一、合合信息acge模型获MTEB中文榜单第一
现阶段,大语言模型的飞速发展吸引着社会各界的目光,背后支撑大型语言模型应用落地的Embedding模型也成为业内关注的焦点。近期,合合信息发布了文本向量化模型acge_text_embedding(简称“acge模型”),获得MTEB中文榜单(C-MTEB)第一的成绩。
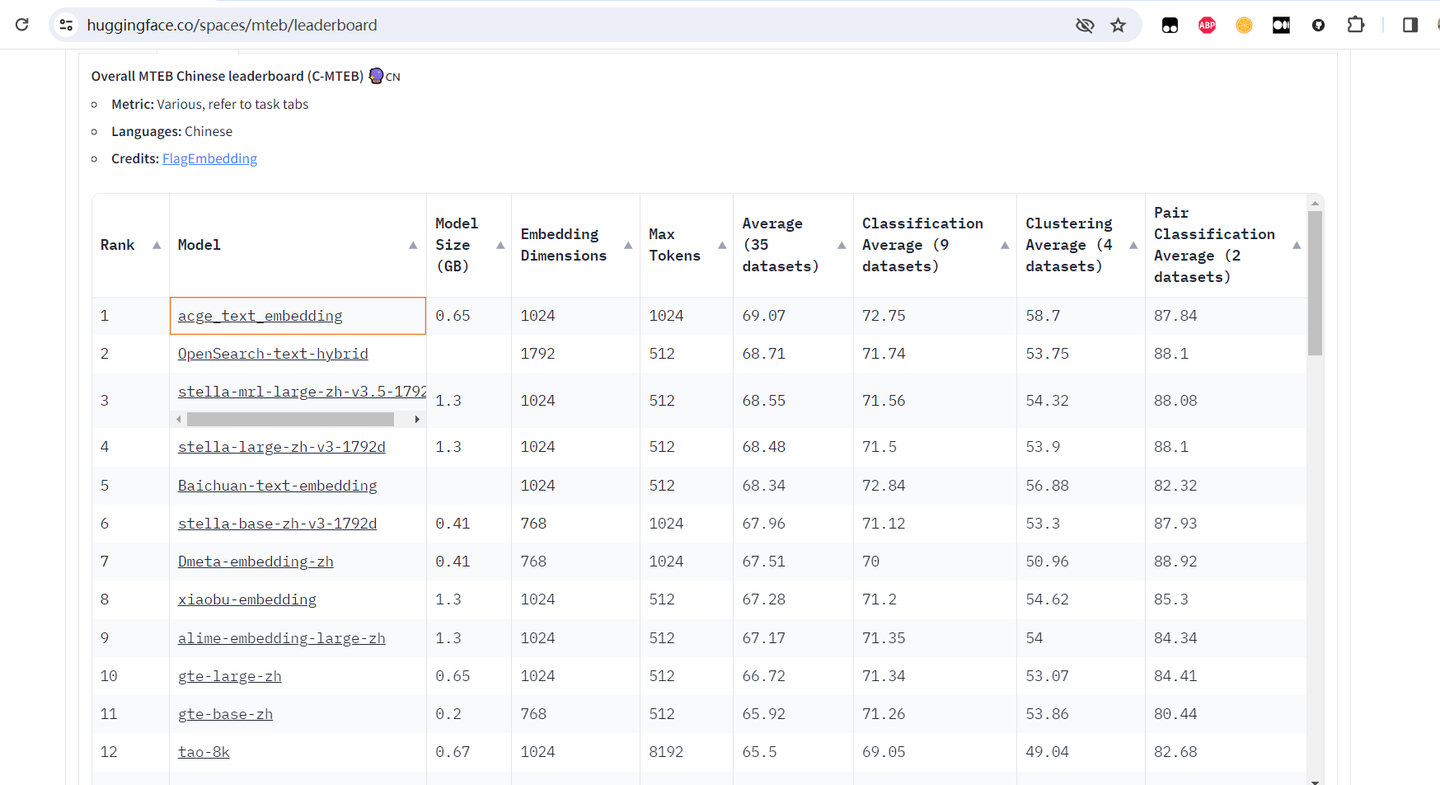 图1:C-MTEB榜单结果
二、MTEB与C-MTEB
MTEB(Massive Text Embedding Benchmark)是衡量文本嵌入模型(Embedding模型)的评估指标的合集,是目前业内评测文本向量模型性能的重要参考。对应的C-MTEB则是专门针对中文文本向量的评测基准。
C-MTEB被公认为是目前业界最全面、最权威的中文语义向量评测基准之一,涵盖了分类、聚类、检索、排序、文本相似度、STS等6个经典任务,共计35个数据集,为深度测试中文语义向量的全面性和可靠性提供了可靠的实验平台。
三、Embedding模型的意义
互联网时代中,随着信息量急剧膨胀,人们接触信息的渠道不断拓展,大量无关的信息已成为信息检索的干扰项。Embedding模型通过理解查询的深层含义和上下文,能够显著提高搜索和问答的质量、效率和准确性,让搜索和问答引擎不再只是匹配文字,而是可以真正理解人的意图。
图1:C-MTEB榜单结果
二、MTEB与C-MTEB
MTEB(Massive Text Embedding Benchmark)是衡量文本嵌入模型(Embedding模型)的评估指标的合集,是目前业内评测文本向量模型性能的重要参考。对应的C-MTEB则是专门针对中文文本向量的评测基准。
C-MTEB被公认为是目前业界最全面、最权威的中文语义向量评测基准之一,涵盖了分类、聚类、检索、排序、文本相似度、STS等6个经典任务,共计35个数据集,为深度测试中文语义向量的全面性和可靠性提供了可靠的实验平台。
三、Embedding模型的意义
互联网时代中,随着信息量急剧膨胀,人们接触信息的渠道不断拓展,大量无关的信息已成为信息检索的干扰项。Embedding模型通过理解查询的深层含义和上下文,能够显著提高搜索和问答的质量、效率和准确性,让搜索和问答引擎不再只是匹配文字,而是可以真正理解人的意图。
 Embedding模型能够将单词、句子或图像特征等高维的离散数据转换为低维的连续向量,捕捉到数据的语义特征和关系,被广泛应用于搜索、推荐、问答、检索增强生成、数据挖掘等领域。
“假设你需要了解如何在家中自制咖啡,可能会在搜索引擎中输入‘家庭咖啡制作方法’。如果没有Embedding模型,传统的引擎会简单地匹配包含关键词的文章,提供一些表面相关的内容而非实用的指南。”团队成员提到,借助Embedding模型,引擎便能更准确地理解用户意图,从而提供包括但不限于选择咖啡豆、磨豆技巧、不同的冲泡方法等更专业的内容。”
Embedding模型能够将单词、句子或图像特征等高维的离散数据转换为低维的连续向量,捕捉到数据的语义特征和关系,被广泛应用于搜索、推荐、问答、检索增强生成、数据挖掘等领域。
“假设你需要了解如何在家中自制咖啡,可能会在搜索引擎中输入‘家庭咖啡制作方法’。如果没有Embedding模型,传统的引擎会简单地匹配包含关键词的文章,提供一些表面相关的内容而非实用的指南。”团队成员提到,借助Embedding模型,引擎便能更准确地理解用户意图,从而提供包括但不限于选择咖啡豆、磨豆技巧、不同的冲泡方法等更专业的内容。”
 图2:embedding模型原理示意图
四、合合信息acge模型
Embedding模型在当前大模型实际落地应用过程中扮演着至关重要的角色。为了更好地发挥大模型在应用过程中的价值,合合信息技术团队重点从数据集、训练策略等方面针对Embedding模型进行了优化,打造了acge模型。技术人员构造了大量的数据集,保证训练的质量与场景覆盖面;在模型训练方面,团队也引入多种有效的模型调优技术。
(一)acge模型特点
据合合信息技术团队成员介绍,相比于传统的预训练或微调垂直领域模型,acge模型支持在不同场景下构建通用分类模型、提升长文档信息抽取精度,且应用成本相对较低,可帮助大模型在多个行业中快速创造价值,推动科技创新和产业升级,为构建新质生产力提供强有力的技术支持。
(二)acge模型功能
具体实践上,为做好不同任务的针对性学习,团队使用策略学习训练方式,显著提升了检索、聚类、排序等任务上的性能;引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题,使模型训练迭代能够达到相对优秀的收敛空间;运用MRL技术,实现一次训练,获取不同维度的表征。
(三)acge模型优势
与目前C-MTEB榜单上排名前五的开源模型相比,合合信息本次发布的acge模型较小,占用资源少;模型输入文本长度为1024,满足绝大部分场景的需求。此外,acge模型还支持可变输出维度,让企业能够根据具体场景去合理分配资源。
图2:embedding模型原理示意图
四、合合信息acge模型
Embedding模型在当前大模型实际落地应用过程中扮演着至关重要的角色。为了更好地发挥大模型在应用过程中的价值,合合信息技术团队重点从数据集、训练策略等方面针对Embedding模型进行了优化,打造了acge模型。技术人员构造了大量的数据集,保证训练的质量与场景覆盖面;在模型训练方面,团队也引入多种有效的模型调优技术。
(一)acge模型特点
据合合信息技术团队成员介绍,相比于传统的预训练或微调垂直领域模型,acge模型支持在不同场景下构建通用分类模型、提升长文档信息抽取精度,且应用成本相对较低,可帮助大模型在多个行业中快速创造价值,推动科技创新和产业升级,为构建新质生产力提供强有力的技术支持。
(二)acge模型功能
具体实践上,为做好不同任务的针对性学习,团队使用策略学习训练方式,显著提升了检索、聚类、排序等任务上的性能;引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题,使模型训练迭代能够达到相对优秀的收敛空间;运用MRL技术,实现一次训练,获取不同维度的表征。
(三)acge模型优势
与目前C-MTEB榜单上排名前五的开源模型相比,合合信息本次发布的acge模型较小,占用资源少;模型输入文本长度为1024,满足绝大部分场景的需求。此外,acge模型还支持可变输出维度,让企业能够根据具体场景去合理分配资源。
 五、公司介绍
合合信息是一家人工智能及大数据科技企业,基于自主研发的领先的智能文字识别及商业大数据核心技术,为全球C端用户和多元行业B端客户提供数字化、智能化的产品及服务。公开资料显示,公司的C端产品覆盖了全球百余个国家和地区的亿级用户,B端服务覆盖了近30个行业的企业客户。《财富》杂志2022年发布的世界500强公司名单中,公司客户已覆盖超过125家。
五、公司介绍
合合信息是一家人工智能及大数据科技企业,基于自主研发的领先的智能文字识别及商业大数据核心技术,为全球C端用户和多元行业B端客户提供数字化、智能化的产品及服务。公开资料显示,公司的C端产品覆盖了全球百余个国家和地区的亿级用户,B端服务覆盖了近30个行业的企业客户。《财富》杂志2022年发布的世界500强公司名单中,公司客户已覆盖超过125家。