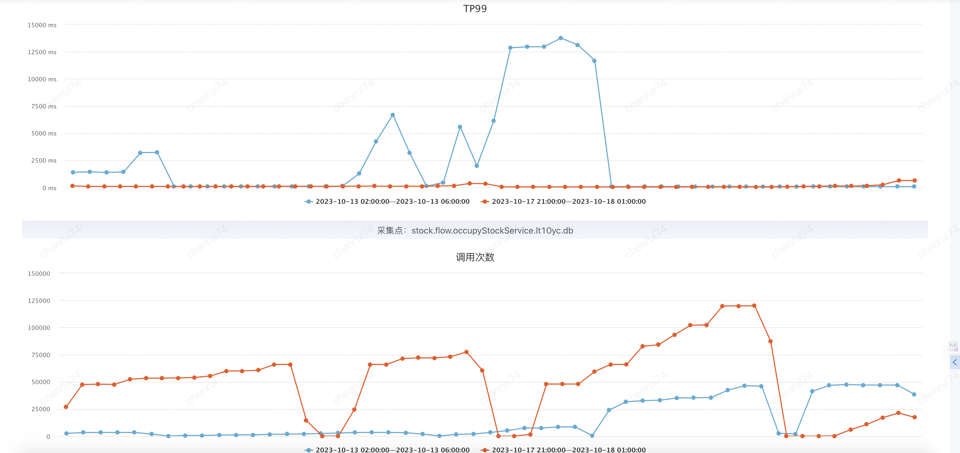
2.1.3 性能优化成果
通过优化,成功将热点商品预占TPS从50提升到1200,提升了24倍。TP99降低到130ms,降低至原时长的4.3%(从3000ms到130ms)。
橙色部分为优化后的结果:
2.2 线程同步问题
问题定义:多个线程操作查询、操作同一个商品的库存,使库存数据混乱
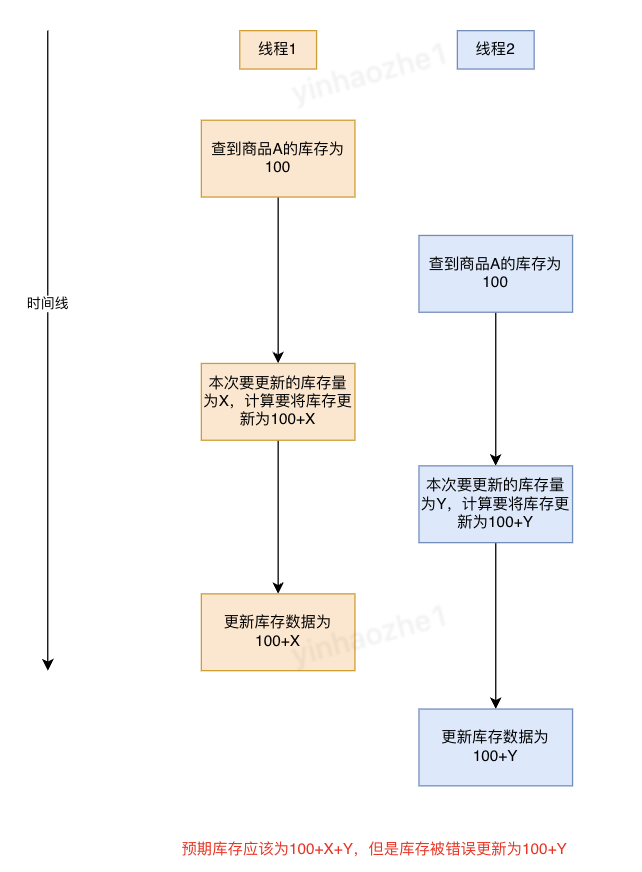
DB预占模式
解决方案:利用mysql事务、行锁机制来避免线程之间互相影响,在sql语句中操作变化量
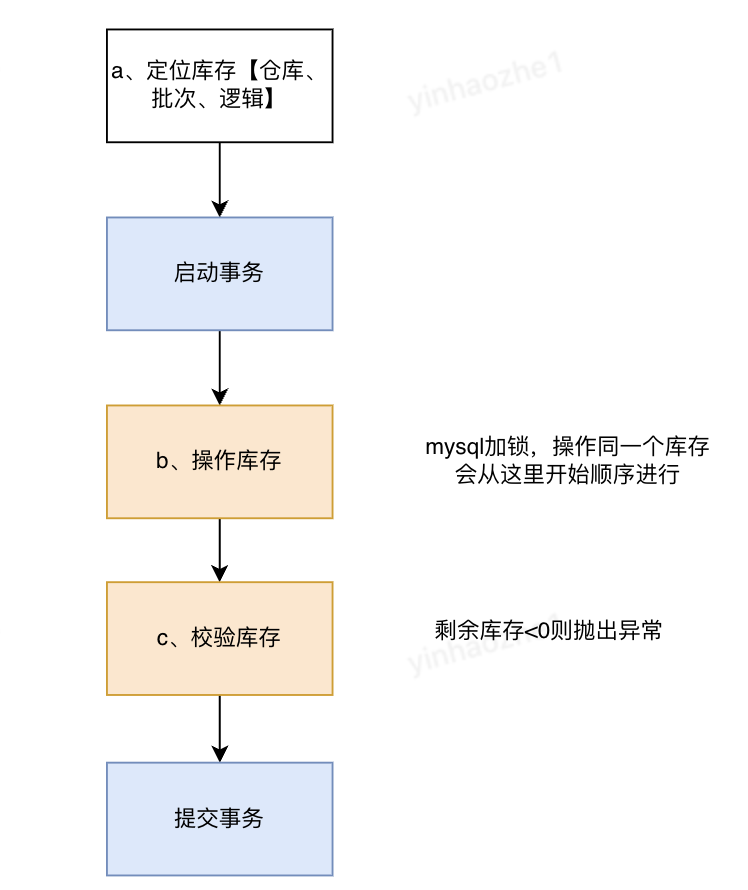
a、定位库存。使用商品id、仓库id、库存状态等信息来定位库存id
b、操作库存。根据库存id扣减库存,set 当前库存=当前库存+操作量。该步骤mysql会在id上加互斥锁,避免不同线程之间的互相影响。这里使用批量更新,来提升一单操作多商品的性能
UPDATE stock
SET stock_num = stock_num + CASE id
WHEN 1 THEN 'value1'
WHEN 2 THEN 'value2'
WHEN 3 THEN 'value3'
END
WHERE id IN (1,2,3)
c、校验库存。为了防止超卖,根据库存id查询库存,如果订单中任一商品库存被扣减为小于0,则抛出异常,使用数据库事务机制进行回滚
缓存(redis)预占模式
解决方案:将redis操作放入lua脚本中,利用redis单线程执行以及lua脚本执行过程中不会被其他操作语句插入的特性,避免线程间互相影响
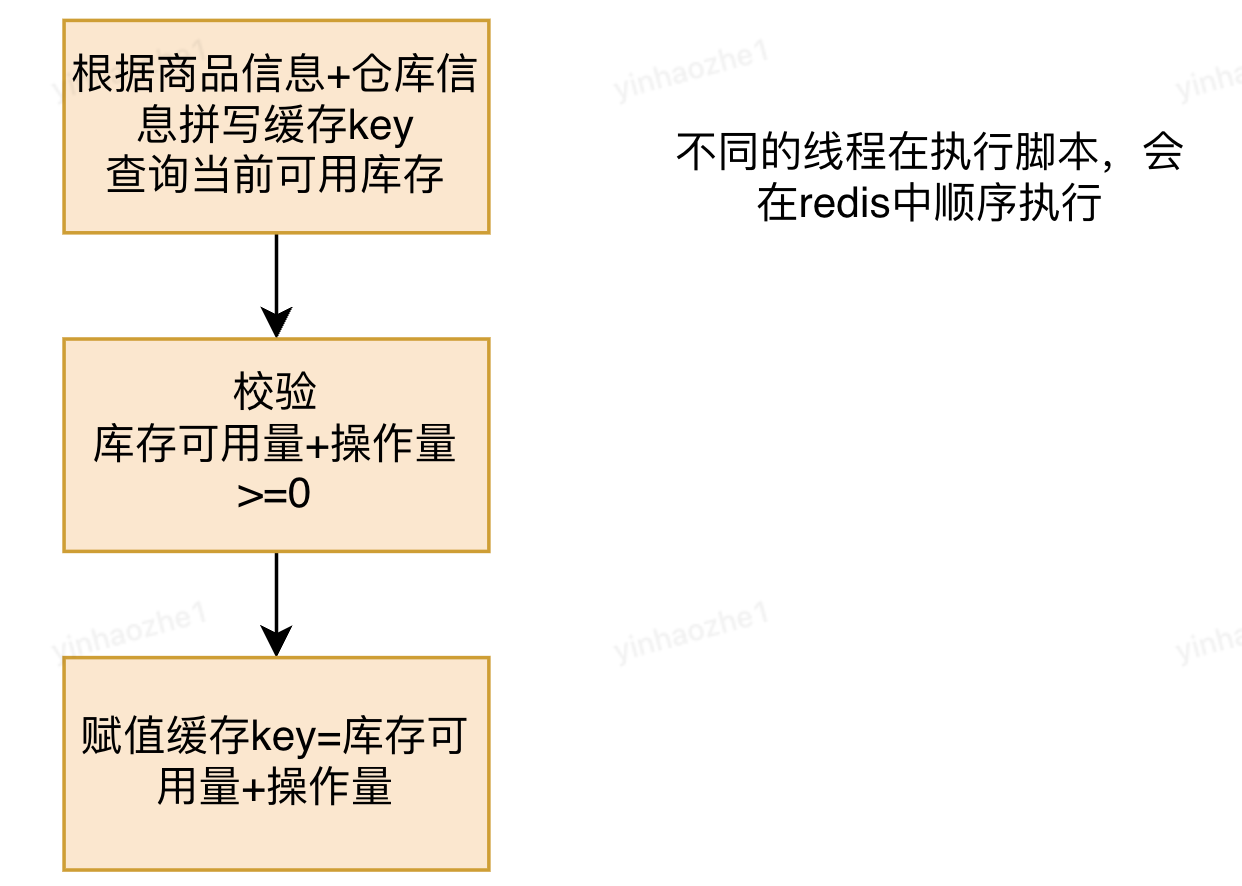
2.3 死锁问题
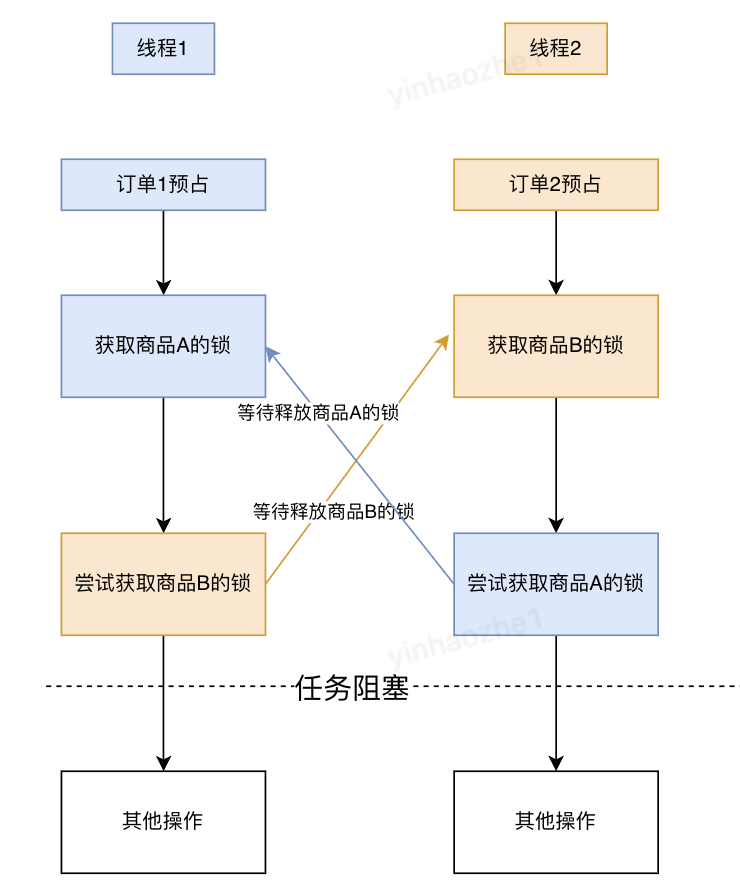
•死锁产生的原因1、预占流程间死锁。多个订单预占商品,包含多个相同商品,多线程并发请求时,线程之间持有对方依赖的锁,然后等待对方释放自己依赖的锁。见下图:
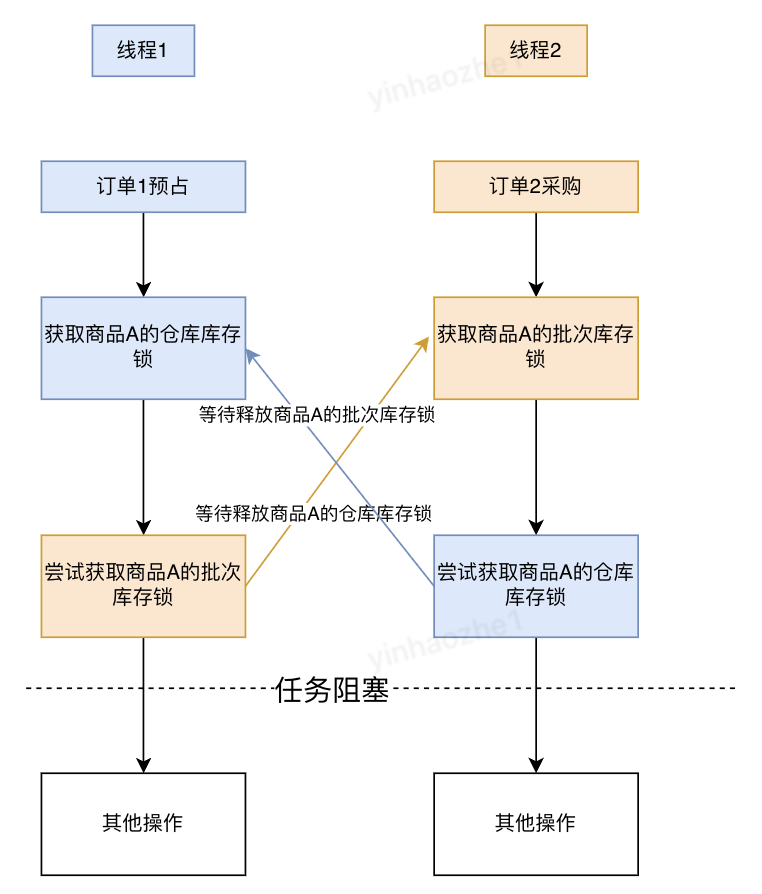
2、多流程间死锁。多种单据(预占、采购、取消等)操作多种类型库存,多线程并发请求时,线程之间持有对方依赖的锁,然后等待对方释放自己依赖的锁。
注:当前物流库存平台需要进行操作的库存数据可以分为仓库库存、逻辑库存、批次库存。其中逻辑库存、批次库存可以看作对某一个仓库库存进行不同维度的拆分。
•如何避免死锁
锁排序,保持锁的顺序一致。在多个事务请求资源的情况下,要保持锁的请求顺序一致,从而保障线程顺序执行。伪代码如下:
public Result handleOccupyRequest(List<CalcOccupyRequest> paramList) {
//XX业务逻辑
//Long类型比较器,根据库存id进行排序
Comparator<Long> comparator = new Comparator<Long>() {
@Override
public int compare(Long o1, Long o2) {
return o1.compareTo(o2);
}
};
//对要操作的各类库存进行排序
if(saleableStockIds!=null){
Collections.sort(saleableStockIds, comparator);
}
if (otherStockIds!=null){
Collections.sort(otherStockIds, comparator);
}
//XX业务逻辑
}
2.4 数据一致性问题
问题定义:redis、db作为两个独立的数据源,都需要维护库存数据,如何保障两个数据源的最终一致性?
这个问题又可以拆解为
1、如何从流程处理机制上保障redis-db之间的数据最终一致性?
2、万一出现了不一致,如何发现及解决?
如何从流程处理机制上保障redis-db之间的数据最终一致性
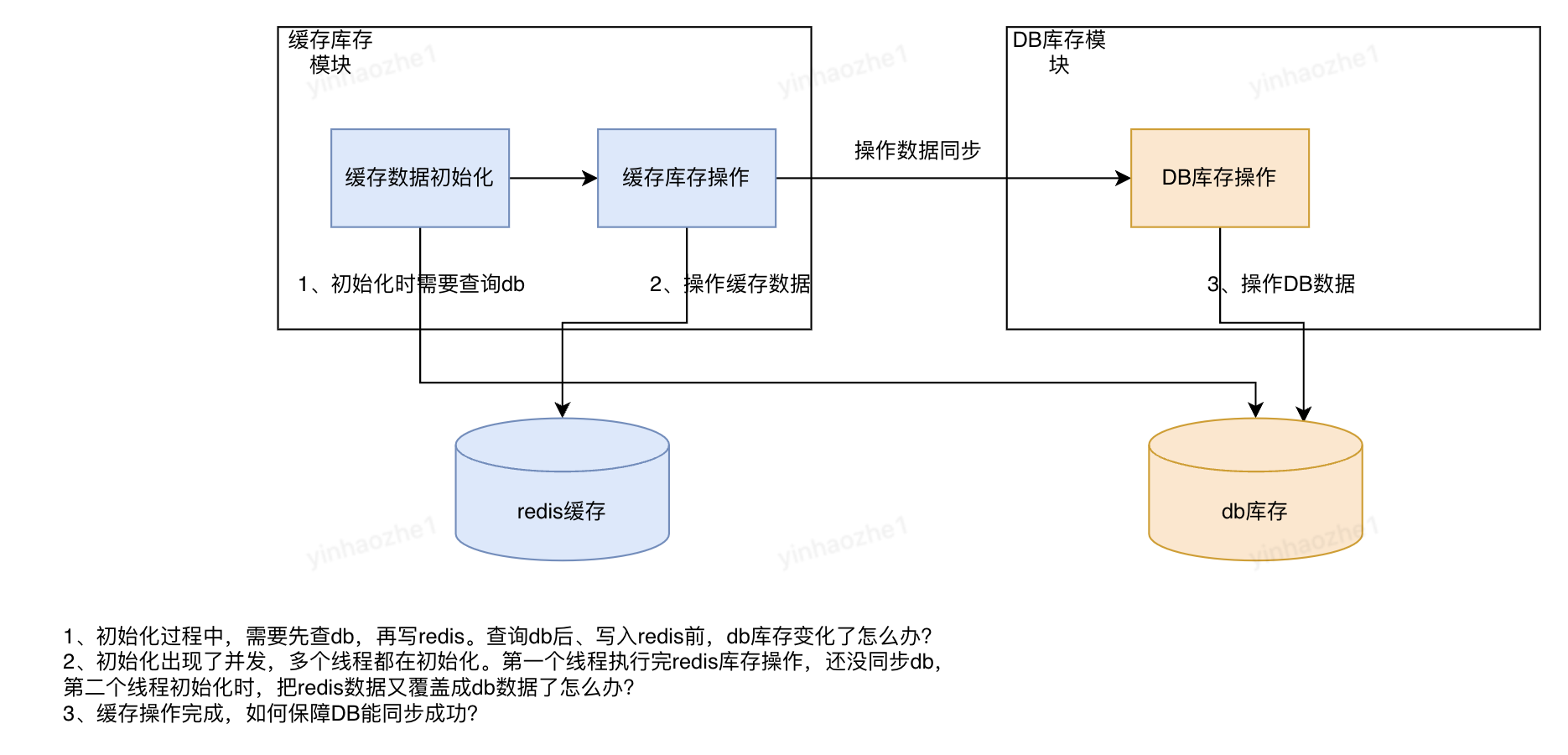
•初始化流程方案。使用 锁定db库存+redis事务来保障数据一致性。见下图:
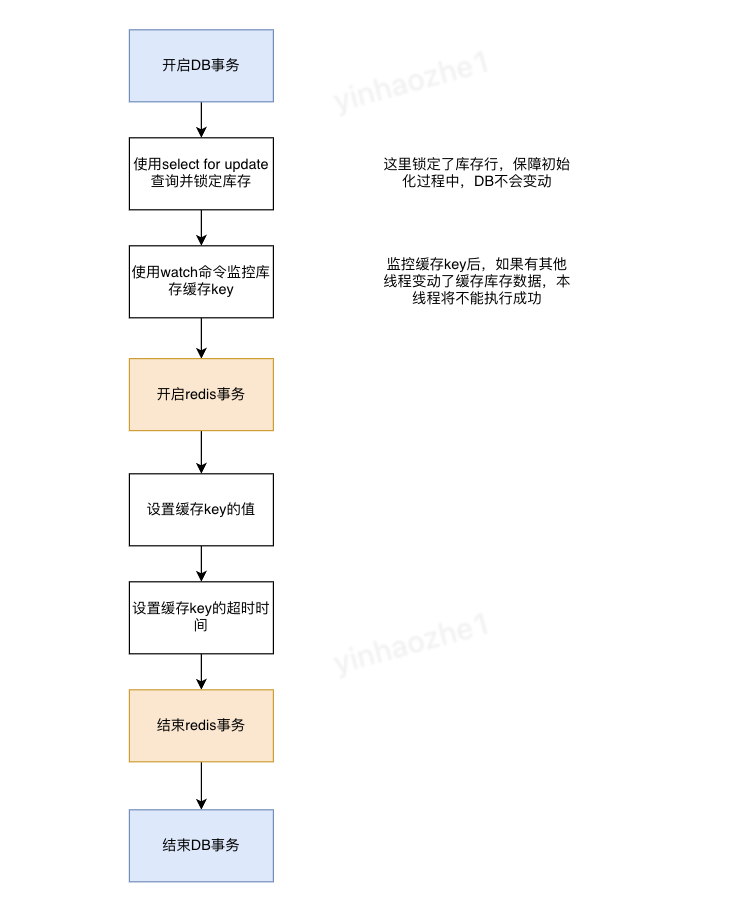
•数据同步流程。使用mq重试+任务系统兜底来保障同步能完成
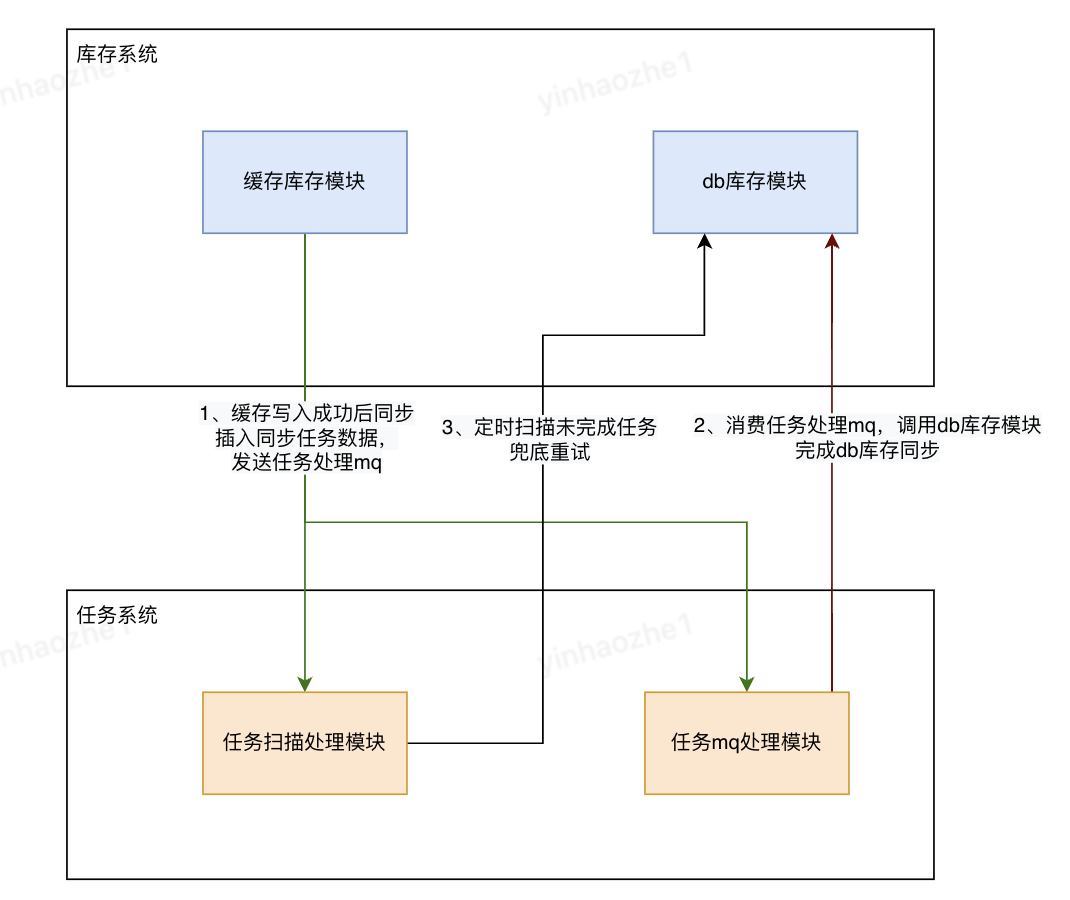
万一出现了不一致,如何发现及解决
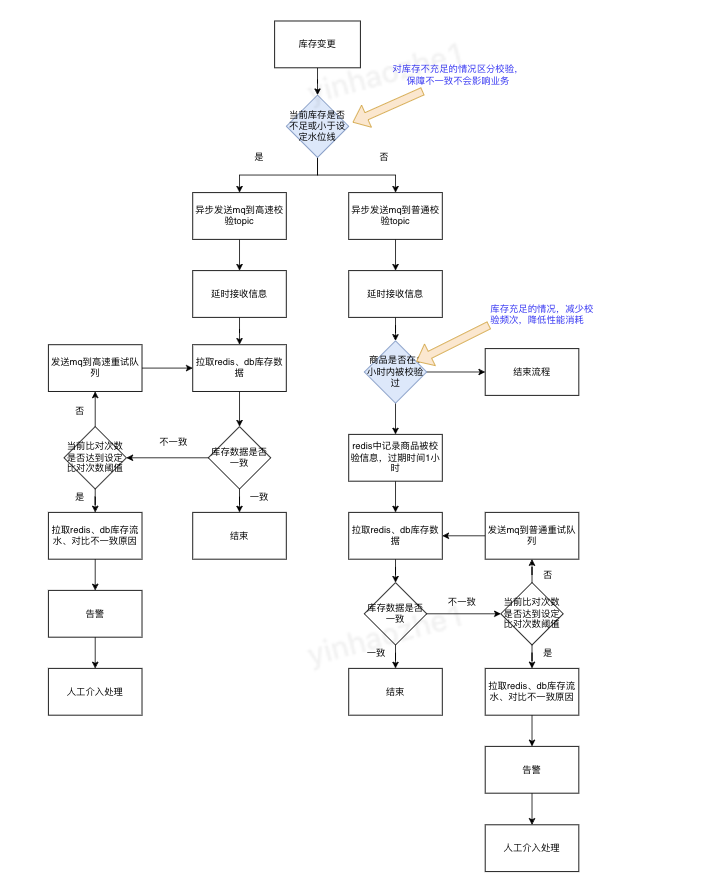
•db库存和redis库存在不断的变动中,尤其是同步过程,一定会存在明显的延迟,怎么判断数据是否一致? ◦引入缓存操作量数据,最大可能的消除同步延迟对数据一致性比对的影响。操作缓存时,将操作量增加到【缓存操作量数据】中,db同步完成后,从【缓存操作量数据】中减去操作量。数据一致性比对公式为:【缓存库存数据】+【缓存操作量数据】=【db库存数据】 ◦使用多次比对来尽量消除剩余延迟的影响。设定比对次数阈值,多次比对中只要有一次判断 缓存-db数据是一致的,则判断为通过一致性校验 •库存每天进行数百万次变动,如何在节约性能的同时保障及时发现不一致? ◦针对库存低于一定水位线的商品,每次库存变动后都进行一致性比对,避免因为数据不一致影响业务 ◦库存充足的商品,设定比对时间间隔,在间隔内区间内,只进行一次比对,避免影响系统性能
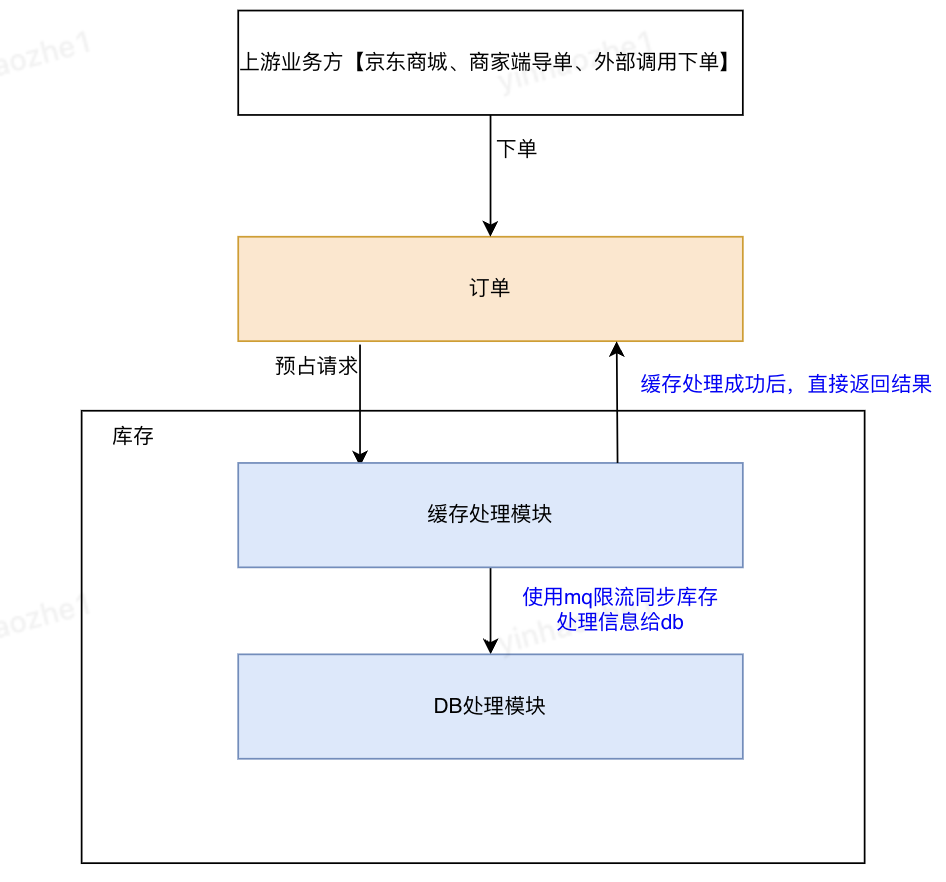
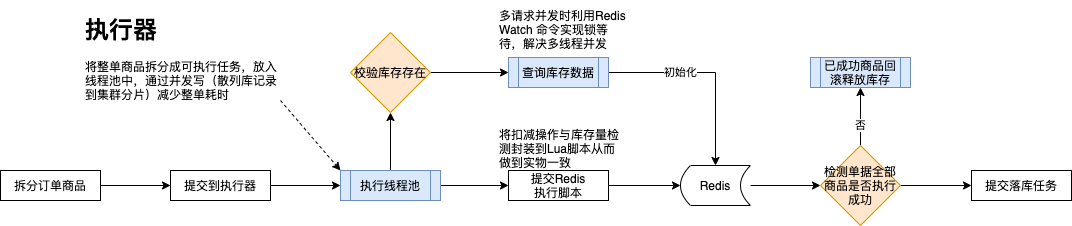
3、库存预占处理流程
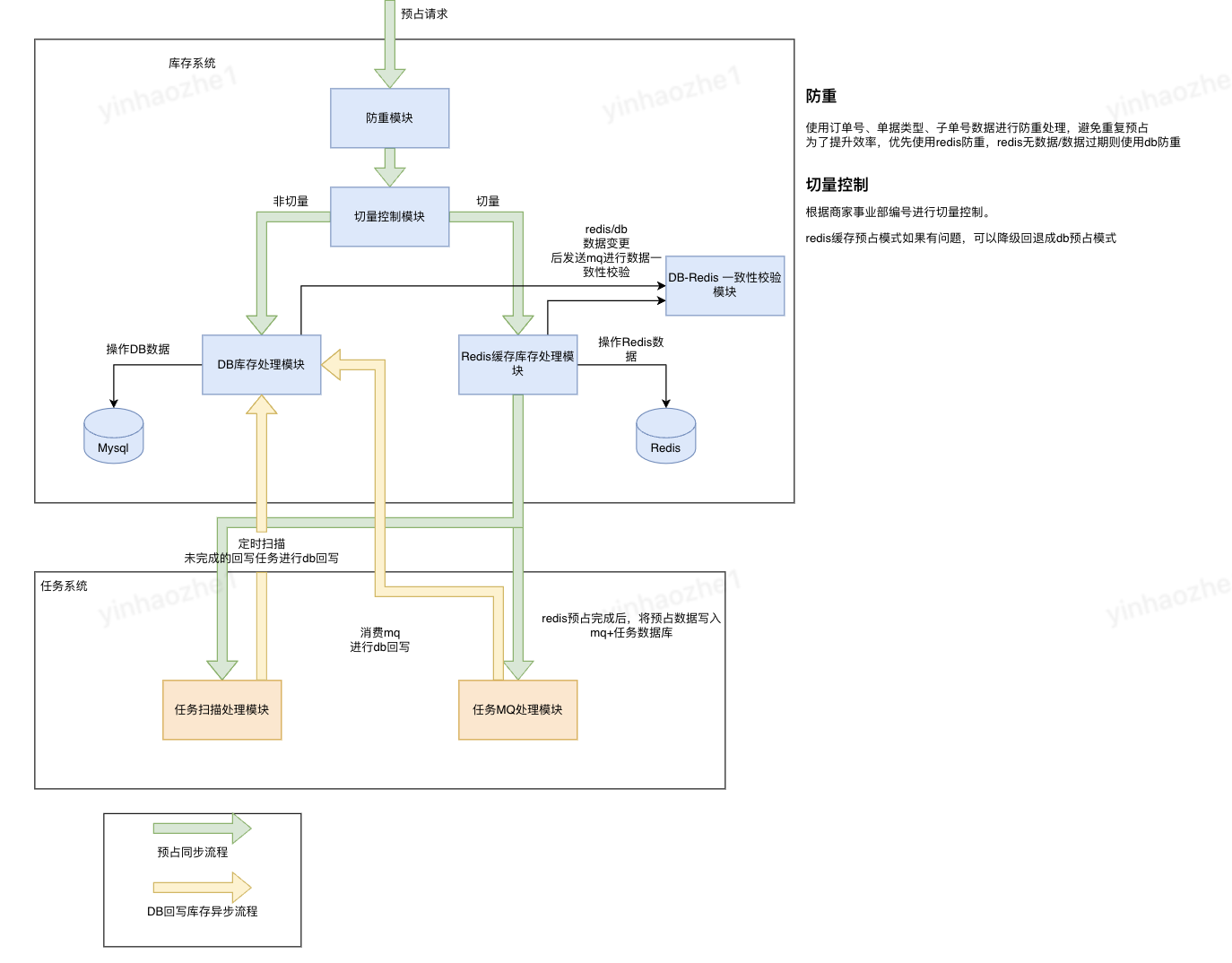
缓存处理流程:
标签:缓存,--,预占,商品,库存,操作,数据 From: https://www.cnblogs.com/Jcloud/p/18143670