包的安装
pip install lxml
谷歌浏览器插件安装
XPath Helper 可以自行搜索安装也可以点击: 传送门
解析流程与使用
- 实例化一个etree的对象,把即将被解析的页面源码加载到该对象。
- 调用该对象的xpath方法结合着不同形式的xpath表达式进行标签定位和数据提取
# 导入lxml.etree
from lxml import etree
# 方法1:
# 使用etree.parse() 解析本地html文件
# 如果遇到报错,在打开文件之前指定编码 etree.HTMLParser(encoding='utf-8')
parser = etree.HTMLParser(encoding='utf-8')
# 这里直接指定路径就行,如果使用open打开会报错
selector = etree.parse('../bs4练习/豆瓣读书 Top 250.html', parser=parser)
result = etree.tostring(selector)
print(result)
# 方法2:
# 【推荐】使用etree.HTML(html字符串) 解析网络或者本地资源 这种方法容错能力更强
with open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8') as file:
data = file.read()
html_tree = etree.HTML(data)
print(html_tree) # <Element html at 0x1ee7986ba80> 这个就表示节点对象
# 【推荐】另一种写法
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# 使用html_tree.xpath() 得到的结果是一个列表
items = html_tree.xpath('xpath语法')
print(items)
xpath语法
xpath是一门在XML文档中查找信息的语言。xpath用于在XML文档中通过元素和属性进行导航。
路径表达式
| 表达式 | 描述 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| ./ | 当前节点再次进行xpath |
| @ | 选取属性 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果
| 路径表达式 | 结果 |
|---|---|
| /html | 选取根元素/bookstore。注释:加入路径起始于正斜杠(/),则此路径始终代表到某元素的绝对路径! |
| //li | 选取所有li子元素,而不管它们在文档中的位置。 |
| //ul//li | 选择属于ul元素的后代的所有li元素,而不管它们位于ul之下的什么位置。 |
节点对象.xpath('./div') |
选择当前节点对象里面的第一个div节点 |
一层一层取 / 开头
获取整个标签 tostring
节点对象转成字符串的输出 etree.tostring(obj, encoding) 这样得到的结果就是整个标签<a>..</a>
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# 拿到的是一个列表
result = tree.xpath('/html/body/div/div/div/a')
# 使用etree.tostring将节点对象转成字符串的输出
# 参数解读 etree.tostring(转谁, 编码)
r = etree.tostring(result[0], encoding='utf-8') # 这样拿到的是二进制
# 解码 不写参数默认就是utf-8
print(r.decode())
# 简写
r = etree.tostring(result[0], encoding='utf-8').decode()
# 单个取值
r1 = etree.tostring(result[0], encoding='utf-8').decode()
r2 = etree.tostring(result[1], encoding='utf-8').decode()
print(r1)
print(r2)
# 遍历取值
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
我全都要 // 开头
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# 获取当前页面所有的a 无论是哪一个位置
result = tree.xpath('//a')
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
# 获取当前页面所有的图片标签 不论在哪一个位置
result = tree.xpath('//img')
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
获取标签的文本内容 /text()
# 获取a标签中的文本
result = tree.xpath('/html/body/div/div/div/a/text()')
print(result) # ['登录/注册', '下载豆瓣客户端']
通过[ ] 可以指定位置,索引是从1开始,不是从0开始
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
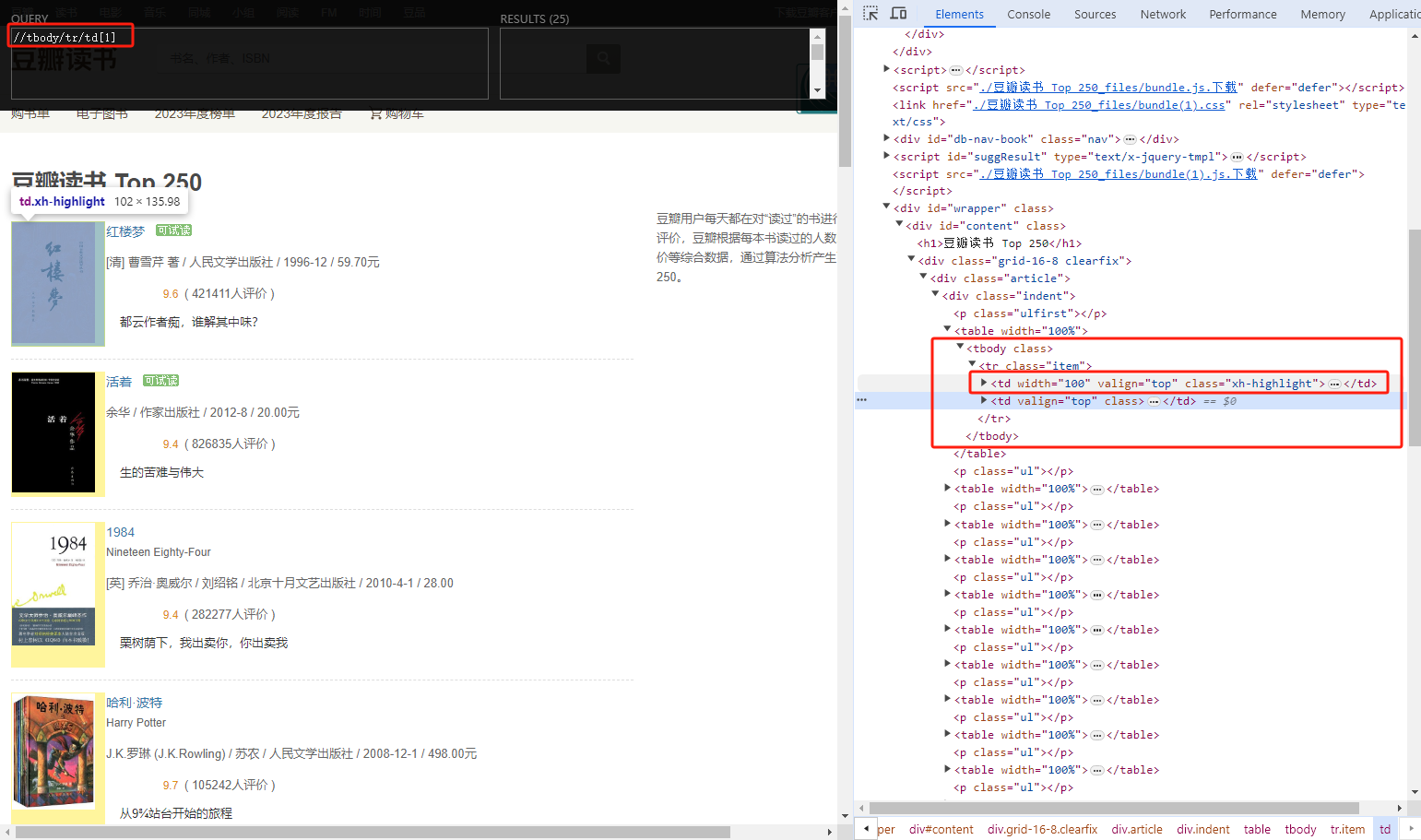
# tr下面有2个td 获取第一个td下面的a标签
result = tree.xpath('//tbody/tr/td[1]/a')
for line in result:
print(line)
/ 和 // 在下一次路径中的使用
总结:
当前节点下如果要继续匹配,只能使用
./,继续匹配,使用/和//都不起作用,都相当从头开始找了。
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
result = tree.xpath('/html/body/div/div/div/a')
print(result) # [<Element a at 0x1b1106bf300>, <Element a at 0x1b1106be880>]
# 只要是<class 'lxml.etree._Element'> 对象,就可以一直使用节点.xpath()继续匹配
# ./ 代表当前节点往下继续匹配
r1 = result[0].xpath('./text()') # 这个写法等同于tree.xpath('/html/body/div/div/div/a/text()')
print(r1) # ['登录/注册']
# 如果确定只有一个标签 那么 . 可以省略
r2 = result[0].xpath('text()')
print(r2) # ['登录/注册']
# 因为单独一个 / 代表从根目录匹配 所以在这个案例中 /text() 拿不到任何数据
# 这里的/text() 从根下开始匹配 根应该是/html 和前面的result[0] 一点关系都没有 所以也就拿不到数据
r3 = result[0].xpath('/text()')
print(r3) # []
# //text() 相当于tree.xpath('//text()') 查找所有的有文本的内容 和result[0] 一点关系也没有,所以拿到了全部的数据
r4 = result[0].xpath('//text()')
print(r4) # 拿到了全部的结果
/ 和 // 的混合使用
获取属性值通过 /@属性名
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# 获取属性,可以通过@ 下面这个xpath表达式的意思就是 查找所有class属性为item的tr标签
# //标签名[@属性名=属性值]
result = tree.xpath('//tr[@class="item"]')
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
# 获取所有文本 在class=pl2这个节点下的所有标签的文本我都要
result = tree.xpath('//div[@class="pl2"]//text()')
for line in result:
print(line)
# 获取class=item的tr标签下面的第一个td标签里面的全部img标签
result = tree.xpath("//tr[@class='item']/td[1]//img")
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
# 获取class=item的tr标签下的第一个td标签里面的全部img标签的链接地址,即src属性
# 获取属性值通过@属性名
result = tree.xpath('//tr[@class="item"]/td[1]//img/@src')
for line in result:
print(line)
数量限制
现在说的xpath语法,完全可以使用列表的切片替代。
- 获取第几个使用:
[n]- 获取最后一个使用:
[last()]- 获取倒数的,使用:
[last()-(n-1)]- 前n个,使用:
[position()<=n]或者[position()<n-1]- 获取a到b,使用:
[position()>=a and position()<=b]
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
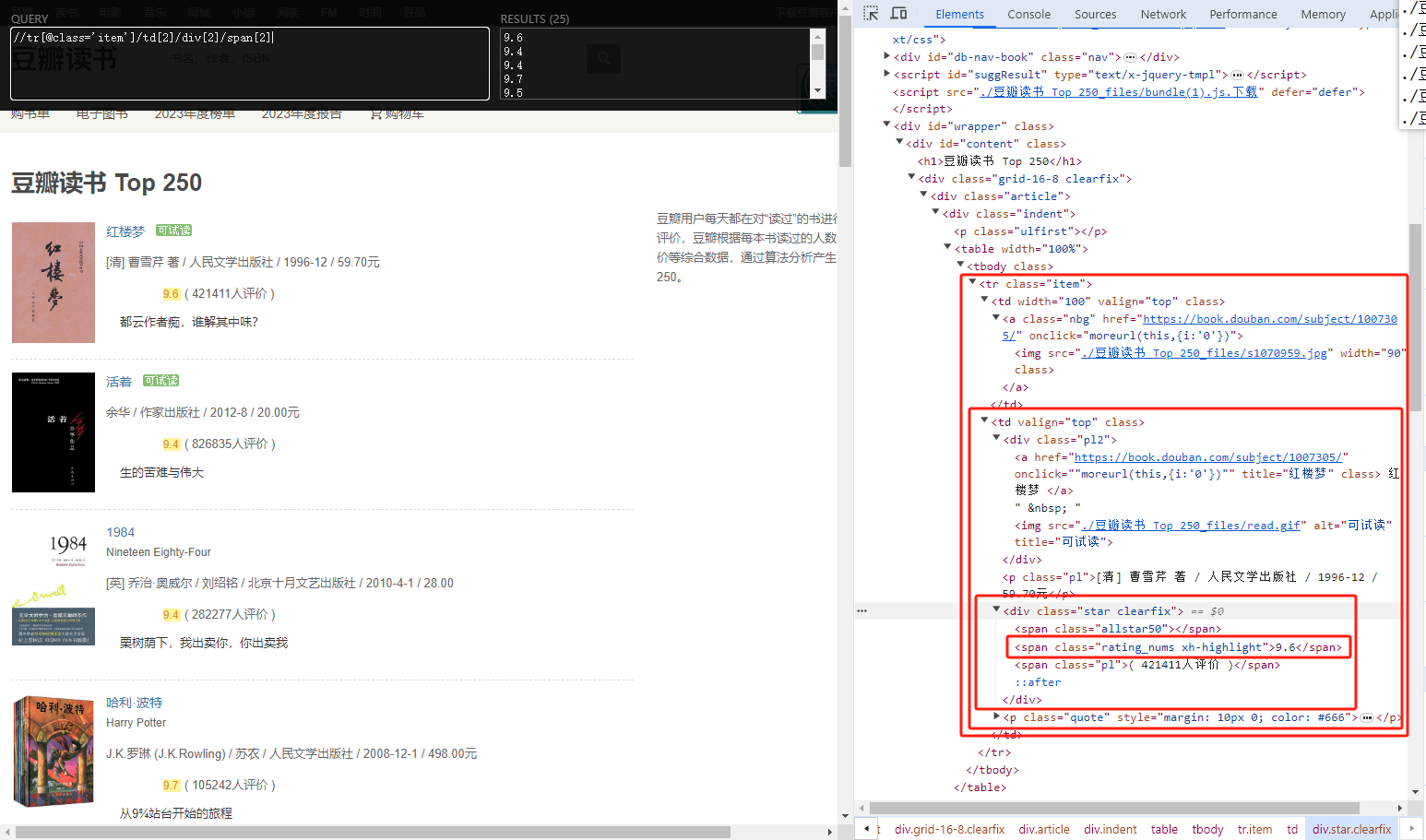
# 获取class=item的tr标签下的第二个td标签里面的第二个div标签里面的第2个span标签
result = tree.xpath("//tr[@class='item']/td[2]/div[2]/span[2]")
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
# 获取最后一个[last()]
# 获取class=item的tr标签下的第二个td标签里面的第二个div标签里面的最后一个span标签
result = tree.xpath('//tr[@class="item"]/td[2]/div[2]/span[last()]')
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
# 获取倒数第n个 [last()-(n-1)] 倒数第二个就是 [last()-(2-1)] --> [last()-1]
# 获取class=item的tr标签下的第二个td标签里面的第二个div标签里面的倒数第二个span标签
result = tree.xpath('//tr[@class="item"]/td[2]/div[2]/span[last()-1]')
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
# 获取前几个 [position<n+1] 获取前两个就是 [position<2+1] --> [position()<3]
# 前2个也可以写成[position()<=2]
# 获取class=item的tr标签下的第二个td标签里面的第二个div标签里面的前span标签
# result = tree.xpath('//tr[@class="item"]/td[2]/div[2]/span[position<=2]')
result = tree.xpath('//tr[@class="item"]/td[2]/div[2]/span[position<3]')
for line in result:
print(etree.tostring(line, encoding='utf-8').decode())
https://www.shicimingju.com/book/hongloumeng.html
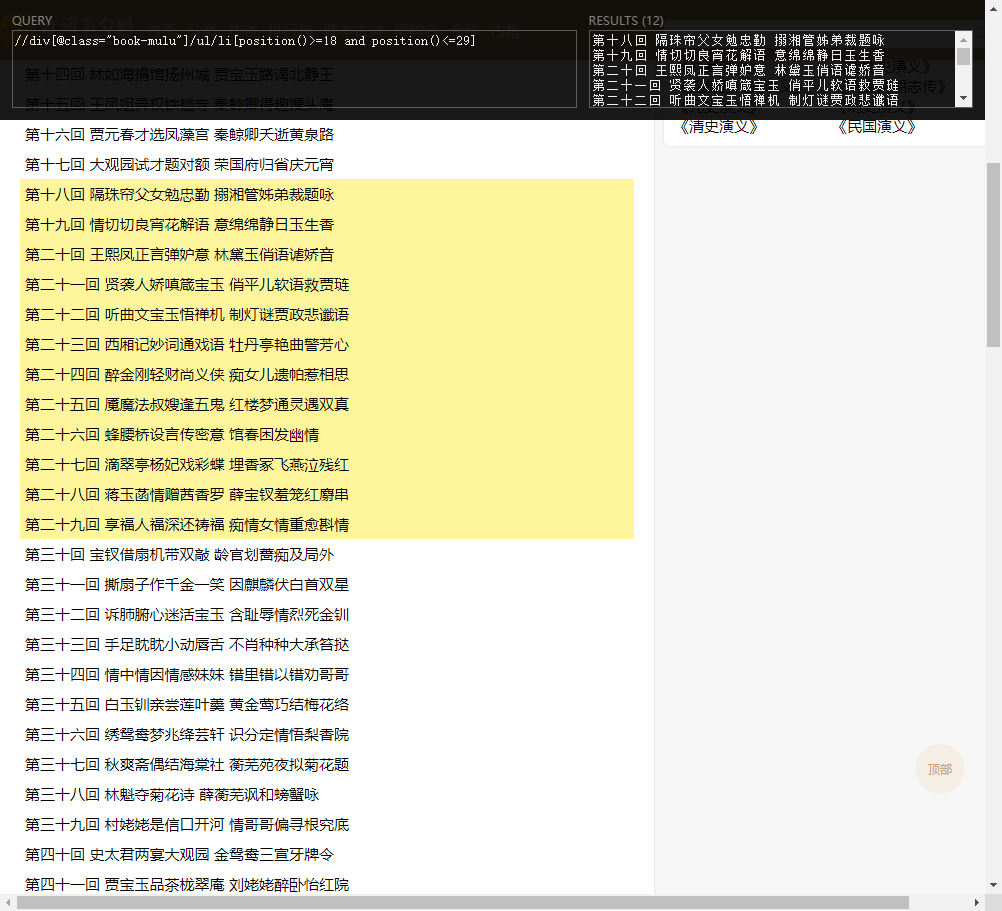
获取第18个到29个
逻辑或 |
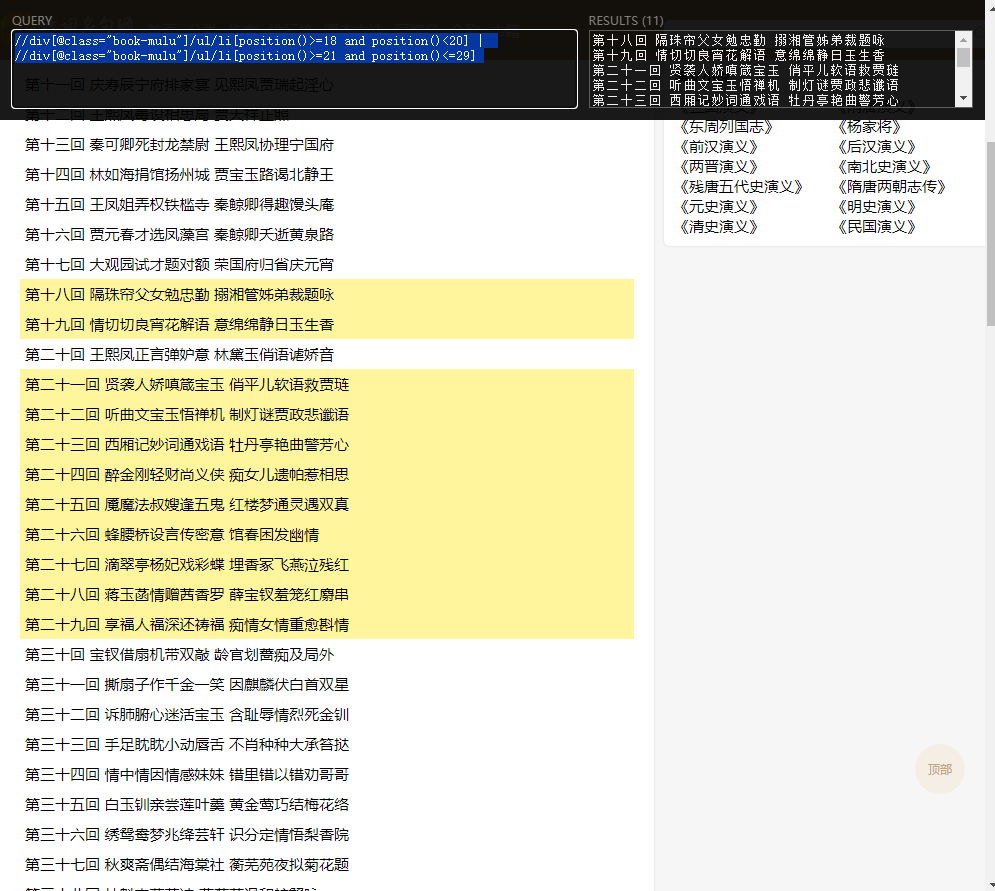
获取第18到29回合,但是不包含20回合的数据
//div[@class="book-mulu"]/ul/li[position()>=18 and position()<20] | //div[@class="book-mulu"]/ul/li[position()>=21 and position()<=29]
逻辑 and
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# 获取id等于"top-nav-appintro" 并且 class等于"more-items" 的div标签
result = tree.xpath('//div[@id="top-nav-appintro" and @class="more-items"]')
print(etree.tostring(result[0], encoding='utf-8').decode())
attr属性
如果要属性值指定了,那就是获取指定属性的标签,如果没有指定,就是获取带有这个属性的标签
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# 获取所有的img标签
r1 = tree.xpath('//img')
# 获取所有img的src属性
r2 = tree.xpath('//img/@src')
# 获取所有包含src属性的结果 (即不论是不是img标签)
r3 = tree.xpath('//@src')
# 获取所有,具有src属性的img标签
r4 = tree.xpath('//img[@src]')
# 获取所有具有class属性的div标签
r5 = tree.xpath('//div[@class]')
判断
除了
=和!=,其他了解即可这里的判断同JavaScript,会自动换成同一个类型进行比较,不多余赘述。
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# 获取所有带有class属性的a
result = tree.xpath('//a[@class]')
# 获取所有class属性值为"cover"的a
result = tree.xpath('//a[@class="cover"]')
# 获取price属性大于10的标签
result = tree.xpath('//a[@price>"10"]')
# 获取price属性大于等于10的标签
result = tree.xpath('//a[@price>="10"]')
# 获取price属性小于10的标签
result = tree.xpath('//a[@price<"10"]')
# 获取price属性小于等于10的标签
result = tree.xpath('//a[@price<="10"]')
# 获取price属性不等于10的标签
result = tree.xpath('//a[@price!="10"]')
通配符 * 的使用
通配符
*一般只有在copy xpath的时候会出现*自己写的时候很少用
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# 获取所有带有class属性的标签 不论什么标签我都要
result = tree.xpath('//*[@class]')
# 获取带有price属性的全部标签
result = tree.xpath('//*[@"price"]')
# node() 匹配任何类型的节点 (没有什么意义)
result = tree.xpath("node()")
包含关系 contains
语法:
*[contains(@属性, '包含的标签部分')]
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# div标签中 属性值包含pl的节点
result = tree.xpath('//div[contains(@class, "pl")]//text()')
print(result)
以什么开始 starts-with
from lxml import etree
# 实例化tree对象
tree = etree.HTML(open('../bs4练习/豆瓣读书 Top 250.html', encoding='utf-8').read())
# div标签中 属性值以a开头的节点
result = tree.xpath('//div[starts-with(@class, "a")]//text()')
print(result)
案例练习
import requests
from lxml import etree
import base64
from openpyxl import Workbook
from pathlib import Path
from fake_useragent import UserAgent
BASE_DIR = Path(__file__).parent
def encryption():
url = b'aHR0cDovL3d3dy5xaWFubXUub3JnL3Jhbmtpbmc='
return base64.b64decode(url).decode()
def get_request(url):
try:
response = requests.get(url=url, headers={'UserAgent': UserAgent().random})
response.encoding = response.apparent_encoding
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(e)
else:
return response.text
wb = Workbook()
ws = wb.active
ws.title = '世界大学排行榜最新'
ws.append(['排名', '学校名称', '学校英语名', '国家/地区'])
def fetch_content(content):
tree = etree.HTML(content)
result = tree.xpath('//*[@id="page-wrapper"]/div/div[2]/div/div/div/div[2]/div/div[5]/table/tbody')
for line in result:
rank = line.xpath(".//td[1]/text()")
school_name = line.xpath(".//td[2]/text()")
school_english_name = line.xpath(".//td[3]/text()")
country = line.xpath(".//td[4]/text()")
for rank_result, school_name_result, school_english_name_result, country_result in zip(rank, school_name,
school_english_name,
country):
data = [rank_result, school_name_result, school_english_name_result, country_result]
ws.append(data)
if __name__ == '__main__':
url = encryption()
content = get_request(url)
fetch_content(content)
wb.save(rf'{BASE_DIR}/世界大学排行榜.xlsx')