背景
大家工作时,少不了ssh登录各个服务器,我这边手里也有很多服务器,有一些登录很快就进去了,有些要卡半天才能进去。之前以为是公司网络问题,每次也就忍了,这次突然不想忍了,决定定位一下。
我这边的服务器是10.80.121.46。因为这个问题是可复现的,算是个好问题,于是在本地开了wireshark,ssh登录,看看能不能看出端倪。
host 10.80.121.46 and tcp port 22
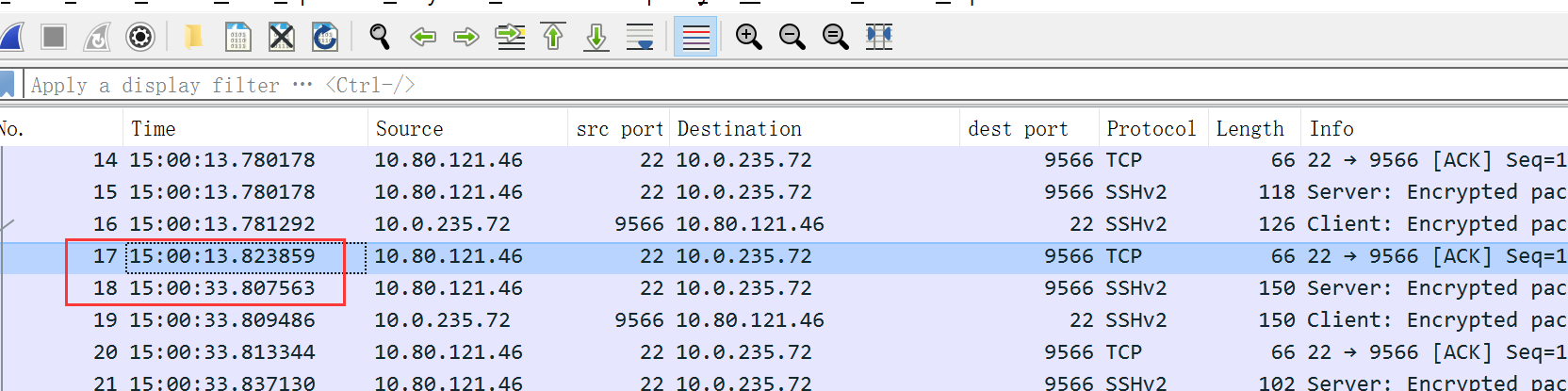
可以看到,服务端在00:13,发了第一个消息过来;过了20s,发了第二个消息过来。
总的来说,应该是服务端问题。
定位过程
看日志
由于是ssh这种加密了的协议,抓包也看不出个啥。所以我首先的思路是看看sshd这个服务端进程的日志。sshd是systemd管理的,所以看看状态先。
这种的话,一般也能看到最新的日志,如果要看完整的日志,可以用如下命令:
journalctl -u sshd
ps: journalctl -u sshd -f 可以像tailf那样持续跟踪日志
但是,发现只有info级别的日志,也看不出什么特别.
Apr 03 15:27:30 nginx2 sshd[87616]: Accepted password for root from 10.0.235.72 port 11481 ssh2
接下来,又看了下其他日志:
/var/log/messages:
Apr 3 15:27:30 year-account-nginx2 systemd-logind: New session 13336 of user root.
Apr 3 15:27:30 year-account-nginx2 systemd: Started Session 13336 of user root.
/var/log/secure:
Apr 3 15:27:30 year-account-nginx2 sshd[87616]: Accepted password for root from 10.0.235.72 port 11481 ssh2
Apr 3 15:27:30 year-account-nginx2 sshd[87616]: pam_unix(sshd:session): session opened for user root by (uid=0)
反正看了好些日志,没啥用,这边上个链接,讲linux下的各种日志。
https://www.plesk.com/blog/featured/linux-logs-explained/
https://www.eurovps.com/blog/important-linux-log-files-you-must-be-monitoring/
开启debug日志
上网查了下,怎么开启sshd的debug级别日志,结论如下:
vim /etc/ssh/sshd_config
加一行:
LogLevel DEBUG
这个LogLevel的取值有哪些呢,具体可以在机器上执行:
man sshd_config
没想到取值还有更逆天的:

我之前就是在debug级别下测试的,然后看日志:
journalctl -u sshd -f
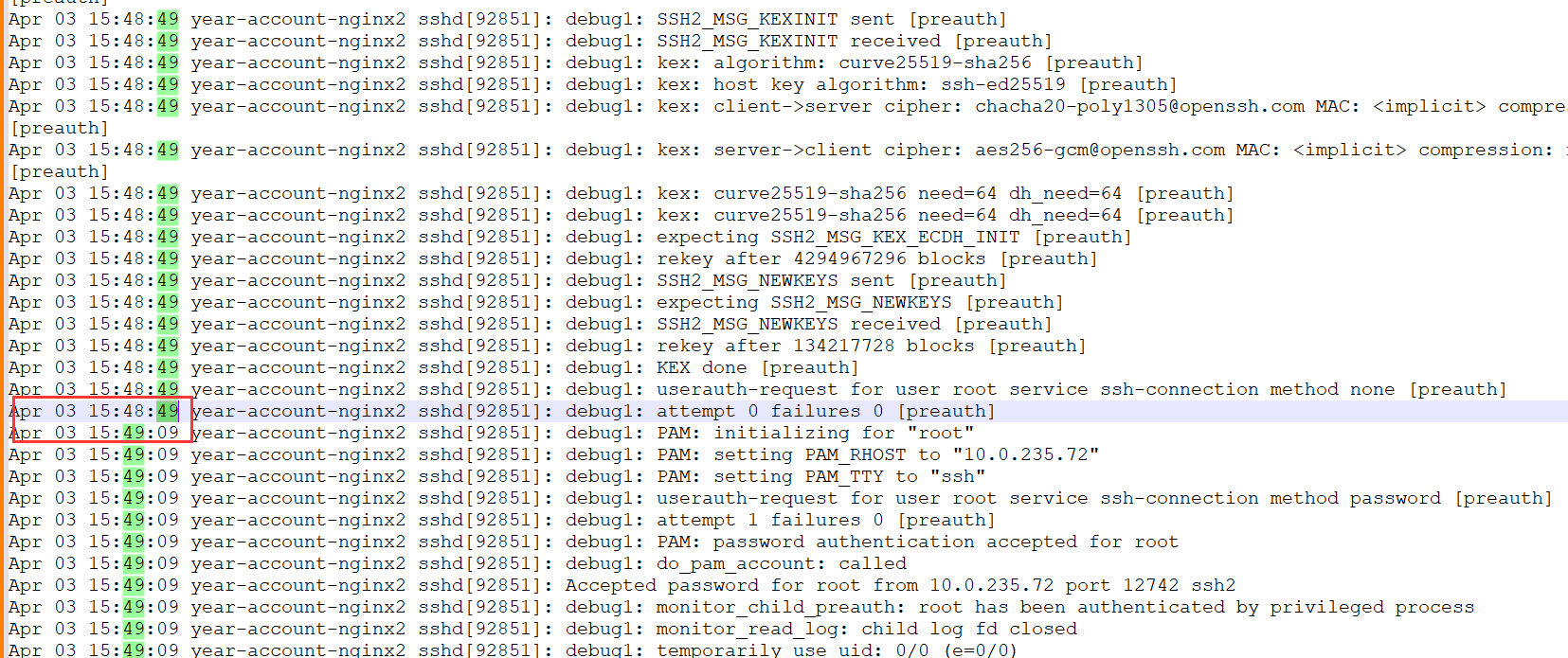
看到出现了20s的间隔,但是,还是没有什么错误或者警告。当时,我就开始上网查了,但是这次,咱们要不试试把日志级别弄成DEBUG3:
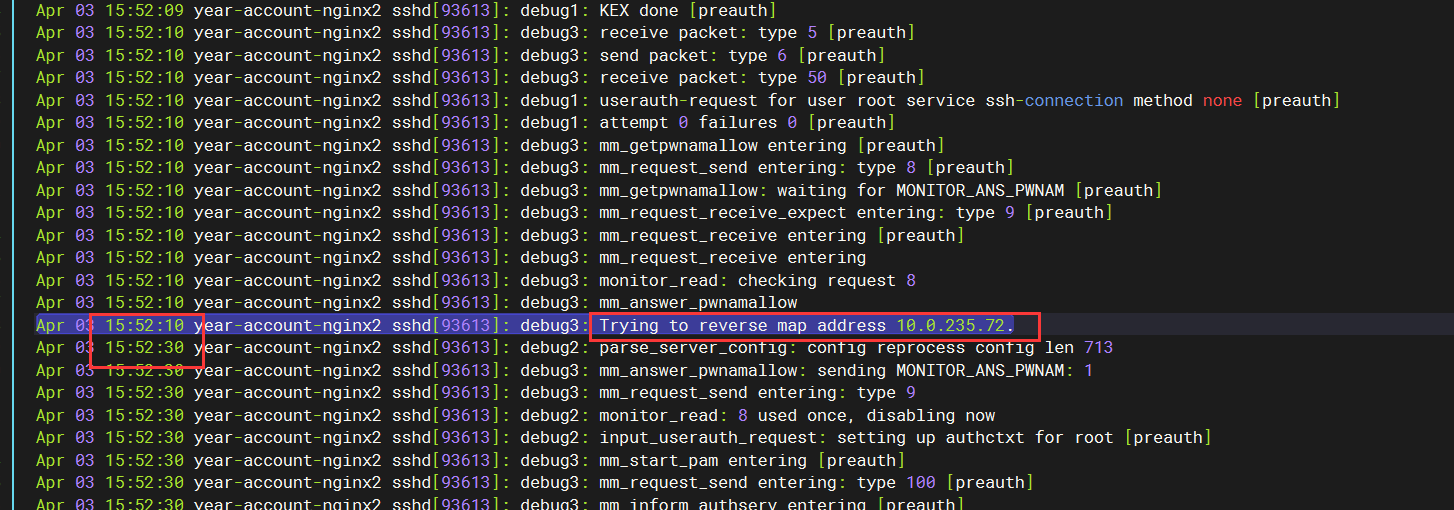
这里日志细了一些,但还是看不太出来啥问题。这个10.0.235.72,是我本机windows的ip。
服务端dns抓包
经过上网冲浪,发现很多文章提到了一点,就是sshd会拿着我们客户端的ip,去dns 服务器查询ip对应的主机名(域名)。很明显,我这个ip,肯定是没什么域名的。大概率是这个原因,但是基于严谨的角度考虑,我还是先找找证据。
dns服务器对外的端口是53,所以我抓的就是这个端口的网络包:
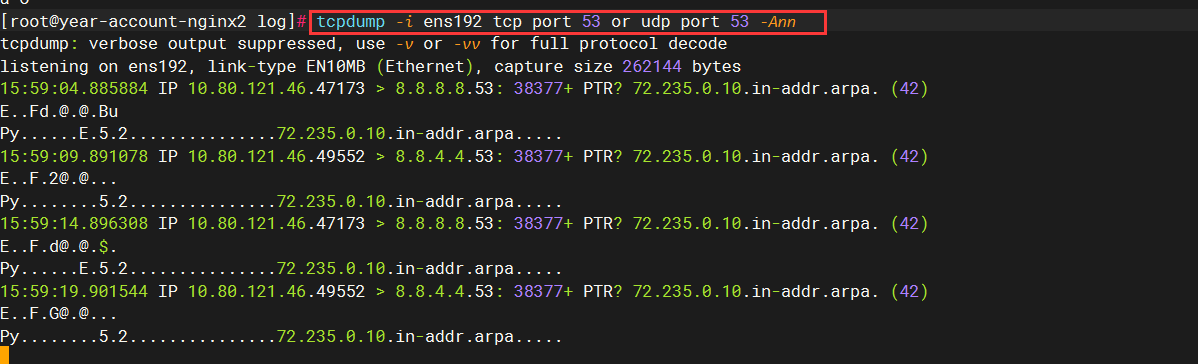
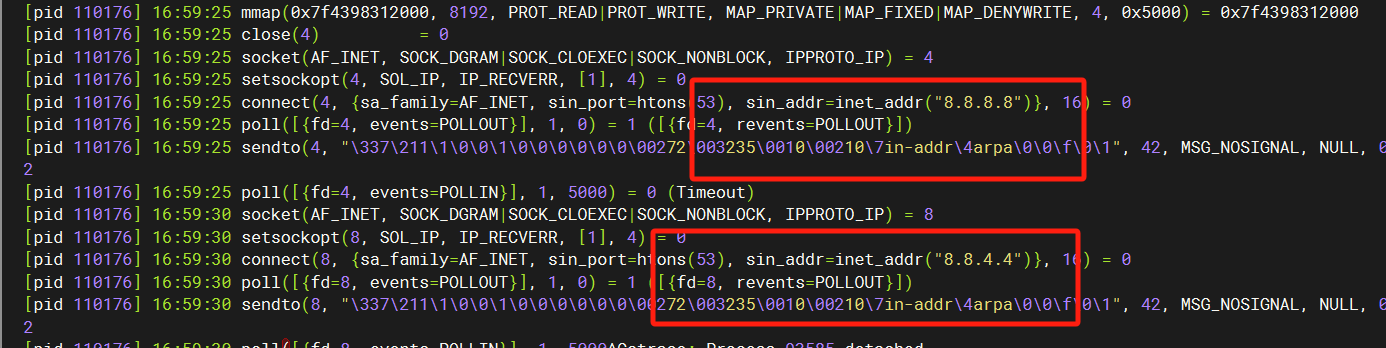
可以发现,本机是给两个dns服务器发请求的,分别是8.8.8.8 8.8.4.4
看下机器的dns服务器配置:
vim /etc/resolv.conf
nameserver 8.8.8.8
nameserver 8.8.4.4
不知道为啥是这个地址,反正是运维同事给的。
测试了端口通不通,发现tcp不通,udp不知道咋测(试了下netcat、nmap,没太弄懂)
ping也不通,不知道是真不通,还是对端禁ping了。
这些都不重要,重要的是,这个报文也不知道是啥意思,看起来和我的问题没什么关系。
strace排查
暂时放下dns这块,准备strace试试,反正,死马当活马医。
strace这个一般用得少,选项记不住,一开始就这么试试:
netstat -nltp|grep 22
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 93585/sshd
tcp 0 0 0.0.0.0:4822 0.0.0.0:* LISTEN 31633/nginx: master
tcp6 0 0 :::22 :::* LISTEN 93585/sshd
拿到sshd pid为93585,开启strace:
但是啥也没看出来。
找了下以前笔记,加了几个选项:
strace -p 121920 -s 1000 -t -e trace=network,file,desc,process
-s: 字符串显示1000个字符串,不截断(默认是32,会看不全)
-t:显示时间
-e trace=network,file,desc,process,监控网络、文件、文件描述符、进程相关的系统调用
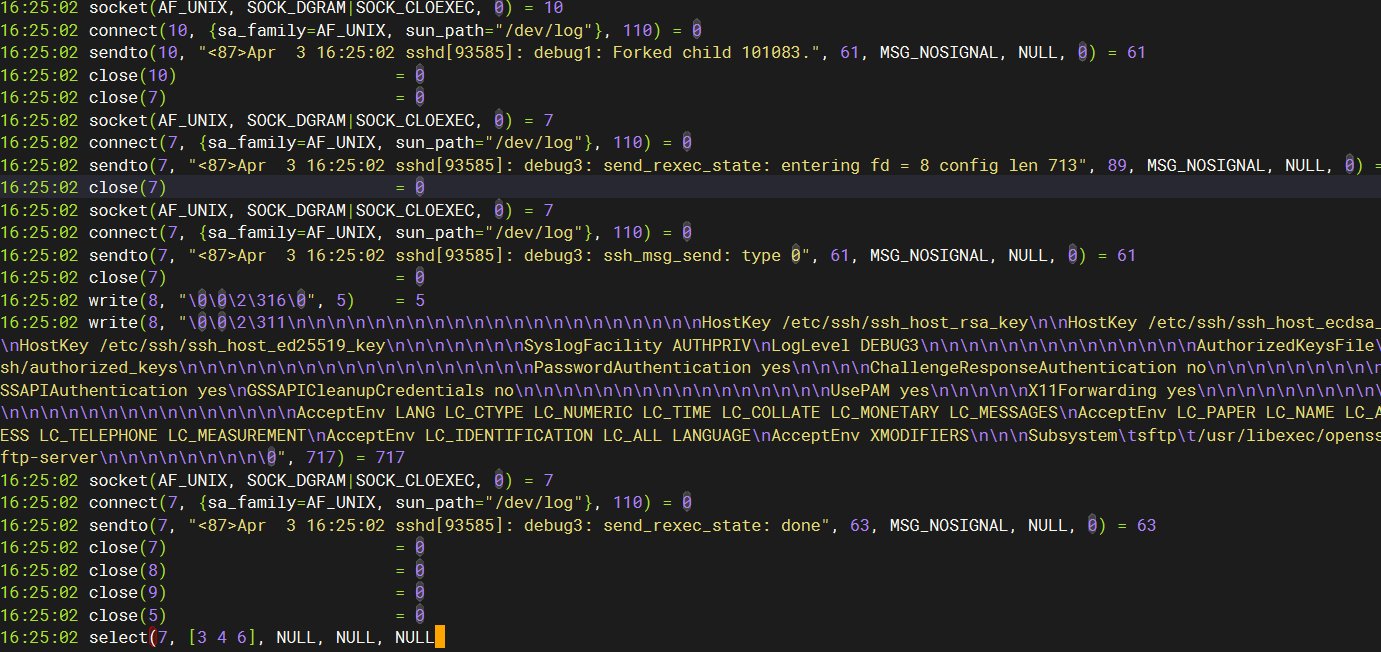
这次信息多一点,还是啥都看不出来。
上网查
没法了,把之前dns抓的包拿下来用wireshark分析分析。
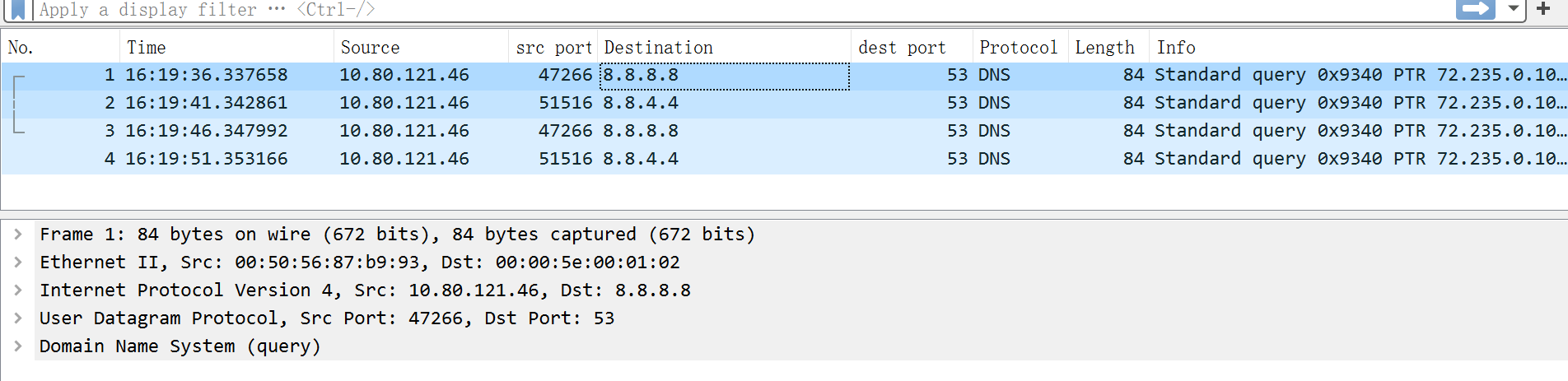
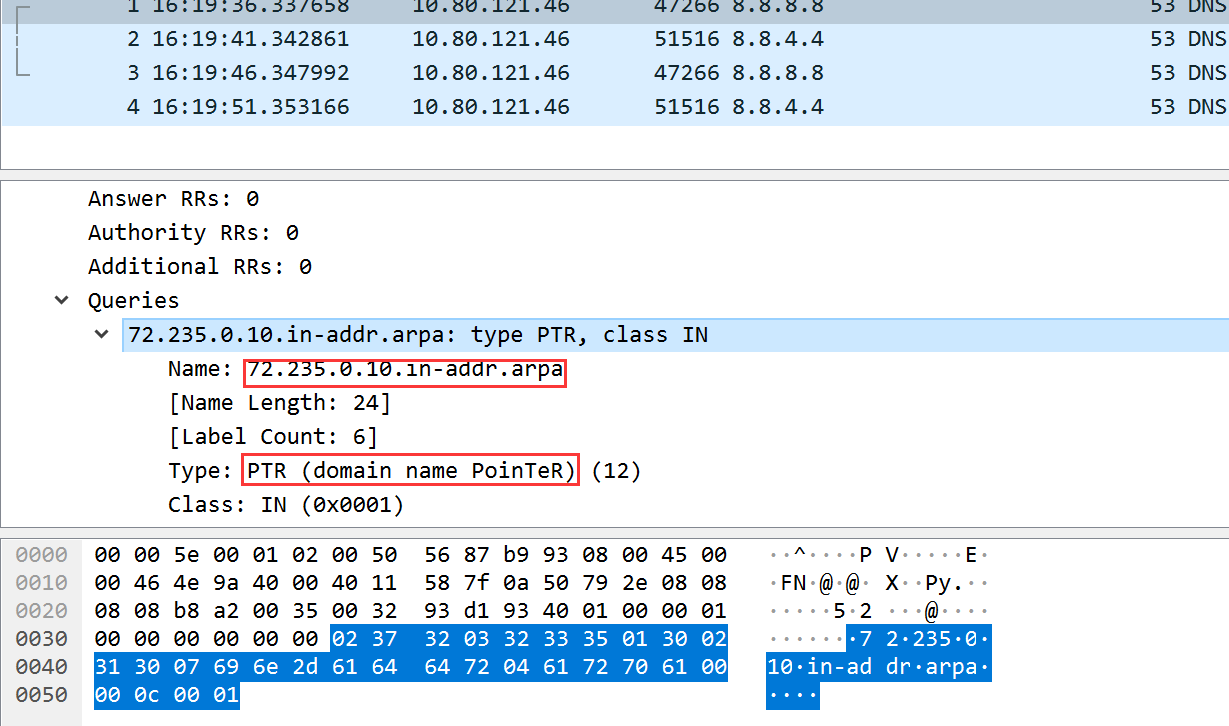
这个dns查询,有点看不懂,直接拿关键字搜了下,大家看如下链接吧:
https://www.cloudflare.com/zh-cn/learning/dns/dns-records/dns-ptr-record/
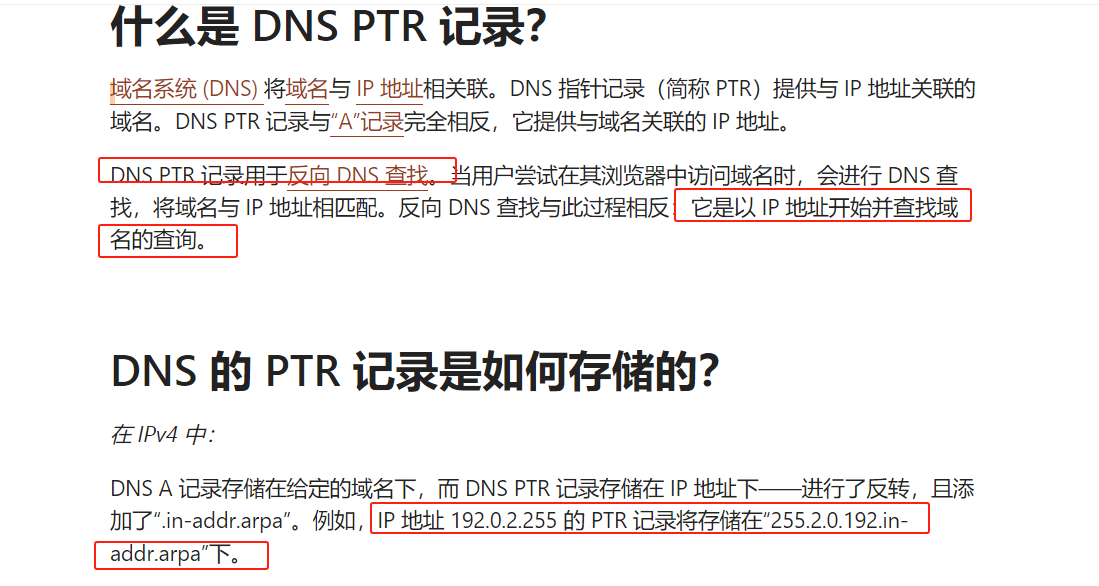
难怪,dns进行反向查找时,客户端ip是反的,我的实际ip是:10.0.235.72
到了上图,就变成了:
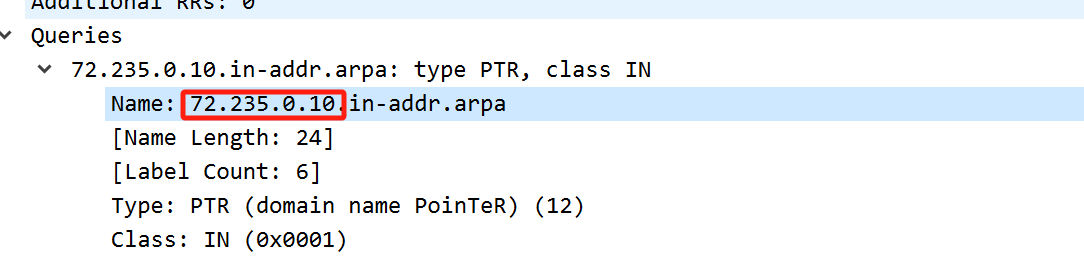
也难怪我没看出来,这个基本算是一个强力证据了,大概率是dns解析的问题,毕竟用了我的ip。
修改sshd配置
那就禁用这个机制吧,方式如下:
vim /etc/ssh/sshd_config
UseDNS no
然后重启sshd
systemctl restart sshd
这样基本就ok了。重新试了下,再没有卡20s了,秒登录。
继续探索strace
找到问题原因后,strace我又继续研究了下。原来是少了个选项,-f:
-f
--follow-forks
Trace child processes as they are created by currently traced processes as a result of the fork(2), vfork(2) and
clone(2) system calls. Note that -p PID -f will attach all threads of process PID if it is multi-threaded, not only
thread with thread_id = PID.
这个选项是跟踪子进程的系统调用,因为,sshd收到一个客户端连接时,会fork一个新进程出来。前面都忘了加-f,所以导致没跟踪到。
换下命令:
strace -p 93585 -s 1000 -t -e trace=network,file,desc,process -f
这次可以跟踪了。
补充
在写这篇文章的时候,对一个地方产生了疑问。一般看日志的时候,对于systemd管理的service,我会看journalctl,也会看/var/log/messages,经常的情况是,在journalctl中的日志,在/var/log/messages中也能看到。
查了下两者的机制,参考:
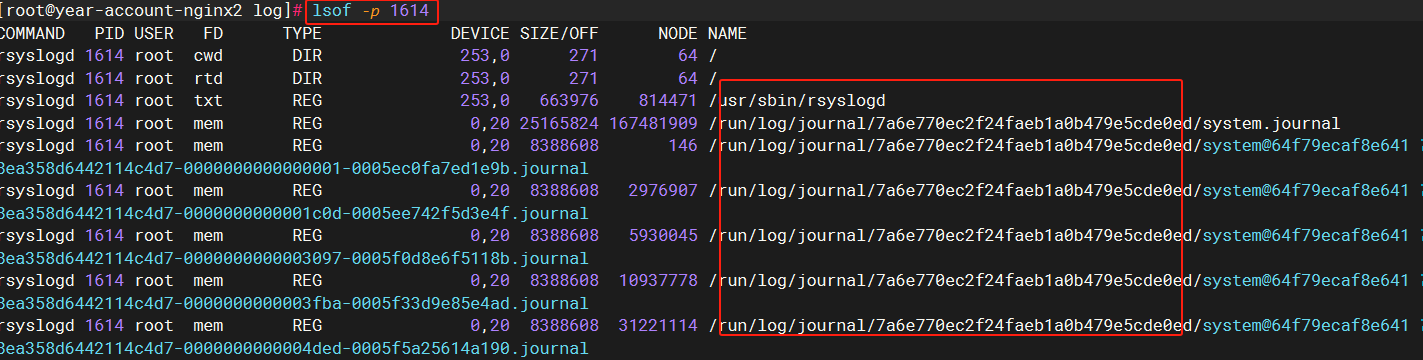
systemd会写日志到一些文件(journalctl就会读这些文件),然后,另一个后台进程rsyslogd,也会读这些日志,然后写到/var/log/messages这些文件中。
[root@year-account-nginx2 log]# ps -ef|grep rsys
root 1614 1 0 2022 ? 00:46:28 /usr/sbin/rsyslogd -n