论文提出用于out-of-distributions输入检测的energy-based方案,通过非概率的energy score区分in-distribution数据和out-of-distribution数据。不同于softmax置信度,energy score能够对齐输入数据的密度,提升OOD检测的准确率,对算法的实际应用有很大的意义
来源:晓飞的算法工程笔记 公众号
论文: Energy-based Out-of-distribution Detection

Introduction
今天给大家分享一篇基于能量函数来区分非训练集相关(Out-of-distribution, OOD)输入的文章,连LeCun看了都说好。虽然文章是2020年的,但里面的内容对算法实际应用比较有用。这篇文章提出的能量模型想法在之前分享的《OWOD:开放世界目标检测,更贴近现实的检测场景 | CVPR 2021 Oral》也有应用,有兴趣的可以去看看。
现实世界是开放且未知的,OOD由于与训练集差异很大,使用通过特定训练集训练出来的模型进行预测的话,往往会出现不可控的结果。因此,确定输入是否为OOD并过滤掉,对算法在高安全要求场景下的应用是十分重要的。
大部分OOD研究依赖softmax置信度来过滤OOD输入,将低置信度的认定为OOD。然而,由于网络通常已经过拟合了输入空间,softmax对跟训练集差异较大的输入时常会不稳定地返回高置信度,所以softmax并不是OOD检测的最佳方法。还有部分OOD研究则从生成模型的角度来产生输入的似然分数\(logp(x)\),但这种方法在实践中难以实现而且很不稳定,因为需要估计整个输入空间的归一化密度。
为此,论文提出energy-based方法来检测OOD输入,将输入映射为energy score,能直接应用到当前的网络中。论文还提供了理论证明和实验验证,表明这种energy-based方法比softmax-based和generative-based方法更优。
Background: Energy-based Models
EBM(energy-based model)的核心是建立一个函数\(E(x): \mathbb{R}^D\to\mathbb{R}\),将输入\(x\)映射为一个叫energy的常量。
一组energy常量可以通过Gibbs分布转为概率分布\(p(x)\):
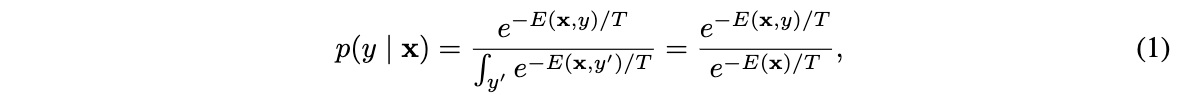
这里将\((x,y)\)作为输入,对于分类场景,\(E(x,y)\)可认为是数据与标签相关的energy常量。分母\(\int_{y^{'}}e^{-E(x,y^{'})/T}\)是配分函数,即所有标签energy的整合,\(T\)是温度系数。
输入数据\(x\in\mathbb{R}^D\)的Helmholtz free energy \(E(x)\)可表示为配分函数的负对数:
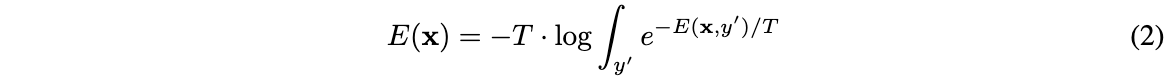
结合公式1和公式2就构建了一个跟分类模型十分类似的EBM,可以通过Gibbs分布将多个energy输出转换为概率输出,还可以通过Helmholtz free energy得出最终的energy。
对于分类模型,分类器\(f(x):\mathbb{R}^D\to\mathbb{R}^K\)将输入映射为K个值(logits),随后通过softmax函数将其转换为类别分布:
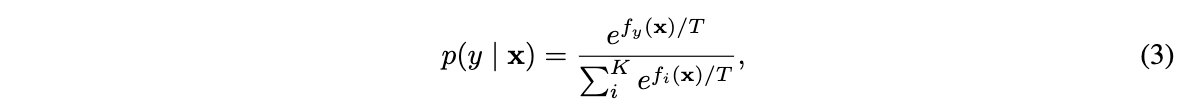
其中\(f_y(x)\)为\(f(x)\)的第\(y\)个输出。
通过关联公式1和公式3,可在不改动网络\(f(x)\)的情况下将分类网络转换为EBM。定义输入\((x,y)\)的energy为softmax的对应输入值\(E(x,y)=-f_y(x)\),再定义\(x\in\mathbb{R}^D\)的free energy为:
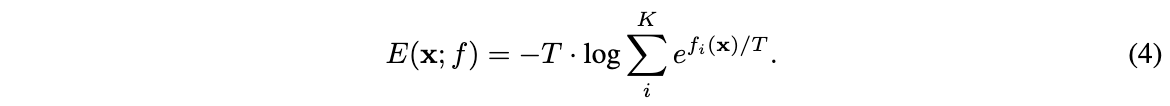
Energy-based Out-of-distribution Detection
Energy as Inference-time OOD Score
Out-of-distribution detection是个二分类问题,评价函数需要产生一个能够判定ID(in-distribution)数据和OOD(out-of-distribution)数据的分数。因此,论文尝试在分类模型上接入energy函数,通过energy进行OOD检测。energy较小的为ID数据,energy较大的为OOD数据。
实际上,通过负对数似然(negative log-likelihood,NLL))损失训练的模型本身就倾向于拉低ID数据的energy,负对数似然损失可表示为:
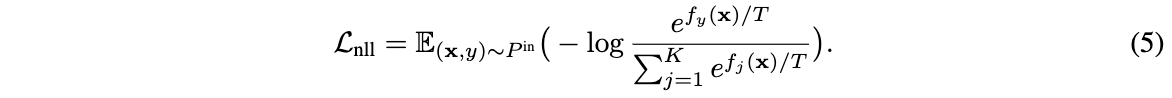
定义energy函数\(E(x,y)=-f_y(x)\)并将\(log\)里面的分数展开,NLL损失可转换为:
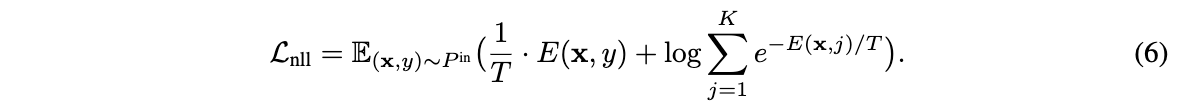
从损失值越低越好的优化角度看,公式6的第一项倾向于拉低目标类别\(y\)的energy,而公式6第二项从形式来看相当于输入数据的free energy。第二项导致整体损失函数倾向于拉低目标类别\(y\)的energy,同时拉高其它标签的energy,可以从梯度的角度进行解释:
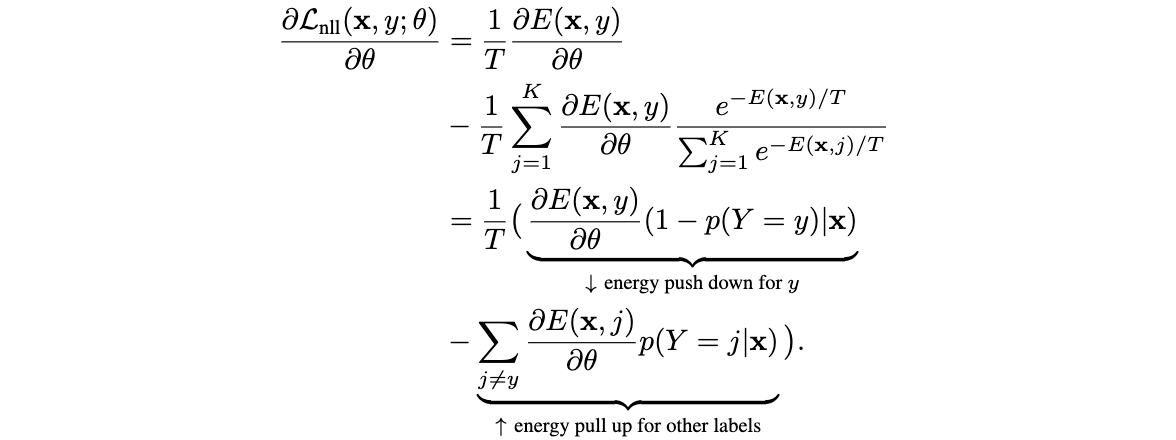
上述式子是对两项的梯度进行整合,分为目标类别相关的梯度和非目标相关的梯度。可以看到,目标类别相关的梯度是倾向于更小的energy,而非目标类别相关的梯度由于前面有负号,所以是倾向于更大的energy。另外,由于energy近似为\(-f_y(x)=E(x,y)\),通常都是目标类别的值比较大,所以NLL损失整体倾向于拉低ID数据的energy。
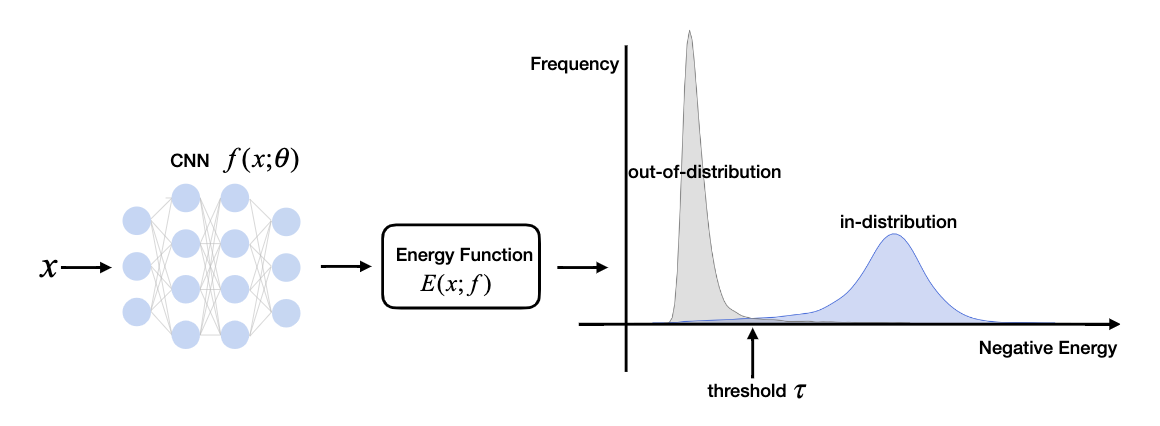
由于上述的energy特性,就可以基于energy函数\(E(x;f)\)进行OOD检测:
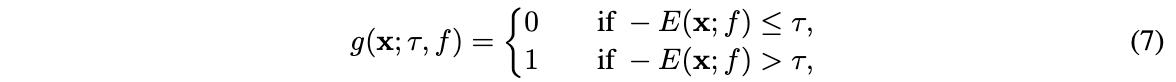
其中\(\tau\)为energy阈值,energy高于该阈值的被认定为OOD数据。在实际测试中,使用ID数据计算阈值,保证大部分的训练数据能被\(g(x)\)正确地区分。另外,需要注意的是,这里用了负energy分数\(-E(x;f)\),是为了遵循正样本有更高分数的常规定义。
Energy Score vs. Softmax Score
论文先通过公式推导,来证明energy可以简单又高效地在任意训练好的模型上代替softmax置信度。将sofmax置信度进行对数展开,结合公式4以及\(T=1\)进行符号转换:
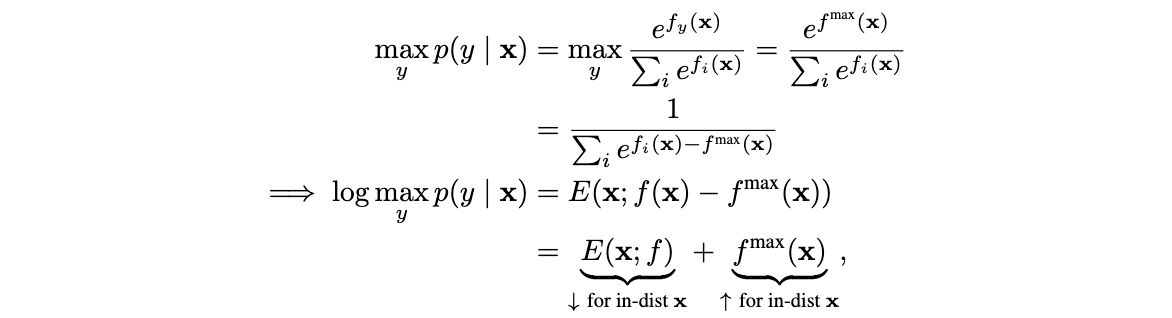
从上述式子可以看出,softmax置信度的对数实际上是free energy的特例,先将每个energy减去最大的energy进行偏移(shift),再进行free energy的计算,导致置信度与输入的概率密度不匹配。随着训练的进行,通常\(f^{max}(x)\)会变高,而\(E(x; f)\)则变低,所以softmax是有偏评价函数,置信度也不适用于OOD检测。
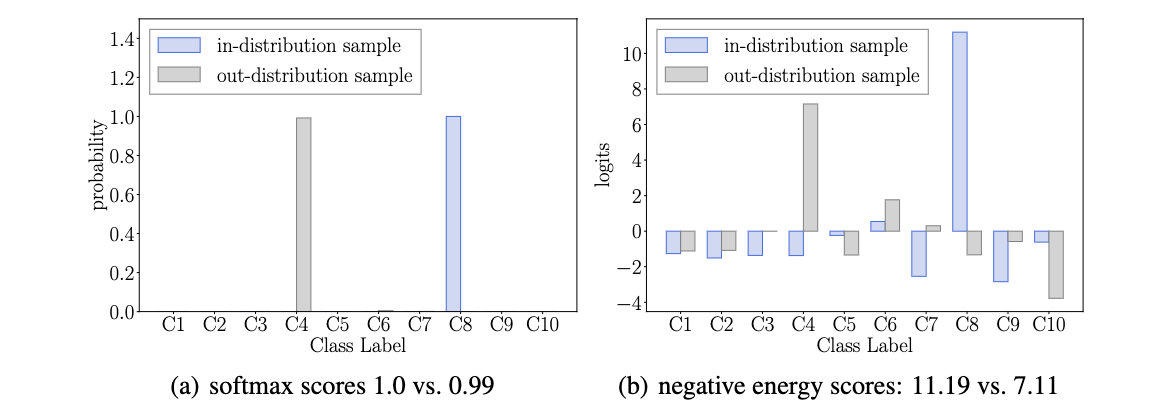
论文也通过真实的例子来进行对比,ID数据和OOD数据的softmax置信度差别很小(1.0 vs 0.99),而负energy则更有区分度(11.19 vs. 7.11)。因此,网络输出的值(energy)比偏移后的值(softmax score)包含更多有用的信息。
Energy-bounded Learning for OOD Detection
尽管energy score能够直接应用于训练好的模型,但ID数据和OOD数据的区分度可能还不够明显。为此,论文提出energy-bounded学习目标,对训练好的网络进行fine-tuned训练,显示地扩大ID数据和OOD数据之间的energy差异:
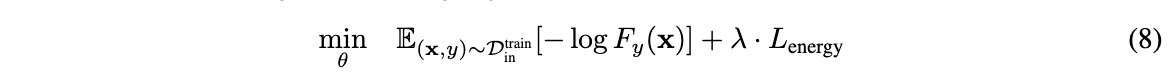
\(F(x)\)为softmax输出,\(D^{train}_{in}\)为ID数据。整体的训练目标包含标准交叉熵损失,以及基于energy的正则损失:
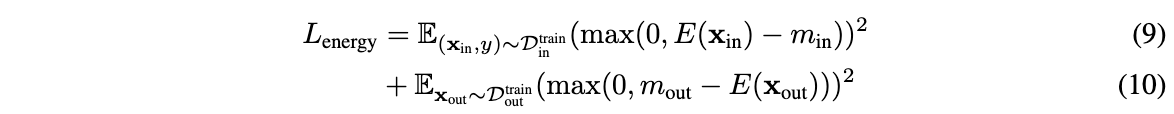
\(D^{train}_{out}\)为无标签的辅助OOD数据集,通过两个平方hinge损失对energy进行正则化,惩罚energy大于间隔参数\(m_{in}\)的ID数据以及energy小于间隔参数\(m_{out}\)的OOD数据。当模型fine-tuned好后,即可根据公式7进行OOD检测。
Experiment
ID数据集包含CIFA-10、CIFAR-100,并且分割训练集和测试集。OOD测试数据集包含Textures、SVHN、Places365、LSUN-Crop、LSUN_Resize和iSUN。辅助用的OOD数据集则采用80 Million Tiny Images,去掉CIFAR里面出现的类别。
评价指标采用以下:1)在ID数据95%正确的\(\tau\)阈值下的OOD数据错误率。2)ROC曲线下的区域大小(AUROC)。3)PR曲线下的区域大小(AUPR)。
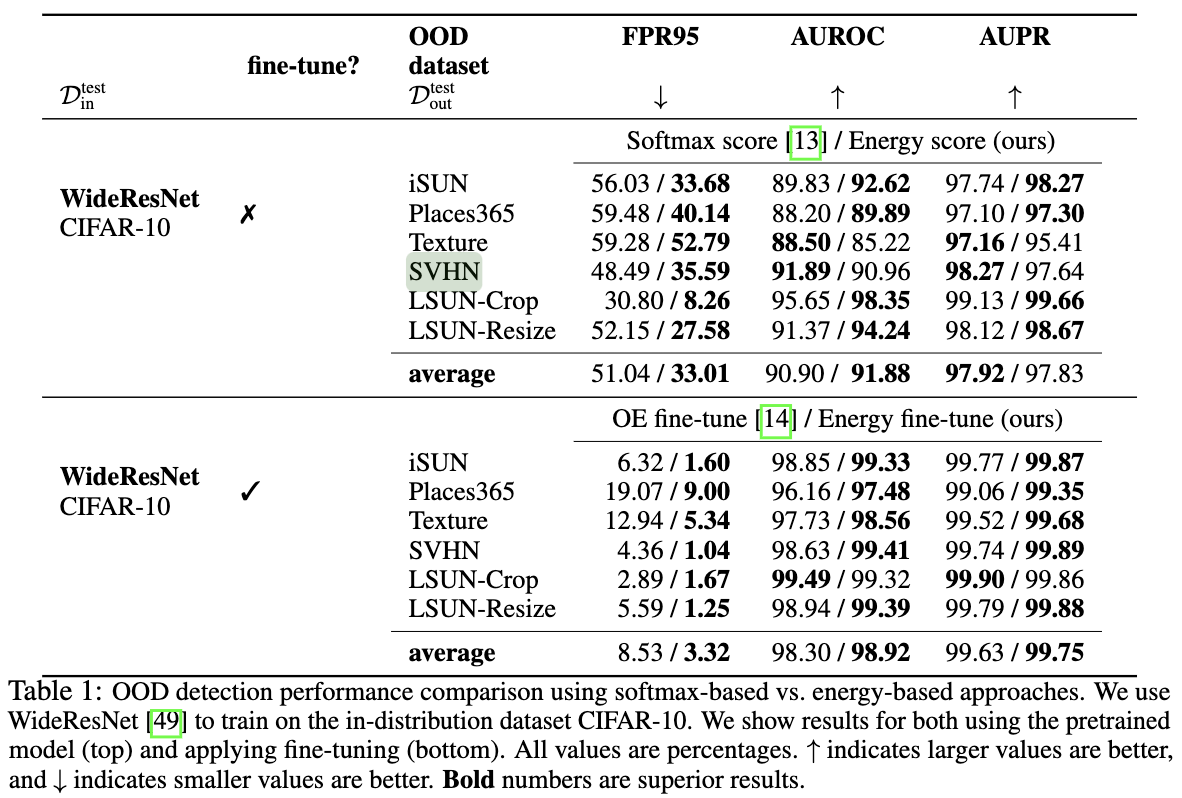
从结果可以看出,energy score比softmax score的表现要好,而经过fine-tuned之后,错误就很低了。
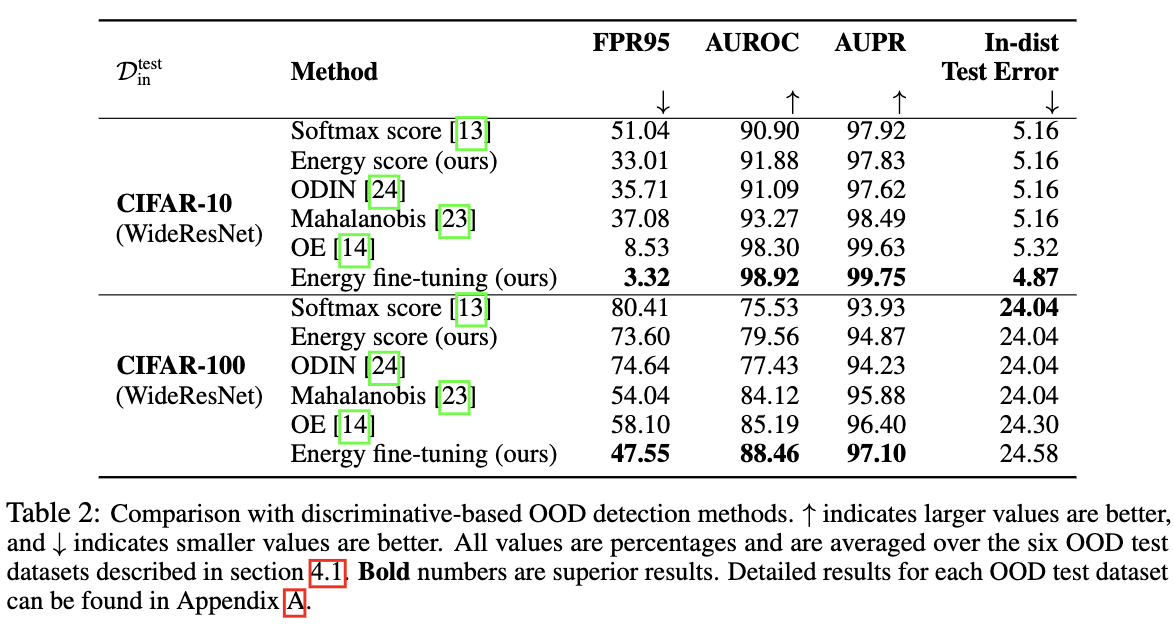
与其他OOD方法进行比较。
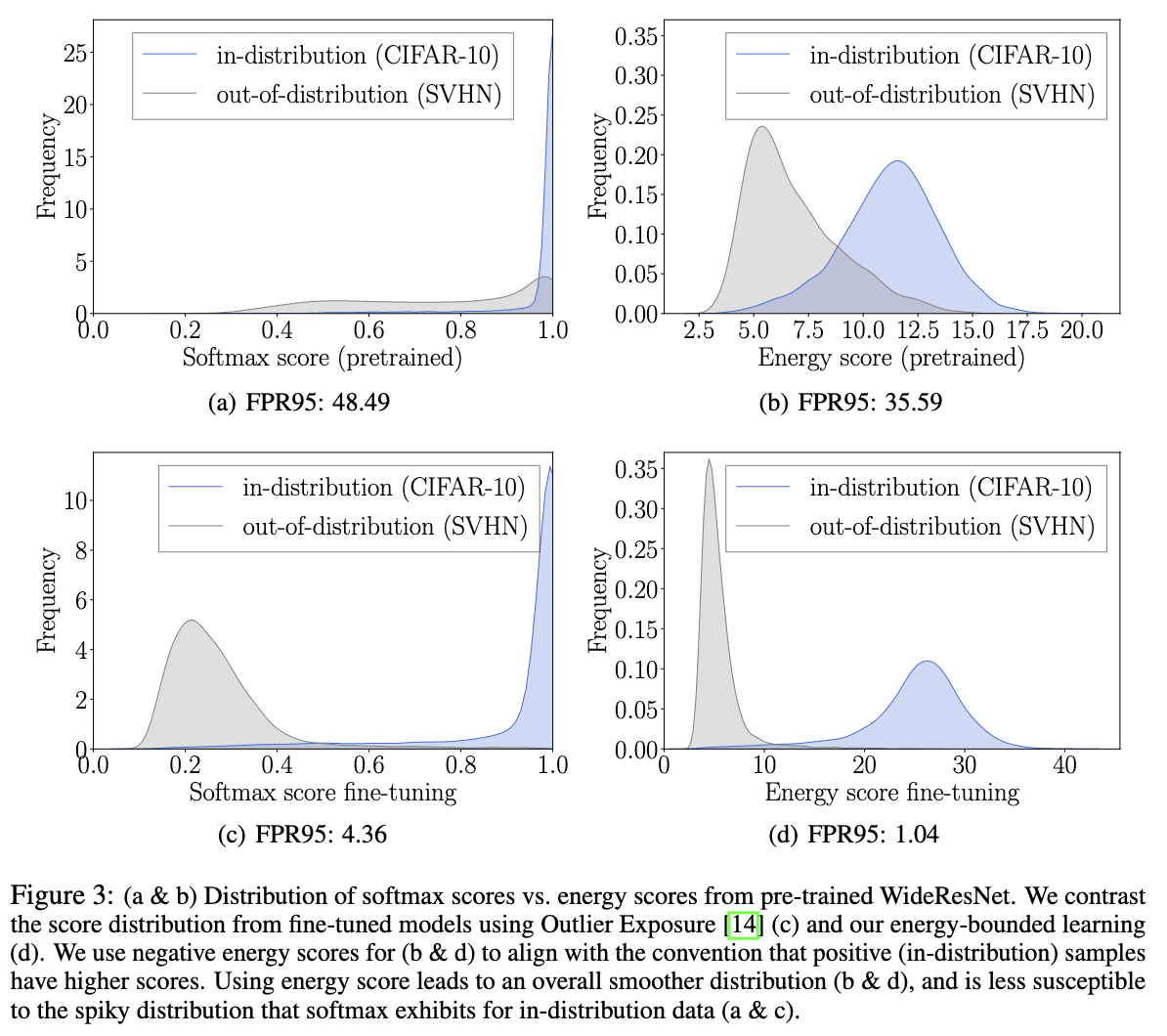
可视化对比。
Conclustion
论文提出用于out-of-distributions输入检测的energy-based方案,通过非概率的energy score区分in-distribution数据和out-of-distribution数据。不同于softmax置信度,energy score能够对齐输入数据的密度,提升OOD检测的准确率,对算法的实际应用有很大的意义。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
