1. 前言
自从和员外上家公司离职后,我们就自己搞公司投入到了RAG大模型的AI产品应用的开发中,这中间有一个春节,前后的总时间大概是三个月左右,在这三个月期间,基本是昼夜兼程啊,到今天3月底结束,产品目前看是有了一个基础的雏形。
在这期间,员外负责整个产品的营销、商业客户的洽谈等方面的内容,我和阿包负责整体的技术架构搭建,代码从0-1的编写,我们是在24年1月26,产品初步上线了一个版本,开始接受企业客户的试用,这让我们接受到了大量的需求,以及我们产品在目前的市场环境中还存在哪些竞争力不足需要改进的地方。
三个月时间过去了,在我们的TorchV AI 产品初步成型之际,和大家分享一下开发RAG、LLM系统以来的一些心得和经验。
2. RAG简介
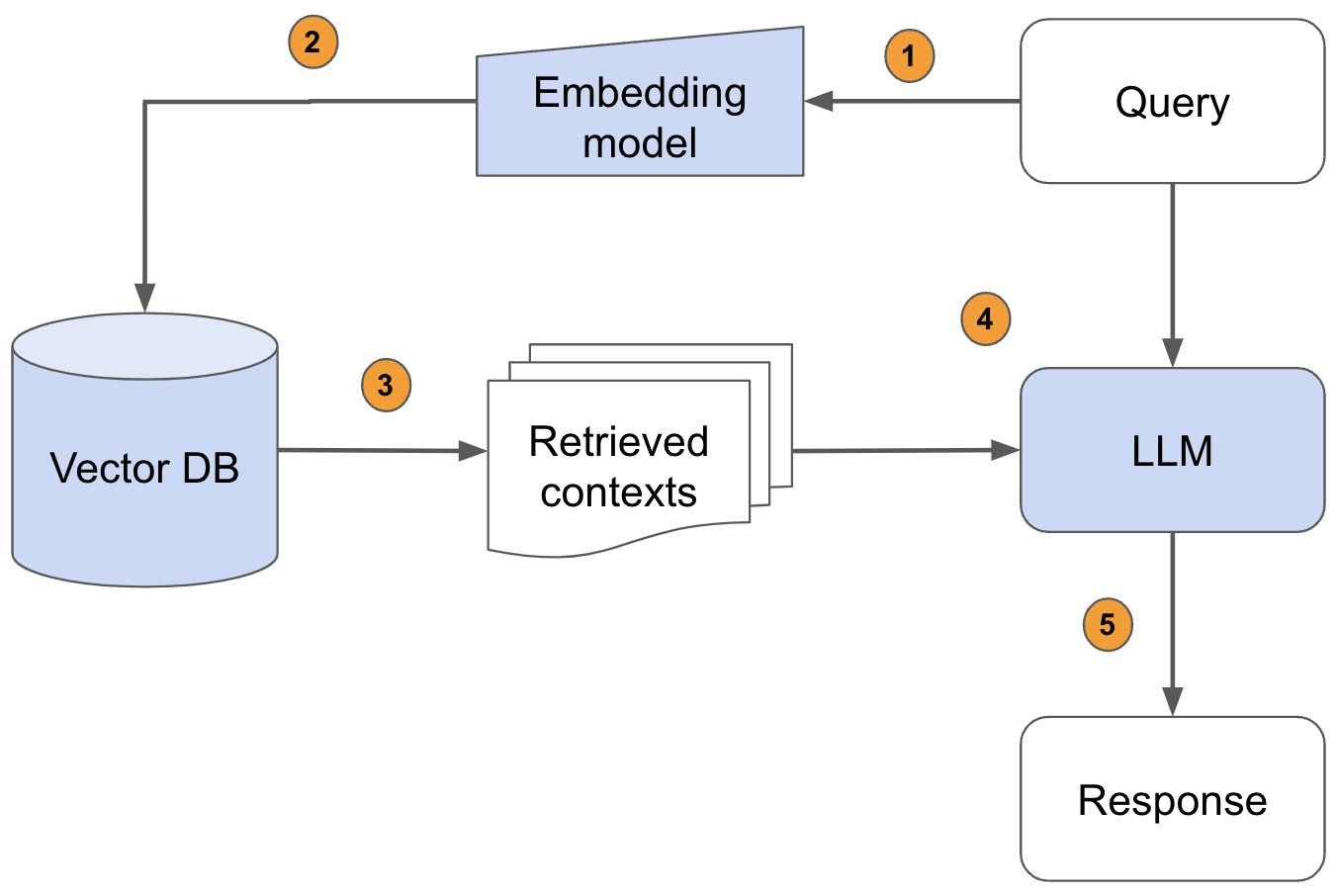
RAG(检索增强生成)名词一开始来源于2020年的一片论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》,旨在为大语言模型(LLM)提供额外的、来自外部知识源的信息。这样,LLM 在生成更精确、更贴合上下文的答案的同时,也能有效减少产生误导性信息的可能。
可以说在目前大模型井喷的今天,RAG作为一项为密集型知识NLP任务的处理指明了方向,配合AI大模型,让世界发生了翻天覆地的变化,数以万计的开发者都涌入这个赛道,同时竞争。
我们知道LLM目前存在的一些问题和挑战:
我自己理解LLM大模型本质就是一个二进制文件,所有的知识都通过压缩技术全部压缩在一个/多个GB的二进制文件中,最终在获取数据的时候,通过LLM的模型架构,推理能力,将所有的知识信息又生成出来。
- 在没有答案的情况下提供虚假信息(胡说八道、幻觉)。
- 模型知识的更新成本、周期、及大模型的通用能力问题(大公司才玩的转)
- 数据安全和隐私等问题
而RAG技术的出现,正好能有效的缓解目前大模型存在的一些问题,主要表现方面如下:
- 经济高效的处理知识&开箱即用:只需要借助信息检索&向量技术,将用户的问题和知识库进行相关性搜索结合,就能高效的提供大模型不知道的知识,同时具有权威性
- 有效避免幻觉问题:虽然无法100%解决大模型的幻觉问题,但通过RAG技术能够有效的降低幻觉,在软件系统中结合大模型提供幂等的API接口就可以发挥大模型的重大作用
- 数据安全:企业的数据可以得到有效的保护,通过私有化部署基于RAG系统开发的AI产品,能够在体验AI带来的便利性的同时,又能避免企业隐私数据的泄漏。
3. RAG技术&架构思考
既然我们知道,RAG作为密集型知识库的处理和大模型配合起来有着天然优势,那么如何做好RAG的开发?
RAG应用的基础技术核心是:让大模型依靠现有的数据(PDF/WORD/Excel/HTML等等)精准的回答用户的问题
这是最基础的功能,同时也是最低要求,任何做RAG领域的AI应用产品,技术层面都需要去突破解决的技术难题。
注意两个核心点: